게시판 서비스를 만들었는데
테이블 하나에 게시물의 글 내용, 작성자, 발행일을 저장하기 시작했다. 이 때 검색기능이 필요해지면 어떻게 구현하면 될까?
LIKE 연산자
예전에 간단한 검색기능 구현하고 싶으면
컬럼명 LIKE %단어% 하면 된다고 했는데
1. % 기호를 맨 앞에 쓰면 인덱스 활용을 못하고
2. 문장이 좀 길거나 행이 많아지면 LIKE 만으로는 매우 느리게 동작한다.
이러한 단점의 해결책으로는 full text index가 있다.
full text search를 위한 index
긴 글도 데이터베이스의 컬럼 하나에 보관가능하다.
text 타임을 쓰면 6만5천자를 보관할 수 있기 때문이다.
이렇게 긴 글 안에서 원하는 단어를 검색하고 싶으면 그냥 index말고 full text search index를 만들어두어야한다.
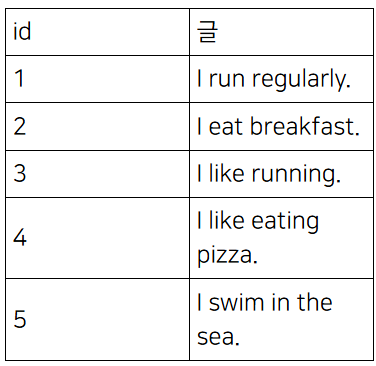
이러한 테이블이 있다고 하고
이 테이블에 full text index를 만들라고 하면
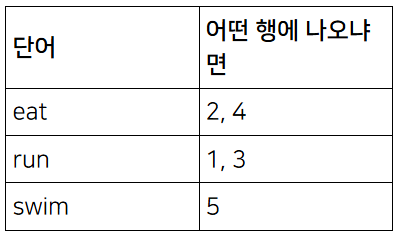
긴 글에 있는 모든 단어를 뽑아서 정렬하고
그 단어가 어떤 행에 있는지 옆에 적어둔다.
그러면 eat 이라는 단어를 검색했을 때 어떤 행에 들어있는지
쉽게 파악가능하다.
full text index 만드는 법
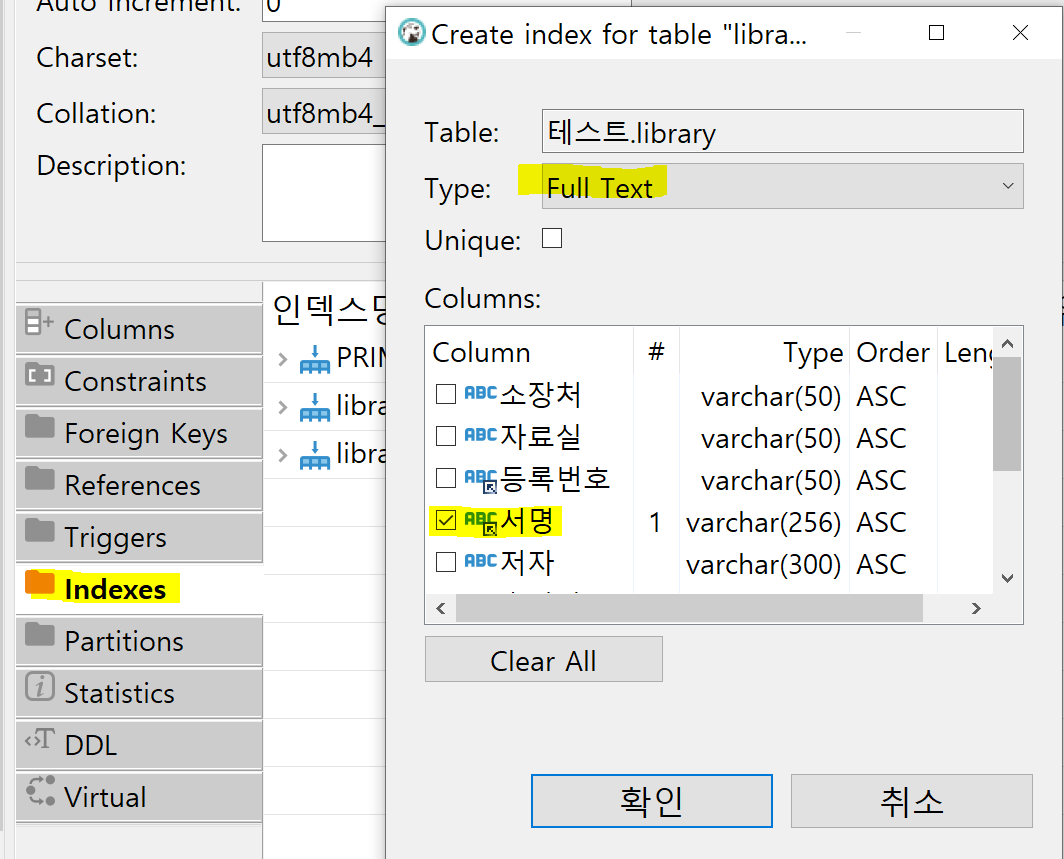
index 만들 때 type이 Btree로 되어있던 것에서
full text로 바꿔주면 된다.
