sql --------해석 기능--------> DBMS ------알고리즘(실행계획)-----> 데이터 적용
실행계획(execution plan)
SQL 문으로 요청한 데이터를 어떻게 불러올 것인지에 관한 계획, 즉 경로를 의미합
query optimizer : 실행계획을 기획하는 사람
query tunning : query optimizer가 원하는 실행계획을 만드는 것
DML
select
insert
update
delete
DDL
create database / table
drop database / table
alter table ...
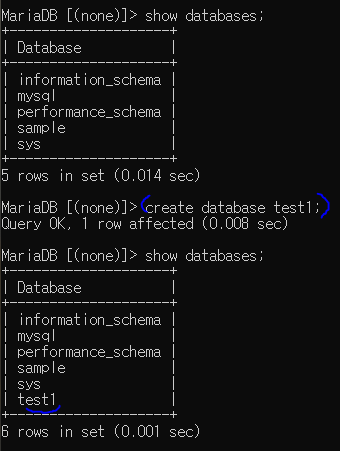
create : 데이터베이스(폴더) 생성
우리가 했던 예제 (sample 데이터베이스) 같은 폴더 생성해줌
똑같은 폴더는 만들 수 없다( 중복 불가 )
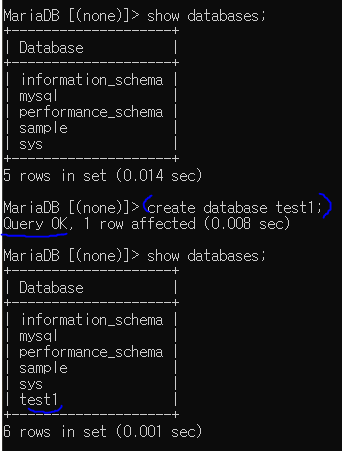
Query Ok. 구문이 뜨면 정상적으로 실행된 것
if문을 이용하여 중복시 오류 안 뜨게 하기
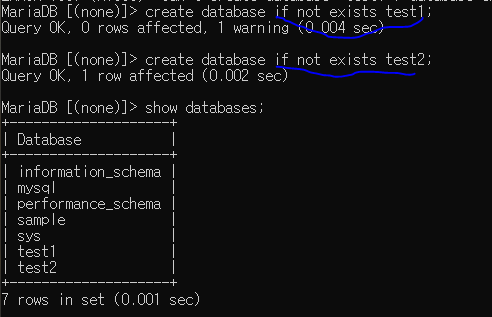
파일이 존재하면 그냥 두고 존재하지 않으면 생성하라 라는 뜻
drop : 데이터베이스(폴더) 삭제
만들어진 데이터베이스, 테이블 삭제
없는 폴더 삭제 불가
, 구분자로 여러개 삭제 가능
drop database / table 해당명;
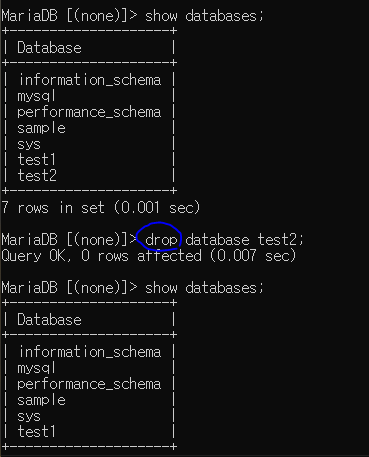
이것도 if문 사용하여 오류 방지할 수 있다.
데이터 타입 종류
-
문자형
char : 고정 길이 (ex > 5개 공간에 3개만 쓴다면 2개는 없어지지 않고 보존됨)
varchar : 가변 (ex> 5개 공간에 3개만 사용하면 2개는 다른 거 채워짐, 신축성 좋음)
tinytext / text(가장 많이) / mediumtext / longtext : 많은 공간 할당하여 데이터 저장 -
숫자형
정수형 : int
실수형 : decimal(전체자리수, 소수점자리수) / double -
날짜형
date / datetime -
이진 데이터
X
table : 테이블 만들기
컬럼 이름, 데이터 종류(데이터 길이), 옵션으로 이루어져 있음
테이블 만드려면 데이터 타입의 종류를 알아야 한다.
