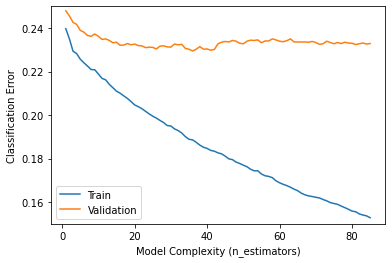
분류 문제를 풀기 위해서는 트리 앙상블 모델을 많이 사용한다.
- 트리 앙상블은 randomforest나 gradient boosting 모델을 말하며 여러 문제에서 좋은 성능을 보이는 것을 확인했었다.
- 트리 모델은 non-linear, non-monotonic 관계, 특성 간 상호작용이 존재하는 데이터 학습에 적용하기 좋다.
- 한 트리를 깊게 학습시키면 과적합을 일으키기 쉽기 때문에 배깅(Bagging, 랜덤포레스트)이나 부스팅(Boosting)앙상블 모델을 사용해 과적합을 피한다.
- 랜덤포레스트의 장점은 하이퍼파라미터에 상대적으로 덜 민감한 것인데, 그래디언트 부스팅의 경우 하이퍼파리미터 셋팅에 따라 랜덤포레스트보다 더 좋은 예측성능을 보여줄 수 있다.
Boosting vs Bagging
랜덤포레스트와 그래디언트 부스팅은 모두 트리 앙상블 모델이지만 트리를 만드는 방법에 차이가 있다.
가장 큰 차이는 랜덤포레스트의 경우 각 트리를 독립적으로 만들지만 부스팅은 만들어지는 트리가 이전에 만들어진 트리에 영향을 받는다는 것이다.
부스팅 알고리즘 중 AdaBoost는 각 트리(약한 학습기, weak learners)가 만들어질 때 잘못 분류되는 관측치에 가중치를 준다, 그리고 다음 트리가 만들어질 때 이저에 잘못 분류된 관측치가 더 많이 샘플링되게 하여 그 관측치를 분류하는데 더 초점을 맞춘다.
-
bagging: 약한 모델을 여러 개 만들기
bag데이터에 중복이 있을 수 있고, 학습에 이용되지 않는 데이터(out of bag, OOB)가 있다. (과적합 방지, data imbalance와는 관련없다.) -
boosting: 약한 모델이 잘못 예측한 sample(error)을 점점 강화시킴, 잘못 분류된 샘플에 가중치를 줘서 더 잘 보이게 해준다.
Boosting
AdaBoost