CREATE FULLTEXT INDEX 인덱스이름작명 ON 테이블명(컬러명)SQL문법으로 만드는 법이다.
full text index를 이용해 검색
MATCH() AGAINST() 이런 특별한 문법이 필요하다.
WHERE뒤에 조건식 형태로 넣을 수 있고 이것을 쓰면 full text index를 이용해서 매우 빠르게 필터링해준다.
SELECT * FROM library WHERE MATCH(서명) AGAINST('부동산');이렇게 작성하면 '부동산'이라는 정확한 단어를 가진 행을 매우 빠르게 필터링해준다.
(포인트1)
그냥 MATCH() AGAINST() 사용하면 IN NATURAL LANGUAGE MODE 라는 모드로 검색해주는데 영어의 경우 이 모드를 쓰면 is, a, the, or 이런 stopwords가 포함되어있을 때 무시하고 검색해준다.
한글은 stopwords 적용안된다.
(포인트2)
AGANINST('부동산') 이라고 검색하면 정확히 '부동산' 단어만 찾아준다. '부동산을' 이런건 못찾는다.
그렇기 때문에 보통은 더 다양한 기능을 쓸 수 있는 IN BOOLEAN MODE를 사용한다.
SELECT * FROM library WHERE MATCH(서명)
AGAINST('부동산' IN BOOLEAN MODE);이렇게 IN BOOLEAN MODE를 킬 수 있다.
SELECT * FROM library WHERE MATCH(서명)
AGAINST('부동산*' IN BOOLEAN MODE);IN BOOLEAN MODE에서는 * 기호를 사용할 수 있는데
- 기호를 넣어주면 % 기호와 유사하게 동작한다.
위 코드는 부동산이 앞에 포함된 모든 단어를 검색할 수 있다. (ex. 부동산을, 부동산이 ..)
SELECT * FROM library WHERE MATCH(서명)
AGAINST('부동산 종이접기' IN BOOLEAN MODE);여러 단어를 넣으면 OR 연산을 해준다. 부동산 또는 종이접기가 포함된 결과를 출력해준다.
(참고) 2자 이하는 검색안된다.
SELECT * FROM library WHERE MATCH(서명)
AGAINST('+부동산 +빅데이터' IN BOOLEAN MODE);+기호를 앞에 붙이면 해당단어가 꼭 들어가있는 것만 찾아준다.
위 코드 처럼 입력하면 '부동산'이 꼭 들어있고 '빅데이터'도 꼭 들어있는 것을 찾아준다.
AND랑 비슷하다.
SELECT * FROM library WHERE MATCH(서명)
AGAINST('-부동산 +빅데이터' IN BOOLEAN MODE);-기호를 앞에 붙이면 해당단어를 걸러준다.
위 코드 처럼 입력하면 '부동산'은 안들어있고 '빅데이터'는 꼭 들어있는 것을 찾아준다.
NOT이랑 비슷하다.
n-gram parser
영어는 띄어쓰기로 단어를 분리할 수 있는데
한글, 일본어, 중국어는 띄어쓰기가 그렇게 중요하지 않다.
그래서 글자들을 다 붙여준 다음에 몇 글자 단위로 잘라서 index를 생성하는 방식이 있는데 이것을 n-gram parser라고 한다.
예를 들어 '주식 투자'라는 문자를 n-gram으로 index를 생성하면
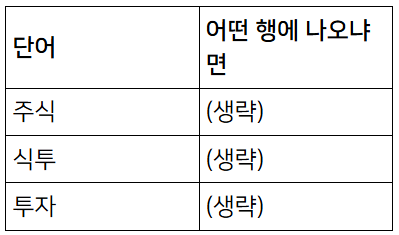
띄어쓰기 무시하고 2자 단위로 잘라서 index를 만들어준다.
(최소 글자 수는 항상 2자일 필요는 없고 설정 가능하다.)
그럼 이전과 다르게 다양한 단어도 검색이 가능하다는 장점이 있다.
CREATE FULLTEXT INDEX 인덱스이름작명
ON 테이블명(컬럼명) WITH PARSER ngram;n-gram parser로 index를 생성하려면 SQL 문법으로 생성해야한다.
SELECT * FROM library
WHERE MATCH(서명) AGAINST('철학을'); 그래서 n-gram을 이용해서 index를 만들어둔 후
위 처럼 검색하면 '철학','학을'이 포함된 모든 책 제목을 찾아준다.
왜냐면 IN NATURAL LANGUAGE MODE + ngram parser index를 적용하면 검색어를 2개 단어 단위로 쪼개서 하나라도 일치하는 모든 결과를 검색해줘서 그렇다.
그래서 지엽적인 책 제목까지 모두 가져올 수 있다는 장점이 있는데
1. n-gram parser로 index를 만들면 하드용량을 많이 차지할 수 있고
2. 쓸데없는 결과도 많이 출력되는 단점이 있다.
그렇지만 기본적으로 관련도가 높은 결과를 맨 위로 올려주기 때문에 나름 네이버같은 검색엔진을 조금 흉내낼 수 있는 기능이라고 할 수 있다.
이 정도의 성능말고 네이버, 구글, 대형쇼핑몰처럼 검색성능이 매우 중요한 사이트를 만들고 싶다면 elastic serach라던지 검색만을 위한 DB 또는 서비스를 따로 사용할 수도 있다.
