
📖 DataBase & SQL
📌 DataBase
✅ 데이터베이스란?
-
여러 사람이 공유하고 사용할 목적으로 통합 관리되는 정보의 집합
-
논리적으로 연관된 하나 이상의 자료의 모음으로, 그 내용을 고도로 구조화 함으로써 검색과 갱신의 효율화를 노린 것
-
몇 개의 자료 파일을 조직적으로 통합하여 자료 항목의 중복을 없애고 자료를 구조화하여 기억시켜 놓은 자료의 집합체
- 통합된 데이터 (Integrated Data)
- 각자 사용하던 데이터를 모아서 중복을 최소화하고 데이터 불일치를 제거
- 저장된 데이터 (Stored Data)
- 문서 형태로 보관되는 것이 아니라 저장장치 (디스크, 테이프 등 컴퓨터 저장장치)에 저장됨
- 운영 데이터 (Operational Data)
- 조직의 목적을 위해서 사용되는 데이터를 의미
- 공용 데이터 (Shared Data)
- 여러 사람이 각각 다른 목적의 업무를 위해서 공통으로 사용되는 데이터를 의미
- DB : 조직 또는 개인이 필요에 의해 논리적으로 연관된 데이터를 모아 일정한 형태로 저장한 것
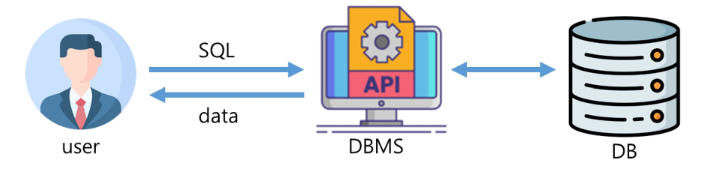
✅ DBMS(Database Management System)
- DBMS : 데이터베이스 관리 프로그램
- 데이터베이스 조작 인터페이스 제공
- 효율적 데이터 관리 기능 제공
- 데이터베이스 구축 기능 제공
- 데이터 복구, 사용자 권한부여, 유지보수 기능 제공
📌 관계형 데이터베이스 (Relational DB)
✅ 관계형 데이터베이스 (Relational DataBase)
-
테이블(Table) 기반의 Database
-
테이블(table)
- 실제 데이터가 저장되는 곳
- 행과 열의 2차원 구조를 가진 데이터 저장 장소
-
데이터를 테이블 단위로 관리
- 하나의 데이터(record)는 여러 속성(Attribute)을 가진다.
- 데이터 중복을 최소화
- 테이블 간의 관계를 이용하여 필요한 데이터 검색 가능
-
관계형 데이터베이스의 테이블 구조 - 행 or 레코드 / 열 or 속성
✅ 관계형 데이터베이스 관리 시스템 (Relational Database Management System)

