
추석 연휴 동안 푹 쉬고 힘내서 다시 CS 공부 드감니다,,
`
확실히 잘 정리된 문서를 읽는 것도 정말 좋은 공부 방법이지만, 아직 개념이 부족한 상태에서는 누군가가 자신이 이해한 방법으로 고민해서 발표해 주는 내용을 듣는 것이 도움이 많이 되는 것 같다.
저번 포스트부터 우테코 크루들이 발표한 내용을 바탕으로 부족한 개념들을 채우면서 블로그에 정리도 같이 해보고 있는데 오늘은 운영체제를 주제로 발표한 몇몇 토픽들을 정리해 보려고 한다! 두구두구..
Topic 3. 가상메모리
메모리 관리 기법으로 프로세스 전체가 메모리 내에 올라오지 않더라도 실행이 가능하도록 하는 것이다.

어떻게? 왜 ?! 이렇게 동작할 수 있을까 를 지금부터 설명해 주신다.
가상 메모리를 이해하기 위해서는 컴퓨터 구조, 프로그램 실행, 주소바인딩, 스왑영역에 대해 배경 지식이 필요해서 설명 전에 간략하게 이 개념들에 대해서도 다뤄 주셨다 (오마이,, 감사합니다)
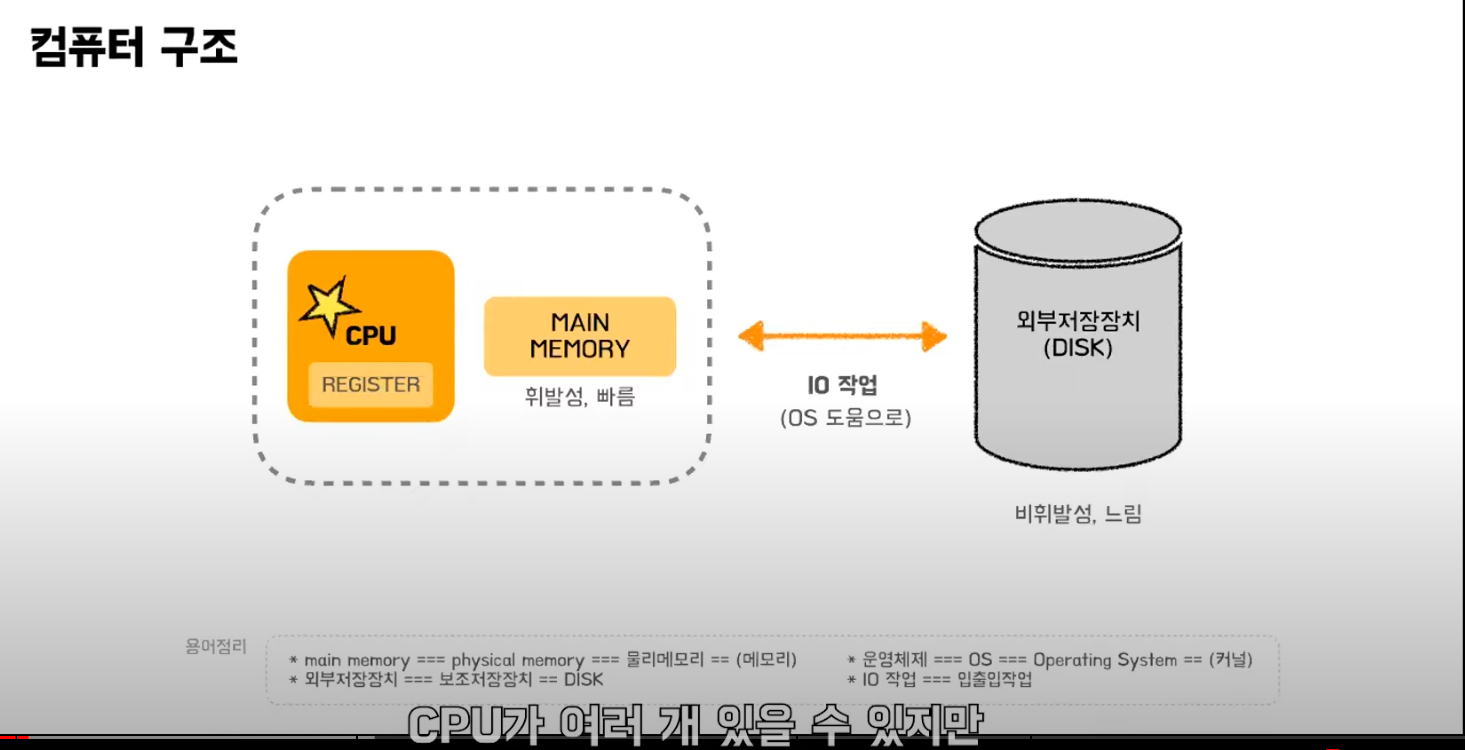
CPU는 연산할 때 메모리의 값을 참조해야하는데, 레지스터의 값을 참조한다. 레지스터는 자료를 보관하는 매우 빠른 기억장소이다. but 용량이 매우 작다. 그래서 레지스터보단 좀 느리지만 용량이 더 큰 메인메모리(physical memory)에서 해당 내용을 참조한다. 레지스터 메인메모리는 빠르지만 휘발성이기 때문에 더 많은 내용을 다루기 위해 비휘발성인 DISK(외부저장장치)를 참조한다.
