위 데이터셋은 어떤 도서관의 소장도서 6만원의 정보가 들어있다.
execution plan(실행계획) 분석해보기
SELECT * FROM library WHERE 등록번호 = 'CEM97499' 원하는 쿼리문 작성해서 커서 찍고 dbeaver 상단메뉴의
sql편집기 - 실행계획보기를 눌러보면 실행계획이 출력된다.
컴퓨터가 이 쿼리문을 어떻게 실행할지 계획을 짜놓은것을 볼 수 있는 화면인데 이것을 보고 성능평가를 할 수 있다.
-
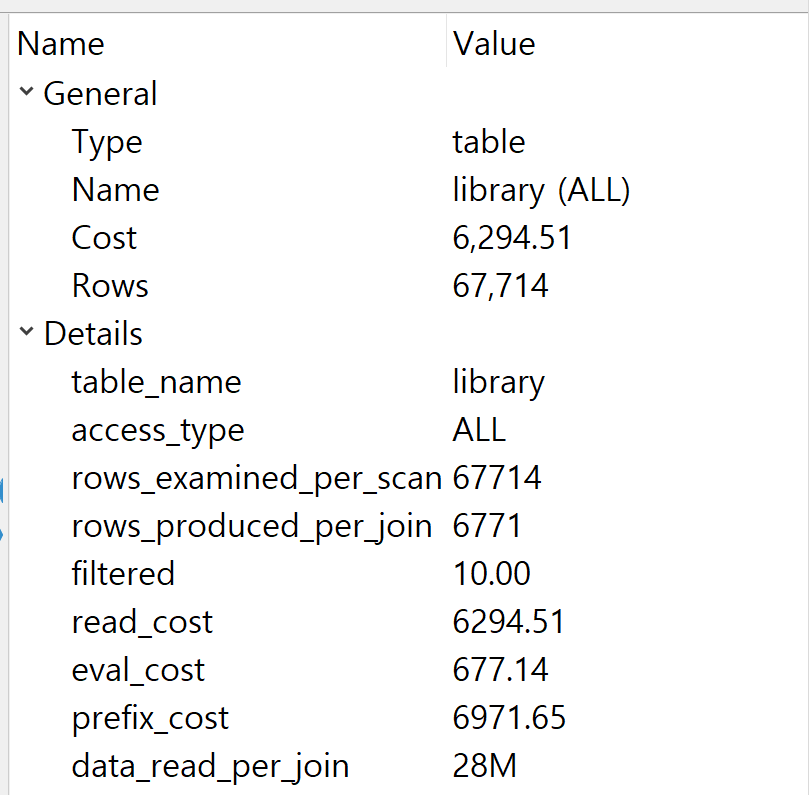
cost
어림잡아 걸리는 시간이라고 생각하면 되고 낮을 수록 좋다. cost가 몇천, 몇만 정도라면 1초에 몇백건 실행해도 부담이 되지않는다. 하지만 10만정도 되는 경우는 많이 실행할 경우 컴퓨터에 부담을 주거나 병목현상이 일어날 수 있다. -
access_type 혹은 type
ALL만 피하면 된다. ALL이 기록되어있으면 테이블 전체 행을 full scan한다는 뜻이라서 성능이 좋지 않다.
여기 들어갈 것들은 index, range, ref, const 등이 있다. -
filtered
컴퓨터가 읽은 행을 출력결과에 넣는 비율인데
예를 들어 10개의 행을 읽었는데 1개의 행만 출력결과에 넣으면 10%로 계산된다.
그래서 100%에 가까울 수록 좋다. 수치가 정확한 것은 아니라서 보조지표로 활용하면 좋다.
