10. 시계열을 위한 딥러닝
- 딥러닝 개념
- 딥러닝 모델의 적용에 사용해볼 만한 예제
딥러닝 개념

위 모델의 동작 방식
- 은닉 계층을 구성하는 네 개의 요소는 으로 계산
- 활성함수로 비선형성을 적용 (하이퍼볼릭 탄젠트나 시그모이드)
- 은닉 계층의 출력을 두 개의 출력으로 변환
최종 출력당 은닉 계층의 네 개의 출력을 결합하기 위한 dense layer 적용
신경망 프로그래밍
딥러닝 프레임워크 : 모든 구조는 개별 요소와 그들 간의 관계로 설명될 수 있어야 함
기호와 데이터의 관계 때문에 모든 프레임 워크는 기호와 데이터를 반드시 구별해야 함
앞의 완전연결계층을 행렬 연산, 활성함수, 편향을 모두 고려하면 다음과 같이 표현
여러 계층을 서로 연결해 다음 계층으로 연결할 수도 있다
그래프는 기호와 기호 사이의 의존성, 그 의존 방법을 정확하게 구별하는데 사용됨
→ 경사도를 계산하는 경사 하강 과정 중 학습 단계마다 일어나는 가중치 조정에 필수
행렬곱셈, 행렬덧셈, 요소별 활성함수의 적용을 수학적 요소를 모두 적는 대신완전연결계층 하나만을 사용할 수 있음
import mxnet as mx
fc1 = mx.gluon.nn.Dense(120, activation = 'relu')→ 입력을 120차원의 출력으로 변환하는 완전연결계층
하지만 입력, 타깃, 측정하려는 손실의 정의가 추가로 필요하고, 모델이라는 큰 틀 속에 계층을 배치하는 등의 작업이 필요
## 독립적인 계층을 덩그러니 선언하는 대신 신경망 모델을 만든다.
from mx.gluon import nn
net = nn.Sequential()
net.add(nn.Dense(120, activation = 'relu'), nn.Dense(1))
net.initialize(init=init.Xavier())
## 원하는 손실을 정의
L2Loss = gluon.loss.L2Loss()
trainer = gluon.Train(net.collect_params(), 'sgd', {'learning_rate':0.01})학습 에폭을 실행
for data, target in train_data:
## 경사를 계산
with autograd.record():
out = net(data)
loss = L2Loss(output, data)
loss.backward()
## 파라미터 업데이트를 위해 경사를 적용
trainer.step(batch_size)모델, 모델을 구성하는 파라미터를 저장
net.save_parameters('model.params')학습 파이프라인 만들기
Dataset : 몇 년간 다양한 장소에서 측정된 전기사용량
데이터 처리 공정
- 미리 기본 학습 파라미터 값을 정의해 코드를 쉽게 설정할 수 있도록 만듦
- 데이터를 메모리에 적재해 전처리를 수행
- 기대되는 형식으로 데이터의 모양을 알맞게 맞춤
- 사용하는 딥러닝 모듈에 적합한 반복자를 만듦
- 반복자로 기대되는 데이터 모양을 얻고, 이를 활용해 그래프를 구축
- optimizer, 학습률, 학습할 에폭 횟수와 같은 학습 파라미터를 설정
- 에폭마다 결과와 가중치를 기록하는 저장 시스템을 구축
이러한 작업을 달성하는 방법
from math import floor
## 저장 모듈
import os
import argparse
## 딥러닝 모듈
import mxnet as mx
## 데이터 처리용 모듈
import numpy as np
import pandas as pd
## 사용자 정의 보고용 모듈
import perf하드코딩된 변수와 조정 가능한 파라미터를 혼합
## 커맨드라인에서 입력받지 않는 몇 가지 하이퍼파라미터가 있다
DATA_SEGMENTS = {'tr':0.6, 'va':0.2, 'tst':0.2}
TRESHOLD_EPOCHS = 5
COR_THRESHOLD = 0.0005
## 파서 설정
parser = argparse.ArgumentParser()
## 데이터의 모양
parser.add_argument('--win', type = int, default = 24*7)
parser.add_argument('--h', type=int, default=3)
## 모델의 사양
parser.add_argument('--model', type=str, default='rnn_model')
## cnn의 구성 요소
parser.add_argument('--sz-filt', type=int, default=8)
parser.add_argument('--n-filt', type=int, default=10)
## Rnn의 구성 요소
parser.add_argument('--rnn-units', type=int, default=10)
## 학습의 상세
parser.add_argument('--batch-n', type=int, default=1024)
parser.add_argument('--lr', type=float, default=0.0001)