ex> 테이블 만들기
테이블명 tbl1 (if문 사용 가능함, create table if not exists tbl1)
컬럼명 col1, 데이터 타입 varchar(2)

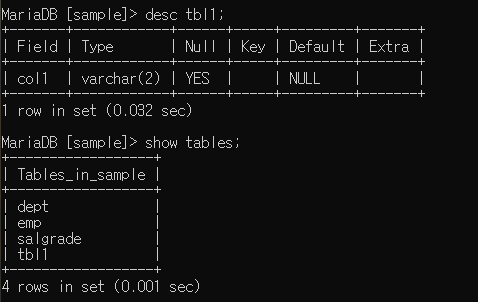
만들어진 것 확인
테이블 삭제는 마찬가지로 drop(if exists 사용 가능)
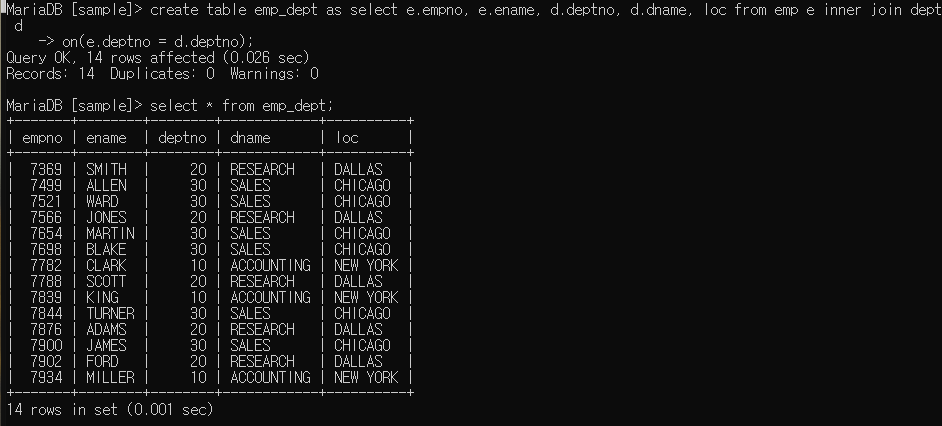
as : 테이블 복사
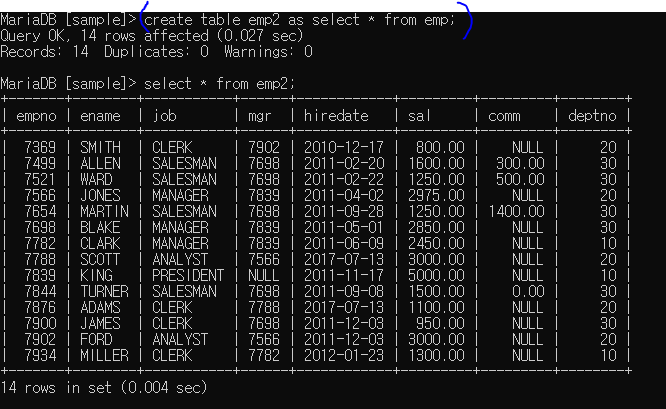
일부분만 추출하여 복사 가능
ex1
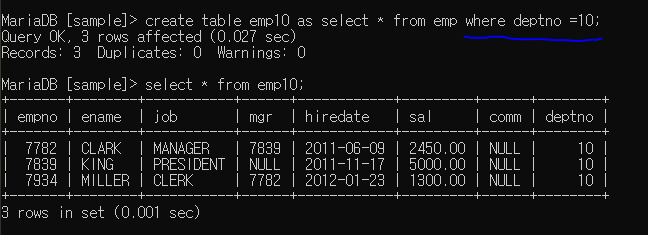
ex2
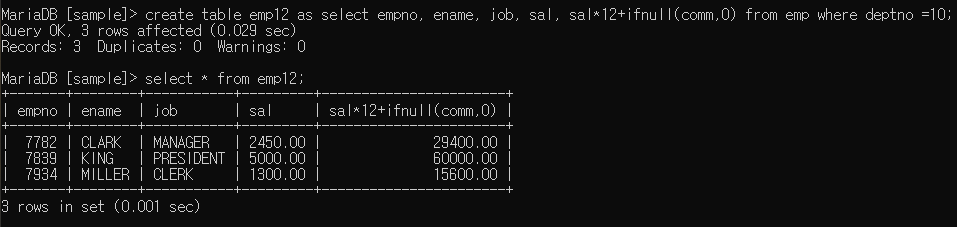
ex2에서 가공된 컬럼(sal * 12 ..) 이름 바꾸기
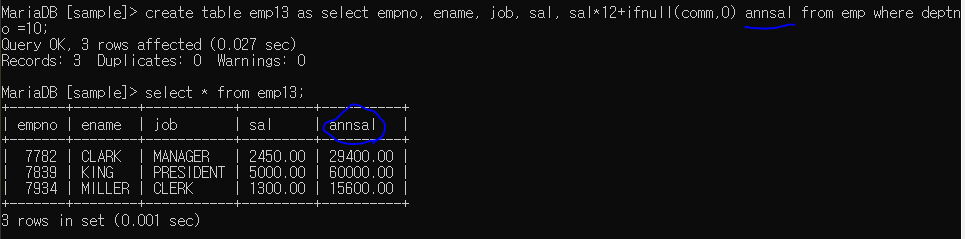
응용 = empno, ename, deptno, dname, loc 있는 테이블 생성
빈 테이블 만들기
껍데기만 있고 안에 데이터가 없는 테이블 만들기
테이블 줄 때 where로 부정조건을 주면 됨(부정조건은 아무거나 상관 없다)
