Google Coral 공식문서를 참조해서 Edge TPU에서 구동시킬 Tensorflow 모델을 설계하고자 합니다.
Edge Tpu
Edge TPU에 대해 완전히 8비트 양자화된 TensorFlow Lite 모델만 지원합니다.
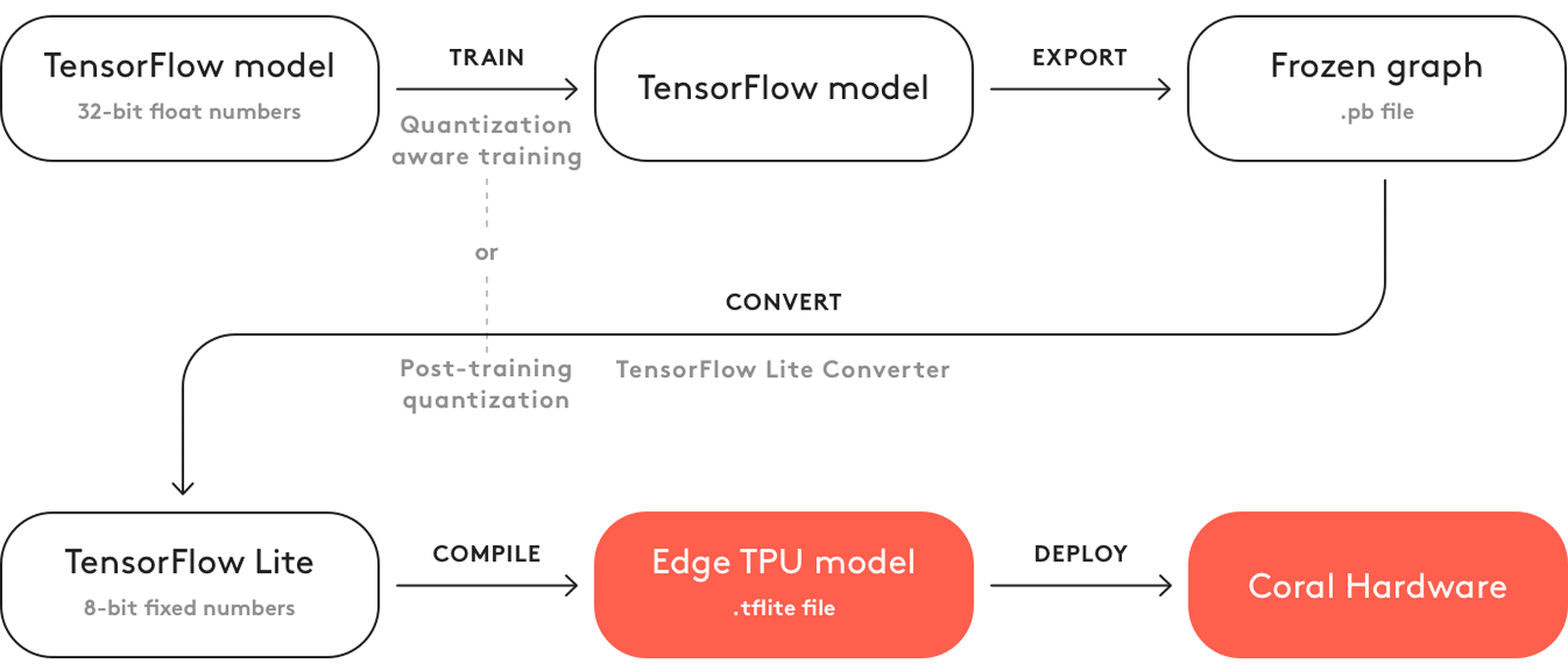
TensorFlow Lite로 직접 모델을 훈련할 수는 없으며, 대신 TensorFlow 파일(.pb 파일)을 TensorFlow Lite 파일(.tflite 파일)로 변환해야 합니다.
전이 학습
전이 학습은 직접 모델을 구축하고 처음부터 훈련하는 대신, 이미 Edge TPU와 호환되는 기존 모델을 재학습하는 기법입니다.