parser.add_argument('--drop', type=float, default=0.2)
parser.add_argument('--n-epochs', type=int, default=30)
## 작업 내역 저장
parser.add_argument('--data-dir', type=str, default='../data')
parser.add_argument('--save-dir', type=str, default=None)→ 조정된 하이퍼파라미터는 데이터 전처리, 모델의 사양, 학습 방법 등 학습 전반에 걸쳐 영향을 미침
데이터의 모양 → 데이터를 입력받는 방식과 관련
- win 파라미터 : 모델이 예측을 만들어낼 때 시간상 얼마나 이전까지 바라볼 수 있는지 나타냄
- h 변수 : 얼마만큼 떨어진 미래를 예측할지 나타냄
📌 입력 데이터 준비
신경망은 일종의 확률적 경사 하강법을 통해 한 번에 전체 데이터의 일부분에 접근하는 걸 반복해 전체 데이터를 학습하므로 이런 방식의 학습을 위한 데이터 기반이 마련되어야 함
학습에 데이터를 제공하는 방법
- 반복자를 사용하여 고수준으로 처리하는 방식
- 반복자로 들어가는 데이터의 모양을 상세히 잡는 저수준 처리 방식
입력 데이터의 모양 만들기
| 시간 | A | B | C |
|---|---|---|---|
| t-3 | 0 | -1 | -2 |
| t-2 | 3 | -2 | -3 |
| t-1 | 4 | -2 | -4 |
| t | 8 | -3 | -9 |
두 단계 이전의 데이터들로 한 단계 미래를 예측하는 모델 만들기
→ A, B, C 데이터를 사용해서 A, B, C를 예측하는 문제이며 X와 Y는 입력과 출력
시간 와 에 대한 입력을 하나의 형식으로 저장하면
| 시간 | A, 시간-1 | A, 시간-2 | B, 시간-1 | B, 시간-2 | C, 시간-1 | C, 시간-2 |
|---|---|---|---|---|---|---|
| t-1 | 3 | 0 | -2 | -1 | -3 | -2 |
| t | 4 | 3 | -2 | -2 | -4 | -3 |
→ NC 데이터 형식 ~ 완전 연결 신경망 학습에 사용
N : 개별 샘플, C : 다변량 정보를 표현하는 또 다른 방법의 채널
시간에 특화된 축을 만드는 방법으로 데이터의 모양을 다르게 잡아줄 때 쓰는 형식 NTC : '샘플시간채널의 개수를 지정
| 시간 | A | B | C |
|---|---|---|---|
| t-1 | 4 | -2 | -4 |
| t | 8 | -3 | -9 |
→ NTC 데이터 형식 ~ 합성곱 및 순환 신경망에 대한 입력으로 사용
반복자 구성하기
반복자 : 일종의 데이터 집합을 통해 동작하는 객체에 대한 개념
→ 전체 데이터 집합의 작업 위치를 추적하고 그 시점을 표현하는 기능
## 데이터 준비작업
def prepare_iters(data_dir, win, h, model, batch_n):
X, Y = prepared_data(data_dir, win, h, model)
n_tr = int(Y.shape[0] * DATA_SEGMENTS['tr'])
n_va = int(Y.shape[0] * DATA_SEGMENTS['va'])
X_tr, X_valid, X_test = X[:n_tr], X[n_tr:n_tr+n_va], X[n_tr+n_va:]
Y_tr, Y_valid,Y_test = Y[:n_tr], Y[n_tr:n_tr+n_va], Y[N_tr+n_va:]
iter_tr = mx.io.NDArrayIter(data = X_tr, label = Y_tr, batch_size = batch_n)
iter_val = mx.io.NDArrayIter(data = X_valid, label = Y_valid, batch_size = batch_n)
iter_test = mx.io.NDArrayIter(data = X_test, label = Y_test, batch_size = batch_n)
return (iter_tr, iter_val, iter_test)📌 코드로 데이터 모양 잡기
def prepared_data(data_dir, win, h, model_name):
df = pd.read_csv(os.path.join(data_dir, 'electricity.diff.txt'), sep = ',', header = 0)
x = df.as_matrix()
## 데이터셋을 정규화하고 사전관찰을 만든다
## 데이터셋 전체의 측정치 기반으로 정규화하기 때문이다
## 이 예제는 간단한 방법을 사용하지만 좀 더 복잡한 파이프라인이라면
## 사전관찰 문제를 피하기 위한 롤링 통계를 사용하여 계산해야 한다
x = (x - np.mean(x, axis = 0)) / (np.std(x, axis = 0))
if model_name == 'fc_model': ## NC data format NC 데이터 형식
## 평평한 형태의 입력 배열에서 첫 번째와 두 번때 이전 단계를 제공
X = np.hstack([x[1:-1], x[:-h]])