테이블에 index 생성하려면
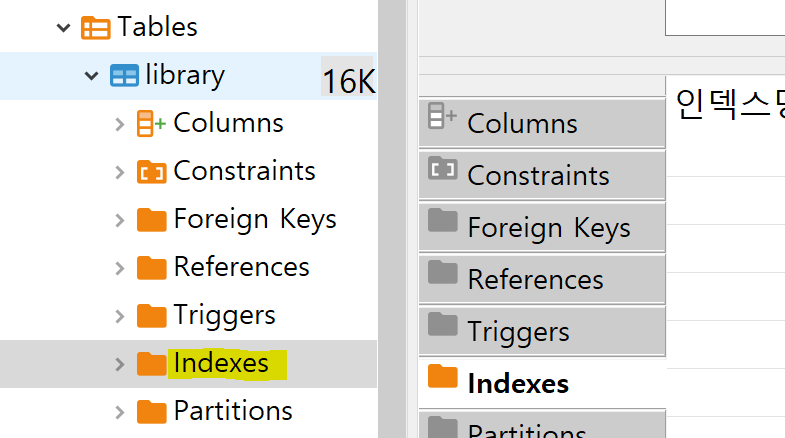
테이블마다 indexes 메뉴가 있는데 거기서 우클릭하면 index를 하나씩 생성이 가능하다.
그리고 원하는 컬럼 선택해서 확인 누르고 저장하면 된다.
B+tree말고 다른 식으로 index를 만들 수 있는데
Rtree는 2차원 좌표값을 저장한 컬럼일 때 사용하고 (위도/경도)
Full text는 긴 문장에서 원하는 단어를 빠르게 찾고 싶을 때 쓴다. 글 검색 기능만들 때 주로 사용한다.
UNIQUE 제약은 행마다 서로 다른 값을 가진 컬럼이라면 체크를해서 검색 성능이 더 빨라질 수 있다. Unique index라고 한다. (겹칠 수 있는 이름 같은 거 말고 등록번호 같은 것)
index 만든 후 성능을 다시 평가해보자
SELECT * FROM library WHERE 등록번호 = 'CEM97499' 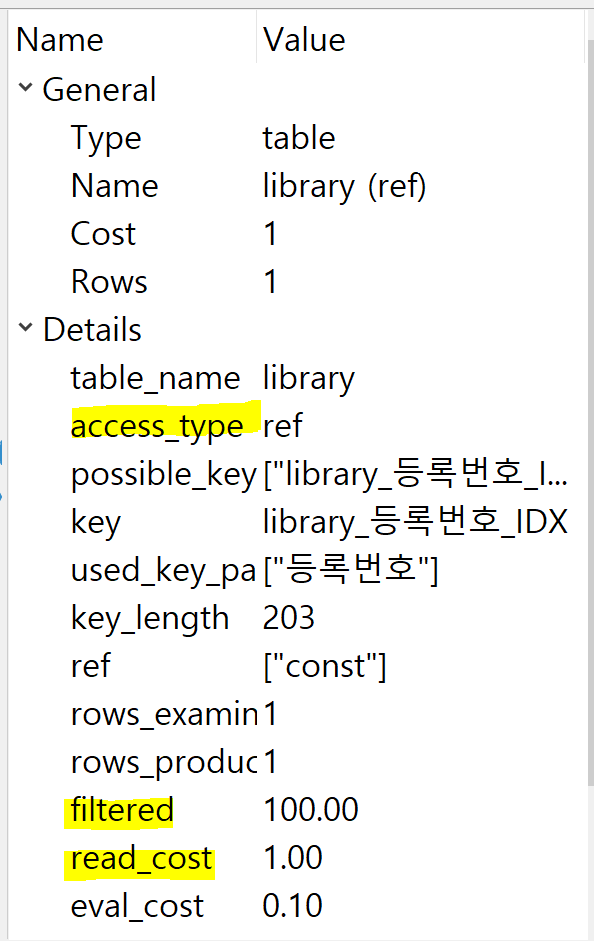
cost : 6000 -> 1
access_type : all -> ref
filtered : 10 -> 100
많이 개선되었다.
(참고1) MySQL workbench에서 쿼리문 작성후 실행하고 우측 execution plan 눌러보면 더 상세히 조회가능하다. 쿼리문이 길고 복잡할 수록 workbench 켜서 분석해보는 것이 좋다.