📌 SQL(Structured Query Language)
✅ SQL
- 관계형 데이터 베이스에서 데이터 조작과 데이터 정의를 위해 사용하는 언어
- 데이터 조회
- 데이터 삽입, 삭제, 수정
- DB Object 생성 및 변경, 삭제
- DB 사용자 생성 및 삭제, 권한 제어
- 표준 SQL은 모든 DBMS에서 사용 가능
✅ SQL 특징
-
배우고 사용하기 쉽다
-
대소문자 구별 X (데이터 대소문자는 구분)
-
절차적 언어가 아닌 선언적 언어
-
DBMS에 종속적이지 않다
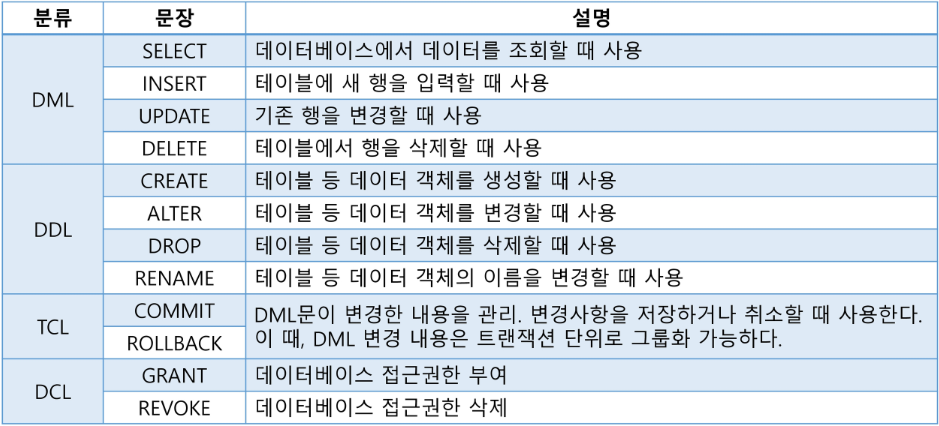
✅ SQL 종류
-
DML(Data Manipulation Language : 데이터 조작 언어)
- DB에서 데이터를 조작하거나 조회할 때 사용
- 테이블의 레코드를 CRUD (Create, Read, Update, Delete)
-
DDL(Data Definition Language) : 데이터 정의 언어
- DB 객체(table, view, user, index 등)의 구조를 정의
-
DCL(Data Control Language) : 데이터 제어 언어
- DB, Table 접근 권한이나 CRUD 권한 정의
- 특정 사용자에게 테이블의 검색 권한 부여 / 금지
-
TCL(Transaction Control Language) : 트랜잭션 제어 언어
- 트랜잭션 단위로 실행한 명령문을 적용하거나 취소
📌 DDL (Data Definition Language)
✅ DB 생성
CREATE DATABASE databasename;-
새 DB를 생성하는 데 사용
-
DB는 여러 테이블을 포함
-
DB 생성 시 관리자 권한으로 생성
-- DB 생성 후, 다음 명령어를 이용해 DB의 목록을 확인할 수 있다.
SHOW DATABASES;✅ DB 문자 집합(Character set) 설정하기
-
DB 생성 시 설정 또는 생성 후 수정 가능
-
문자집합은 각 문자가 컴퓨터에 저장될 때 어떤 코드로 저장되는지 규칙을 지정한 집합
-
Collation은 특정 문자 집합에 의해 DB에 저장된 값들을 비교, 검색, 정렬 등의 작업을 수행할때 사용하는 비교 규칙 집합이다.
CREATE DATABASE db_name
[[DEFAULT]CHARACTER SET charset_name]
[[DEFAULT]COLLATE collation_name]
ALTER DATABASE db_name
[[DEFAULT]CHARACTER SET charset_name]
[[DEFAULT]COLLATE collation_name]✅ DB 삭제
-
DB의 모든 테이블을 삭제하고 DB 삭제
-
삭제 시, DROP DB 권한 필요
-
DROP SCHEMA는 DROP DATABASE와 동의어
-
IF EXISTS는 DB가 없을 시 발생할 수 있는 에러를 방지
DROP {DTABASE | SCHEMA} [IF EXISTS] db_name✅ DB 사용
- DB가 있는 경우 (접근 권한이 있는 경우), USE 명령어를 이용하여 사용
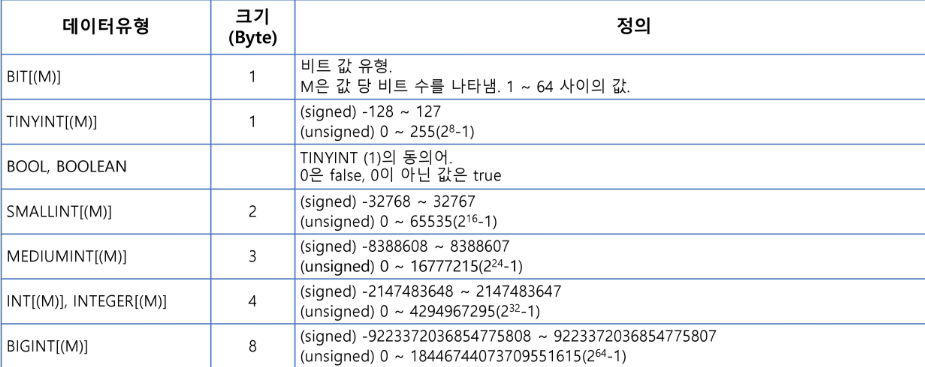
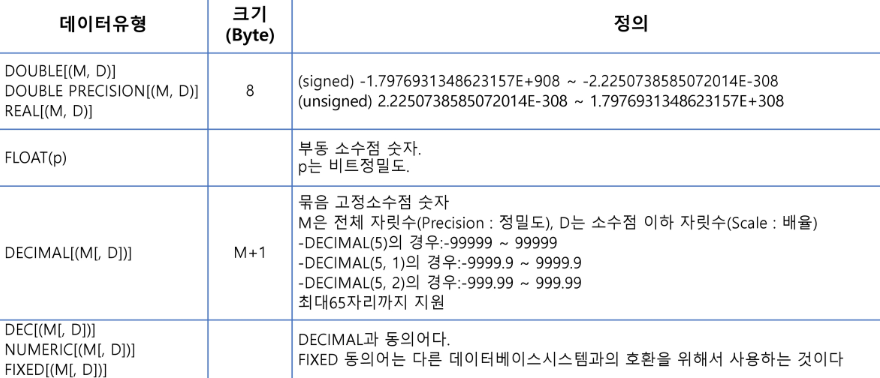
USE databasename;✅ 숫자 자료형 (Numeric Data Types)
✅ 문자 자료형 (String Data Types)

