9. 시계열을 위한 머신러닝
- 클러스터링과 트리 기반 방법론
시계열 분류
cesium 시계열 관련 패키지
: 여러 가지 유용한 데이터셋 제공
서로 다른 EEG 측정 모습
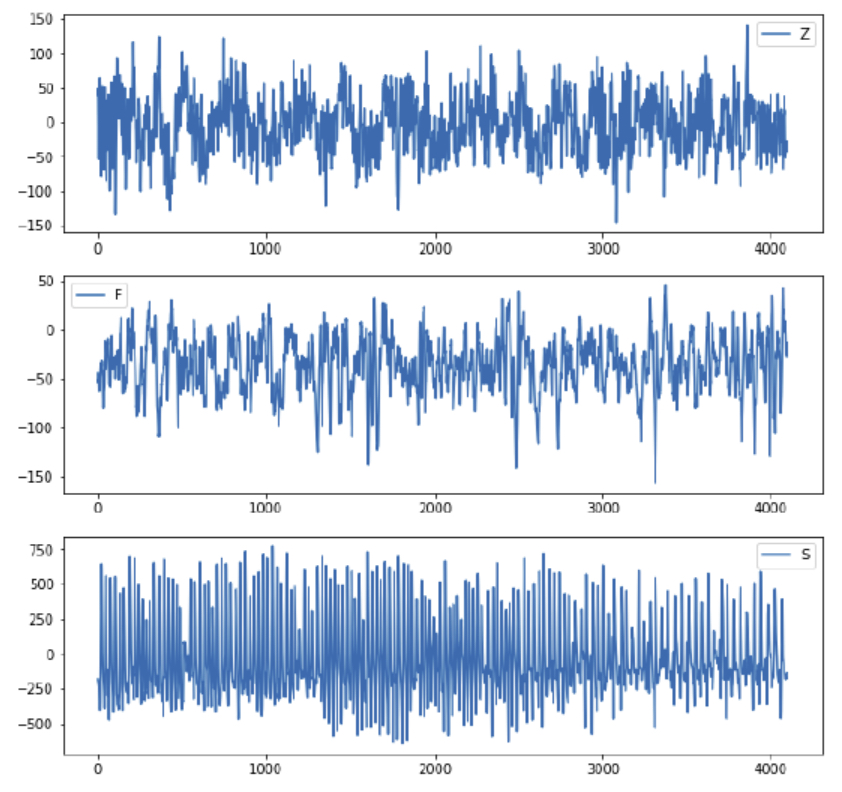
→ 서로 다른 시간에 서로 다른 환자를 대상으로 측정한 독립적인 시계열
cesium 으로 특징의 생성 방법
from cesium import featurize.featurize_time_series as ft
features_to_use = ["amplitude", "percent_beyond_1_std", "percent_close_to_median", "skew", "max_slope"]
fset_cesium = ft(times = eeg["times"], values = eeg["measurements"], errors = None, features_to_use = features_to_use, scheduler = None)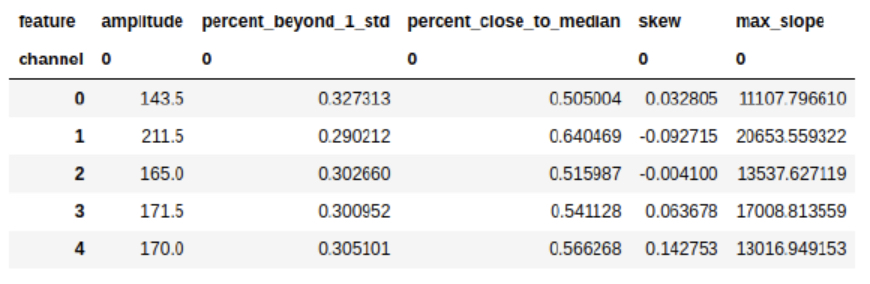
위 코드로 다음과 같은 출력된 특징을 생성한다.