프로그램이 실행되는 것이란 CPU가 일을 하는 것이고, CPU는 메인 메모리까지의 값만 참조할 수 있다. 따라서 CPU가 일을 하기 위해서는 프로그램 정보가 메모리에 올라와야 한다. 일반적으로 프로그램은 DISK에 이진 실행 파일 형식으로 존재한다. 개발자가 작성한 소스는 컴파일러, 링커의 작업으로 실행 파일을 생성한다.
프로그램을 실행하면 해당 이진 실행파일이 물리메모리에 올라오게 된다. 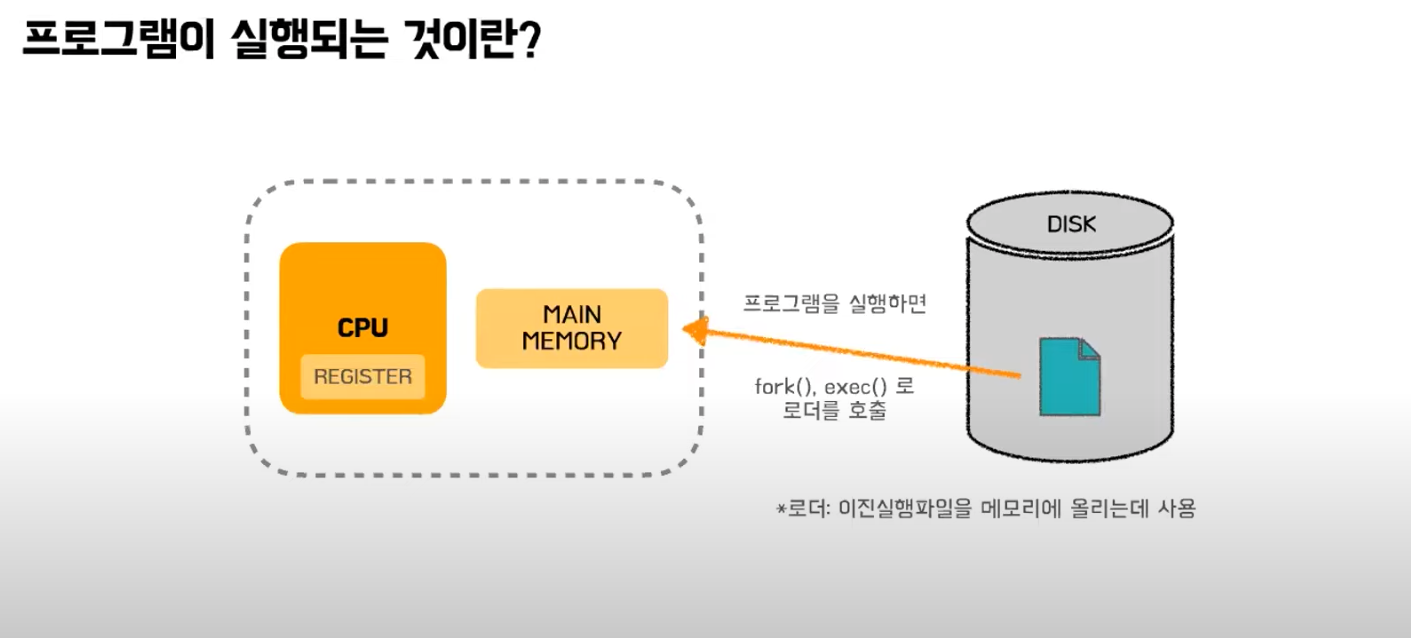
프로그램이 프로세스 형태(CPU가 참조할 수 있는 형태)로 배치되는 것이다. (이전 프로세스 관련 주제에서 다뤘던..!)
fork 요청으로 새 프로세스를 생성하고 exec 요청으로 로더를 호출한다. 로더는 새로 생성된 프로세스의 주소공간을 사용하여 지정된 실행파일을 메모리에 올리는데 사용된다.