Y = x[h:]
return (X, Y)
else: ## NTC 데이터 형식
## X와 Y를 사전 할당 해준다
## X의 모양 = 표본의 개수 * 시간 윈도 크기 * 채널의 개수
X = np.zeros((x.shape[0] - win - h, win, x.shape[1]))
Y = np.zeros((x.shape[0] - win - h, x.shape[1]))
for i in range(win, x.shape[0]-h):
## 타깃 및 레이블 값은 h단계만큼 앞서도록 해준다
Y[i-win] = x[i+h-1, :]
## win 크기의 단계만큼 이전 데이터를 입력으로 지정한다
X[i-win]=x[(i-win):i, :]
return (X, Y)NC 데이터 형식
if model_name == 'fc_model': ## NC 데이터 형식
X = np.hstack([x[1:-h], x[0:-(h+1)]])
Y = x[(h+1):]시간 t-h에 대한 입력 x를 생성하고, 시간 t에서 예측을 수행하기 위해서 x의 마지막 h만큼의 행을 제거한 뒤 이 데이터를 시간축에 따라 이동해 지연된 값을 구성한다
NTC 데이터 형식
## X와 Y 사전 할당
## X의 모양 = 표본의 개수 * 시간 윈도의 크기 * 채널의 개수
X = np.zeros((x.shape[0] - win - h, win, x.shape[1]))
Y = np.zeros((x.shape[0] - win - h, x.shape[1]))
for i in range(win, x.shape[0]-h):
## 타깃/레이블 값은 h단계만큼 앞선다
Y[i-win] = x[i+h-1, :]
## 입력 데이터는 win단계만큼 이전에 위치
X[i-win]=x[(i-win):i, :]모든 열에 대한 입력 데이터의 마지막 win 크기만큼의 행을 가져와 3차원을 만든다
→ 첫 번째 차원은 데이터에 대한 인덱스, 데이터의 값은 시간 채널이라는 2차원 형태
📌 학습 파라미터의 설정과 기록 관리 시스템의 구축
def train(symbol, iter_train, valid_iter, iter_test, data_names, label_names, save_dir):
##학습 정보와 결과 저장
if not os.path.exists(args.save_dir):
os.makedirs(args.save_dir)
printFile = open(os.path.join(args.save_dir, 'log.txt'), 'w')
def print_to_file(msg):
print(msg)
print(msg, file = printFile, flush = True)
##결과에 대한 헤더 저장
print_to_file('Epoch Training Cor Validation Cor')
## 이전 에폭에 대한 값을 저장하여 성능 향상의 한계점 설정
## 진행이 느릴 경우 학습을 일찍 끝내도록 해준다
buf = RingBuffer(THRESHOLD_EPOCHS)
old_val = None
## MXNet의 보일러플레이트
## 기본으로 GPU 1개 사용되며 해당 GPU의 인덱스는 0번이다
devs = [mx.gpu(0)]
module = mx.mod.Module(symbol, data_names = data_names, label_names=label_names, context=devs)
module.bind(data_shapes=iter_train.provide_data, label_shapes=iter_train.provide_label)
module.init_params(mx.initializer.Uniform(0.1))
module.init_optimizer(optimizer='adam', optimizer_params={'learning_rate':args.lr})
## 학습 과정
for epoch in range(args.n_epochs):
iter_train.reset()
iter_val.reset()
for batch in iter_train:
## 예측값 계산
module.forward(batch, is_train = True)
## 경사값 계산
module.backward()
## 파라미터 갱신
module.update()
## 학습 데이터셋의 결과
train_pred = module.predict(iter_train).asnumpy()
train_label = iter_train.label[0][1].asnumpy()
train_perf = perf.wirte_eval(train_pred, train_label, save_dir, 'train', epoch)
## 검증 데이터셋의 결과
val_pred = module.predict(iter_val).asnumpy()
val_label = iter_val.label[0][1].asnumpy()
