만약 1억개의 데이터 중 하나의 데이터를 찾으려면
1억개의 행을 모두 뒤져봐야한다. (매우느리다는뜻)
효율적으로 데이터를 검색하고 싶으면 index를 사용해야한다.
업다운놀이

1부터 100까지 써있는 카드가 책상에 있으면
그 중 정답 숫자 하나를 맞춰보고자 한다.
멍청한 사람은 1부터 100까지 하나씩 물어보면서 정답이냐 하겠지만
똑똑한 사람은 50보다 큰지 작은지 75보다 큰지 작은지 물어가면서 답이 아닌 것을 소거해서 정답을 찾아낸다.
데이터베이스에 있는 데이터도 이런식으로 반을 자르면서 검색할 수 있다.
찾을 컬럼을 1,2,3 또는 가나다 순으로 정렬해놓고 절반씩 치우면서 데이터를 검색해나가는 방법이다.
따라서 검색을 빠르게 만들기 위해 "미리 정렬해둔 복사본"을 index라고 한다.
binary search tree
데이터를 빠르게 찾고 싶으면 데이터를 미리 정렬해두면 된다고 했는데 숫자 뿐아니라 문자도 마찬가지이다.
그럼 절반씩 치우면서 검색할 수 있기 때문이다.
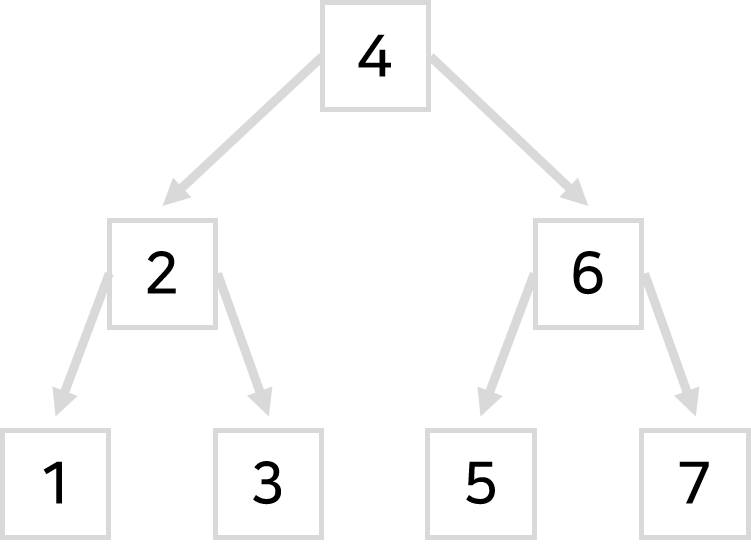
1. 자료들을 화살표로 이어두고
2. 사진처럼 숫자를 왼쪽부터 123순으로 배치만 잘 해둬도 반씩 갈라가며 빠르게 검색이 가능하다.
위 사진을 뒤집어놓은 나무같다고 해서 이것을 binary search tree라고 부른다.
데이터를 binary tree 형태로 미리 배치해놓아야 빠르게 찾을 수 있고 실제로 index도 tree 형태로 배치해두는 경우가 많다.
B-tree
하지만 50%씩 소거하며 찾는 것말고
66%나 75%씩 소거해버릴 수 있는 tree가 있다.
B-tree 형태로 자료를 배치해두면 가능하다.
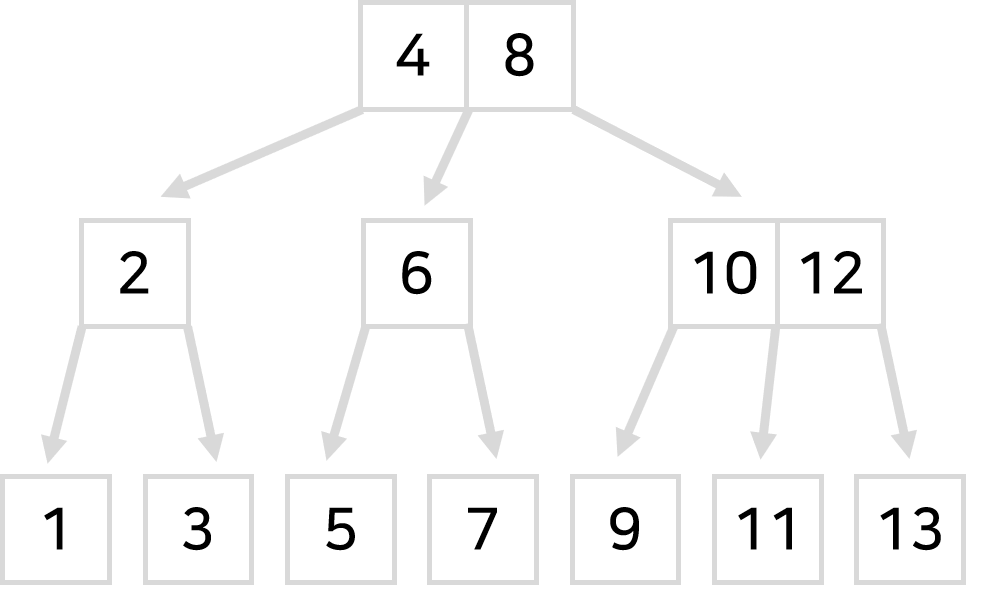
- 하나의 네모칸 안에 숫자를 여러개 담아놓는 식으로 배치하고
- 갈림길을 3개 이상으로 쪼개놓는 것이다.
