
📖 JOIN & SubQuery & DB 모델링
📌 JOIN
✅ JOIN?
-
둘 이상의 테이블에서 테이블을 조회하기 위해서 사용
-
일반적으로 조인 조건은 PK(Primary Key), FK(Foregin Key)로 구성된다.
-
PK 및 FK 관계가 없더라도 논리적인 연관만으로도 JOIN 가능
-
JOIN의 종류
-
INNER JOIN : 조인 조건에 해당하는 칼럼 값이 양쪽 테이블에 모두 존재하는 경우에만 조회
- 동등 조인(Equi-join) 이라고도 한다.
- N개의 테이블 조인 시 N-1개의 조인 조건이 필요
-
OUTER JOIN : 조인 조건에 해당하는 칼럼 값이 한 쪽 테이블에만 존재하더라도 조회 기준 테이블에 따라 LEFT OUTER JOIN, RIGHT OUTER JOIN으로 구분
-
✅ 카타시안 곱 (Cartesian Product)
- 두 개 이상의 테이블에서 데이터를 조회할 때
- 조인 조건을 지정하지 않음
- 조인 조건이 부적합 함
- 첫 번째 테이블의 모든 행이 두 번째 테이블의 모든 행에 조인되어 처리됨.
SELECT empno, ename, job, emp.deptno, dept,deptno, dname
FROM emp, dept;✅ INNER JOIN
- 두 테이블에서 일치하는 값을 가진 레코드 조회
SELECT column_name(s)
FROM table1
INNER JOIN table2
ON table1.column_name = table2.column_name;- on : 조인 조건
SELECT e.ename, e.job, e.depno, d.dname
FROM emp e
INNER JOIN dept d
ON e.depno = d.deptno
WHERE e.empno = 7788;-
using 알아보기
-
INNER JOIN을 쓰지 않고 WHERE 절 만으로도 INNER JOIN 가능
SELECT column_name(s)
FROM table1, table2
WHERE table1.column_name = table2.column_name;✅ OUTER JOIN
-
두 테이블에서 하나의 테이블에 조인 조건 데이터가 존재하지 않더라도 데이터를 조회하기 위해 사용
-
기준 테이블에 따라 LEFT OUTER JOIN (LEFT JOIN), RIGHT OUTER JOIN(RIGHT JOIN)으로 구분
✅ 셀프 조인 (SELF JOIN)
- 같은 테이블 2개를 조인
✅ 비 동등 조인 (Non-Equi JOIN)
- 조인 조건이 table의 PK, FK 등으로 정확히 일치하는 것이 아닐 때 사용
📌 SubQuery
✅ 서브 쿼리 (Subquery)란?
-
서브 쿼리란 하나의 SQL 문안에 포함되어 있는 SQL문을 의미한다.
-
서브 쿼리를 포함하는 SQL을 외부 쿼리(outer query) 또는 메인 쿼리라고 부르며, 서브 쿼리는 내부 쿼리 (inner query) 라고도 부른다.
✅ 서브 쿼리의 종류
-
중첩 서브 쿼리 (Nested Subquery) - WHERE 절에 작성하는 서브 쿼리
- 단일행, 다중행, 다중열
-
인라인 뷰 (Inline-view) - FROM 절에 작성하는 서브 쿼리
-
스칼라 서브 쿼리 (Scalar Subquery) - SELECT 문에 작성하는 서브 쿼리
✅ 서브 쿼리를 포함할 수 있는 SQL문
-
SELECT, FROM, WHERE, HAVING, ORDER BY
-
INSERT문의 VALUES
-
UPDATE문의 SET
✅ 서브 쿼리의 사용시 주의 사항
-
서브 쿼리는 반드시 ()로 감싸서 사용한다.
-
서브 쿼리는 단일 행 또는 다중 행 비교 연산자와 함께 사용 가능하다.
- 단일 행 비교연산자는 서브 쿼리 결과가 1건 이하이어야 하고, 복수 행 비교 연산자는 결과 건수와 상관 X
✅ 서브 쿼리 - 상호연관 서브 쿼리 (Correlated Subqueries)
- 외부 쿼리에 있는 테이블에 대한 참조를 하는 서브 쿼리를 의미
SELECT *
FROM t1
WHERE column1 = ANY (SELECT column1 FROM t2
WHERE t2.column2 = t1.column2);-
서브 쿼리의 FROM에는 t1에 대한 선언이 존재하지 않는다. 따라서 서브 쿼리는 외부 쿼리에서 t1을 참조한다.
-
테이블에서 행을 먼저 읽어서 각 행의 값을 관련된 데이터와 비교하는 방법 중 하나이다.
