Ensemble Learning
: 여러 개의 개별 모델을 조합하여 최적의 모델로 일반화하는 방법이다.
모델 간의 다양성을 활용하여 예측의 일반화 성능을 향상시키고, 과적합을 줄이는 데 도움을 줄 수 있다.
Stacking
-
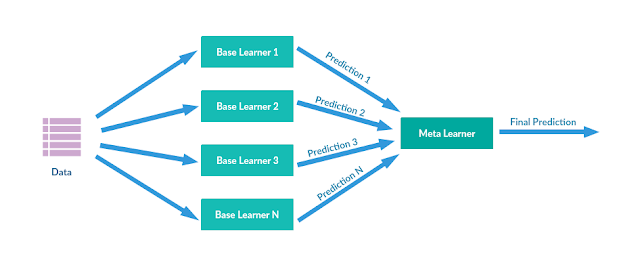
목적: 여러 개별적인 모델을 조합하여 예측을 수행하는 방법이다. 주로 분류 및 회귀 문제에 사용된다.
-
작동 원리:
- 원본 데이터를 사용하여 여러 모델을 훈련한 후, 모델의 예측 결과를 새로운 메타 모델에 입력으로 제공한다.
- 메타 모델은 이러한 예측 결과를 기반으로 최종 예측을 수행한다.
이를 통해 각 모델의 강점을 활용하고 예측 성능을 향상시킬 수 있다.
Cross Validation
기본적인 Stacking 방법의 경우 Base Learner들이 동일한 데이터 원본 데이터를 가지고 그대로 학습을 진행했기 때문에 overfitting 문제가 발생한다.
따라서 k-fold 교차 검증을 기반으로 Stacking을 적용함으로써 overfitting은 피하며 meta 모델은 '특정 형태의 샘플에서 어떤 종류의 단일 모델이 어떤 결과를 가지는지' 학습할 수 있게 된다.
참고 : https://data-analysis-science.tistory.com/61
Bagging
-
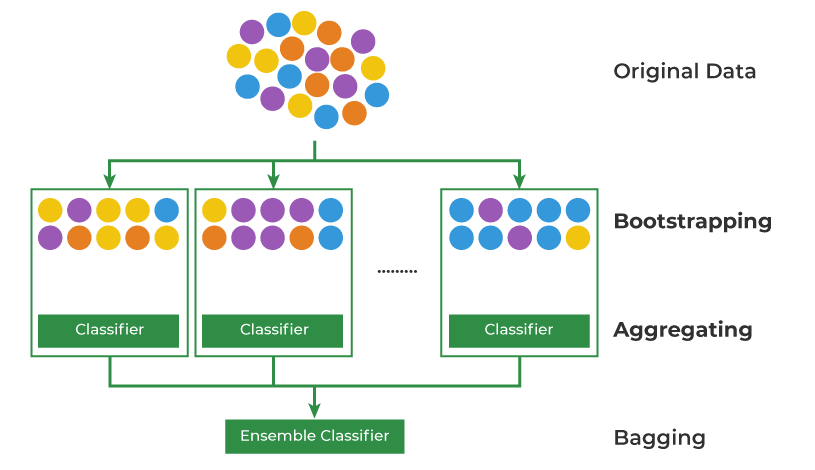
목적: Bootstrap Aggregating의 줄임말로, 같은 모델을 여러 번 병렬로 훈련하고, 각 모델의 예측을 결합하여 예측 성능을 향상시키는 방법입니다. 주로 분류 및 회귀 문제에 사용된다.
-
작동 원리: 부트스트랩 샘플을 사용하여 여러 모델을 병렬로 훈련하고, 각 모델의 예측을 평균 또는 다수결 방식으로 결합하여 최종 예측을 만든다.
-
예시 알고리즘: 랜덤 포레스트(Random Forest)가 대표적인 결정 트리 앙상블 모델이다.
Bootstrap Sample
표본 데이터 집합의 일부로, 주어진 원본 데이터셋에서 무작위로 중복을 허용(복원 랜덤 추출)하여 데이터 포인트를 선택하는 방법이다.
신뢰 구간 추정, 모델 평가, 통계적 추론 등의 목적으로 사용이 가능하다.