(참고2) 왜 WHERE 등록번호 < 'CEM97499' 이런 범위 검색은 index를 안쓸까? 현재 테이블의 전체행은 6만개인데 3만개가 출력된다. 범위 검색시 출력할 향이 전체 행의 20%를 넘어서면 index를 안쓰는게 더 빠르다고 DBMS가 판단해서 index를 쓰지 않는다.
다중컬럼 index
SELECT * FROM 어쩌구 WHERE name = 'park' AND age = 20 위 코드 처럼 어떤 쿼리문을 작성할 때 컬럼 2개 이상에서 검색작업을 수행하고 있는 경우 그 컬럼에서 각각 index를 만드는 것 보다 필요한 컬럼을 묶어서 index를 만드는 것이 성능향상에 좋다.
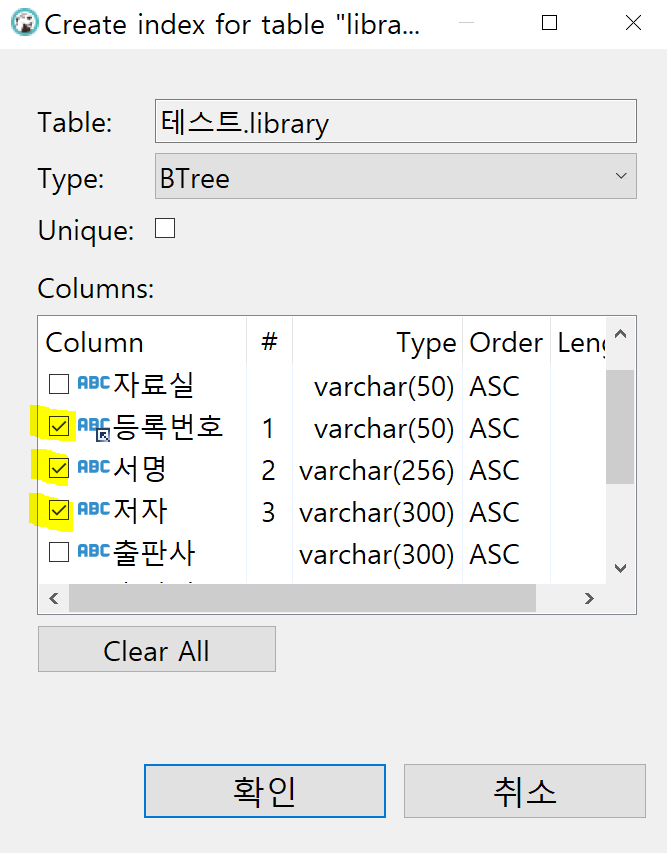
이렇게 여러개 동시에 체크하면 되고 (등록번호, 서명, 저자)를 전부 묶어서 index가 만들어진다.
예를 들어 (name,age) 순으로 다중컬럼 index를 만들어놓았다면
WHERE name = ? AND age = ? 이런 쿼리를 작성할 때 (name,age) index를 사용해준다
name,age를 각각 별도의 index로 만들어놓는 경우보다 쿼리속도가 빠르다.
WHERE name = ? 이런 쿼리에도 (name,age) index를 사용해준다.
(MySQL에선 그럼. 다른 DBMS에서는 아닐 수 있음)
WHERE age = ? 이런 쿼리엔 (name,age) index를 사용할 수 없다.
그래서 다중컬럼 index는 컬럼 넣는 순서도 중요하다.
일반적인 상황에서는 cardinality(구분명확도)가 높은 컬럼을 왼쪽에 넣는 것이 좋은데
예를 들어서 (이름,주민번호) 컬럼이 있으면 주민번호 같이 중복이 없는 컬럼을 왼쪽에 넣어서 (주민번호,이름) 이렇게 index를 만드는 것이 좋다.
SQL 문법으로 index 만들기
CREATE INDEX 인덱스이름작명 ON 테이블명 (컬럼명);index 생성
CREATE INDEX 인덱스이름작명 ON 테이블명 (컬럼명1,컬럼명2);다중컬럼 index 생성