val_perf = perf.write_eval(val_pred, val_label, save_dir, 'valid', epoch)
print_to_file('%d %f %f ' % (epoch, train_perf['COR'], val_perf['COR']))
## 성능 향상을 측정할 수 없는 경우에는 건너뛴다
if epoch > 0:
buf.append(val_perf['COR'] - old_val)
## 성능 향상을 측정할 수 있는 경우에는 향상 정도를 검사한다
if epoch > 2:
vals = buf.get()
vals = [v for v in vals if v != 0]
if sum([v < COR_THRESHOLD for v in vals]) == len(vals):
print_to_file('EARLY EXIT')
break
old_val = vla_perf['COR']
## 테스트 데이터셋 검증
test_pred = module.predict(iter_test).asnumpy()
test_label = iter_test.label[0][1].asnumpy()
test_perf = perf.write_eval(test_pred, test_label, save_dir, 'test', epoch)
print_to_file('TESTING PERFORMANCE')
print_to_file(test_perf)MXNet의 보일러플레이트
- 신경망 구성에 필요한 개별 요소를 계산 그래프로 구성
- 신경망에 입력된 데이터의 모양 설정
- 그래프의 모든 가중치를 임의 값으로 초기화
- 옵티마이저를 초기화
성능 지표
에폭당 관측되는 상관계수, 타깃, 추정 값 모두를 기록
def evaluate_and_write(pred, label, save_dir, mode, epoch):
if not os.path.exists(save_dir):
os.makedirs(save_dir)
pred_df = pd.DataFrame(pred)
label_df = pd.DataFrame(label)
pred_df.to_csv(os.path.join(save_dor, '%s_pred%d.csv' %(mode, epoch)))
label_df.to_csv(os.path.join(save_dor, '%s_label%d.csv' %(mode, epoch)))
return {'COR':COR(label, pred)}상관관계를 계산하는 함수
def COR(label, pred):
label_demeaned = label - label.mean(0)
label_sumsquares = np.sum(np.square(label_demeaned), 0)
pred_demeaned = pred - pred.mean(0)
pred_sumsquares = np.sum(np.square(pred_demeaned), 0)
cor_coef = np.diagonal(np.dot(label_demeaned.T, pred_demeaned)) / np.sqrt(label_sumsquares * pred_sumsquares)
return np.nanmean(cor_coef)순전파 네트워크
- 순전파 네트워크는 병렬화될 수 있어서 성능이 좋다
- 연속된 사건들에서 역동적이며 복잡한 시간축의 존재를 검사하는 데 좋다
- 순전파 네트워크의 구성요소는 더 크고 복잡한 시계열 딥러닝 구조에 통합되는 경우가 많다
순전파 네트워크는 완전연결계층의 연속으로 구성된다
def fc_model(iter_train, window, filter_size, num_filter, dropout):
X = mx.sym.Variable(iter_train,.provide_Data[0].name)
Y = mx.sym.Variable(iter_train.provide_label[0].name)
output = mx.sym.FullyConnected(data=X, num_hiddem = 20)
output = mx.sym.Activation(output, act_type = 'relu')
output = mx.sym.FullyConnected(data=output, num_hidden = 10)
output = mx.sym.Activation(output, act_type = 'relu')
output = mx.sym.FullyConnected(data=output, num_hidden = 321)
loss_grad = mx.sym.LinearRegressionOutput(data=output, label = Y)
return loss_grad, [v.name for v in iter_train.provide_data]
, [v.name for v in iter_train.provide_label]→ 3계층으로 구성된 완전연결된 네트워크로 첫 번째 계층은 20개의 은닉 유닛, 두 번째는 10개의 은닉 유닛으로 구성된다. 이 두 계층 다음에는 활성계층이 이어서 존재한다. 이 활성 계층으로 모델은 비선형성을 가지게 된다.