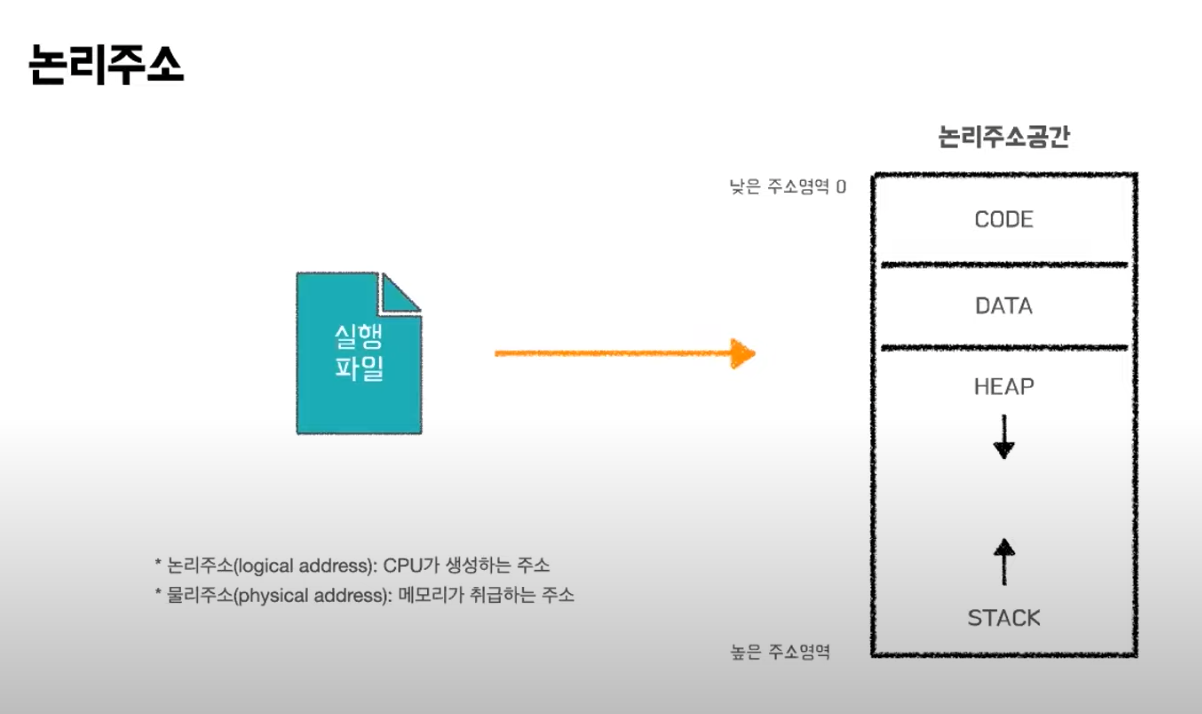 논리주소는 CPU가 바라보는 주소이다. 논리주소가 물리적 메모리의 특정위치로 매핑되는데 이 작업을 주소바인딩이라고 한다.
논리주소는 CPU가 바라보는 주소이다. 논리주소가 물리적 메모리의 특정위치로 매핑되는데 이 작업을 주소바인딩이라고 한다. 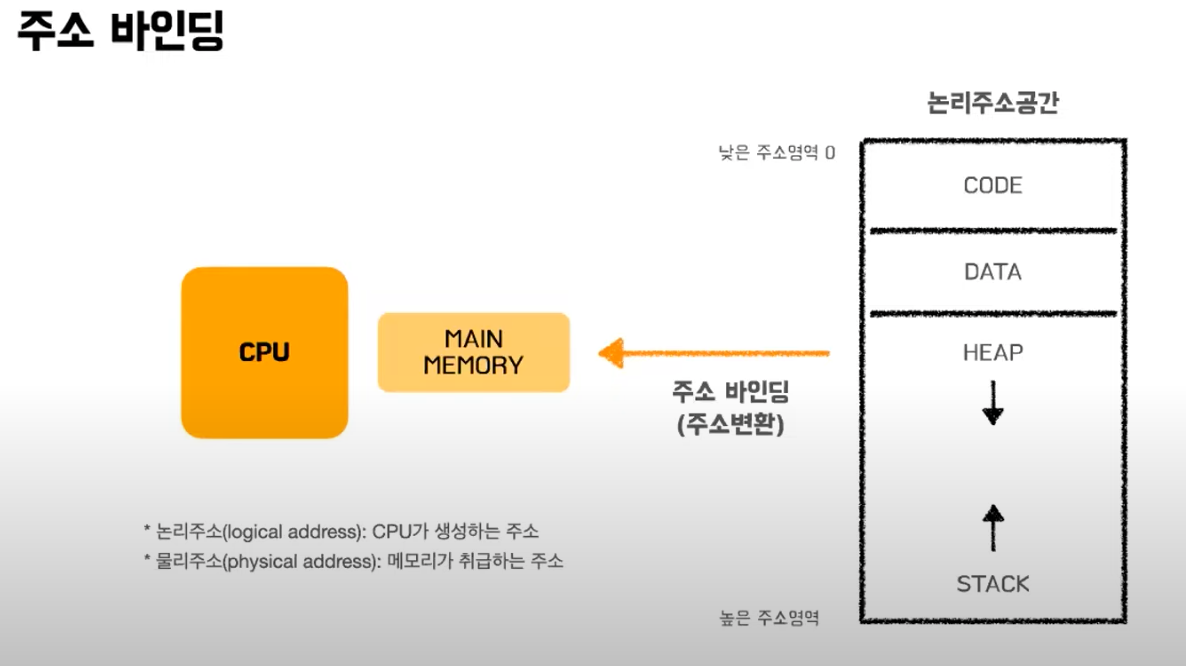
바인딩 시점에 따라 물리주소와 논리주소는 같을 수도 다를 수도 있다.