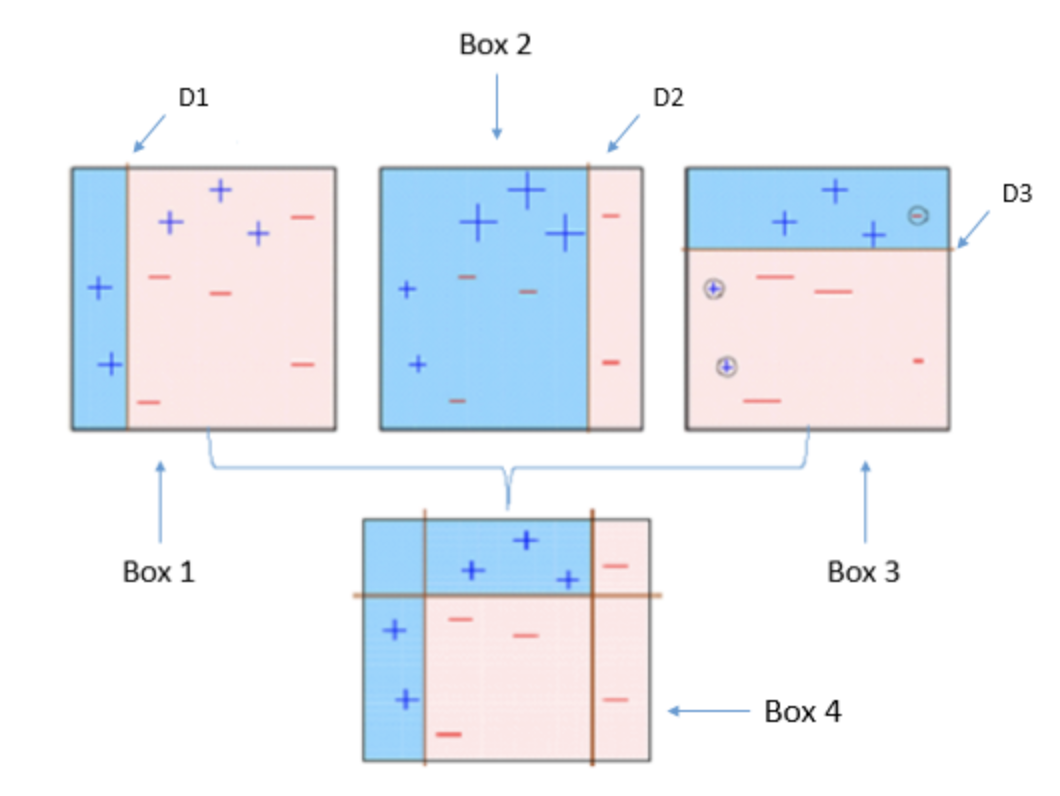
AdaBoost은 그래디언트 부스팅과 유사하지만 비용함수(Loss Function)을 최적화하는 방법에 있어서 차이가 있다. AdaBoost에서는 샘플의 가중치를 조정하여 가중치가 더 큰 데이터를 학습시키도록 하는 효과가 있다.
1️⃣ 모든 관측치에 대해 가중치를 동일하게 설정한다.
2️⃣ 관측치를 복원추출하여 약한 학습기 Dn을 학습하고 +와 -를 분류한다.
3️⃣ 잘못 분류된 관측치에 가중치를 부여해 다음 과정에서 샘플링이 잘 되도록 한다.
4️⃣ 2️⃣~3️⃣의 과정을 n회 반복한다.
5️⃣ 분류기들(D1, D2,...,Dn)을 결합하여 최종 예측을 수행한다.
AdaBoost의 의사코드는 아래와 같다.

최종 학습기 는 약한 학습기들의 가중()합으로 만들어진다.
여기에서 가 크면 가 작다는 것으로 분류기 성능이 좋다는 것이고
여기에서 가 작으면 가 크다는 것으로 분류기 성능이 안 좋다는 뜻이다.
Gradient Boosting
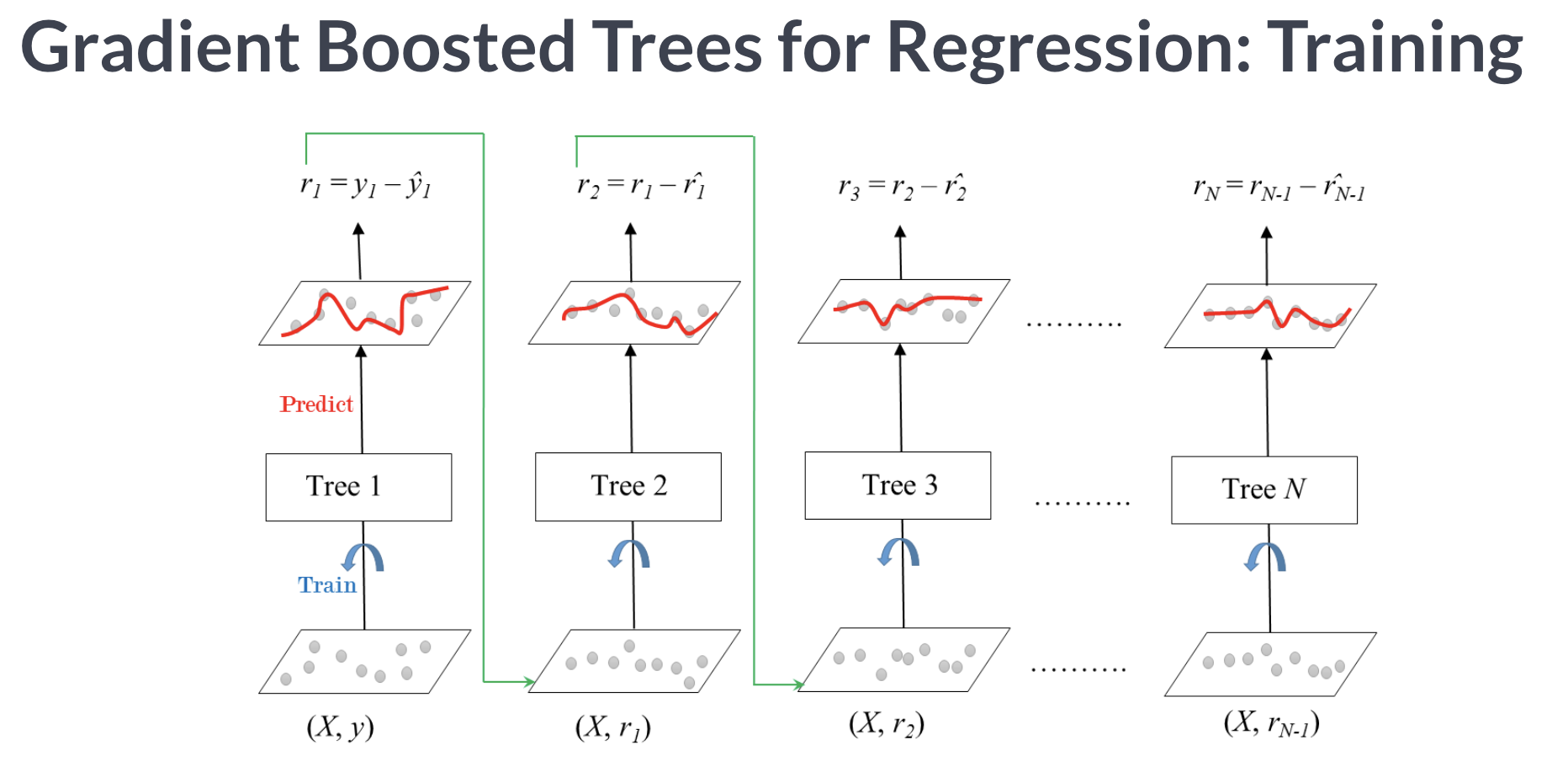
그래디언트 부스팅은 회귀와 분류 문제에 모두 사용할 수 있다.
그래디언트 부스팅은 AdaBoost와 유사하지만 비용함수(Loss Function)을 최적화하는 방법에 있어서 차이가 있다. 그래디언트 부스트에서는 잔차(residual)을 학습하도록 하여 잔차가 더 큰 데이터를 더 학습하도록 만든다.
sklearn 외에 부스팅이 구현된 여러가지 라이브러리를 사용할 수 있다.
- scikit-learn Gradient Tree Boosting : 상대적으로 속도가 느릴 수 있다.
- xgboost : 결측값을 수용하며, monotonic constraints를 강제할 수 있다.
- LightGBM : 결측값을 수용하며, monotonic constraints를 강제할 수 있다.