Voting
-
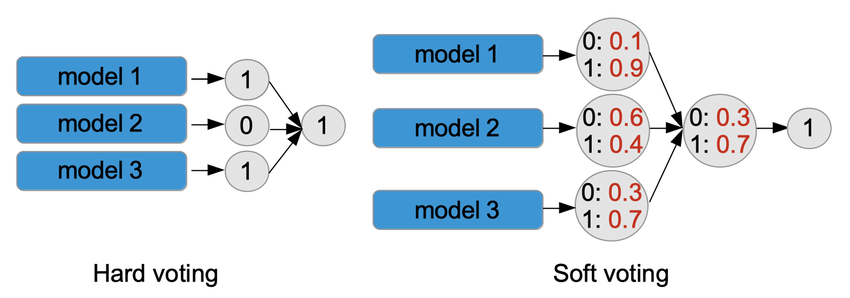
목적: 다양한 개별 모델의 예측을 결합하여 최종 예측을 만드는 방식이다. 주로 분류 문제에 사용된다.
-
작동 원리: 다양한 모델의 예측을 종합적으로 고려하여 최종 예측을 수행한다.
- 하드 보팅 : 각 모델의 예측 중 가장 많은 선택을 받은 클래스를 최종 예측으로 선택한다.
- 소프트 보팅 : 각 모델의 예측 확률을 평균하여 가장 높은 평균 확률을 갖는 클래스를 최종 예측으로 선택한다.
보팅을 사용하면 다양한 모델의 다양한 관점을 고려하여 예측 성능을 향상시킬 수 있다.
Boosting
-
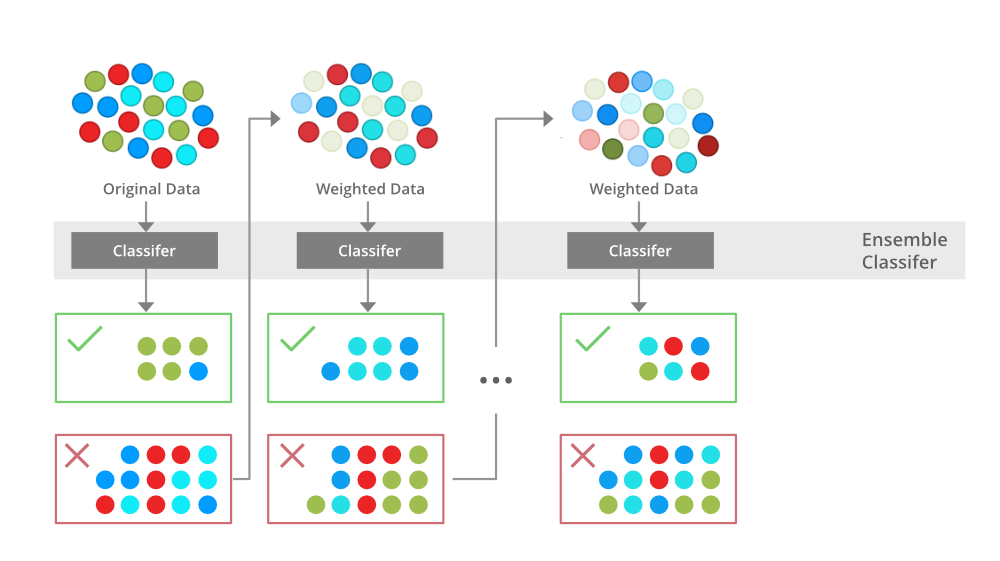
목적: 약한 학습기(weak learner)라 불리는 모델을 조합하여 강한 학습기(strong learner)를 만든다. 주로 분류 및 회귀 문제에 사용된다.
-
작동 원리: 순차적인 방식으로 모델을 훈련한다. 이전 모델이 만든 오차에 초점을 맞춰 다음 모델을 향상시키는 방식으로 작동한다. 각 모델은 데이터 포인트에 가중치를 부여하고, 가중치를 조절하여 예측을 수행한다. 최종 예측은 이러한 모델의 예측을 결합하여 생성된다.
-
예시 알고리즘: AdaBoost, Gradient Boosting, XGBoost, LightGBM, CatBoost 등