(컴파일 타임 / 로드 타임 / 실행 시간)
이 중에서 가상메모리를 사용하기 위해서는 실행 시간 바인딩이 지원되어야 한다. 이 기법을 사용하면 논리주소와 물리주소가 달라지게 된다. 실행시간 바인딩을 하기 위해서는 하드웨어적 지원이 필요한데 CPU가 주소를 참조할 때마다 주소매핑테이블을 이용해 바인딩을 점검한다. 그러기 위해 기준 레지스터와 한계 레지스터를 포함하여 MMU라는 하드웨어의 지원이 필요하다.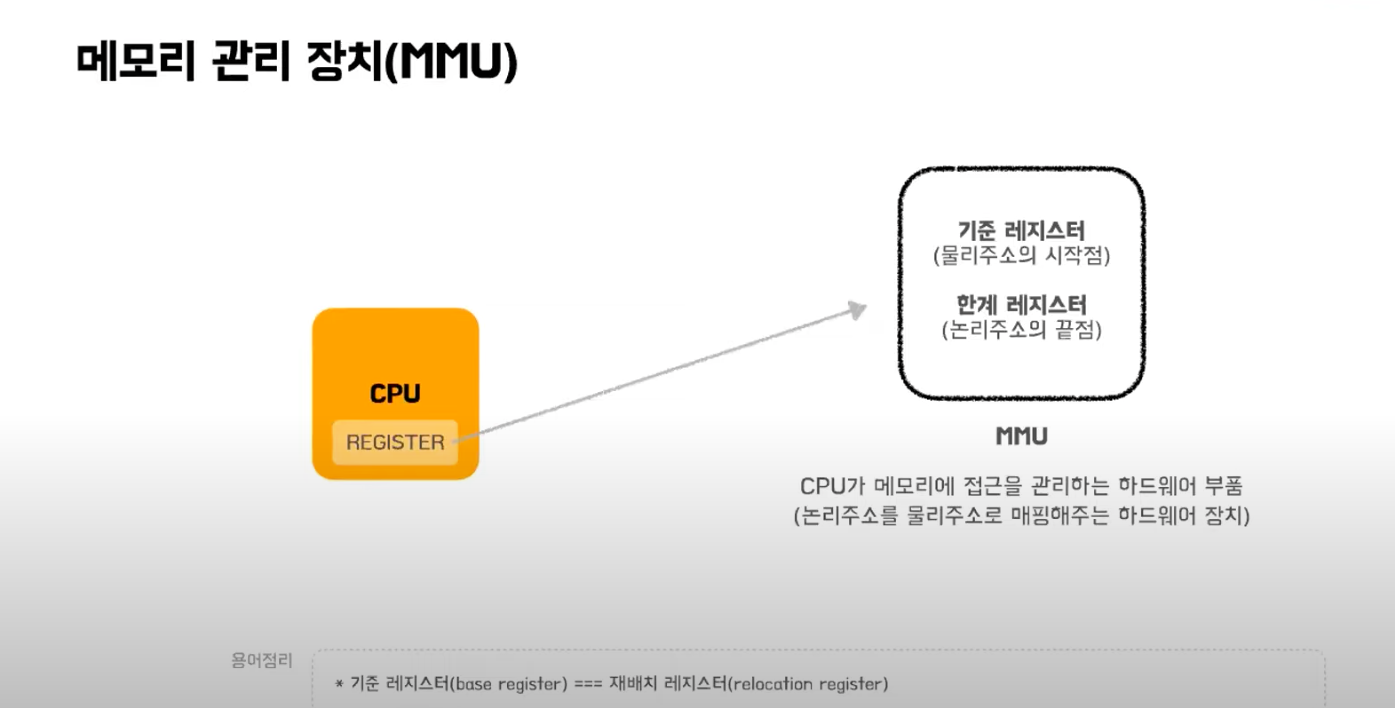