훈련 데이터와 일부 하이퍼파라미터 조정을 통해 이 과정을 통해 단일 세션에서 매우 정확한 TensorFlow 모델을 만들 수 있습니다. 모델의 성능에 만족하면, TensorFlow Lite로 변환한 다음 Edge TPU를 위해 컴파일하면 됩니다. 그리고 전이 학습 중 모델 아키텍처가 변경되지 않기 때문에 (호환 가능한 모델로 시작한다는 가정하에) Edge TPU에 완전히 컴파일될 것입니다.
전이학습 예제에서 기존 모델에 Classification head를 추가해 학습시키고, fine tuning 후 TFlite로 변환, Edge TPU로 컴파일 시키는 과정이 모두 나와있으니 참고하면 좋을 것 같습니다.
Python 및 C++ API를 사용하여 디바이스 내에서 전이 학습을 수행하는 두 가지 기술이 제공됩니다:
- 마지막 레이어에서 역전파 수행하기 (Python 또는 C++에서 SoftmaxRegression 사용)
- 마지막 레이어에 가중치 imprinting하기 (Python 또는 C++에서 ImprintingEngine 사용)
두 기술 모두 마지막 레이어에 대해 훈련이 가능하도록 특별히 설계된 모델을 제공해야 합니다. 각 API마다 요구되는 모델 구조가 다르지만, 기본적으로는 분류가 발생하는 마지막 fully-connected 레이어를 그래프의 기반과 분리시킵니다. 그런 다음, Edge TPU를 위해 그래프의 기반 부분만 컴파일하고, 마지막 레이어의 가중치는 훈련에 접근할 수 있도록 남겨둡니다. 모델 아키텍처에 대한 자세한 내용은 해당 문서에서 확인할 수 있습니다.
이제 각 기술에 대한 재훈련 방법을 비교해보겠습니다:
-
역전파 : 전통적인 역전파의 간소화 버전입니다. 그래프의 모든 레이어에 대한 새로운 가중치를 역전파하는 대신, 그래프의 끝에 있는 fully-connected 레이어만 새로운 가중치로 업데이트합니다. 이는 일반적으로 더 높은 정확도를 달성하는 더 전통적인 훈련 전략이지만, 더 많은 이미지와 여러 번의 훈련 반복을 필요로 합니다.
-
가중치 imprinting : 기본 모델의 출력 (임베딩 벡터)을 사용하여 활성화 벡터를 L2 정규화로 조정하고, 이 값을 사용하여 마지막 레이어의 새로운 가중치를 계산합니다. 이는 새로운 클래스를 매우 적은 샘플 이미지로 효과적으로 훈련시키는 데 사용됩니다.
이러한 훈련 기술 중에서 선택할 때 다음 요소를 고려할 수 있습니다:
-
훈련 샘플 크기
- 역전파 : 더 많은 훈련 샘플을 사용할 수 있는 경우
- 가중치 imprinting : 상대적으로 작은 규모의 훈련 샘플 세트(각 클래스에 1에서 200개의 샘플 이미지로, 최소 5개의 이미지도 효과적이며, API에서는 최대 200개로 제한됨)
-
훈련 샘플의 분산도
- 역전파 : 동일한 클래스 내의 이미지가 각각 각도나 크기 등에서 크게 다른 경우
- 가중치 imprinting : 분산이 낮고 훈련 샘플 간에 클래스 내 분산이 적은 환경
-
새로운 클래스 추가
- 역전파 : 훈련을 시작한 후에 새로운 클래스를 추가하려면 모든 클래스에 대해 훈련을 다시 시작해야 하며, 디바이스 내에서 모든 클래스를 학습해야 함
- 가중치 imprinting : 이미 훈련을 시작한 후에도 새로운 클래스를 모델에 추가할 수 있으며, 사전 훈련된 모델에서 클래스(Edge TPU로 모델을 변환하기 전에 훈련된 클래스들)를 유지할 수 있음
-
모델 호환성
- 역전파 : "외부에서 제공되는" 모델 아키텍처와 호환되는 경우가 더 많음 (기존의 사전 훈련된 MobileNet 및 Inception 모델을 디바이스 내에서 역전파와 호환되는 임베딩 추출기로 변환 가능)
- 가중치 imprinting : 특정한 레이어를 가진 모델을 사용하고 특정한 방식으로 훈련해야 함(현재, 적절한 수정이 된 MobileNet v1의 버전을 제공하고 있음)
두 기술 모두 대부분의 훈련 과정이 Edge TPU에서 가속화되며, 재훈련된 모델로 추론을 수행할 때에는 마지막 분류 레이어를 제외한 나머지모든 부분이 Edge TPU에서 가속화됩니다. 그리고 재훈련된 모델로 추론을 수행할 때에는 마지막 분류 레이어가 CPU에서 실행됩니다. 그러나 이 마지막 레이어는 모델의 일부분이므로 추론 속도에 큰 영향을 미치지 않을 것입니다.
