Paper : https://arxiv.org/abs/2211.06892
Github : https://github.com/shivammehta25/OverFlow
Abstract
Neural HMM은 TTS의 sequence-to-sequence 모델링을 위해 최근 제안된 neural transducer의 한 종류다. 이는 고전적인 통계적 음성 합성과 최신 신경망 기반 TTS의 장점을 결합하여 데이터와 학습 업데이트가 적게 필요하며, 신경망 attention의 실패로 인해 횡설수설하는 결과를 줄일 수 있다.
음성 음향의 높은 non-Gaussian 분포를 설명하기 위해 Neural HMM TTS와 정규화 플로우를 결합한다. 결과적으로, 정확한 maximum likelihood를 사용하여 훈련할 수 있는 강력하고 완전한 확률 모델이 만들어진다. 실험 결과 본 논문의 제안에 기반한 시스템은 정확한 발음과 자연어에 가까운 주관적인 음성 품질을 생성하기 위해 유사한 방법보다 적은 업데이트를 요구한다.
1. Introduction
Sequence-to-sequence neural text-to-speech 가 전통적인 neural attention을 neural hidden Markov model 또는 neural transducer의 일종인 neural HMM으로 대체함으로써 개선될 수 있음이 최근에 입증되었다.
Hidden Markov Model, HMM
: 시간에 따라 변하는 숨겨진 상태(hidden state)를 가진 확률적 모델이다. 현재 상태가 이전 상태에만 의존하며, 현재 상태에서 관찰 가능한 결과를 생성한다. 주로 순차적 데이터 분석에 사용되며, 음성 및 텍스트와 같은 시계열 데이터를 모델링하는 데 유용하다.
결과적인 모델 클래스는 전통적인 HMM 기반 TTS와 현대적인 neural sequence-to-sequence 모델의 좋은 특성을 결합한다.
- 완전히 확률적이다.
- 정확한 sequence likelihood를 최대화하기 위해 훈련될 수 있다.
- 왼쪽에서 오른쪽으로 건너뛰지 않는 HMM을 사용하여 입력의 각 단음이 올바른 순서로 발음되는 monotonic 특성이 보장된다.
이것은 많은 attention 기반 neural TTS 모델들이 무작위로 횡설수설하는 경향이 있는 non-monotonic attention으로 인한 문제와 올바르게 말하는 방법을 배우기 위해 많은 양의 데이터와 업데이트를 필요로 하는 문제를 직접적으로 해결한다.
non-monotonic attention
: 기계 번역 및 음성 합성과 같은 작업에서 발생하는 문제다. attention 메커니즘은 모델이 입력의 특정 부분에 집중할 수 있도록 하는 데 사용된다. 그러나 non-monotonic attention은 출력이 입력의 순차적인 부분과 일치하지 않을 수 있음 을 의미한다. 즉, 모델이 결과를 생성할 때 입력의 순서를 따르지 않을 수 있다. 이는 번역이나 음성 합성에서 문제를 일으킬 수 있으며, 이상적으로는 입력과 출력 간에 일관된 순서가 유지되어야 한다.
제한된 병렬 처리를 가진 장치에서 순차적인 특성을 가지는 autoregressive synthesis가 유리하며, TTS의 점진적 및 스트리밍되는 응용 프로그램에도 잘 적용된다.
그러나 neural HMM 프레임워크를 기반으로 한 TTS는 아직 전체 잠재력을 보여주지 못했다. 특히, 기존의 모델들은 상태 조건부 발산 분포가 가우시안(L2 손실) 또는 라플라스(L1 손실)인 제한적인 가정을 포함한다. 자연스러운 음성 신호는 매우 복잡한 확률 분포를 따르기 때문에 인간의 음성 생성에 약한 모델이 생성된다.
본 논문에서는 OverFlow를 제시한다. 음성 파라미터 궤적의 비가우시안 분포를 더 잘 설명하기 위해 neural HMM TTS 위에 정규화 플로우를 추가했다. 이는 음향 및 지속시간의 완전한 확률적 모델을 제공하며, 대부분의 플로우 기반 음향 모델과 달리 autoregression을 사용하여 장거리 메모리를 활성화한다.
실험 결과 이 모델은 정확한 발음과 좋은 합성 품질을 빠르게 학습하며, 관련된 접근 방식인 Tacotron 2 및 Glow-TTS를 기반으로 한 유사한 시스템을 능가한다.