기준 레지스터는 현재 프로세스의 물리적 메모리의 시작주소가 저장되어 있어서 논리주소 + 기준 레지스터 값으로 물리적 주소의 위치를 찾는다. 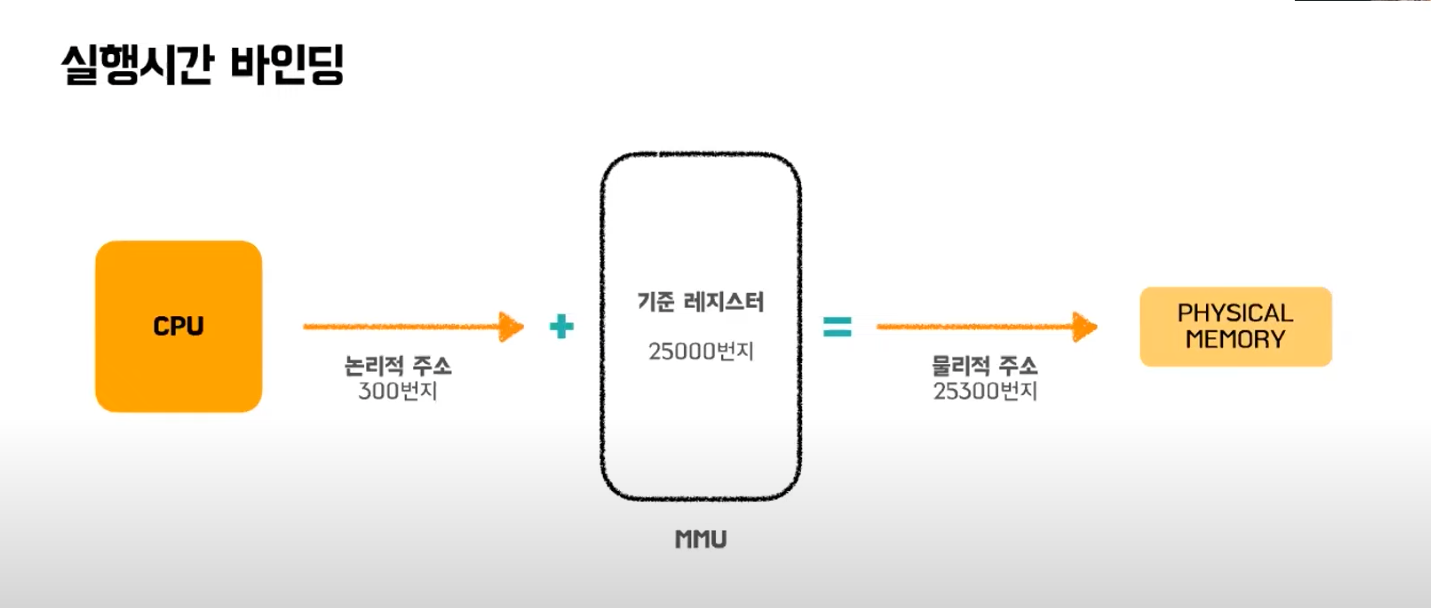
프로세스는 자기 자신만의 고유한 주소공간을 가지기 때문에 동일한 논리주소 값이라도 동일한 논리주소여도 각 프로세스마다 다른 내용을 담고 있다. MMU 기법에서는 문맥 교환도 기준 레지스터값을 각 프로세스에 맞게 설정한다.