결정 트리 기법
: 한 번에 한 단계씩, 비선형적인 방식으로 결정을 내리는 방식을 반영
📌 랜덤포레스트
: 하나의 결정 트리가 아니라, 여러 개의 결정 트리를 사용
→ 학습될 트리의 개수, 각 트리에 허용되는 최대 깊이에 대한 파라미터에 따라 구조가 결정됨
하지만 원시 시계열 데이터를 사용할 때는 다음과 같은 문제가 있다
- 균일하지 않은 길이의 시계열을 다루는 것은 복잡할 수 있다
- 대규모 입력은 계산 비용이 비싼 모델과 학습 과정의 결과를 초래할 수 있다
- 특정 시간 단계가 매우 중요하지 않다고 가정하면 트리 관점에서는 시간 단계를 개별 입력으로 봐서 매우 심한 노이즈와 약한 신호만 존재
원시 데이터가 특징들로 압축되어 요약하면 랜덤 포레스트가 유용할 수 있다
- 효율성/계산 자원의 관점에서 볼 때 유용
- 과적합의 위험을 줄이는 데 좋음
- 과정의 기본 동작에 대해 작동하는 모델이나 가설이 없는 시계열 데이터에 적합
📌 그레이디언트 부스팅 트리
- 차례대로 트리를 만든다 - 각 트리는 이전 트리들의 결합에 대한 잔차를 예측
- 첫 번째 트리는 데이터와 일치하려고 시도
- 두 번째 트리는 타깃에서 예측된 값을 뺀 잔차를 예측
- 세 번째 트리는 타깃에서 첫 번째 트리가 예측한 값, 첫 번째 트리의 잔차에 대해 두 번째 트리가 예측한 값을 뺀 것을 예측
→ 모델의 복잡도에 대한 패널티 항을 포함한 손실 함수를 최소화
예제 코드
EEG 데이터에 랜덤포레스트 사용
from sklearn.ensemble import RandomForestClassifier
rf_clf = RandomForestClassifier(n_estimators = 10, max_depth = 3, random_state = 21)
rf_clf.fit(X_train, y_train)→ 전체 EEG 데이터 대신 요약 통계를 입력으로 사용해 좋은 성능을 보임
XGBoost 사용
import xgboost as xgb
xgb_clf = xgb.XGBClassifier(n_estimators = 10, max_depth = 3, random_state = 21)
xgb_clf.fit(X_train, y_train)→ 성능을 확인해보면 XGBoost가 랜덤포레스트보다 약간 더 좋다
XGBoost가 성능이 더 좋은 이유가 특정 하이퍼파라미터 때문이 아닐까 실험
두 앙상블에 대해 동일한 트리 개수를 부여하고, 트리들의 깊이를 제한해 복잡도를 낮춤
## 같은 수의 트리(10), 그러나 복잡성은 낮춘 경우를 테스트
## max_depth = 2
## XGBoost
xgb_clf = xgb.XGBClassifier(n_estimators = 10, max_depth = 2, random_state = 21)
xgb_clf.fit(X_train, y_train)
## 랜덤포레스트
rf_clf = RandomForestClassifier(n_estimators = 10, max_depth = 2, random_state = 21)
rf_clf.fit(X_train, y_train)→ 트리의 복잡성을 더 낮추더라도 랜덤포레스트 모델보다 XGBoost 모델이 더 좋은 정확도를 유지한다
부스팅은 항상 모든 특징을 사용하고 관련도가 높은 것에 특혜를 줘서 의미 없는 특징이 무시될 가능성이 높지만 배깅(랜덤포레스트)의 결과로 얻은 트리들은 덜 의미있는 특징을 사용하도록 강요받을 수 있기 때문
분류와 회귀
그레이디언트 부스팅 트리 모델의 장점 : 자율적으로 접근하는 능력을 가짐
→ 모델이 스스로 관련성이 적거나 노이즈가 많은 특징은 제거하고, 가장 중요한 특징들에 초점을 맞춘다는 것
클러스터링
: 분석의 목적상 서로 유사한 데이터가 의미 있는 집단을 구성한다
분류와 예측 모두에 클러스터링이 사용될 수 있다
- 분류
원하는 수만큼의 집단을 모델의 학습 단계에서 식별할 수 있다 - 예측
순수 클러스터링이나 거리 측정법을 이용하는 형태의 클러스터링이 사용될 수 있다
시계열 데이터에 클러스터링 기법을 적용하는 상황에서의 거리 측정법
- 특징에 기반한 거리
시계열을 위한 특징을 생성하고, 이들을 데이터의 계산을 위한 좌표로 취급 - 원시 시계열 데이터에 기반한 거리
서로 다른 시계열이 얼마나 가까운지 결정하는 방법을 찾음