2. Prior work
2.1. TTS with transducers and neural HMMs
Neural HMM
상태 조건부 발산 분포와 전이 확률이 모두 신경망에 의해 정의된 autoregressive HMM의 한 종류다. 이는 고전적인 HMM보다 훨씬 강력하다. 이 모델들의 가장 간단한 버전은 왼쪽에서 오른쪽으로 건너뛰지 않는 HMM을 나타내므로 monotonic하다.
이러한 모델은 여전히 전통적인 hidden Markov 가정을 만족하기 때문에, 다음과 같은 과정으로 학습이 가능하다:
- 순방향 또는 Viterbi 알고리즘(또는 하한을 정의하여)을 사용하여 log likelyhood를 효율적으로 계산
- 자동 미분 위에 확률적 경사 상승을 사용하여 최적화
이러한 방법은 autoregressive TTS에 매력적인 선택지다.
Viterbi 알고리즘
: 동적 프로그래밍의 한 형태로, 최적 경로를 찾는 데 사용되는 알고리즘이다. HMM과 같은 시스템에서 관측된 데이터의 시퀀스를 기반으로 가장 가능성이 높은 숨겨진 상태(또는 상태 시퀀스)를 찾는 데 사용된다. 이 알고리즘은 모든 가능한 상태 시퀀스에 대해 가능성을 계산하고, 가장 가능성이 높은 시퀀스를 선택하는 최적 경로를 찾아낸다.
Neural transducer
수학적으로, neural HMM은 neural transducer의 한 종류다. Neural transducer는 최근 몇 년간 강력한 자동 음성 인식 성능으로 알려져 있다.
-
SSNT-TTS : TTS에 사용되었다. 본 논문의 접근 방식은 이와 달리 확률적이다.
-
Speech-T : 단일 모델 내에서 ASR 및 스트리밍 TTS를 처리하는 것으로 나타났다. 본 논문은 이와 달리 보다 일관된 음성-소리 지속 시간을 위해 분위수 기반의 지속 시간 생성을 통합한다.
가장 중요한 것은 이러한 유형의 모델에 정규화 플로우를 통합하여 음성 음향의 행동을 설명할 수 있는 강력한 확률적 프레임워크를 얻는 것이다.
2.2. Normalising flows in TTS acoustic modelling
Normalising flow
딥러닝을 사용하여 확률 분포의 매우 유연한 매개변수화된 군집을 정의한다. 이 아이디어는 신경망 기반의 비선형적이고 가역적인 변환을 통해 단순한 가우시안에서 복잡한 확률 분포를 만드는 것이다. 가역성은 변수 변환 공식을 사용하여 생성된 모델의 likelyhood를 계산하고 최대화하는 데 사용될 수 있음을 의미한다.
Normalising flow는 음성 기술 전반에 걸쳐 많은 응용 분야를 본 것으로, 최초로 이를 통합한 TTS 음향 모델은 Flowtron과 Flow-TTS다. 그 후에는 Glow-TTS, RAD-TTS 및 EfficientTTS가 이어졌다.
-
Flowtron : Tacotron 2를 확장한 것으로, 여러 화자와 전역 스타일 토큰을 사용하여 다음 출력 프레임을 생성하는 autoregressive 디코더 내에 정규화 플로우를 배치한다. Tacotron 2와 같이 학습하여 말하고 정렬하기 위해 neural attention을 사용한다.
정렬
: 음성 처리에서 주로 단어나 음소의 시간적인 배치나 순서를 의미한다. 일반적으로 음성 합성이나 인식 작업에서는 입력 문장의 각 단어 또는 음소를 해당하는 음성 신호와 일치시키는 것이 필요하다. -
Flow-TTS : 외부 정렬에 의존하는 non-autoregressive 구조다.
-
Glow-TTS : 동시에 말하고 정렬하는 것을 학습하여 Flow-TTS를 개선했으며, 외부 정렬 도구의 필요성을 제거했다. 또한 HMM의 Viterbi 알고리즘을 기반으로 한 동적 프로그래밍 절차를 도입하여 학습 중에 단조 정렬을 강제로 시행한다.