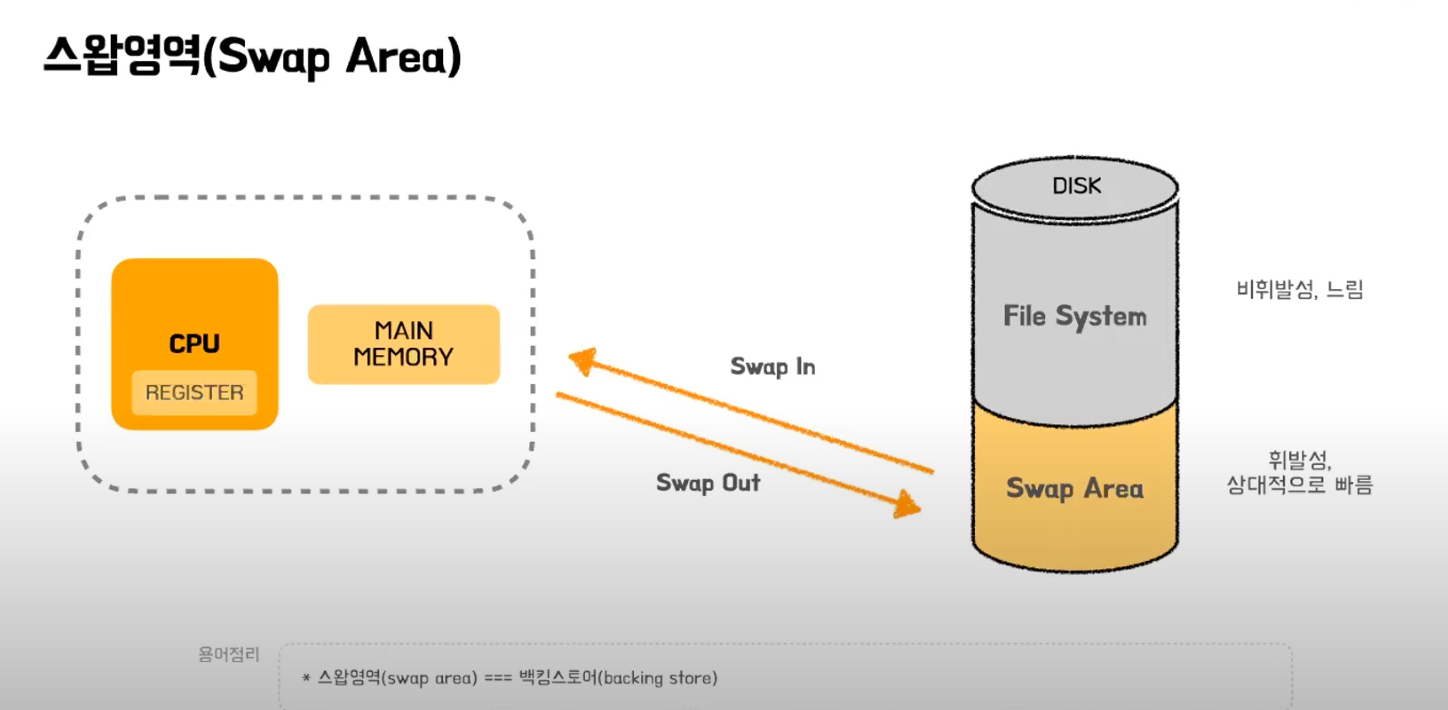
스왑영역은 물리메모리의 데이터를 일시적으로 내려놓는 공간으로 DISK에 붙어있다. 하지만 파일시스템(DISK)와 다르게 메모리 공간의 확장으로 사용하기 때문에 휘발성이고 빠르며 프로세스 수행 중에만 일시적으로 이곳에 저장된다. 일반적으로 파일 시스템에 접근하는 것보다 좀 더 빠른 접근이 가능하다. (공간효율성 보다는 시간효율성을 고려한 저장)
그러면 왜 가상메모리가 필요할까??
여러개의 프로그램을 실행할 수록 각 프로그램에 할당 될 수 있는 물리메모리의 공간이 줄어든다. 물리메모리보다 용량이 크거나 한번에 수행하고 싶은 프로그램이 많아지게 되면 스왑영역으로도 실행이 불가능해질 것이다. 이런 불편함 때문에 가상메모리 개념이 등장했다.
좋은 프로그램일 수록 자주 사용되지 않는 방어 코드나 관리 코드가 많다고 한다. 이 코드들을 효율적으로 저장하기 위해 가상메모리의 필요성이 재기되는데 가상메모리를 사용하면 프로세스 전체를 메모리에 올릴 필요 없이 필요한 내용만 메모리에 올려 실행할 수 있다.
이 기법이 요구 페이징 기법 (Demand Paging)이다. 이 기법에서는 주소공간이 여러개의 페이지로 나누어져 있는데, 그 중 당장 필요한 페이지만 물리 메모리에 적재합니다. 필요한 정보인지 여부는 유무효 비트를 사용해서 구분한다.