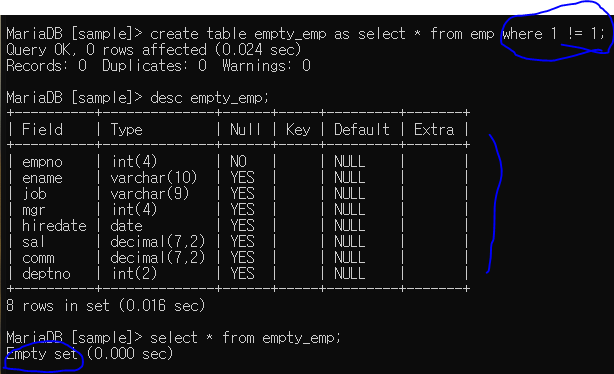
테이블과 컬럼은 있으나, 안의 내용은 비어있는 테이블
데이터베이스에서 다른 데이터베이스 데이터 접근
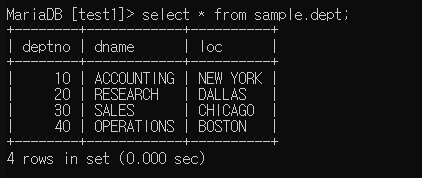
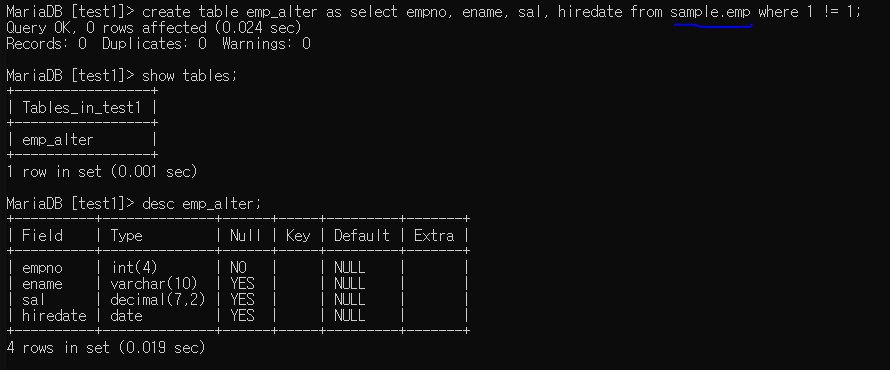
이런식으로 데이터베이스명.컬럼명 사용하여 접근할 수 있다(테이블도 만들기 가능하다)
alter
alter 통하여 테이블 규정 수정 : (컬럼 추가 / 수정 / 삭제 등)
마찬가지로 삭제는 drop;
add : 추가
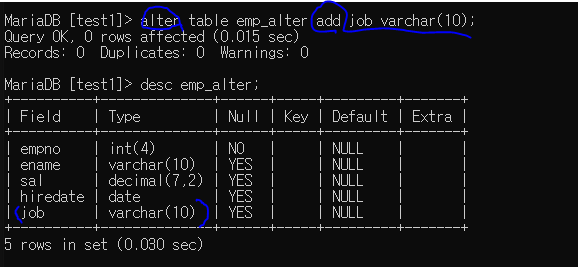
추가할때 원하는 위치에 집어넣진 못하고 맨 뒤에 추가된다.
alter ~ modify : 수정
만들어진 컬럼을 수정한다, 수정시에 데이터를 잘 생각하고 하기(자료형 크기나, 내부 공간 크기)
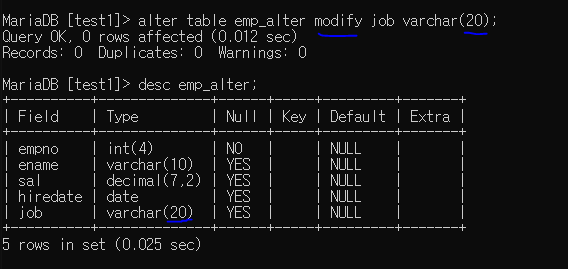
job의 varchar(10) 을 varchar(20)으로 수정
늘리는 건 가능하나, 줄이는 건 제한된다.
큰방향 -> 작은방향 에러날 수 있다.
