문자열 비교 하기
프로젝트 Memic에서는 발음을 평가하는 기능을 제공합니다.
아래 사진들은 저희 서비스의 일부입니다.

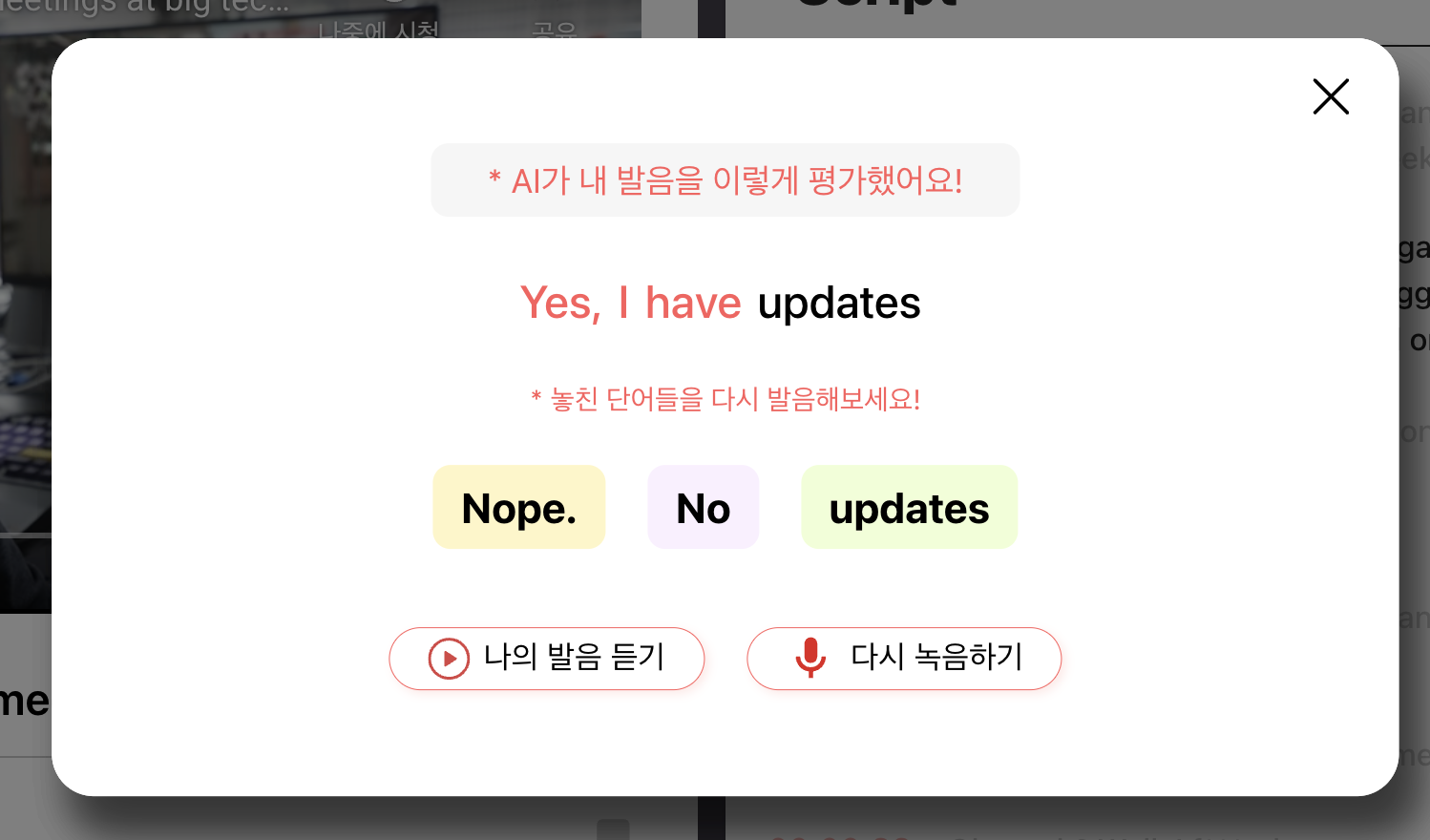