어텐션 기법
어텐션 : 입력되는 순서의 어떤 부분이 원하는 출력에 연관되는지 배울 수 있게 해줌
어떤 정보가 언제 중요한지는 시간 단계마다 학습되는 어텐션 가중치에 의해 수행된다
→ 모델의 출력이나 이전 단계의 은닉 상태를 곱해서 은닉 상태를 콘텍스트 벡터로 변환
순전파 어텐션 메커니즘
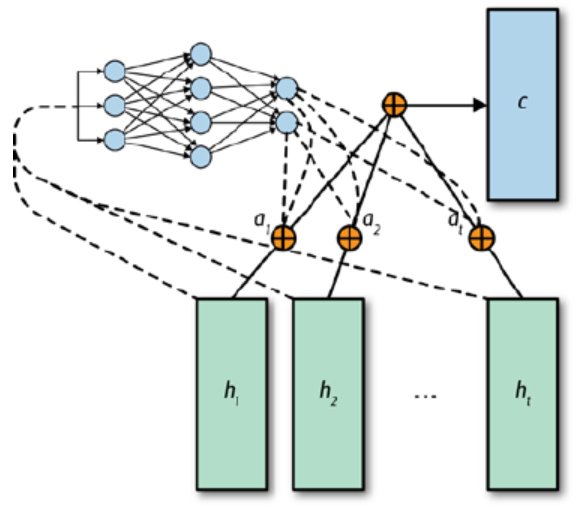
어텐션 메커니즘은 네트워크가 다른 시간대의 데이터에서 들어오는 상태 정보인 각 입력에 얼마나 가중치를 줄 것인지 학습할 수 있도록 해준다
→ 입력들의 최종 합을 계산할 때 어느 시간 단계에 더 가중치를 주는지 또는 덜 가중치를 주는지를 결정할 수 있도록 해준다
합성곱 신경망
합성곱 : 더 큰 행렬 위를 미끄러지듯이 움직이는 방식으로 적용하여 새로운 행렬을 만들어내는 것을 의미
합성곱 모델 → 데이터 : NTC 형식
def cnn_model(iter_train, input_feature_shape, X, Y, win, sz_filt, n_filter, drop):
conv_input = mx.sym.reshape(data = X, shape = (0, 1, win, -1))
## 합성곱은 4d 입력을 기대한다(배치크기x채널x높이x너비)
## 여기서 채널=1이고
## 높이 = 시간, 너비 = 전기사용 지역을 구분하는 채널이다
cnn_output = mx.sym.Convolution(data=conv_input, kernel = (sz_filt, input_feature_shape[2]), num_filter=n_filter)
cnn_output = mx.sym.Activation(Data=cnn_output, act_type = 'relu')
cnn_output = mx.sym.reshape(mx.sym.transpose(data=cnn_output, axes=(0, 2, 1, 3)), shape = (0, 0, 0))
cnn_output = mx.sym.Dropout(cnn_output, p=drop)
output = mx.sym.FullyConnected(data=cnn_output, num_hidden = input_feature_shape[2])
loss_grad = mx.sym.LinearRegression(data=output, label=Y)
return loss_grad, [v.name for v in iter_train.provide_data], [v.name for v in inter_train.provide_label])→ 단일 축을 따라 시간이 배치되어 순서를 가진다
인과적 합성곱
: 사건의 의미와 인과관계를 만들기 위해 변형된 인과적 합성곱
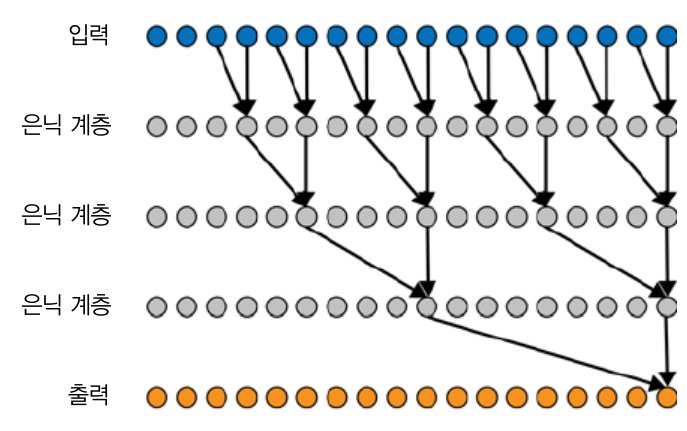
→ 팽창된 인과적 합성곱
시간상 이른 시점의 데이터만 합성곱 필터로 들어가 시간의 인과관계란 개념을 도입한다
