스프링부트는 멀티 쓰레드 환경이며, 동시성 문제는 중요합니다.
프로젝트를 진행하던 중 Application Lock을 활용해 동시성 이슈 해결한 경험을 공유하고자 합니다. 🫠
즐겨찾기 기능
프로젝트 Memic에서는 사용자의 편의성을 위해 자주 학습하는 영상을 즐겨찾기 할 수 있는 스크랩 기능을 제공하고 있다.
해당 서비스는 다음과 같은 플로우로 작동한다.
//controller
1. 로그인한 사용자가 특정 transcription_id를 통해 scrap 요청한다.
//service
2. transcription_id로 db에 해당 transcription을 가져온다.
3. 조회한 member와 transcription을 통해 scrap이 저장되어있는지 확인한다.
3-1. 저장된 scrap이 있으면 바로 해당 scrap의 id를 반환하고
3-2. 저장된 scrap이 없으면 해당 scrap을 저장후 저장된 id를 반환한다.코드를 보자면
@Entity
@NoArgsConstructor
@Getter
public class Scrap {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
@ManyToOne(fetch = FetchType.LAZY)
@NotNull
@JoinColumn(name = "transcription_id")
private Transcription transcription;
@ManyToOne(fetch = FetchType.LAZY)
@NotNull
@JoinColumn(name = "member_id")
private Member member;
@CreationTimestamp
@Column(name = "created_at")
private LocalDateTime createdAt;
...
}
@Service
@RequiredArgsConstructor
public class ScrapService {
private final ScrapRepository scrapRepository;
private final TranscriptionRepository transcriptionRepository;
@Transactional
public ScrapCreatedResponse createScrap(Member member, ScrapCreateRequest request) {
Transcription transcription = transcriptionRepository.getById(request.transcriptionId());
Scrap scrap = scrapRepository.findByMemberAndTranscription(member, transcription)
.orElseGet(() -> createNewScrap(transcription, member));
return new ScrapCreatedResponse(scrap.getId());
}
...
}앞서 말했다시피 스프링부트는 멀티 쓰레드로 동작을 하기 때문에 하나의 서비스 로직에서 조회 성공 여부에 따라 저장을 하는 로직에서 동시성 이슈가 발생할 것을 인지하였고
Testcode를 통해 직접 확인을 해보았다.
Testcode_without_concurrency
@Test
void 스크랩을_저장한다() {
//given
Member member = memberRepository.findByEmail("yunho@naver.com").get();
ScrapCreateRequest request = new ScrapCreateRequest(1L);
//when
for (int i = 0; i < 10; i++) {
scrapService.createScrap(member, request);
}
//then
assertEquals(1, scrapRepository.findAllByMember(member).size());
}일단 createScrap()이 정상적으로 동작을 하는지 확인을 해보았다.
물론 정상적으로 통과를 한다.
하지만 동시성 환경을 가장한 병렬 요청에서는 어떻게 될까? 🤔🤔🤔
Testcode_with_concurrency
동시성 환경을 가장한 Testcode를 작성해보았다.
사용자의 요청이 2번 병렬적으로 들어온다고 가정해 numberOfThread를 2로 잡았다.
@Test
void 병렬_환경에서_스크랩을_저장한다() throws InterruptedException {
//given
Member member = memberRepository.findByEmail("yunho@naver.com").get();
ScrapCreateRequest request = new ScrapCreateRequest(1L);
int numberOfThread = 2;
ExecutorService threadPool = Executors.newFixedThreadPool(numberOfThread);
CountDownLatch countDownLatch = new CountDownLatch(numberOfThread);
for (int i = 0; i < numberOfThread; i++) {
threadPool.execute(() -> {
try {
scrapService.createScrap(member, request);
} catch (Exception e) {
System.out.println(e);
} finally {
countDownLatch.countDown();
}
});
}
countDownLatch.await();
//then
assertEquals(1, scrapRepository.findAllByMember(member).size());
}
분명 위에서 구현한 로직처럼 값이 존재하면 저장을 안하고 반환을 해야하는데 결과는 저장이 2개가 되었다.
왜 이런 결과가 나온걸까?
Java에서는 메서드의 단위가 원자적으로 작동을 하는게 아니다.
우리가 원하는 방향은 아래의 사진과 같지만..