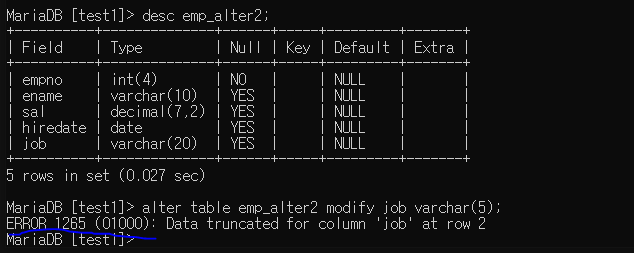
데이터 공간을 줄이는 것으로 수정할 시 에러가 나는 모습
alter ~ drop : 삭제
만들어진 컬럼 삭제
alter table 테이블명 drop 컬럼명
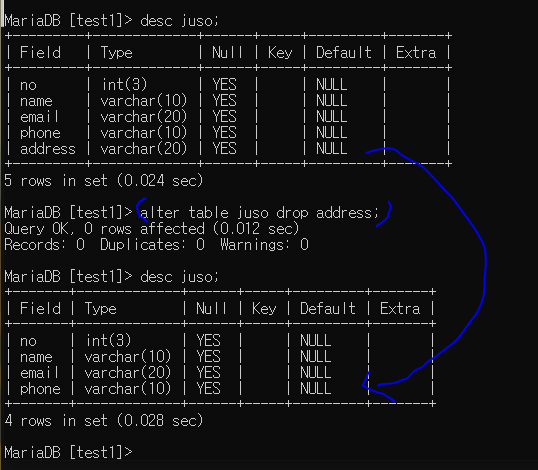
rename ~ to : 이름 바꾸기
대상의 이름을 변경한다.
컬럼 이름 변경시
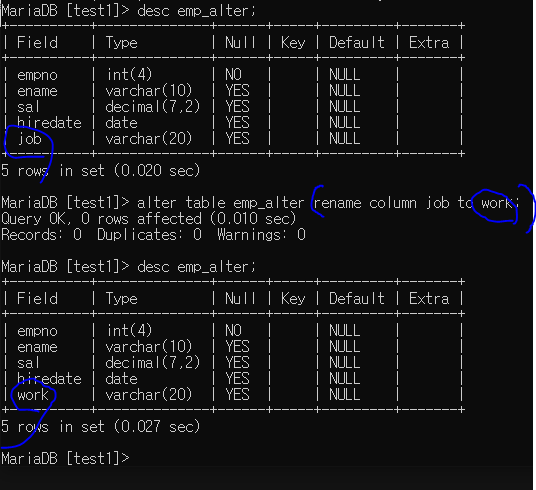
테이블 이름 변경시
alter table emp_alter2 rename emp_alter3;
rename table emp_alter3 to emp_alter2;
2가지가 있다.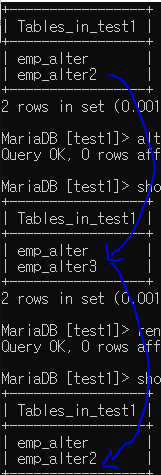
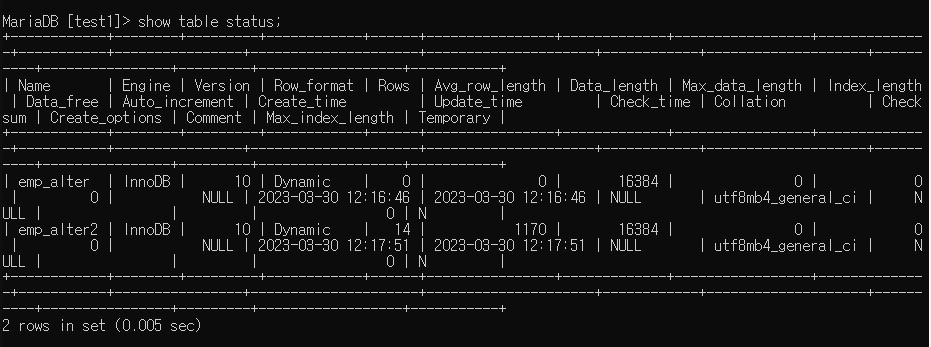
테이블 정보
show table status; -> 테이블 정보, 성격들이 출력됨
show create table 테이블명; -> 테이블 형식으로 보여준다.
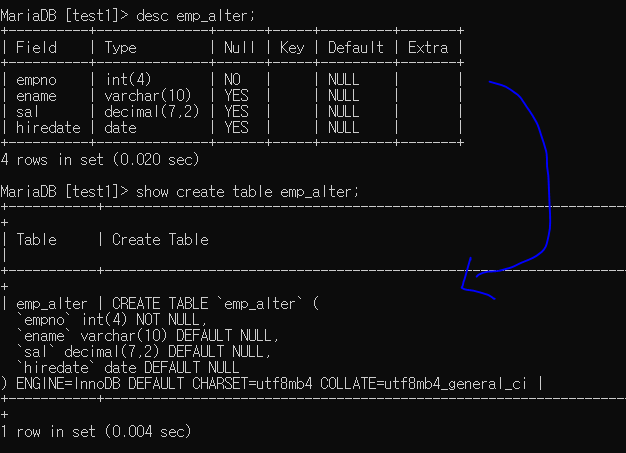
여기서 테이블명 뒤에 \G를 붙이면 ---+ 이런 기호들이 사라진다.
insert : 데이터 입력
insert into 테이블명 values (값1, 값2 ,,,)
insert into dept values (50, '생산', '부산');
insert into dept (deptno, loc, dname) values (50, '부산', '생산'); --> 이렇게 쓰면 컬럼의 순서와 동일할 필요 없다, 자동으로 맞게 바뀜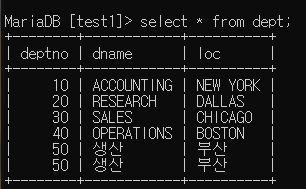
- 값의 순서는 컬럼의 순서와 동일해야 한다.