📌 데이터에서 특징 생성하기
투영 그래프 : 2D 공간의 이미지를 1D 공간으로 변환한 것
범주형 데이터를 1D 히스토그램으로 표현하는 방법
## 범주형 데이터 그래프
plt.plot(words.iloc[1, 1:-1])
## 히스토그램
plt.hist(words.iloc[1, 1:-1], 10)
단어의 차이를 확인하는 두 단어에 대한 2D 히스토그램 구성
x = np.array([])
y = np.array([])
w = 12
selected_words = words[words.word == w]
selected_words.shape
for idx, row in selected_words.iterrows():
y = np.hstack([y, row[1:271]])
x = np.hstack([x, np.array(range(270))])
fig, ax = plt.subplots()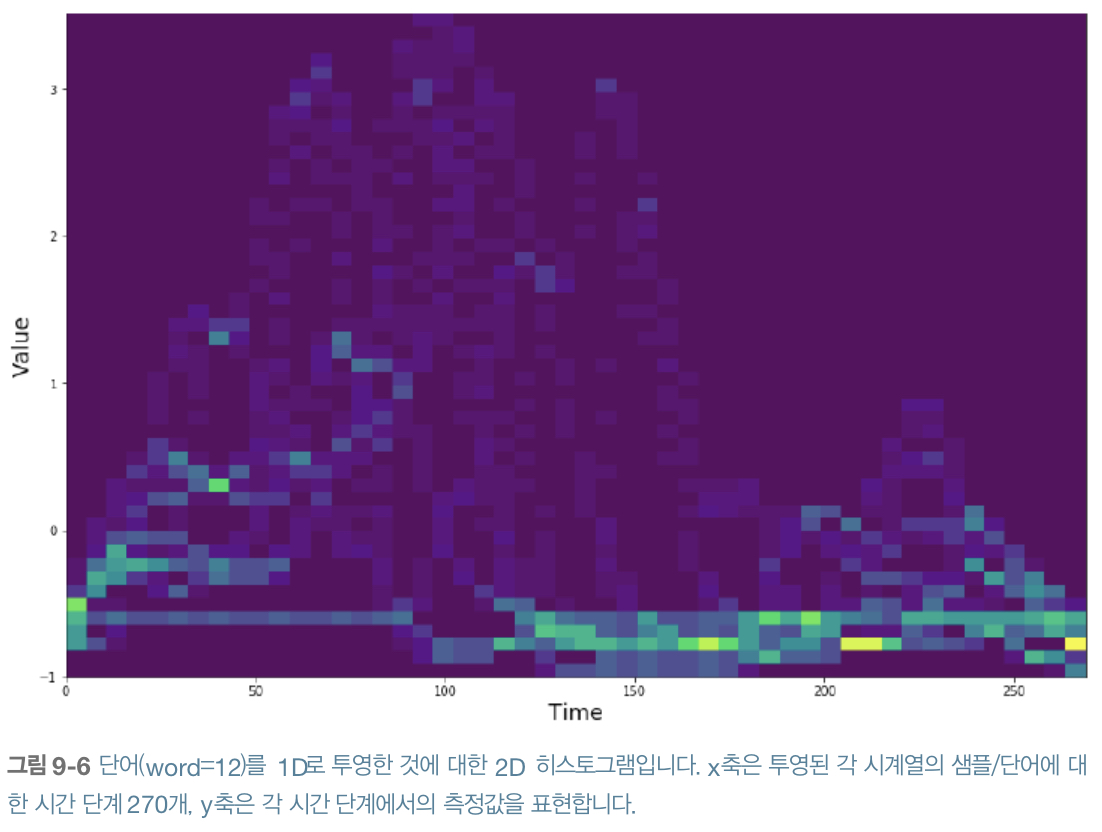
2D 히스토그램은 개별 범주 내 특징에 대한 가변성을 알려주는 데 유용하여 하나의 데이터에 과도하게 의존하지 않는 특징의 구성 방식을 고려할 수 있음
히스토그램은 값들의 위치를 특징짓지 않고 그 값의 종류를 나타냄
→ 고점이 안정적인 시간의 위치에 분포되지 않은 투영된 시계열을 다룰 때 중요한 역할
시간 단계 270개를 가진 시계열의 특징 생성
from cesium import featurize.featurize_time as ft
word_vals = words.iloc[:, 1:271]
times = []
word_values = []
for idx, row in word_vals.iterrows():
word_values.append(row.values)
times.append(np.array([i for i in range(row.values.shape[0])]))
features_to_use = ['amplitude', 'percent_beyond_1_std', 'percent_close_to_median']
featurized_hists = ft(times = times, values = word_values, errors = None, features_to_use = features_to_use, scheduler = None)히스토그램 생성, 이를 또 다른 시계열로 취급해 특징 생성
## 히스토그램에서 파생된 일부 특징을 생성
times = []
hist_values = []
for idx, row in words_features.iterrows():
hist_values.append(np.histogram(row.values, bins = 10, range=(-2.5, 5.0))[0]+.0001)
## 0들은 하위 작업에서 문제를 초래
times.append(np.array([i for i in range(9)]))
features_to_use = ["amplitude", "percent_close_to_median", "skew"]
featurized_hists = ft(times = times, values = hist_values, errors = None, features_to_use = features_to_use, scheduler = None)서로 다른 방식으로 얻은 특징들을 결합
features = pd.concat([featurized_words.reset_index(drop=True), featurized_hists], axis = 1)📌 시간을 인식하는 거리 측정법
시계열 간의 유사성 측정 문제를 다루기 위한 거리 지표를 정의 : 동적시간왜곡(DTW)
동적시간왜곡의 작동 방식

표시된 두 곡선 사이의 점들 간 최상의 정렬을 찾아 두 곡선의 모양을 비교하기 위해 시간축이 왜곡된다
DTW의 규칙
- 한 시계열의 모든 시간은 최소한 다른 시계열의 한 시간에 대응해야 한다
- 각 시계열의 처음과 끝은 서로 처음과 끝에 대응해야 한다
- 시간 만의 매핑은 과거가 아니라 미래로 이동하는 관계만 표현해야 한다
def distDTW(ts1, ts2):
## 설정과정
DTW = {}
for i in range(len(ts1)):