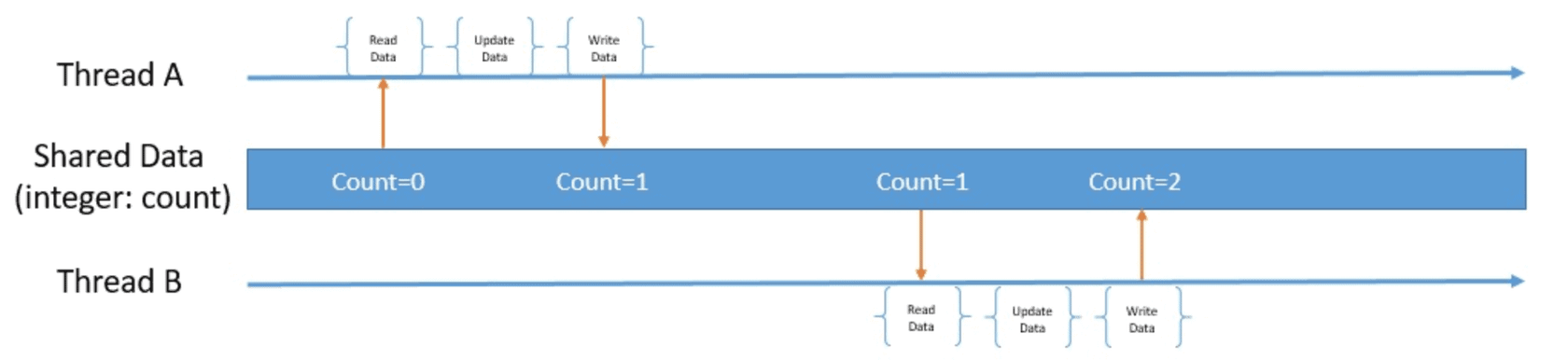
실제로 다음과 같은 많은 interleaving이 발생을 한다.
사진으로 확인하면
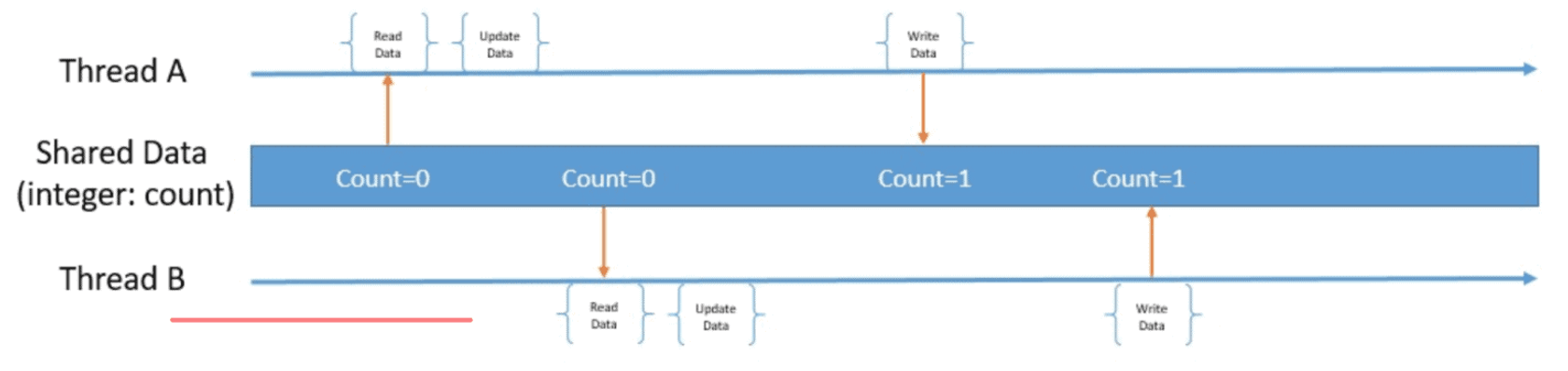
다음과 같이 작동을 하기 때문에 위와 테스트 실패 결과를 초래했다.
동시성 문제 해결하기
동시성 문제를 해결하는 방법으로는 크게 3가지가 있다.
- 어플리케이션에서 해결하기(단일 서버)
- DB에서 해결하기 (분산 환경)
- 외부 시스템 활용하기 (대규모 분산환경)
3가지 방법중 어플리케이션에서 해결하는 방법을 적용했다.
그 이유는 현재 단일 인스턴스에서 서버가 띄워지는 환경이고, DB 또한 하나이기 때문이다.
Java에서 제공하는 상호 배제의 방법으로 충분히 동시성 문제를 해결 할 수 있다고 판단을 하였다.
DB에서 해결하는 방법으로는 낙관적 락 또는 비관적 락이 존재하는데 해당 방법은 복잡한 충돌처리 또는 무한 재시도, 데드락 등에 문제가 발생할 수 있다 판단을 하였고. 또한 DB Connection이라는 자원을 활용해야하는 문제가 있었다.
또한 단일 인스턴스 단일 서버인 환경에서는 외부 시스템을 사용하는 것은 오버엔지니어링이 될 수 있다고 판단을 했다.
1. syncronized
@Transactional
public synchronized ScrapCreatedResponse createScrap(Member member, ScrapCreateRequest request) {
Transcription transcription = transcriptionRepository.getById(request.transcriptionId());
Scrap scrap = scrapRepository.findByMemberAndTranscription(member, transcription)
.orElseGet(() -> createNewScrap(transcription, member));
return new ScrapCreatedResponse(scrap.getId());
}
private Scrap createNewScrap(Transcription transcription, Member member) {
Scrap scrap = new Scrap(transcription, member);
return scrapRepository.save(scrap);
}메서드에 sychronized를 적용해 보니 무난하게 test는 통과를 하였다.
