Contents-based filtering
Contents-based filtering은 콘텐츠 기반 필터링 방식으로, 사용자가 특정 아이템을 선호하는 경우 그 아이템과 비슷한 콘텐츠(content)를 가진 다른 아이템을 추천해주는 것이다. 예를 들어 사용자가 영화 '인셉션'과 '인터스텔라'를 보고 '좋아요'라고 평가했다면 두 영화는 SF 장르이고 감독이 같으므로 해당 감독의 다른 SF 영화를 추천해주는 방식이다. 따라서 콘텐츠 기반 필터링이란 아이템들의 특징 간 유사도에 따라 추천을 한다는 의미이다.
Item Profile : 사용자가 좋아한 아이템을 뽑아낸 목록
User Profile : Item Profile의 공통된 특징을 뽑아낸 결과
즉, User Profile의 특징(feature, contents)에 기반한 아이템을 추천하는 것이 Contents-based filtering이다.
아이템이 영화라면 user profile에는 감독, 제목, 배우 등이 해당되는 것이다.
Contents-based filtering의 장점
1) 다른 사용자의 데이터가 불필요하다.
개인의 평가에 기반하여 아이템을 추천하기 때문에 추천 내역이 부족하여 발생할 수 있는 아래의 문제로부터 자유로운 편이다.
- cold-start problem: 해당 아이템을 추천한 사람이 없어 추천이 어려운 문제.
- sparsity problem: 모든 유저들이 모든 아이템에 대해 평가하지 않아 생기는 문제.
2) 사용자의 특정 관심사를 포착하여 새로운 아이템이나 대중적이지 않은 아이템도 추천할 수 있다.
아무도 평가하지 않은 아이템이나 인기없는 아이템도 콘텐츠 혹은 특징(feature)을 바탕으로 추천.
3) 사용자에게 추천하는 이유에 대한 설명이 가능하다.
사용자가 선호하는 아이템들의 특징을 바탕으로 추천하기 때문에 해당 아이템이 왜 추천되었는지에 대해 이해할 수 있다.
Contents-based filtering의 단점
1) 아이템의 콘텐츠는 어느 정도 수작업으로 이루어지기 때문에 도메인 지식이 필요하므로 수작업의 완성도에 따라 추천의 효과성이 좌우된다.
2) 사용자의 기존 관심분야를 기반으로만 추천할 수 있어서 사용자의 관심사가 확장될 때 효과적이지 않을 수 있다.
원리 : 유사도 함수 사용
유사도 함수는 특정 아이템과 가장 비슷한 아이템을 찾을 때 사용하는 것으로 특정 아이템의 콘텐츠와 어떤 아이템의 콘텐츠가 유사한지 판단하기 위한 것이다. 이를 계산하기 위해 아이템의 콘텐츠를 벡터로 변환하여 유사도를 측정하게 된다. content, 즉 item의 feature들을 count 기반으로 벡터 변환을 한뒤, 해당 feature 백터화 행렬 데이터셋을 다른 item의 벡터와의 유사도를 통해 비교할 수 있게 된다. 대표적인 유사도 함수에는 유클리디안, 코사인, 피어슨, 자카드 유사도 등이 있다.
##유클리디안 유사도
##코사인 유사도 (가장 많이 사용)
코사인 유사도는 두 벡터 간의 코사인 각도를 이용하여 구할 수 있는 두 벡터의 유사도를 의미한다. 두 벡터의 방향이 완전히 동일한 경우에는 1의 값을 가지며 90도의 각을 가지면 0, 180도의 각을 가지면 -1의 값을 가지게 된다. 즉, -1이상 1 이하의 값을 가지며 값이 1에 가까울수록 유사도가 높다고 판단할 수 있다. 즉, 두 벡터가 가리키는 방향이 얼마나 유사한지를 볼 수 있는 것이다.
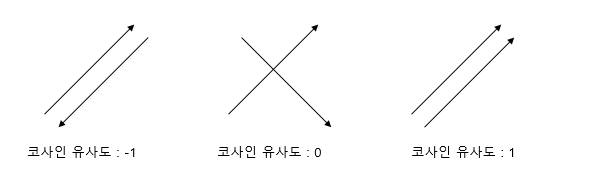

코사인 유사도는 유사도를 구할 때 벡터의 방향(패턴)에 초점을 두기 때문에 문서의 길이가 다른 상황에서 비교적 공정한 비교를 할 수 있게 도와준다.
[ 참고자료 ]
이미지 https://ariz1623.tistory.com/230
https://developers.google.com/machine-learning/recommendation/content-based/basics
https://ssongblog.tistory.com/112