- 자료형의 크기 조심(테이블 자료형 크기보다 크게 쓰면 에러)
- 문자열 데이터는 반드시 ''로 표시(숫자는 '' 써도 자동으로 형변환 됨)
입력 시 필수요소 : null / not null
null = 안 넣어도 되는 것(null을 넣어도 무방하다)
not null = 반드시 넣어야 하는 것(null을 넣을 수 없다)
기본적으로 table을 만들면 null을 허용함
create table dept3 (deptno int(2) not null, dname varchar(14), loc varchar(13) ); --> 자료형 크기 뒤에 not null을 붙여줘서 적용
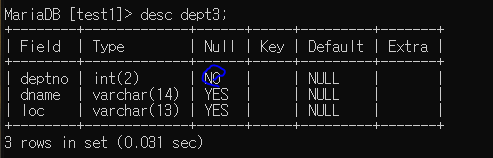
여기서 Null부분에 No는 Null을 넣을 수 없다(Yes는 가능)
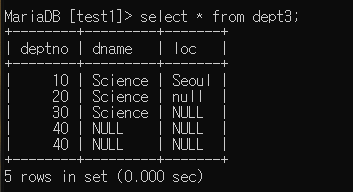
1. insert into dept3 values(10, 'Science', 'Seoul');
2. insert into dept3 values(20, 'Science', 'null'); --> 이 경우 Null이 아닌 순수 문자열이 들어감.
3. insert into dept3 values(30, 'Science', Null); --> Null
4. insert into dept3 (deptno) values (40);
5. insert into dept3 values(40, Null, Null); --> 4번과 5번은 결과값 동일(똑같은 기능)
deptno 부분에 Null을 넣을 시 나오는 에러
Default : 기본값
create table dept2 (
deptno int(2) default 90, dename varchar(14), loc varchar(13) );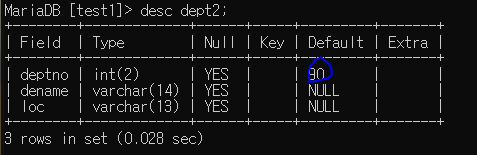
insert into dept2 values (default, 'Science' , 'Seoul'); --> 디폴트값 90 추가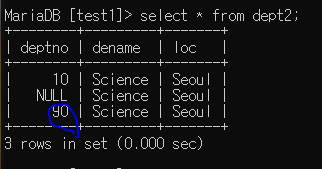
bulk insert
대량으로 insert 수행하게 해주는 문
insert into dept2 values (31, 'social', 'Busan'), (32, 'math', 'Tokyo');,를 통하여 여러가지를 삽입 가능하다.
다른 데이터베이스의 컬럼 내용 가져오기
bulk insert의 한 부분
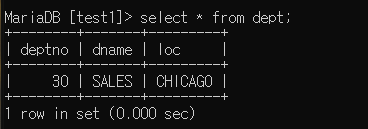
insert into dept select * from sample.dept where deptno = 30;sample.dept 에서 deptno = 30인 것만 가져와서 삽입함
update : 수정 (열을 수정하는 것)
update 테이블명 set 컬럼명 = 값 --> 컬럼내용 전체 변경