-
Valid : 해당 페이지가 메모리에 있음
-
Invalid : 해당 페이지가 메모리에 없음 (Page Fault)
-> 해당 페이지가 가상 공간에 없음 => 해당 프로세스 중단-> 보조저장장치에 존재 => 보조저장장치에서 가져옴
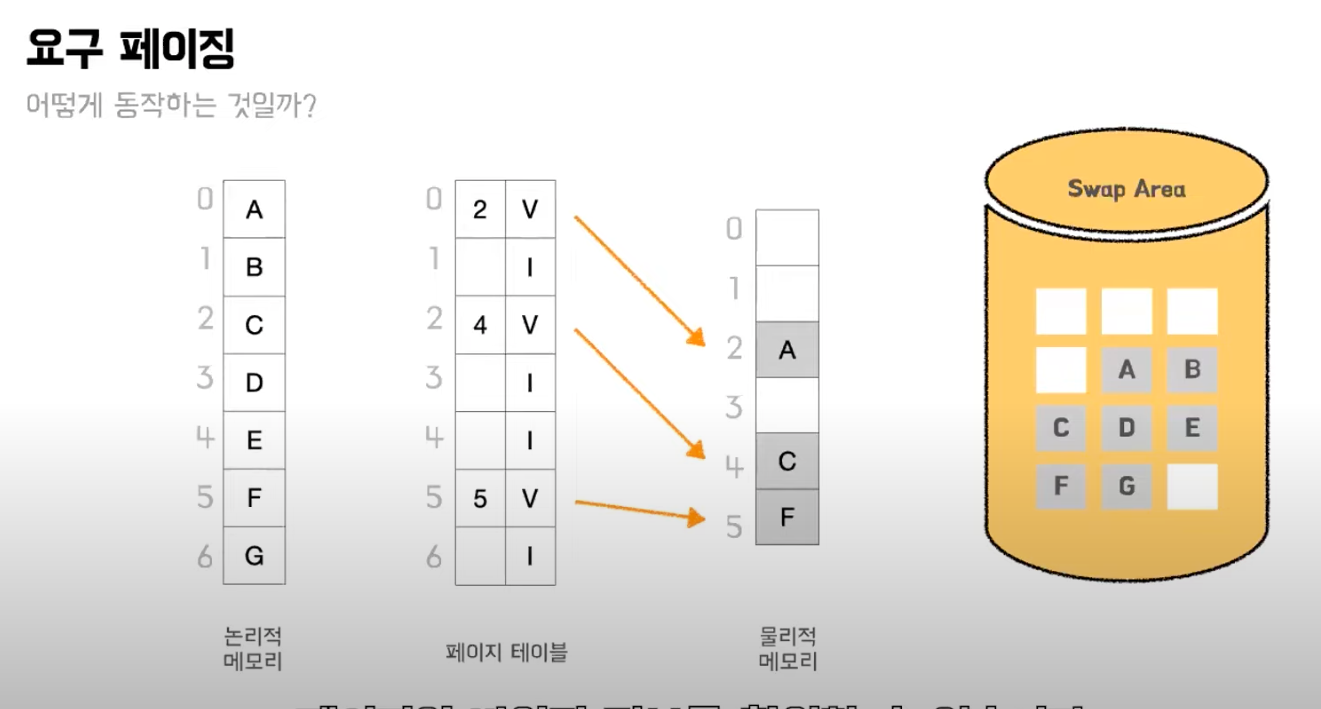
페이지폴트이면 CPU 제어권이 OS에 넘어가게 되고 스왑영역에서 해당 페이지를 참조해서 물리메모리의 빈 공간에 올리게 된다. 이렇게 필요한 페이지만 물리메모리에 올리는 기법을 요구페이징기법이라고 한다.
결론적으로 앞에서 처음 가상메모리의 특징을 설명했던 것을 다시 재정의해서 설명해 주셨다.

wow.. 좀 복잡하지만 꽤 자세하게 다뤄주셔서 한 번 더 읽어보면서 정리하면 어느정도 가상메모리가 어떻게 동작하는지 이해가 될 것 같다. 멋진 발표자님 잘 들었습니다..! 준비 많이 하셨을 것 같ㄷ ㅏ..
Topic 4. Blocking vs. Non-Blocking, Async vs. Sync
Blocking과 Non-Blocking은 다른 주체가 작업할 때 자신의 제어권이 있는지 없는지 여부로 나눠서 볼 수 있다.
Synchronous와 Asynchronous는 결과를 돌려주었을 때 순서와 결과에 관심이 있는지 아닌지로 판단할 수 있다.
Topic 5. Interrupt, Context Switching
인터럽트는 프로세스가 하던 일을 멈추 고 이미 정해진 코드에서 요청에 대한 처리를 수행하는 것을 말한다. (=> 예측이 가능하다..?!)