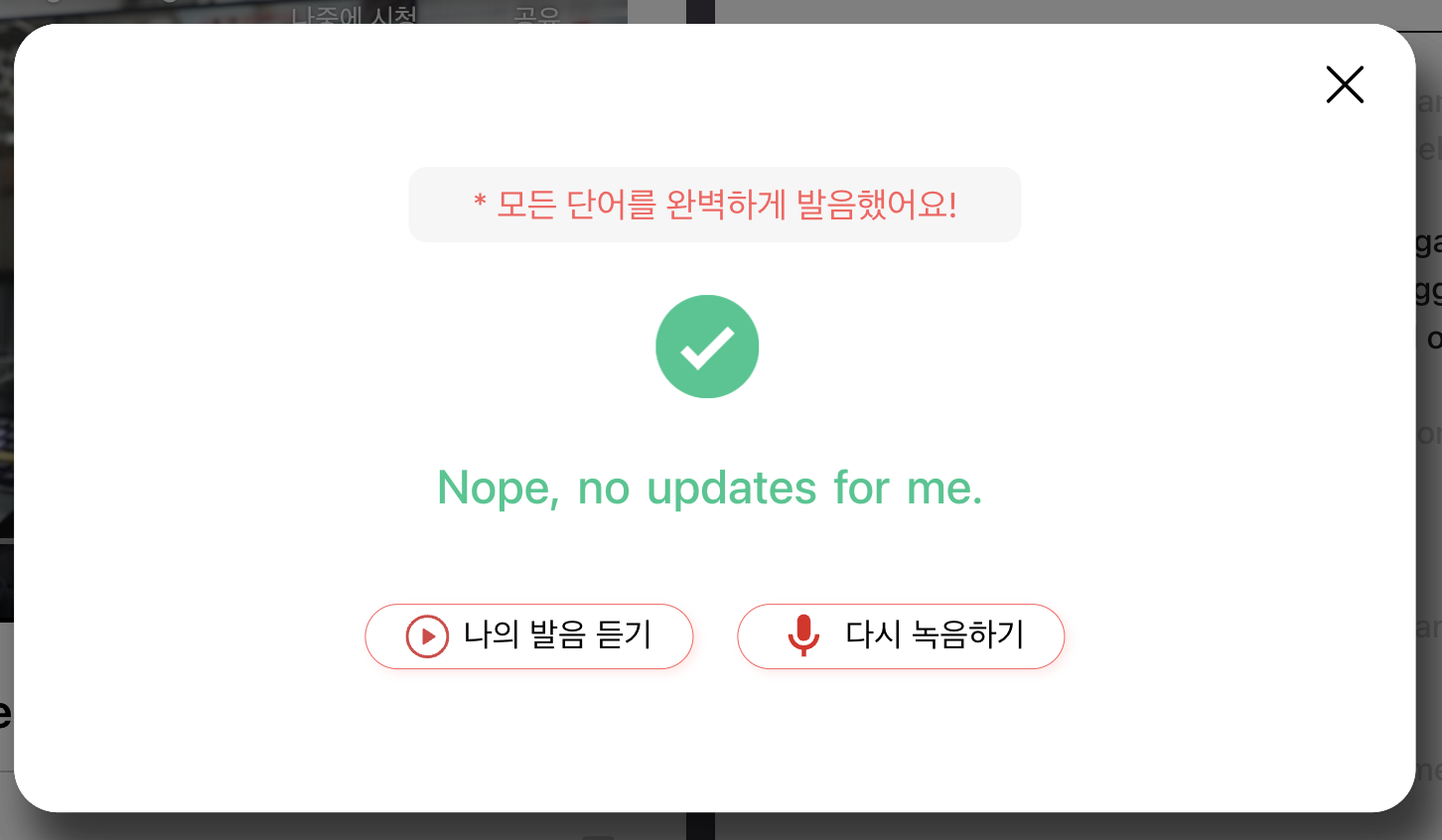
발음 평가 기능
정확하게 말하면 발음이 스크립트와 일치하는지 결과를 제공합니다. 그 이유는 다음과 같습니다.