각 기술에 대해 더 자세히 알아보고 몇 가지 예제 코드를 확인하려면 다음 페이지를 참조하세요:
모델 요구 사항
가속화된 추론을 위해 Edge TPU의 모든 장점을 활용하는 TensorFlow 모델을 구축하려면, 모델은 다음과 같은 기본 요구 사항을 충족해야 합니다.
-
텐서 매개 변수는 양자화(8비트 고정 소수점 숫자; int8 또는 uint8)되어야 합니다.
-
텐서 크기는 컴파일 시간에 상수이어야 합니다(동적 크기는 허용되지 않음).
-
모델 매개 변수(예: 바이어스 텐서)는 컴파일 시간에 상수이어야 합니다.
-
텐서는 1차원, 2차원 또는 3차원 중 하나여야 합니다. 만약 텐서가 3차원보다 더 많은 차원을 가지고 있다면, 3개의 가장 안쪽 차원만 크기가 1보다 큰 경우에만 허용됩니다.
5차원 텐서 (1, 2, 3, 1, 1)의 경우를 생각해 보면
- 3개의 가장 안쪽 차원 : (1, 2, 3)
- 나머지 차원 : (1, 1)
3개의 가장 안쪽 차원은 크기가 1보다 커도 무관하지만 나머지 차원의 크기는 1보다 커서는 안된다.
-
모델은 Edge TPU에서 지원하는 연산만 사용해야 합니다(아래 표 1 참조).
이러한 요구 사항을 충족하지 않으면 모델이 Edge TPU에 대해 전혀 컴파일되지 않을 수 있거나, 컴파일에 일부만 가속화될 수 있습니다.
지원되는 연산
자체 모델 아키텍처를 구축할 때는 Edge TPU에서 지원하는 연산만 사용해야 함을 알아두세요. 다음 표에 나열된 연산 이외의 연산을 사용하는 경우, 모델의 일부만 Edge TPU에 대해 컴파일되고 나머지 연산은 CPU에서 실행됩니다.
새로운 TensorFlow 모델을 작성할 때는 TensorFlow Lite와 호환되는 연산 목록을 참조하세요. 또한, Dev Board Micro를 사용하는 경우, MCU(마이크로 컨트롤러 유닛)에서 실행되는 모델 연산은 TensorFlow Lite for Microcontrollers와 호환되어야 하며, TensorFlow Lite보다 적은 연산을 지원합니다.
표 1. Edge TPU에서 지원하는 모든 연산 및 알려진 제한 사항
| Operation | Runtime version | Known limitations |
|---|---|---|
| Add | All | None |
| AveragePool2d | All | No fused activation function. |
| Concatenation | All | No fused activation function. If any input is a compile-time constant tensor, there must be only 2 inputs, and this constant tensor must be all zeros (effectively, a zero-padding op). |
| Conv2d | All | Must use the same dilation in x and y dimensions. |
| DepthwiseConv2d | ≤12 | Dilated conv kernels are not supported. |
| ≥13 | Must use the same dilation in x and y dimensions. | |
| ExpandDims | ≥13 | None |
| FullyConnected | All | Only the default format is supported for fully-connected weights. Output tensor is one-dimensional. |
| L2Normalization | All | None |
| Logistic | All | None |
| LSTM | ≥14 | Unidirectional LSTM only. |
| Maximum | All | None |
| MaxPool2d | All | No fused activation function. |
| Mean | ≤12 | No reduction in batch dimension. Supports reduction along x- and/or y-dimensions only. |
| ≥13 | No reduction in batch dimension. If a z-reduction, the z-dimension must be multiple of 4. | |
| Minimum | All | None |
| Mul | All | None |
| Pack | ≥13 | No packing in batch dimension. |
| Pad | ≤12 | No padding in batch dimension. Supports padding along x- and/or y-dimensions only. |
| ≥13 | No padding in batch dimension. | |