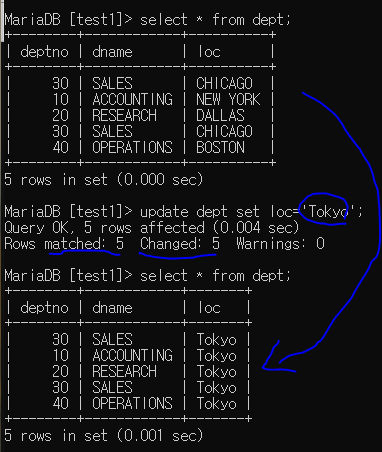
loc이 전부 Tokyo로 변경
update 테이블명 set 컬럼명 = 값 where 조건 --> 조건에 해당하는 것 변경
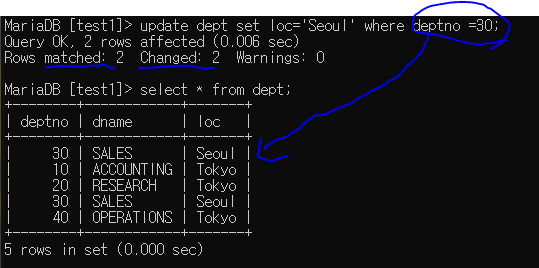
deptno = 30의 loc가 Seoul로 변경
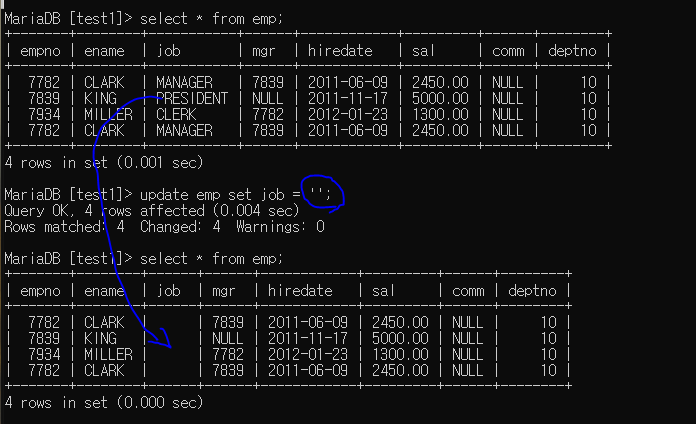
공백을 줘서 삭제하는 느낌 주기
응용 - emp 테이블 복사 후, 직책 clerk, 부서번호 20번인 사원 커미션 1000.0으로 변경
- emp 테이블 복사
- update 사용 ( 조건에 논리연산자 and 사용)
create table emp2 as select * from sample.emp;
update emp2 set comm = 1000.0 where job = 'CLERK' and deptno = 20;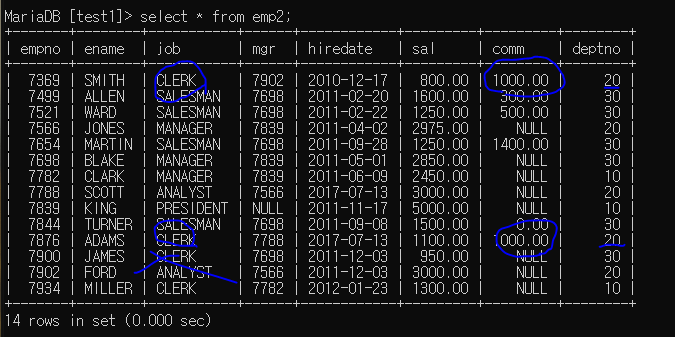
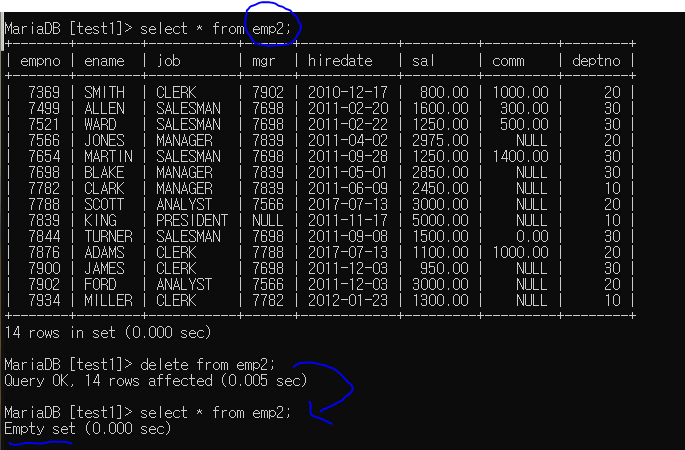
delete : 삭제 (행을 지우는 것)
update와 헷갈리는 것 주의
delete from 테이블명; --> 테이블 전체의 내용
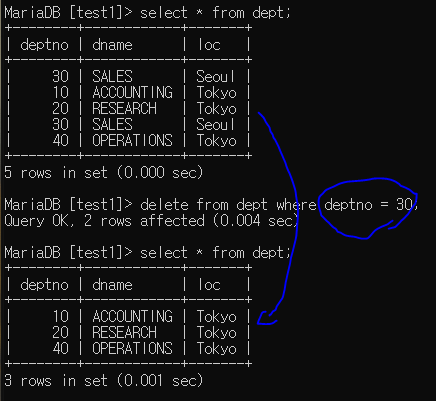
delete from 테이블명 where 조건; --> 특정행 삭제
constraint : 제약조건
제약조건 - 테이블에 입력할 데이터 제한
-
필수 입력 - not null
-
중복 방지 - unique
-
필수 + 중복 - primary key (테이블당 1개, auto_increment 사용 가능)
-
참조 - foreign key
값에 대한 검사 - check (mariadb에는 없다)
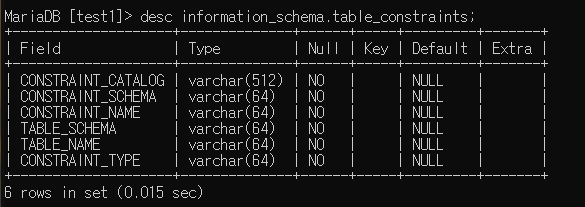
constraint를 규정한 테이블 보기 (제약 조건 확인하기)
desc information_schema.table_constraints;
select constraint_name, table_schema, table_name, constraint_type
from information_schema.table_constraints
where constraint_schema = 'sample'; --> 여기서 sample은 데이터베이스명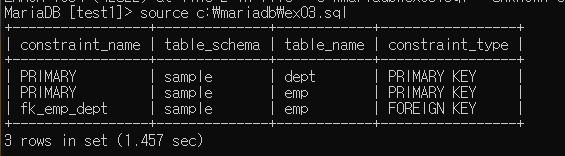
- 기술 방식
테이블 단위 제약 조건
-> 테이블 선언
제약 조건
컬럼 단위 제약 조건
-> 컬럼 선언 제약 조건
not null : 필수 입력
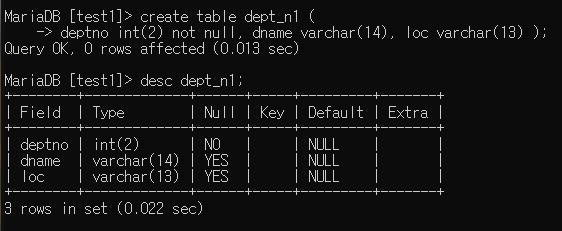
not null 제약 조건이 있는 테이블 생성

not null까지는 제약 조건이 안 뜬다.