- 저희 서비스는 스크립트를 반환할 시 유튜브영상을 mp3로 다운받아 Whisper API에 요청을 해 스크립트를 받습니다.
- 받은 스크립트를 사용자가 녹음해 mp3 파일로 만들어 마찬가지로 Whisper API에 요청을 해 스크립트 받습니다.
- 1번의 결과값과 2번의 결과값을 비교해 발음이 일치하는지 비교합니다.
1차 기능구현
간단하게 접근을 했습니다. 문자열을 공백 기준으로 자르고 정규식으로 특수문자를 제거한뒤 녹음한 문장과 스크립트 문장을 index 기준으로 비교를 하였습니다. 정말 말그대로 replaceAll()과 equals()메서드만 가지고 구현을 원하는 기능을 구현을 했다고 생각했습니다.
하지만 문제가 생겼습니다. 첫번째 스크린샹의 스크립트를 기준으로 말해보겠습니다.
(일부분만 가져왔습니다)
// 입력된 발음
a very powerful earthquake has struck
// 인식된 발음
a very powerful earth cake has struck같은 index를 기준으로 문장을 인식하다보니 earthquake라는 단어가 earth cake 두 단어로 인식이 되어 그 뒤의 단어인 has struck까지 전부 틀린 문장으로 인식이 되는 것이었습니다.
2차 기능 구현
두가지 방법을 생각해보았습니다.
- 문장을 인식된 문장의 단어의 기준으로 앞뒤 일정한 범위의 subList로 잘라 문장의 단어가 포함되어 있는지 contains() 메서드를 통해 판단
- KMP 알고리즘을 활용
1. subList , contains()
발음 평가 기술 또한 저의 프로젝트의 핵심 기술이라고 생각을 해 성능을 고려하기 위해 contains() 메서드의 내부 동작 원리를 보았습니다.