단조 정렬
: 음성 모델이 출력하는 음성 신호의 시간적인 배치를 단조롭게 만든다는 것을 의미한다. 이는 음성이 자연스럽게 흘러나가고 일관된 속도로 발화되도록 하는 것을 목적으로 한다. -
RAD-TTS : 더 복잡한 정렬 메커니즘과 함께 기간 모델링을 위해 별도의 정규화 플로우를 통합했지만, Glow-TTS만큼의 음질을 달성하지 못했다.
-
EfficientTTS : 전통적인 dot-product attention을 사용하여 단조 정렬을 촉진하거나 강제하기 위한 효율적인 메커니즘을 두 가지로 설명하여 주관적 점수를 향상시켰다.
이 중 Flowtron만이 완전한 확률적 모델이며, 다른 모델들은 순차 기간의 이산 값 확률 모델이 없으므로 모든 가능한 이산 시간 출력 시퀀스에 대한 유효한 확률 분포를 정의하지 않는다.
Flowtron을 제외한 위의 모든 플로우 기반 TTS 음향 모델은 non-autoregressive하다. 즉, 병렬적이다. 이는 GPU 서버에서 유리하다.
그러나 확률적 모델링 정확도 측면에서 autoregressive 아키텍처가 종종 non-autoregressive 보다 우위를 차지해 왔다. 예를 들어, 이미지 벤치마크의 bits-per-pixel metrics가 더 좋은 결과를 내곤 한다.
최근 플로우와 non-autoregressive HMM을 결합한 조합은 음성 인식 분야에서 기술 수준을 높였다. 이러한 발견들에서 동기를 얻어, 플로우를 neural HMM을 통해 autoregression 방식으로 결합하는 방식을 시도하게 되었다. 두가지 방법 모두 정확한 maximum-likelihood 훈련을 허용하고 강력한 확률적 모델링 결과를 보여주었기 때문이다.
Flowtron은 monotonic을 강제하지 않는 전통적인 neural attention을 사용하여, 횡설수설하기 쉽고 훈련이 어렵게 만든다. 이 모델은 공정한 비교를 위해 LJ Speech 데이터만으로 훈련되어 말하기를 배울 수 없다.
Glow-TTS는 HMM에서 유래된 알고리즘을 사용하여 monotonic 정렬을 강제하며, 본 논문과 같은 방법을 사용한다. 그러나 해당 방법은 본 논문과 달리 autoregression이 부재하며, 완전한 순방향 알고리즘(모든 경로) 대신 Viterbi 재귀(단일 경로)를 사용, 비확률적 지속 시간 모델을 사용한다.
플로우는 또한 end-to-end TTS에서 사용되었다. 가장 유명한 것은 VITS다. 이는 Glow-TTS에 플로우 기반의 지속 시간 모델과 neural vocoder를 추가하고 복합 손실로 훈련하는 것이다. 이는 강력하지만, 훈련 속도가 훨씬 느리다.
2.3. Flows as an invertible post-net
회귀 손실을 사용하는 많은 autoregressive TTS 시스템은 합성 중에 탐욕적이고 순차적인 출력 생성 절차를 사용한다. 출력 품질을 향상시키기 위해, post-net이라고 불리는 non-causal CNN을 사용한 후처리 네트워크가 적용된다. 이 네트워크는 자기회귀 모델에 의해 생성된 시퀀스에 대해 "되돌아가서" 시퀀스를 개선하기 위해 사용된다.
casual system
: t_0 시점의 출력이 오직 t_0 시점 이전의 입력값에만 영향을 받는 시스템으로, time invarient 하다.
non-casual system
: t0 시점 이후(미래의 값)에도 영향을 받는 시스템이다.
출처 : https://m.blog.naver.com/songsite123/222909136748
그러나 표준 post-net 아키텍처는 neural HMM의 정확한 maximum-likelihood training과 호환되지 않으며, 이러한 후처리 네트워크의 부재는 음성 품질에 부정적인 영향을 미친다. 대신 모델 출력을 가역적인 post-net을 통해 전달함으로써(따라서 모델을 정규화 플로우로 변환), 전체 모델을 훈련시켜 정확한 sequence likelihood를 극대화할 수 있다.
본 논문의 실험에서는 Glow-TTS에서 파생된 디코더를 사용한다. 이는 non-causal CNN을 기반으로 한 아키텍처를 활용하여, attention 기반의 neural TTS의 post-net과 유사한 특성을 띈다. Post-net 대신에, vocoder를 미세 조정하여 개선되지 않은 음향 특성에서 더 자연스러운 파형을 생성할 수도 있다. 그러나 이는 추가적인 훈련 단계가 필요하며, neural vocoder 훈련은 일반적으로 느리다.