unique : 중복 방지 (테이블 단위 제약 조건)
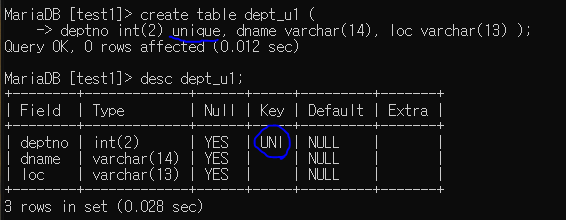
유니크 제약 조건이 있는 테이블 생성
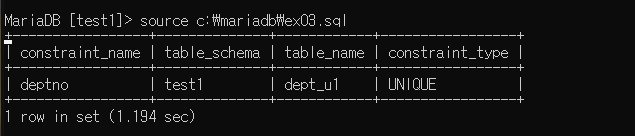
제약 조건이 확인된다.
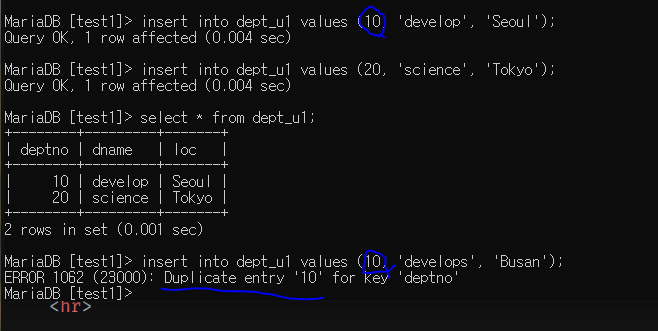
중복이 방지되는 모습
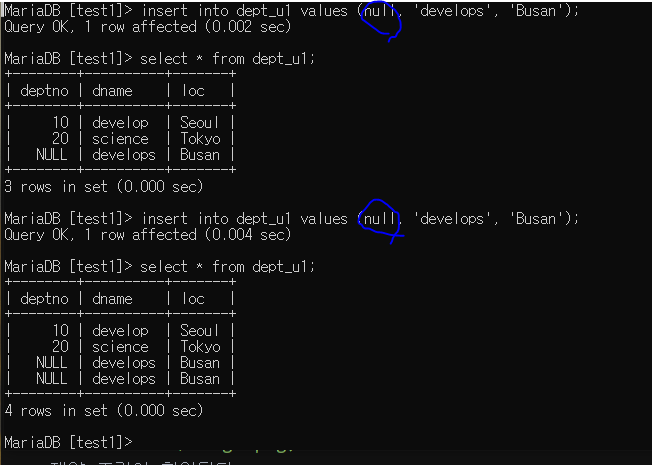
null은 중복을 포함함
unique : 중복 방지 (컬럼 단위 제약 조건)
create table dept_u2 (
deptno int(2), dname varchar(14), loc varchar(13), constraint unique (deptno) ); --> 조금 다른 선언 방식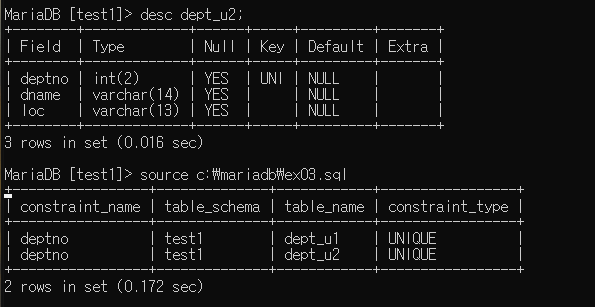
테이블 생성 + 제약 조건 잡힌 모습
constraint_name 이름 변경하기
create table dept_u3 (
deptno int(2), dname varchar(14), loc varchar(13), constraint dept_u3_deptno_uk unique (deptno) ); --> constraint ~ unique 사이에 바꿀 네임 쓰기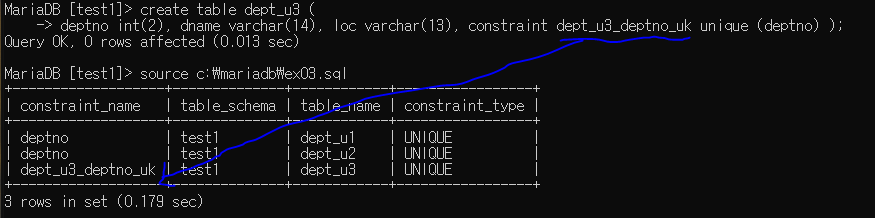
primary key(테이블 당 1개) : 필수 + 중복
create table dept_p1 (
deptno int(2) primary key, dname varchar(14), local varchar(13) );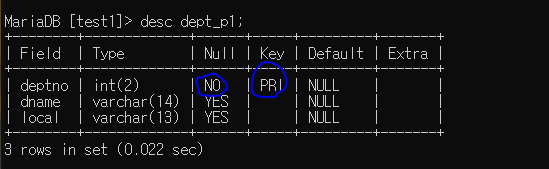