✅ 날짜 자료형 (Date and Time Data Types)

✅ 바이너리 데이터 타입 (Date and Time Data Types)

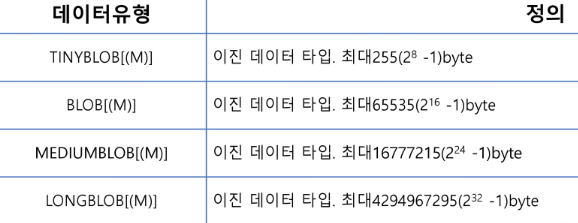
✅ BLOB and TEXT 타입
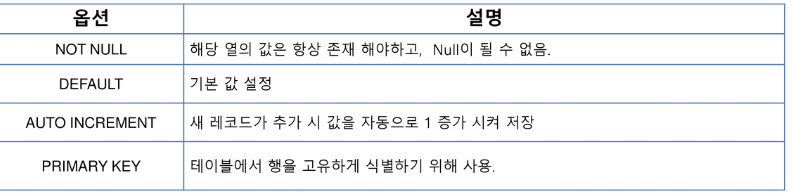
✅ 테이블(Table) 생성하기
CREATE TABLE table_name (
column1 datatype [options],
column2 datatype,
coloumn3 datatype,
...
);- 자주 사용하는 옵션
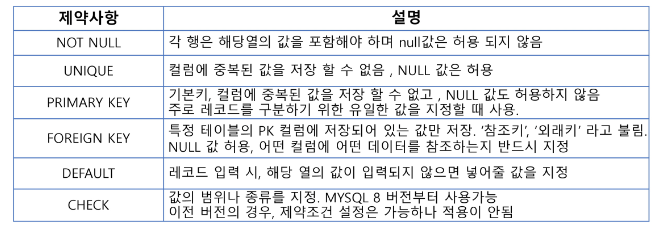
✅ 제약조건 (CONSTRAINT)
-
컬럼에 저장될 데이터의 조건을 설정
-
제약조건에 위배되는 데이터는 저장 불가
-
테이블 생성 시 컬럼에 지정하거나, constraint로 지정 가능 (ALTER를 이용하여 설정 가능)
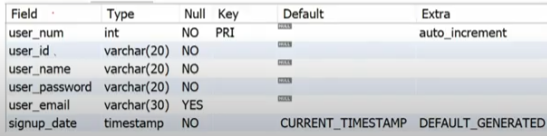
✅ 테이블 (Table) 스키마
- 스키마(Schema) : 테이블에 저장될 데이터의 구조와 형식
✅ 테이블(Table) 스키마 확인하기
- DESCRIBE 또는 DESC 명령어를 이용ㅇ하여 생성된 테이블 스키마 확인
{DESCRIBE | DESC} table_name;
📌 DML (Insert, Update, Delete)
✅ DML (Data Manipulation Language)
- 데이터베이스에 데이터를 삽입, 조회, 수정, 삭제할 때 사용