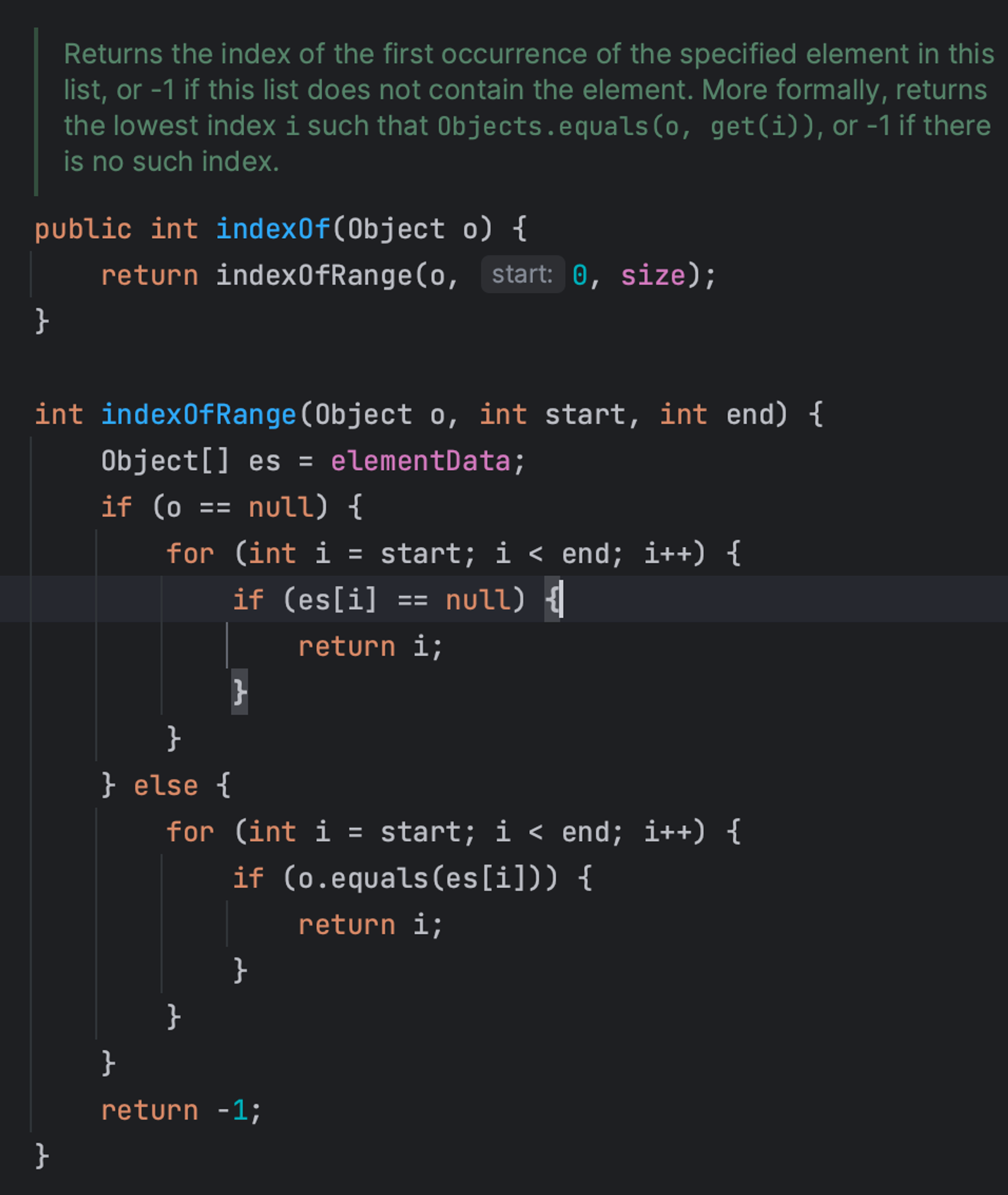
list를 순차적으로 앞에부터 순회를 하며 equals()메서드로 값을 비교해 일치 여부를 반환하는 것이었습니다. 따라서 일일이 순차적으로 값을 조회하는 방법은 비효율적이라고 생각을해 2번째 방법을 확인해보았습니다.
2. kmp 알고리즘
Knuth-Morris-Pratt(KMP) 알고리즘은 문자열 검색 알고리즘으로, 주어진 텍스트에서 특정 패턴을 효율적으로 찾는 데 사용됩니다. KMP 알고리즘의 주요 장점은 중복된 연산을 피함으로써 검색 시간을 최적화하는 것입니다. 이를 위해 KMP 알고리즘은 패턴 내에서 일치 실패가 발생한 경우에 대비하여 미리 계산된 정보(부분 일치 테이블)를 사용합니다.
해당 방법의 시간 복잡도는 O(n*m) (n: 메인 문자열의 길이, m: 검색하고자 하는 패턴 문자열의 길이)를 가집니다.
주어진 텍스트의 길이가 비교적 짧은 저의 서비스는 대용량의 문자를 비교하기위해 탄생한 kmp알고리즘을 사용하는 방향이 결과를 반환하는데 더욱 오래 시간이 걸리는 것을 파악했고 결국 첫번째 방법으로 구현을 하는 쪽으로 선택을 했습니다.
후기
KMP 알고리즘을 사용하면 효율적인 문자열 검색이 가능하다는 장점을 확인할 수 있었습니다. 그러나 각각의 상황에 따라 적합한 구현 방법은 다를 수 있다는 점도 흥미로웠습니다. Java의 JCF 내에 contains() 메서드가 순차적으로 검증하도록 구현된 이유도 이러한 상황별 필요성에 때문일 것이라는 생각이 들었습니다.
알고리즘 선택과 구현 방식은 문제의 특성과 요구사항에 따라 다를 수 있습니다. 이러한 점을 이해하고 적절한 알고리즘을 선택하는 것이 중요하다는 것을 다시 한 번 깨닫는 유익한 시간이었습니다.