not null + 중복 방지 같이 적용
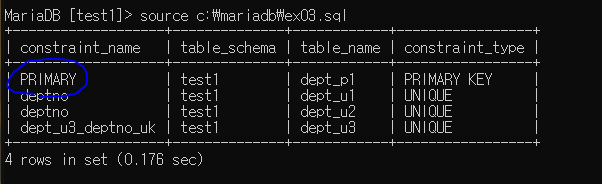
조건 제약 상태 확인
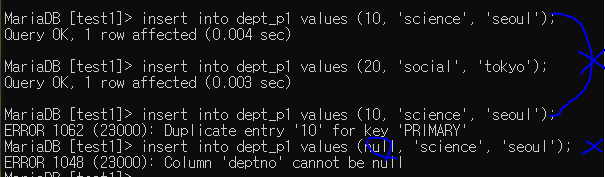
중복과 null이 추가가 안 되는 모습
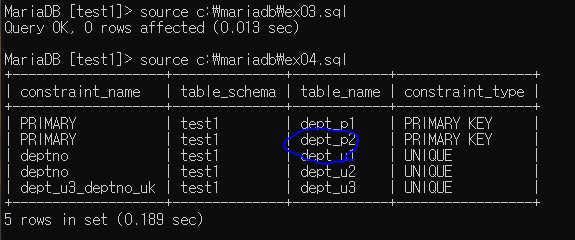
primary 컬럼 단위 제약
create table dept_p2 (
deptno int(2),
dname varchar(14),
loc varchar(13),
constraint primary key (deptno)
);
auto_increment : 데이터 1씩 자동 증가
데이터를 추가할 때마다 1씩 자동증가한다.
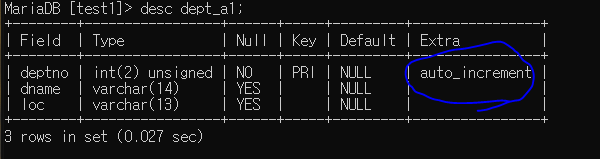
create table dept_a1 (
deptno int(2) unsigned primary key auto_increment,
dname varchar(14),
loc varchar(13),
constraint primary key (deptno)
);
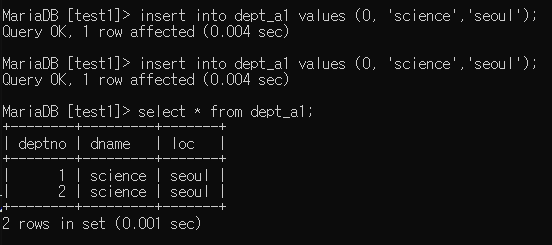
0이나 null을 넣어주면 0이 들어가는 게 아니라 값을 1 증가시켜줌(그래서 1, 2가 나온 것)
0을 넣어도 값이 증가하는 상태니 중복이 아닌 상태
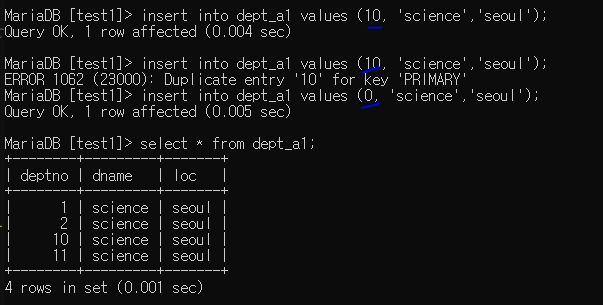
10은 값이므로, 중복되어 들어갈 수 없고, 이후 0을 넣어주면 10 기준부터 1을 추가해준다.