이것을 B-tree라고 부른다.
그럼 훨씬 적은 횟수로 많은 데이터를 찾아낼 수 있다.
아까는 2번의 화살표 이동으로 1~7까지 찾을 수 있었는데
지금은 2번의 화살표 이동으로 1~13까지는 충분히 찾을 수 있다.
B+tree
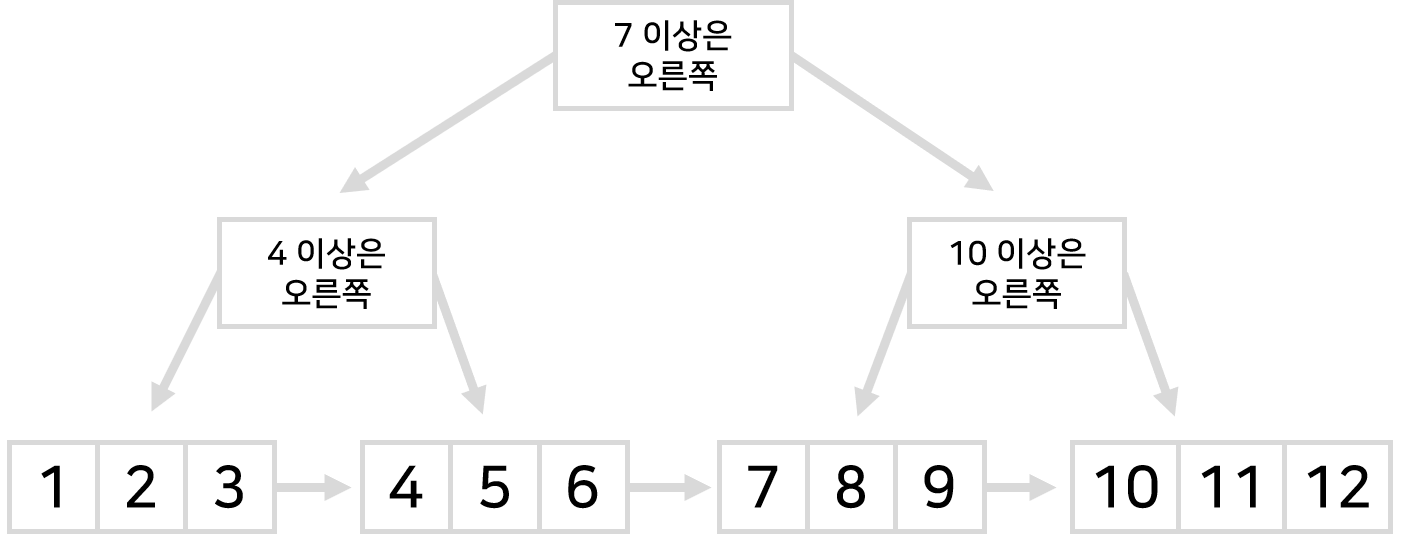
B-tree와의 차이점은 정렬방식을 똑같지만 데이터를 가장 밑에만 저장해두는 것이다.
가장 밑부분에 테이블을 일정한 크기로 쪼개놓고 순서대로 정렬해둔다. 그리고 데이터 탐색 가이드라인만 윗부분에 저장해둔다.
또한 B+tree는 옆 데이터들도 화살표로 연결을 해놓는데 화살표 때문에 옆테이블 조회까지 매우 쉬워진다.
나이가 2와 5 사이인 행을 다 찾아주세요~ 라고 하면 나이가 2인 행을 먼저 찾은 다음에 5까지 전부 출력해준다.
그래서 관계형DB들은 일반적으로 B+tree로 index를 정렬해둔다.
따라서 컬럼을 잘라내서 tree형태로 정렬해둔 것을 index라고 하는데 실제로 index가 컴퓨터에서 어떻게 작동하냐면
1. 컴퓨터는 index안에서 필요한 데이터를 빠르게 찾고
2. 찾은 index의 행과 연결된 원래 테이블의 행을 찾아와서 결과로 출력해준다.
이러한 과정 덕분에 검색속도가 빨라지는 것이다.
=,>,>=,<,<=,BETWEEN,LIKE 연산자를 사용할 때 index가 사용된다.
LIKE 사용시엔 시작이 %기호가 아닐 때만(LIKE~%일때만) index를 사용해준다.
자동으로 index가 적용되는 컬럼이 있음
primary key컬럼은 따로 index를 만들 필요가 없다.
왜냐면 테이블에 primary key가 있으면 애초에 primary key 기준으로 정렬해서 보관해주기 때문에 index가 기본으로 생성되어있다.
그래서 primary key 검색시엔 매우 빠르게 찾아주고 primary key가 아닌 일반 컬럼들은 검색속도를 향상시키고 싶으면 index를 만들어놔야한다.
index의 단점
- index를 만들 때 마다 추가 하드용량을 차지한다.
- index가 있는 테이블은 나중에 삽입, 수정, 삭제 문법으로 데이터를 넣을 때 내부적으로 추가연산이 필요해 느려질 수 있다. 왜냐면 테이블과 index에 각각 데이터를 반영해야하기 때문이다.