- CatBoost : 결측값을 수용하며 categorical features를 전처리 없이 사용할 수 있다.
monotonic constraints
단조증가해야하는 특성이 오류로 비단조 증가할 때, 변수마다 적용이 가능하다.
xgboost 라이브러리의 ML 모델
from xgboost import XGBClassifier
pipe = make_pipeline(
OrdinalEncoder(),
SimpleImputer(strategy = 'median'),
XGBClassifier(n_estimator = 200
, random_state = 2
, n_jobs = -1
, max_depth = 7
, learning_rate = 0.2
)
)
pipe.fit(X_train, y_train);xgboost는 랜덤포레스트보다 하이퍼파라미터 세팅에 더 민감하다.
또한 과적합을 잡는데 효과적인 라이브러리이다.
min_child_weight in xgboost: 과적합 막기
분할과정에서 leaf의 child의 weight을 다 더한 것보다 작으면 분할을 멈춘다. leaf의 weight을 보고 지정한 것보다 작으면 분류를 멈추는 규제를 적용해서 과적합을 막을 수 있다.
scale_pos_weight : data imbalance 맞춰주기
Early stopping을 사용해서 과적합 피하기
n_estimators 최적화를 위해 GridSearchCV나 반복문 대신 early stopping을 사용한다. 왜냐하면 n_iterations가 반복수라고 할 때, early stopping을 사용하면 우리는 n_iterations만큼의 트리를 학습하면 된다.
하지만 GridSearchCV나 반복문을 사용하면 무려 sum(range(1,n_rounds+1))만큼의 트리를 학습해야 한다. 또한 max_depth와 learning_rate등의 파라임터 값에따라 더 돌려야한다.