하지만 문제가 존재한다. synchronized 메서드는 인스턴스 단위로 lock을 건다. 이때 synchronized가 적용된 모든 object에 대해서 lock을 공유한다.
즉 현재 createScrap() 메서드를 호출하면 ScrapService에 있는 모든 메서드를 호출할 수 없게 되고 그만큼 성능 이유가 생길 것이다.
또한 한 블럭 안에서 syncronized를 진행해야 함으로 syncronized는 공정성을 보장하지 않는다 따라서 기아상태를 유발할 수 있다는 문제가 존재한다.
2. Reentrant Lock
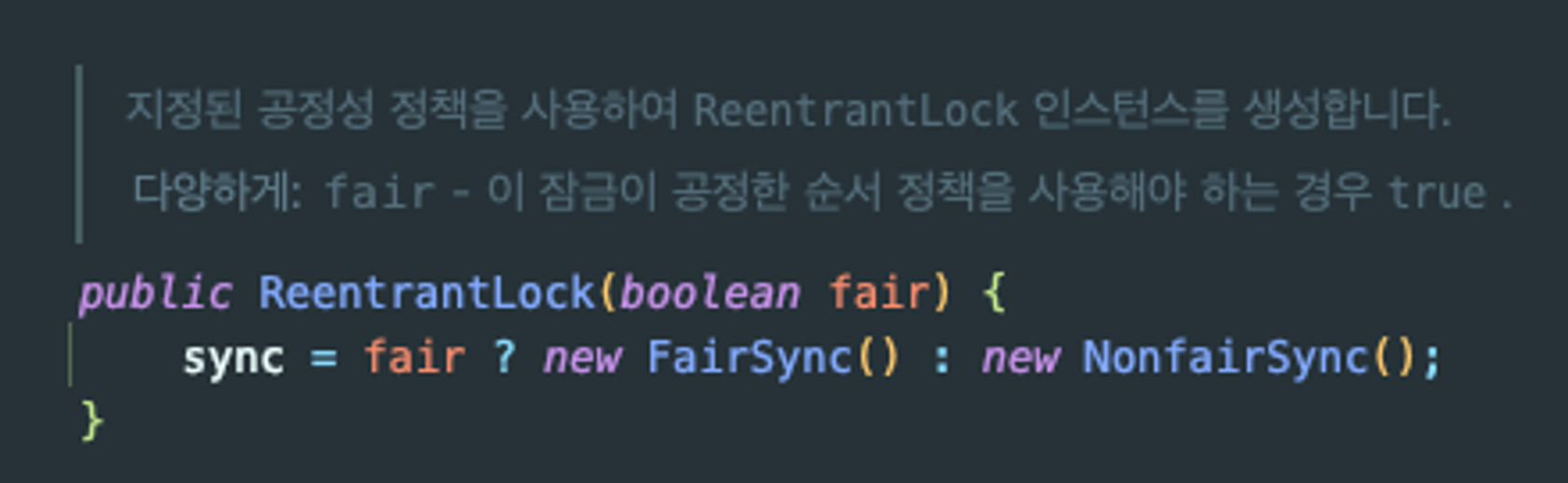
ReentrantLock 경우 두 가지의 생성자를 가지고 있으며, fair를 true로 설정할 경우 sync에 FairSync() 인스턴스를 가지게 되어 공정성을 보장한다.
따라서 Reentrant Lock을 사용하기로 선택을 했고 코드를 보면
@Configuration
public class LockConfig {
@Bean
public Lock reentrantLock(){
return new ReentrantLock(true);
}
}@Service
@RequiredArgsConstructor
public class ScrapService {
private final ScrapRepository scrapRepository;
private final TranscriptionRepository transcriptionRepository;
private final Lock lock;
@Transactional
public ScrapCreatedResponse createScrap(Member member, ScrapCreateRequest request) {
lock.lock();
Transcription transcription = transcriptionRepository.getById(request.transcriptionId());
Scrap scrap = scrapRepository.findByMemberAndTranscription(member, transcription)
.orElseGet(() -> createNewScrap(transcription, member));
lock.unlock();
return new ScrapCreatedResponse(scrap.getId());
}
private Scrap createNewScrap(Transcription transcription, Member member) {
Scrap scrap = new Scrap(transcription, member);
return scrapRepository.save(scrap);
}
...
}다음과 같이 코드를 수정하고 테스트는
통과를 하였다.. ㅎ
테스트를 통해 동시성 이슈가 충분히 발생할 수 있다는 것을 확인하였다.
또한 동시성 이슈를 해결할 수 있는 여러 방법들이 존재하고 각각 선택에 따라 trade-off가 존재가 한다는 것을 인지하고 적절한 선택을 하는 과정을 정리하는 시간 또한 흥미로웠다.