| PReLU | ≥13 | Alpha must be 1-dimensional (only the innermost dimension can be >1 size). If using Keras PReLU with 4D input (batch, height, width, channels), then shared_axes must be [1,2] so each filter has only one set of parameters. |
| Quantize | ≥13 | None |
| ReduceMax | ≥14 | Cannot operate on the batch dimension. |
| ReduceMin | ≥14 | Cannot operate on the batch dimension. |
| ReLU | All | None |
| ReLU6 | All | None |
| ReLUN1To1 | All | None |
| Reshape | All | Certain reshapes might not be mapped for large tensor sizes. |
| ResizeBilinear | All | Input/output is a 3-dimensional tensor. Depending on input/output size, this operation might not be mapped to the Edge TPU to avoid loss in precision. |
| ResizeNearestNeighbor | All | Input/output is a 3-dimensional tensor. Depending on input/output size, this operation might not bemapped to the Edge TPU to avoid loss in precision. |
| Rsqrt | ≥14 | None |
| Slice | All | None |
| Softmax | All | Supports only 1-D input tensor with a max of 16,000 elements. |
| SpaceToDepth | All | None |
| Split | All | No splitting in batch dimension. |
| Squeeze | ≤12 | Supported only when input tensor dimensions that have leading 1s (that is, no relayout needed). For example input tensor with [y][x][z] = 1,1,10 or 1,5,10 is ok. But [y][x][z] = 5,1,10 is not supported. |
| ≥13 | None | |
| StridedSlice | All | Supported only when all strides are equal to 1 (that is, effectively a Stride op), and with ellipsis-axis-mask == 0, and new-axis-max == 0. |
| Sub | All | None |
| Sum | ≥13 | Cannot operate on the batch dimension. |
| Squared-difference | ≥14 | None |
| Tanh | All | None |
| Transpose | ≥14 | None |
| TransposeConv | ≥13 | None |
- Edge TPU Compiler의 버전은 실행 버전과 일치해야 합니다.
양자화
가중치(weight)와 활성화 출력(activation outputs)과 같은 32비트 부동소수점 숫자를 가장 가까운 8비트 고정소수점 숫자로 변환하는 것을 의미합니다. 이를 통해 모델의 크기가 작아지고 속도가 향상됩니다. 또한, 이러한 8비트 표현은 덜 정밀할 수 있지만, 신경망의 추론 정확도에는 크게 영향을 주지 않습니다.
Edge TPU와 호환되기 위해서는 양자화-aware 학습(추천) 또는 후처리 양자화(full integer post-training quantization) 중 하나를 사용해야 합니다.
양자화에 대한 인식을 갖고 학습을 진행하는 기법 (TensorFlow 1용)
학습 중에 "가짜" 양자화 노드를 신경망 그래프에 사용하여 8비트 값의 효과를 모의하는 방식입니다. 따라서, 이 기법은 초기 학습 전에 네트워크를 수정해야 합니다. 이는 보통 후처리 양자화(post-training quantization)와 비교하여 더 높은 정확도의 모델을 제공합니다. 왜냐하면 8비트 가중치가 후처리로 변환되는 것이 아니라 학습을 통해 배워지기 때문에 모델이 낮은 정밀도 값을 더 허용할 수 있기 때문입니다. 또한, 현재 양자화-aware 학습은 후처리 양자화보다 더 많은 연산과 호환됩니다.
2021년 8월 기준으로, TF2에서의 양자화-aware 학습 API는 객체 검출 API와 호환되지 않습니다. 이는 이미지 분류 모델에만 호환됩니다. 객체 검출 API를 포함한 더 많은 호환성을 위해, TF1에서 양자화-aware 학습을 사용하거나 TF2에서 후처리 양자화를 사용할 수 있습니다.