3. Method
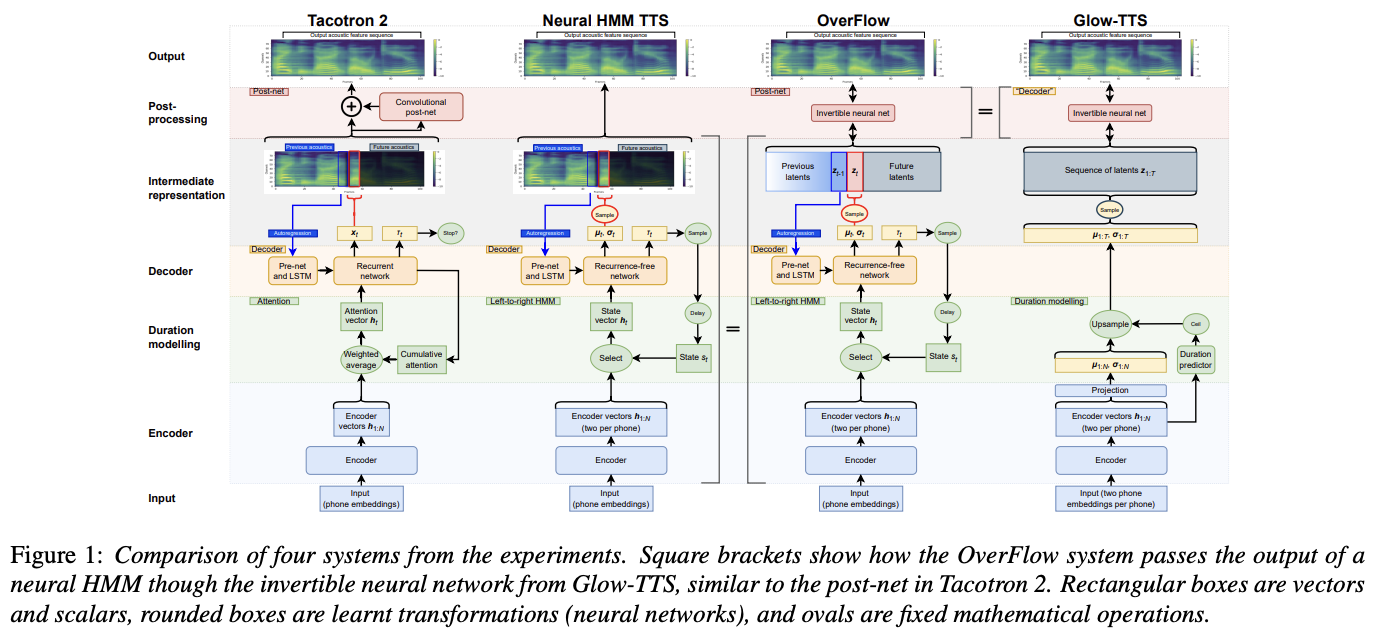
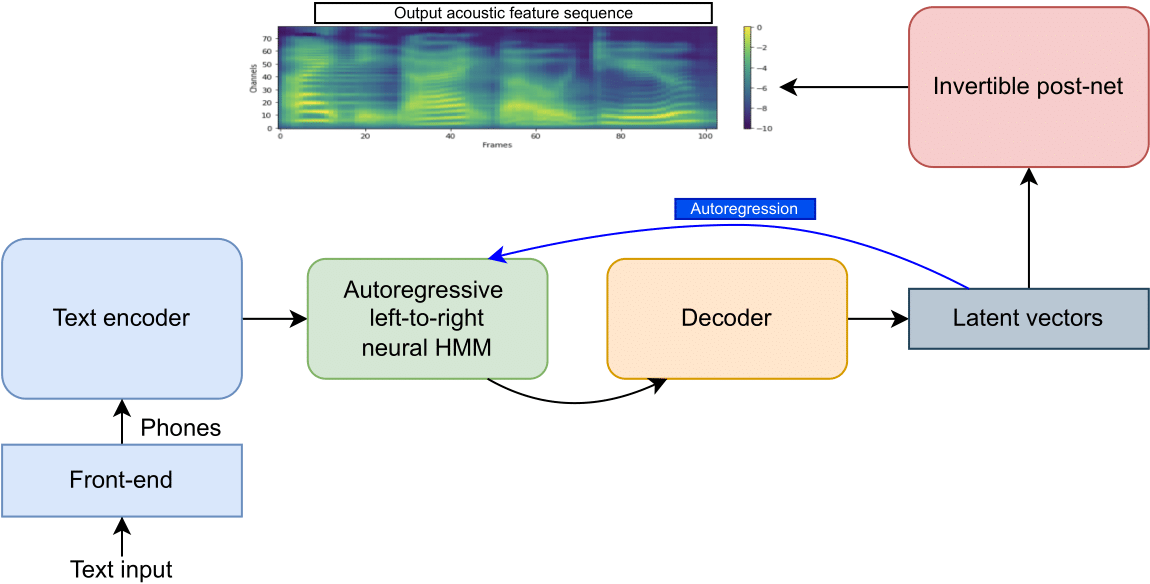
본 논문에서 제안한 방법인 OverFlow는 위 그림과 같다. Neural HMM 출력에 역함수 신경망을 적용하여 모델이 표현할 수 있는 확률 분포의 집합을 크게 증가시켰다.
Neural HMM TTS
Neural HMM은 입력 값과 출력 관측치를 정렬하는 데 전통적인 neural attention의 대안으로 제공되는 확률적 인코더-디코더 sequence-to-sequence 모델의 프레임워크다.
Encoder
TTS 음향 모델링에 사용될 경우, Neural HMM 인코더는 입력 벡터(예: phone 임베딩)를 왼쪽에서 오른쪽으로 건너뛰지 않는 HMM의 N개의 상태를 정의하는 벡터 시퀀스 h_1:N으로 변환한다. 각 입력 기호는 일정한 수의 벡터로 변환되며, 예를 들어 각 기호당 두 개의 상태로 변환된다.
Decoder
Neural HMM 디코더 네트워크는 두 개의 입력을 받고 두 개의 출력을 반환한다.

입력
- h_s_t : 인코더로부터 HMM 상태 s_t ∈ {1, . . . , N}에 해당하는 상태 정의 벡터
- x_1:t−1 : 시간 단계 t에서 이전에 생성된 출력 음향 프레임
- 이전 프레임의 정보를 기반으로 현재 프레임을 생성하므로 모델이 autoregressive한 특성을 갖게된다.