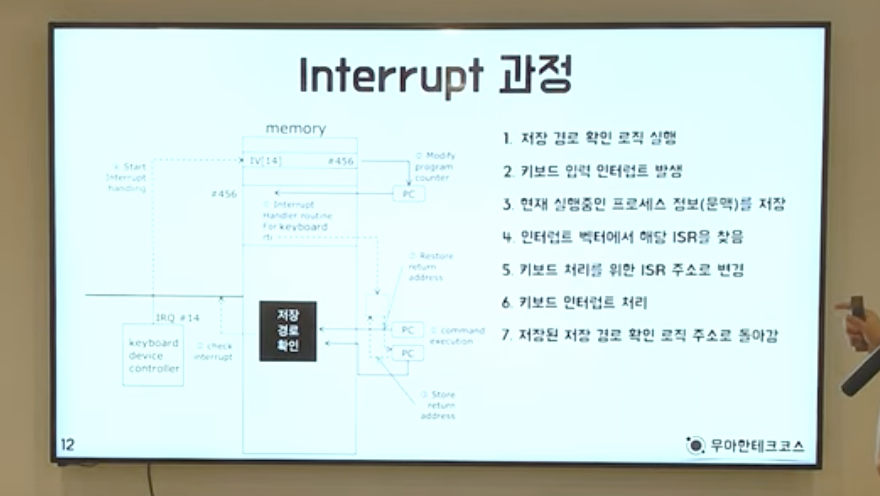
인터럽트를 처리하는 과정을 설명해 주셨는데 화면이 너무 작다ㅠ
- 저장 경로 확인 로직 실행
- 키보드 입력 인터럽트 발생
- 현재 실행중인 프로세스 정보(문맥)를 저장
- 인터럽트 벡터(인터럽트 관련 정보가 저장된 테이블)에서 해당 ISR(Interrupt Service Routine = Interrupt Handler)을 찾음
- 키보드 처리를 위한 ISR 주소로 변경
- 키보드 인터럽트 처리
- 저장된 저장 경로 확인 로직 주소로 돌아감
3~5번 단계의 작업을 Context Switching 이라고 한다.
하나의 프로세스가 CPU를 사용 중인 상태에서 다른 프로세스가 CPU를 사용하도록 하기 위해 이전의 프로세스의 상태(문맥)를 보관하고 새로운 프로세스의 상태를 적재하는 작업을 말한다. 한 프로세스의 문맥은 그 프로세스의 프로세스 제어 블록(PCB)에 기록되어 있다. - by. 위키백과
PCB는 프로세스의 거의 모든 정보를 저장하는 자료구조이다.

Idle은 CPU가 아무것도 하지 않는 상태를 말한다.
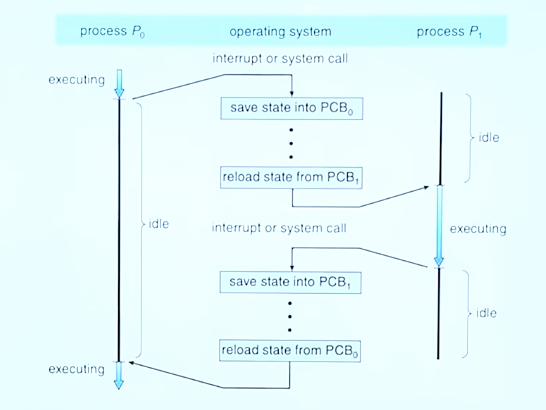
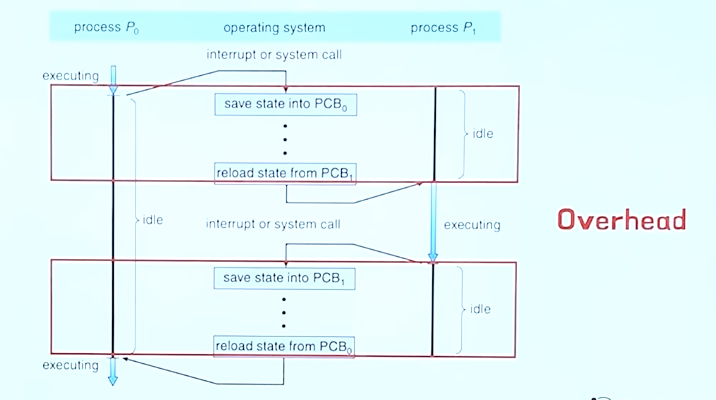
idle이 겹친다는 것은 CPU가 메모리를 적재하느라 아무것도 실행하지 못하고 있는 상태로 CPU를 완전히 낭비하게 되므로 Overhead라고 한다. 스레드가 많아지면 콘텍스트 스위칭이 빈번해 지면서 오버헤드가 많아질 수 있다.