타겟의 비율이 균형이 맞지 않을 때는 클래스에 weight을 주기 위해 ratio를 계산한다.
# class에 적용할 weight 계산하기
vc = y_train.value_counts().tolist()
ratio = float(vc[0]/vc[1])ratio
encoder = OrdinalEncoder()
X_train_encoded = encoder.fit_transform(X_train) #학습데이터 인코딩
X_val_encoded = encoder.transfor,(X_val) #검증데이터 인코딩
model = XGBClassifier(
n_estimators = 1000, # 1000 트리로 설정했지만, early stopping 에 따라 조절된다.
max_depth = 7, # default=3이며 high cardinality 특성을 위해 기본보다 높였다.
learning_rate = 0.2,
#scale_pos_weight=ratio, # imbalance 데이터 일 경우 비율을 적용합니다.
n_jobs = -1
)
eval_set = [(X_train_encoded, y_train),
(X_val_encoded, y_val)]
model.fit(X_train_encoded, y_train,
eval_set=eval_set,
eval_metric='error', # #(wrong cases)/#(all cases)
early_stopping_rounds=50
) # 50 rounds 동안 스코어의 개선이 없으면 멈춤위의 계산식은 아래와 같은 결과값이 남는다.
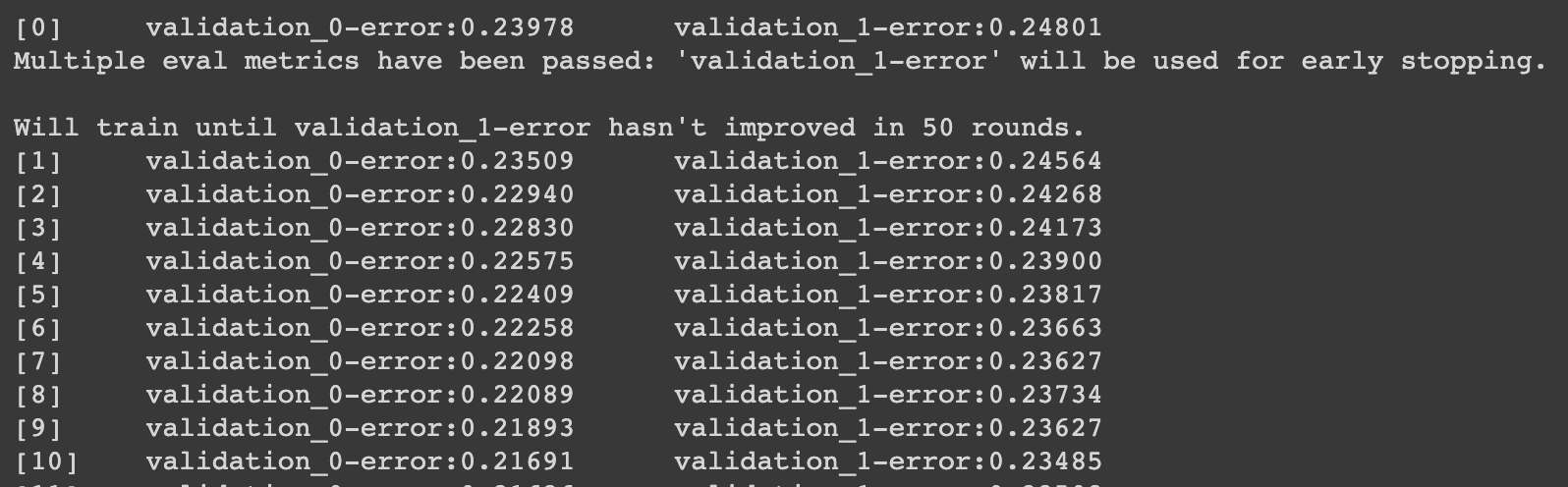
results = model.evals_result()
train_error = results['validation_0']['error']
val_error = results['validation_1']['error']
epoch = range(1, len(train_error)+1)
plt.plot(epoch, train_error, label='Train')
plt.plot(epoch, val_error, label='Validation')
plt.ylabel('Classification Error')
plt.xlabel('Model Complexity (n_estimators)')
plt.ylim((0.15, 0.25)) # Zoom in
plt.legend();