- 실제로는 일반적으로 직전 프레임 x_t−1만을 명시적으로 제공하고, t−1 이전의 출력도 다음 프레임에 영향을 미칠 수 있도록 보장하는 pre-net과 LSTM을 함께 사용하는 것이 일반적이다.
출력
- θ_t : 방출 분포의 매개 변수
- 다음 출력 프레임 x_t에 대한 확률 분포를 정의
- 대부분의 신경 HMM은 x_t가 대각 공분산 행렬을 가진 다변량 가우스 분포를 따른다고 가정
- θ_t = (µ_t, σ_t) : x_t의 각 요소별 평균과 표준 편차에 해당하는 두 개의 벡터
- τ_i : [0, 1] 범위 내의 전이 확률
- 현재 상태에 따라 HMM이 다음 상태로 전이할 여부를 결정
- s_t+1 = s_t + 1 : HMM이 다음 상태로 전이하는 경우
- s_t+1 = s_t: 다음 상태로 전이하지 않는 경우
합성은 s_1 = 1에서 시작하며, s_t = N + 1일 때 종료된다. 마르코프 가정에 따르면, 출력은 이전 시간 단계에서의 입력 벡터에 의존해서는 안된다. 숨겨진 상태 s_1:T에 대한 마르코프 가정을 충족시키기 위해 (즉, 유효한 신경 HMM이 되기 위해) 디코더 출력은 이전 시간 단계에서의 입력 벡터 h_1:t−1에 의존해서는 안된다.
따라서 모델은 훈련 데이터의 log-likelihood를 최대화하기 위해 표준 HMM의 기본 순전파 또는 Viterbi 알고리즘을 사용하여 계산된 훈련 데이터의 log-likelihood를 최대화하기 위해 훈련될 수 있다.