-
기본 질의에서 고려된 각 후보행에 대해 서브 쿼리가 다른 결과를 반환해야 하는 경우 사용한다
-
서브 쿼리에서는 메인 쿼리의 컬럼명을 사용할 수 있으나, 메인 쿼리에서는 서브 쿼리의 컬럼명을 사용할 수 없다.
✅ 서브 쿼리 - 인라인 뷰 (Inline View)
-
FROM 절에서 사용되는 서브 쿼리
-
동적으로 생성된 테이블로 사용 가능하다. 뷰(View)와 같은 역할
SELECT ... FROM (subquery)[AS] tbl_name(col_list) ...- 인라인 뷰는 SQL 문이 실행될 때만 임시적으로 생성되는 뷰 이기 때문에 데이터베이스에 해당 정보가 저장되지 않는다. 그래서 동적 뷰(Dynamic View)라고도 한다.
Top-N은 생략. 공부하면 좋고
✅ 서브 쿼리 - 스칼라 서브 쿼리 (Scalar Subquery)
-
하나의 행에서 하나의 컬럼 값만 반환하는 서브 쿼리
-
아래 경우 사용 가능
- group by를 제외한 select의 모든 절- insert 문의 values
- 조건 및 표현식 부분
- update 문의 set 또는 where 절에서 연산자 목록
✅ 서브 쿼리
-
서브 쿼리를 이용한 CREATE 문
-
emp table을 emp_copy라는 이름으로 복사 (컬럼 이름 동일)
CREATE TABLE emp_copy (SELECT * from emp);- emp table 구조만 emp_blank라는 이름으로 복사하여 생성
CREATE TABLE emp_blank (SELECT * FROM emp WHERE 1 = 0);📌 데이터베이스 모델링
✅ DataBase Modelling
- 모델링 : 실생활을 DB로 옮기는 것
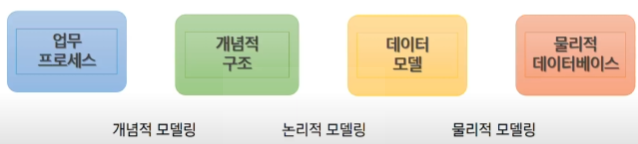
✅ 개념적 데이터베이스 모델링 과정
-
사용자 부문의 처리 현상 분석
-
중요 실체(Entity)와 관계(Relation)를 파악하여 ERD 작성
-
실체에 대한 상세 정의
-
식별자 정의 및 식별자 업무규칙 지정
-
실체별 속성 상세화
-
필요한 속성 및 영역 상세 정의
-
속성에 대한 업무규칙 정의
-
각 단계를 마친 후 사용자와 함께 모델 검토
✅ ERD (Entity Relation Diagram)
- 기호

- 예시
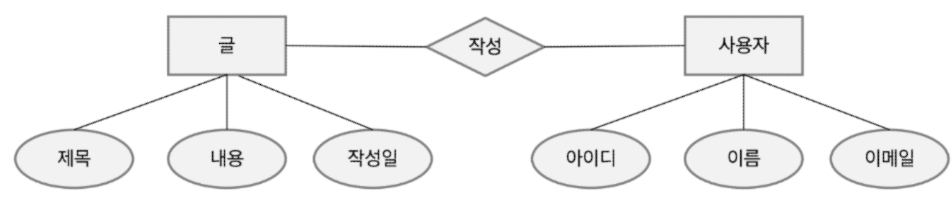
- 목업 툴 : draw.io
✅ 개념적 데이터베이스 모델링
-
개체 (Entity) : 사용자와 관계가 있는 주요 객체 (데이터로 관리 되어야 하는 것)
-
Entity 찾는 법
- 영속적으로 존재하는 것
- 새로 식별이 가능한 데이터 요소를 가짐
- Entity는 Attribute를 가져야 함.