후처리 양자화 기법
네트워크에 어떠한 수정도 필요로 하지 않으므로, 이 기법을 사용하여 이전에 학습한 네트워크를 양자화된 모델로 변환할 수 있습니다. 그러나 이 변환 과정에서는 대표적인 데이터셋을 제공해야 합니다. 즉, 원래의 학습 데이터셋과 동일한 형식으로 포맷팅된 데이터셋이 필요하며, 유사한 스타일을 가지고 있어야 합니다(모든 동일한 클래스를 포함할 필요는 없지만, 이전의 학습/평가 데이터를 사용할 수 있습니다). 이 대표적인 데이터셋을 사용하면 양자화 과정에서 활성화 및 입력의 동적 범위를 측정할 수 있으며, 이는 각 가중치와 활성화 값을 정확한 8비트 표현으로 찾는 데 중요합니다.
그러나 현재 TensorFlow Lite의 모든 연산이 정수 전용 명세로 구현되어 있지 않기 때문에(후처리 양자화로 양자화할 수 없음), TensorFlow Lite 변환기는 이러한 연산을 기본적으로 float 형식으로 유지합니다. 이는 Edge TPU와 호환되지 않습니다. 아래에서 설명한 대로, Edge TPU 컴파일러는 호환되지 않는 연산(비-양자화 연산 등)을 만나면 컴파일을 중단하고 나머지 모델을 CPU에서 실행합니다. 따라서 정수 전용 양자화를 강제하기 위해 변환기에게 양자화할 수 없는 연산을 만나면 오류를 발생시키도록 지시할 수 있습니다. 정수 전용 양자화에 대해 더 자세히 알아보려면 여기에서 읽어보세요.
각 양자화 전략에 대한 예시는 모델 학습을 위한 Google Colab 튜토리얼을 참조하세요.
양자화가 어떻게 작동하는지에 대한 자세한 내용은 TensorFlow Lite 8비트 양자화 사양을 읽어보세요.
실수 입력과 출력 텐서
모델 요구 사항에서 언급한 대로, Edge TPU는 8비트 양자화된 입력 텐서를 필요로 합니다. 그러나 내부적으로 양자화된 모델이지만 여전히 float 입력을 사용하는 모델을 Edge TPU 컴파일러에 전달하면 컴파일러는 그래프의 시작 부분에 양자화 연산을 남깁니다(이 연산은 CPU에서 실행됩니다). 마찬가지로, 출력은 마지막 부분에서 다시 양자화 해제됩니다.
따라서 TensorFlow Lite 모델이 float 입력/출력을 사용하는 경우에는 문제가 없습니다. 그러나 모델이 float 입력과 출력을 사용하는 경우 데이터 형식 변환으로 인해 약간의 지연이 추가될 수 있습니다. 그러나 대부분의 모델에서는 이는 무시할 수 있는 수준일 것입니다(입력 텐서가 클수록 더 많은 지연이 발생합니다).
가능한 최상의 성능을 얻기 위해서는 입력과 출력이 int8 또는 uint8 데이터를 사용하도록 모델을 완전히 양자화하는 것이 좋습니다. 이는 TensorFlow 문서에서 설명하는 대로 TF Lite 변환기를 사용하여 입력과 출력 유형을 설정함으로써 수행할 수 있습니다. 정수 전용 양자화에 대한 TensorFlow 문서를 참조하시기 바랍니다.
컴파일
모델을 훈련하고 TensorFlow Lite로 변환한 후, 마지막 단계는 Edge TPU 컴파일러를 사용하여 컴파일하는 것입니다.
이 섹션의 맨 위에 나열된 요구 사항을 모두 충족하지 않는 경우에도 모델은 컴파일될 수 있지만, Edge TPU에서는 모델의 일부만 실행됩니다. 모델 그래프에서 지원되지 않는 연산이 발생하는 첫 번째 지점에서 컴파일러는 그래프를 두 부분으로 분할합니다. 지원되는 연산만 포함된 그래프의 첫 번째 부분은 Edge TPU에서 실행되는 사용자 정의 연산으로 컴파일되고, 나머지는 CPU에서 실행됩니다. 이는 그림 2에서 시각화되었습니다.
Dev Board Micro를 사용하는 경우, Edge TPU에 컴파일되지 않기 때문에 MCU에서 실행되는 모델 연산은 TensorFlow Lite for Microcontrollers와 호환되어야 합니다. TensorFlow Lite보다 적은 연산을 지원합니다. 또한, 큰 모델은 Dev Board Micro의 메모리에 맞지 않을 수 있습니다.