✅ INSERT 문
-
생성 시 작성한 모든 컬럼에 입력 값이 주어지면 컬럼 이름 생략 가능
-
컬럼 이름과 입력 값의 순서가 일치하도록 작성 (NULL, DEFAULT, AUTO INCREMENT 설정 필드 생략 가능)
✅ UPDATE 문
-
기존 레코드 수정
-
WHERE 절을 이용해 하나의 레코드 또는 다수의 레코드를 한 번에 수정 가능
UPDATE table_name
SET col_name = value[, col_name2 = value2, ....]
[WHERE where_condition];-
WHERE 절을 생략하면 테이블의 모든 행이 수정된다.
-
이거 safe mode때문에 안되는데 체크 풀고 껏다켜야됨
✅ DELETE 문
-
기존 레코드를 삭제
-
WHERE 절을 이용해 하나의 레코드 또는 다수의 레코드를 한 번에 삭제할 수 있다.
DELETE FROM tbl_name
[WHERE where_condition];- 오토 커밋 모드? 확인
📌 DML (Select)
✅ SELECT 문
-
테이블에서 레코드를 조회하기 위해 사용
-
조회 시 컬럼 이름이나 표현식을 조회할 수 있고 별칭(alias) 사용가능
-
*은 모든 속성 조회 -
WHERE 조건식을 이용하여 원하는 레코드 조회 가능
SELECT [DISTINCT] {* | column_name | expressions[alias]}
FROM table_references
[WHERE where_condition]
[GROUP BY {col_name | expr | position},]
[HAVING where_condition]
[ORDER_BY {col_name | expr | position}[ASC | DESC]]
[LIMIT{[offset], row_count | row_count OFFSET offset}]✅ 기본 SELECT 문
SELECT
FROM✅ 기본 SELECT 문 - 별명(alias), 사칙연산
-
as를 이용하여 조회 시 컬럼이름 변경 가능 (띄어쓰기 포함 시 ""으로 묶어준다)
- as 키워드 생략 가능
-
사칙연산 사용 가능, NULL 값 계산 불가
-
IFNULL 함수를 이용하여 NULL 값 처리 - IFNULL (exp1, exp2) : exp1이 NULL이면 exp2 return
✅ 기본 SELECT 문 - CASE Function
CASE
WHEN condition1 THEN result1
WHEN condition2 THEN result2
ELSE result
END;-
CASE 문은 조건을 통과하고 첫 번째 조건이 충족될 때 값을 반환
-
조건이 충족되지 않으면 ELSE 절의 값을 반환한다.
✅ WHERE 절
- WHERE 절은 조건에 맞는 레코드를 조회하기 위해서 사용한다.
SELECT column1, column2, ...
FROM table_name
WHERE condition;-
WHERE 절은 SELECT 문장 뿐만 아니라, UPDATE, DELETE 등 다른 문장에서도 사용됨을 기억하자!
-
AND : &&
-
OR : ||
-
not equal : !=, <>
- 표준은 <>
-
NOT : 조건문이 NOT TRUE일 때 레코드 조회
-
IN : 피연산자가 여러 표현 중 하나라도 같다면 TRUE
-
BETWEEN : 값이 주어진 범위의 범위 안에 있으면 조회
- 값은 숫자나, 문자, 날짜가 될 수 있다.
WHERE column_name BETWEEN value1 AND value2;- NULL 비교 : IS NULL, IS NOT NULL
- 값이 NULL인지 NULL이 아닌지 검사하기 위해 사용
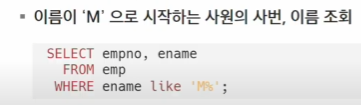
✅ SELECT - LIKE
-
LIKE - WHERE 절에서 칼럼의 값이 특정 패턴을 가지는지 검사하기 위해 사용
-
와일드 카드
(%_)를 이용하여 패턴 표현- % : 0개 이상의 문자 의미
- _ : 문자 하나를 의미