팽창 : 각 계층의 수준에서 어떤 한 시점의 데이터는 하나의 합성곱 필터에만 들어감
행렬의 좌측에 패딩을 추가하고, 패딩을 valid로 설정하여 합성곱이 실제 경계선 내에서만 수행되게 해준다
시계열을 그림으로 변환하기
합성곱 모델을 시계열에 관련되도록 하는 방법 : 시계열을 그림으로 변환하는 방법 찾기
재귀그림을 구성해 그림으로 바꿔주기
→ 재귀그림 : 단계적 상태 공간에서 시계열이 대략적으로 이전 시점과 동일한 단계와 상태를 다시 재방문할 때를 묘사하는 방법
순환 신경망
순환 신경망(RNN) : 시간에 따른 입력값들에 동일한 파라미터가 계속 적용되는 신경망의 한 종류
RNN과 순전파 신경망의 차이점
- RNN은 한 번에 한 시간 단계를 차례대로 관찰
- RNN은 한 시간 단계에서 다음 단계로 상태를 저장
- RNN에는 은닉 상태를 포함한 시간 단계 간의 상태를 갱신하기 위한 파라미터가 있다
순환구조가 셀기반으로 필자는 GRU를 RNN 셀로 사용하고 있다
→ GRU : 장단기 메모리(LSTM)의 간소화 버전
GRU와 LSTM은 RNN을 사용할 때 발생했던 문제인 경사 폭발과 경사 소멸을 해결하는데 도움을 준다
→ 활성 함수의 형식과 전달받은 정보를 통과시킬지 말지를 갱신 게이트에서 학습하는 방법을 통해 해결
def rnn_model(iter_train, window, filter_size, num_filter, dropout):
input_feature_shape = iter_train.provide_data[0][1]
X = mx.sym.Variavle(iter_train.provide_data[0].name)
Y = mx.sym.Variable(iter_train.provide_label[0].name)
rnn_cells = mx.rnn.SequentialRNNCell()
rnn_cells.add(mx.rnn.GRUCell(num_hidden = args.rnn_units))
rnn_cells.add(mx.rnn.DropoutCell(droupout))
outputs, _ = rnn_cells.unroll(length=window, inputs = X, merge_outputs = False)
output = mx.sym.FullyConnected(data=outputs[-1], num_hidden = input_feature_shape[2])
loss_grad = mx.sym.LinearRegressionOutput(data=output, label = Y)
return loss_grad, [v.name for v in iter_train.provide_data], [v.name for v in iter_train.provide_label]오토인코더
: 두 개의 순환 계층으로 구성되며 첫 번째 계층이 완료 상태에 도달하면, 은닉 상태가 두 번째 계층으로 전달된다