Normalising flows
Neural HMM은 각 프레임에 대해 가우스 분포를 가정하여 시간에 따른 이산적인 시퀸스의 분포를 설명한다. 반면에, Normalising flow는 간단한 latent 또는 source distribution Z(ex: Gaussian distribution)를 훨씬 유연한 target distribution X로 변환하는 방법을 제공한다. 이 아이디어는 source distribution에 역함수인 비선형 변환 f를 적용하여 target distribution을 얻는 것이다.
가역성은 관찰된 결과 x의 (log)확률을 계산할 수 있도록 한다.
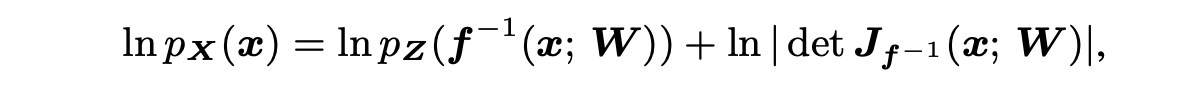
X = f(Z; W) : target distribution
f : 가중치가 W인 신경망
J_f^(-1)(x; W) : f 역함수의 Jacobian 행렬
f가 상대적으로 약한 비선형 변환이라 하더라도, 여러 성분 변환 f_l을 연쇄적으로 연결하면 매우 유연한 분포를 얻을 수 있다. 결합된 변환은 가역적인 신경망으로 알려져 있다.
결정적으로, Neural HMM과 Normalising flow 모두 정확한 likelihood 극대화를 허용하여 음향에 대한 강력한 확률적 모델로 매우 적합하다.
Glow는 인기 있는 정규화 플로우 아키텍처 중 하나다. 이는 학습된 전역 affine 변환과 "coupling layers"라고 불리는 레이어를 번갈아 가며 사용한다.
Coupling layer
: 입력 벡터 zl ∈ R^D의 절반 요소를 나머지 요소의 값에 따라 비선형적으로 변환 (나머지 요소는 변경되지 않음)
각 결합 레이어는 요소별로 역함수가 가능한 affine 변환을 수행하며 다음과 같이 표현할 수 있다.
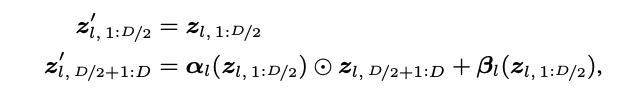
z'_l : l번째 결합 레이어의 출력
α_l > 0, β_l : 가중치 W를 가진 신경망의 출력
이 변환은 역으로 계산할 수 있으며, α_l과 β_l은 z'_l,1:D/2를 신경망에 입력하여 계산할 수 있다.
Affine 변환에서의 행렬 곱셈은 일종의 순열 작업의 일반화로 볼 수 있으며, 플로우에 의해 모든 입력 요소가 여러 비선형 변환을 받을 수 있도록 한다.
TTS에서 대부분의 정규화 플로우는 Glow를 기반으로 하며, Glow-TTS는 전역 affine 변환의 파라미터 효율적인 변형을 도입했다. Glow와 Glow-TTS 모두 coupling layer에서 CNN을 사용하므로 결과적으로 얻어지는 역함수 신경망은 유한한 수신 필드를 가지게 된다.
따라서 이러한 모델은 음향 간의 전역 종속성을 포착할 수 없으며, 이는 많은 Glow-TTS 시스템에서 나타나는 독특한 발화 수준의 억양 및 강조 패턴을 설명할 수 있다.
본 논문의 제안에서 source distribution Z_t는 neural HMM 내에서 이전 출력 z_1:t−1에 의존하며(LSTM에 의해 장기 기억이 제공됨), 이는 더욱 전체적으로 일관된 합성 음성을 생성할 수 있다.
소감
Image나 Text와 달리 Audio 데이터의 특성을 고려해서 모델을 학습시킬 필요성을 확인할 수 있었다. Vits로 학습시킨 결과를 확인해 봤었는데, 당시 부자연스럽다고 느낀 부분이 단조 정렬과 monotonic한 특성을 충분히 학습하지 못했기 때문인 것 같다.
해당 논문의 방법을 적용한다면 Vits보다 성능이 좋을 것으로 기대된다. 소스코드가 공개되어 있으니 모델이 영어로 pre-trained 되어있는 문제를 해결하고 feature를 넣어 줄 방법을 생각해 봐야겠다.