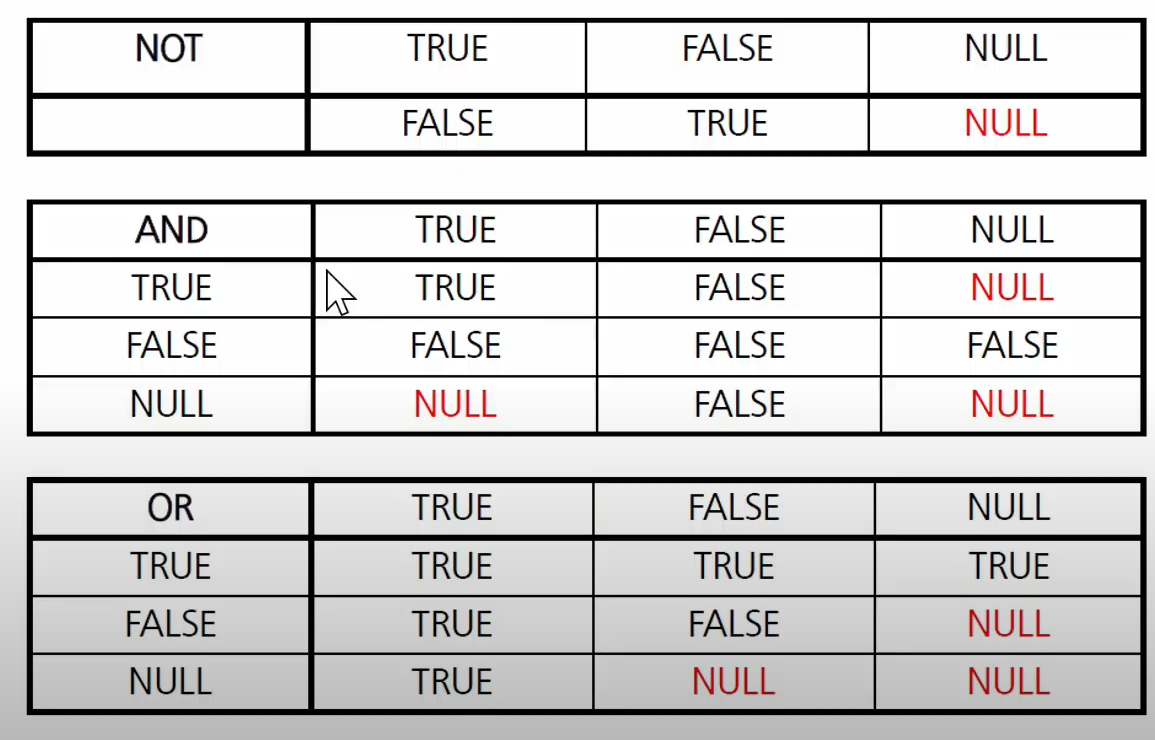
✅ 논리 연산자
-
NOT
-
AND
-
OR
✅ ORDER BY
-
조회 결과를 오름차순(ASC) 또는 내림차순(DESC)으로 정렬할 때 사용
- default : ASC
-
정렬 기준 칼럼을 지정할 수 있다.
SELECT column1, column2, ... ASC | DESC;📌 MySQL 내장 함수
✅ MySQL 내장 함수
-
MySQL은 많은 내장 함수를 가지고 있다.
-
문자열, 숫자, 날짜, 그 외에 대해서 다양한 함수를 제공한다.
- 숫자 관련 함수
- 문자 관련 함수
- 날짜 관련 함수
- 논리 관련 함수
- 그룹 함수
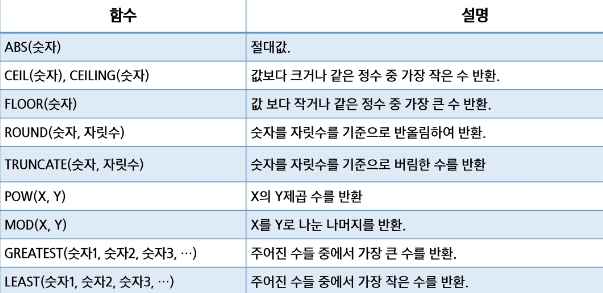
✅ 숫자 관련 함수 (Numeric Functions)
✅ 문자 관련 함수 (String Functions)


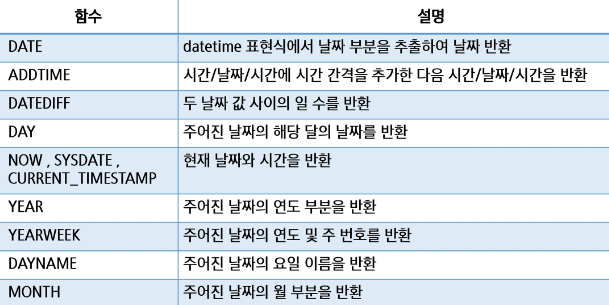
✅ 날짜 관련 함수 (Date Functions)
✅ 그 외 중요 함수

✅ 집계 함수 (Aggregate Function)
-
여러 값의 집합(복수 행)에 대해서 동작한다. (복수 행 함수, 통계 함수, 그룹 함수)
-
GROUP BY 절과 함께 사용하여 전체 집합의 하위 집합을 그룹화한다.

- MySQL에서는 GROUP BY로 묶이지 않은 칼럼을 조회할 때 무의미한 데이터가 조회될 수 있으니 유의
✅ 집계 함수 - HAVING 절
-
집계 함수의 결과 내에서 조건문에 맞는 레코드를 조회
-
문법 순서 : SELECT -> FROM -> WHERE -> GROUP BY -> HAVING -> ORDER BY
-
실행 순서 : FROM -> ON -> JOIN -> WHERE -> GROUP BY -> HAVING -> SELECT -> DISTINCT -> ORDER BY
✅ Transaction
- 트랜잭션(Transaction)
- 커밋(Commit) 하거나 롤백(Rollback) 할 수 있는 가장 작은 작업 단위

- MySQL에서는 기본적으로 세션이 시작하면 autocommit 설정 상태
- 그러므로 MySQL은 각 SQL 문장이 오류를 반환하지 않으면 commit을 수행한다.
