SPARK
Spark
In-Memory 기반 분산 쿼리 및 처리 Engine
목적: 기존 작업 -> 반복 작업 효율성 낮음
Memory 기반 작업 -> 반복 작업 효율성 증가 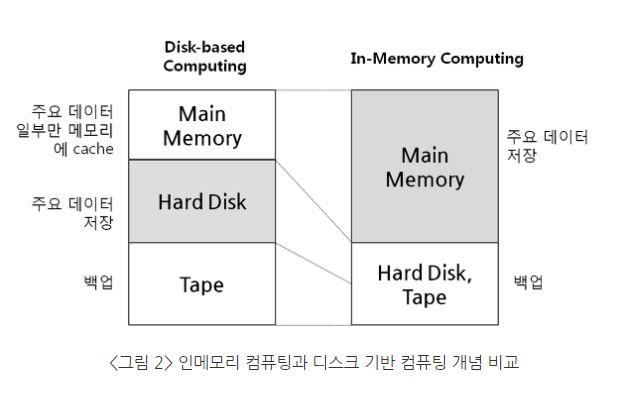
Cf. In-Memory VS Disk-based
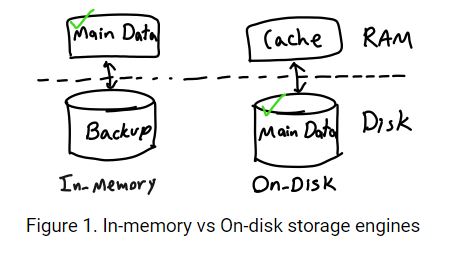
In-Memory 기반은 메모리를 데이터안에 저장하고 backup을 위해 disk를 사용한다. 반면 on-disk 방법은 disk에 저장하고 caching을 위해 메모리를 사용한다. RAM이 DISK보다 훨씬 빠르다..
특징
- 다양한 처리 통합할 수 있는 유연한 환경 제공
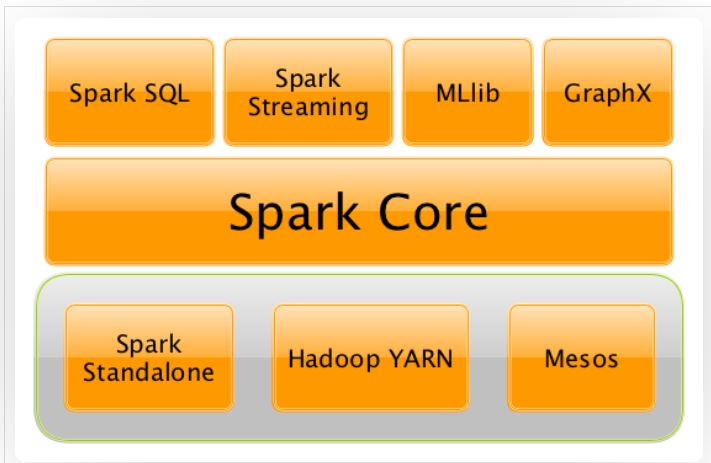
- Spark SQL = 데이터 관계 및 표현, 그래프 및 SQL 조회
- Spark Streaming = Data Streaming
- Mlib = 알고리즘 모델 활용/분석
- Graph x = 데이터 관계 및 표현
출처: https://blog.lgcns.com/176
- 다양한 언어 지원
R(Spark_R), SQL(Spark_sql), Python(pyspark), Scala(spark-shell), java(spark-submit)
scala 기반에서 최적의 성능
Spark command
spark-shell >> Spark shell로 접속하여 작업수행(scala) 기반
pyspar >> Spark shell로 접속하여 작업수행(python) 기반
spark-submit >> Jar faile를 통한 Spark 실행
spark-sql >> Hive 사용시 실행 Engine: Spark
시각화 Tool 활용 지원
웹 기반 NoteBook(Zeppelin) 작업 환경 제공 >> 데이터 시각화, 차트 등 다양한 기능 제공