DTW[(i, -1)] = np.inf
for i in range(len(ts2)):
DTW[(-1, i)] = np.inf
DTW[(-1, -1)] = 0
## 한 번에 한 단계씩
## 최적값 계산
for i in range(len(ts1)):
for j in range(len(ts2)):
dist = (ts1[i] - ts2[j])**2
DTW[(i, j)] = dist + min(DTW[(i-1, j)], DTW[(i, j-1)], DTW[(i-1, j-1)])
## 동적 프로그래밍의 한 예
## 완전한 경로를 찾으면 그 경로를 반환한다
return sqrt(DTW[len(ts1-1, len(ts2)-1])→ DTW 거리는 동적 프로그래밍의 문제 중 하나로 각 시계열의 시작부터 끝까지 한 번에 한 단계씩 진행할 수 있으며 한 단계에 대한 해결책은 이전 단계의 결정을 참조하여 구축된다
DTW 이외에도 시계열 간 거리를 측정하는 방법
- 프레셰 거리
: 시간 왜곡과 비슷한 두 곡선의 순회 동안 두 곡선 간 거리를 최소화할 수 있는 최대 거리 - 피어슨 상관
: 상관관계 지표를 최대화하여 시계열 간의 거리를 최소화 - 최장공통부분수열
: 일련의 범주형값을 나타내는 시계열에 적합한 거리 측정으로 최장공통부분수열로 두 시계열의 유사성을 판단
거리 지표를 자동으로 선택하는 방법은 없기에 다음의 균형을 찾기 위해 최선의 판단을 내려야 한다
- 계산 자원 사용의 최소화
- 최종 목표와 가장 관련 있는 시계열의 특징을 강조하는 지표를 선택
- 거리 지표가 사용한 분석 방법의 가정, 강점 및 약점을 반영하는지 확인
📌 클러스터링 코드
정규화된 특징에 대한 계층적 클러스터링
특징들은 서로 다른 단위의 크기를 가질 수 있어서 단일 거리 지표를 적용하려면 정규화해야 한다
from sklearn import preprocessing
feature_values = preprocessing.scale(features.values)계층적 클러스터링 알고리즘을 사용하고, 데이터셋에 포함된 단어 50개에 매칭되는 클러스터링을 찾기 위해 클러스터 50개에 대한 적합을 수행
from sklearn.cluster import AgglomerativeClustering
feature_clustering = AgglomerativeClustering(n_clusters = 50, linkage = 'ward')
feature_clustering.fit(feature_values)
words['feature_labels'] = feature_clustering.fit_predict(p)클러스터가 단어 라벨에 대해 유용한 대응을 보이는지 확인
from sklearn .metrics.cluster import homogeneity_score
homogeneity_score(words.word, words.feature_labels)DTW 거리 평가 지표와 계층적 클러스터링
DTW로 쌍별 거리 행렬 계산한 것 결과 저장
p = pairwise_distances(X, metric = distDTW)
## 계산하는 데 시간이 꽤 걸리므로 재사용을 위해 따로 저장
with open("pairwise_word_distances.npy", "wb") as f: np.save(f, p)계층적 클러스터링 알고리즘 사용
from sklearn.cluster import AgglomerativeClustering
dtw_clustering = AgglomerativeClustering(linkage = 'average', n_clusters = 50, affinity = 'precomputed')
words['dtw_labels'] = dtw_clustering.fit_predict(p)적합된 클러스터와 이미 알고 있는 라벨 간의 대응 관계를 비교
from sklearn.metrics.cluster import homogeneity_score, completeness_score
homogeneity_score(words.word, words.dtw_labels)
completeness_score(words.word, words.dtw_labels)→ 특징 기반보다 DTW 기반 클러스터링의 성능이 훨씬 우수하다