→ 첫 번째 계층의 은닉 상태가 일종의 요약 기능을 가지게 된다
복합 구조
변형된 LSTNet : AR 모델과 병렬적으로 기본적인 순환 계층 및 스킵 순환 계층의 출력을 합한 것
→ 각 순환 계층에 주입된 입력은 시간과 채널의 축 모두에 대해 합성곱 연산을 수행한 합성곱 계층의 출력
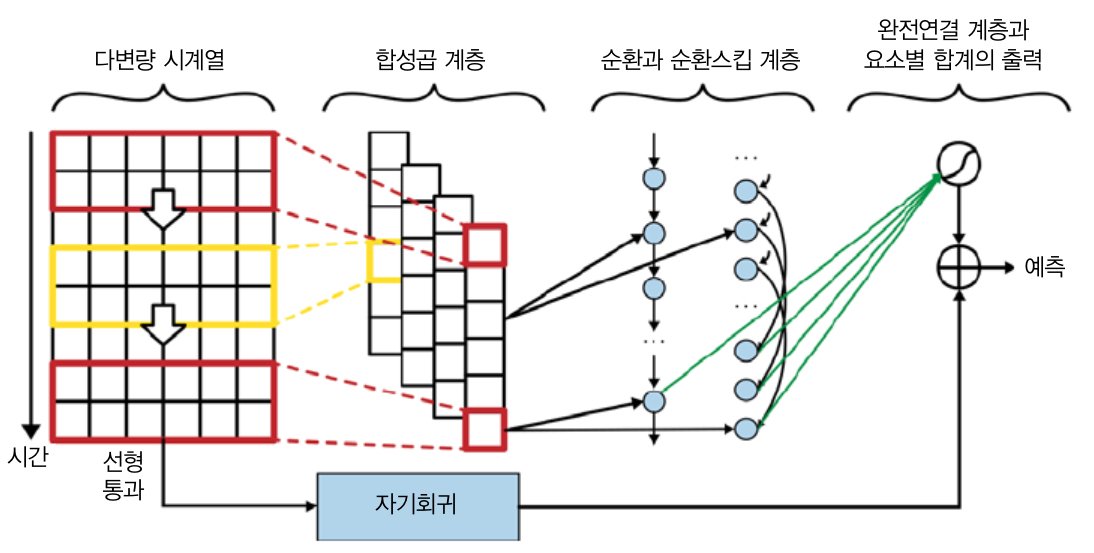
합성곱 계층을 적용
## 패딩 기능을 사용하려면 4d나 5d가 되어야 한다
conv_input = mx.sym.reshape(data=X, shape = (0, 1, win, -1))
## 합성곱 요소
## 시간 윈도의 마지막에 패딩을 추가
cnn_output = mx.sym.pad(data=conv_input, mode = 'constant', constant_value = 0, pad_width = (0, 0, 0, 0, 0, sz_filt-1, 0, 0))
cnn_output = mx.sym.Convolution(data=cnn_output, kernel = (sz_filt, input_feature_shape[2]), num_filter = n_filter)
cnn_output=mx.sym.Activation(data=cnn_output, act_type='relu')
cnn_output = mx.sym.reshape(mx.sym.transpose(data=cnn_output, axes = (0, 2, 1, 3)), shape=(0, 0, 0))
cnn_output = mx.sym.Dropout(cnn_output, p=drop)RNN을 입력이 아닌 합성곱 요소에 적용
## 순환 요소
stacked_rnn_cells = mx.rnn.SequentialRNNCell()
stacked_rnn_cells.add(mx.rnn.GRUCell(num_hidden=args.rnn_units))
outputs, _ = stacked_rnn_cells.unroll(length=win, inputs=cnn_output, merge_outputs=False)
rnn_output = outputs[-1]
n_outputs = input_feature_shape[2]
cnn_rnn_model = mx.sym.FullyConnected(data=rnn_output, num_hidden=n_outputs)AR 모델을 학습
## AR 요소
ar_outputs = []
for i in list(range(input_feature_shape[2])):
ar_series = mx.sym.slice_axis(data=X, axis=2, begin=i, end=i+1)
fc_ar = mx.sym.FullyConnected(data=ar_series, num_hidden=1)
ar_outputs.append(fc_ar)
ar_model = mx.sym.concat(*ar_outputs, dim=1)