현재 Edge TPU 컴파일러는 모델을 한 번 이상 분할할 수 없으므로, 지원되지 않는 연산이 발생하면 해당 연산과 그 이후의 모든 연산은 CPU에서 실행됩니다. 심지어 이후에 지원되는 연산이 나와도 마찬가지입니다.
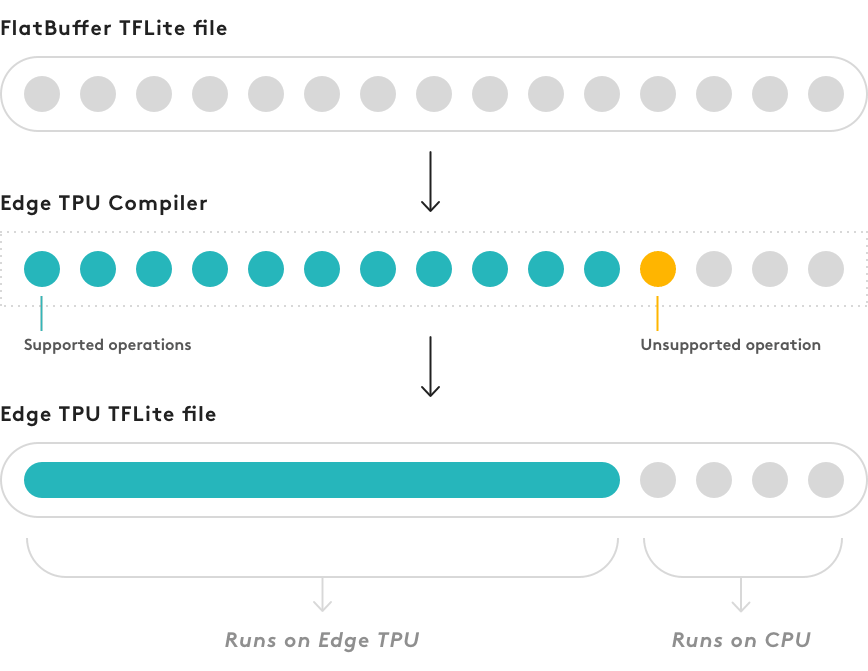
Edge TPU 컴파일러는 지원되는 연산에 대해 하나의 사용자 정의 연산(custom op)을 생성하여 Edge TPU에서 실행합니다. 하지만 지원되지 않는 연산이 나타나면 컴파일러는 그 이후의 연산을 그대로 유지하고 CPU에서 실행합니다.
컴파일된 모델을 (visualize.py와 같은 도구를 사용하여) 검사하면, 그래프의 시작 부분에 사용자 정의 연산이 추가된 TensorFlow Lite 모델임을 확인할 수 있습니다. 이 사용자 정의 연산은 실제로 컴파일된 모델의 일부입니다. Edge TPU에서 실행되는 모든 연산이 포함되어 있습니다. 그래프의 나머지 부분(첫 번째 지원되지 않는 연산부터 시작)은 동일하게 유지되며 CPU에서 실행됩니다.
모델의 일부가 CPU에서 실행되는 경우, 전체적으로 Edge TPU에서 실행되는 모델에 비해 추론 속도가 상당히 떨어질 것으로 예상됩니다. 이러한 상황에서 모델의 성능이 얼마나 느려질지를 정확하게 예측할 수는 없으므로, 다양한 아키텍처를 실험하고 Edge TPU와 완벽하게 호환되는 모델을 만드는 노력을 해야 합니다. 즉, 컴파일된 모델은 Edge TPU 사용자 정의 연산만 포함해야 합니다.
컴파일이 완료되면, Edge TPU 컴파일러는 Edge TPU에서 실행되는 연산 수와 CPU에서 실행되어야 하는 연산 수(있는 경우)를 알려줍니다. 그러나 Edge TPU에서 실행되는 연산의 비율과 CPU에서 실행되는 연산의 비율은 전체적인 성능 영향과 일치하지 않습니다. 모델의 작은 부분이라도 CPU에서 실행되는 경우, 추론 속도가 지수적으로 느려질 수 있습니다(Edge TPU에서 전체적으로 실행되는 모델과 비교했을 때).