-
속성 (Attribute)
- 저장할 필요가 있는 실체에 관한 정보
- 개체(Entity)의 성질, 분류, 수량, 상태, 특성 등을 나타내는 세부 사항
- 개체에 포함되는 속성의 숫자는 10개 내외가 바람직
- 최종 DB 모델링 단계를 통해 테이블의 컬럼으로 활용
- 기초 속성
- 추출 속성
- 단일 속성
- 다중 속성
-
식별자 : 한 개체(Entity) 내에서 인스턴스를 구분할 수 있는 단일 속성 또는 속성 그룹
-
후보키 (Candidate Key) : 개체 내에서 각각의 인스턴스를 구분할 수 있는 속성 (기본 키가 될 수 있음)
-
기본 키 (Primary Key) : 개체에서 각 인스턴스를 유일하게 식별하는데 적합한 Key
-
대체키 (Alternative Key) : 후보키 중에서 기본 키로 선정 되지 않은 Key
-
복합키(Comosite Key) : 하나의 속성으로 기본키가 될 수 없는 경우 둘 이상의 컬럼을 묶어 식별자로 정의
-
대리키 (Surrogate Key) : 식별자가 너무 길거나 여러 개의 속성으로 구성되어 있는 경우 인위적으로 추가
-
관계 (Relationship) : 두 Entity 간 업무적 연관성 또는 관련 사실
-
각 Entity 간에 특정한 존재 여부 결정
-
현재의 관계 뿐 아니라 장래에 사용될 경우도 고려
✅ ERD 관계 설정 순서
- 관계가 있는 두 실체를 실선(점선)으로 연결하고 관계를 부여
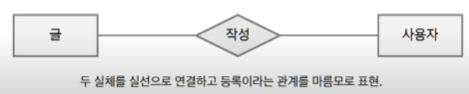
- 관계 차수 표현

- 선택성 표시
✅ 논리적 데이터베이스 모델링
- 개념적 데이터베이스 모델링 단계에서 정의된 ERD를 Mapping Rule을 적용하여 관계형 데이터베이스 이론에 입각한 스키마를 설계하는 단계와 이를 이용하여 필요하다면 정규화하는 단계로 구성
- 기본 키 (Primary Key, PK)
- 후보 키 중에서 선택한 주 키
- Null 가질 수 없다 (Not Null)
- 동일한 값이 중복해서 저장될 수 없다 (Unique)
- 참조키, 이웃키 (Foreign Key)
- 관계를 맺는 두 엔티티에서 서로 참조하는 릴레이션의 attribute로 지정되는 키
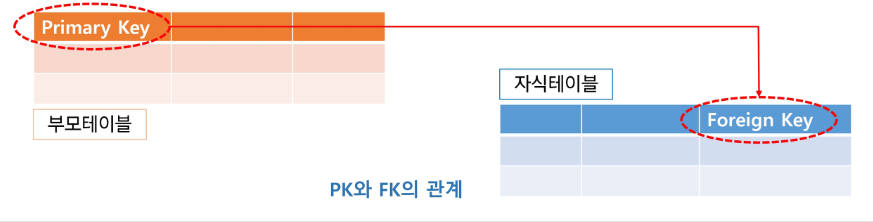
✅ Mapping Rule
- 개념적 데이터베이스 모델링에서 도출된 개체 타입과 관계 타입의 테이블 정의
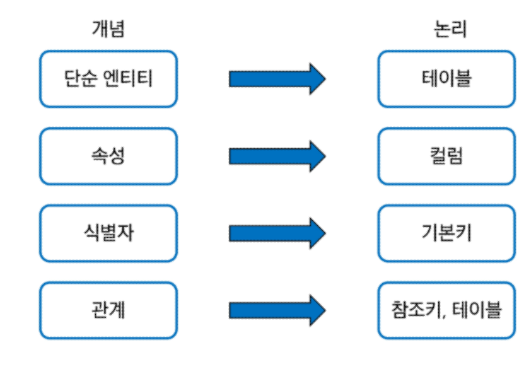
✅ 정규화
-
관계형 데이터베이스 설계에서 중복을 최소화하게 데이터를 구조화 하는 프로세스
-
목적
- db 변경 시 이상 현상 제거
- db 구조 확장 시 재 디자인 최소화
- 사용자에게 db 모델을 더욱 의미있게 작성하도록 함
- 다양한 질의 지원
-
제 1 정규화 (Atomic Columns)
-
제 2 정규화 (부분함수 종속 제거)
-
제 3 정규화 (이행적 함수 종속 제거)
✅ 물리적 데이터베이스 모델링
-
논리적 데이터베이스 모델링 단계에서 얻어진 db 스키마를 좀더 효율적으로 구현하기 위한 작업
-
DBMS 특성에 맞게 실제 db 내의 개체들을 정의하는 단계
- Column의 domain 설정 (int, varchar, date ...)
-
데이터 사용량 분석과 업무 프로세스 분석을 통해 보다 효율적 db가 될 수 있도록 인덱스를 정의하고 상황에 따른 역정규화 작업을 수행
- Index, Trigger, 역정규화
-
역정규화 (Denomalization)
- 시스템 성능을 고려하여 기존 설계 재구성
- 정규화에 위배되는 행위
- 테이블 재구성
-
역정규화 방법
- 데이터 중복 (컬럼 역정규화)
- 파생 컬럼의 생성
- 테이블 분리
- 요약 테이블 생성
- 테이블 통합
