-
데이터전처리
1) 결측치 탐색: isnull().sum()
결측치 처리: fillna(대체값,inplace=True)
2) 인코딩
문자열 feature -> 숫자형 변형
- LabelEncoder : 0,1,2,3 <=
- OneHotEncoder : 가변수(dummy) 처리
예) 4개 범주 -> 4개 가변수
사과, 배, 포도, 딸기 : 2차원
희소행렬(sparse matrix)
sklearn.preprocessing -> fit(), transform()3) scaling
- Z-scoring(Standarization) 표준화: 평균 0 ,표준편차 1
StandardScaler - Min-Max Scaling: 최소 0, 최대 1
MinMaxScaler - 벡터 정규화(Normalization)
NormalScaler
fit(), transform()
- Z-scoring(Standarization) 표준화: 평균 0 ,표준편차 1
-
모델 평가 지표
1) 정확도(accuracy): (Tp+Tn)/(Tp+Tn+Fp+Fn)
2) 정밀도(precision): Tp /(Tp+Fp)
3) 재현율(recall): Tp / (Tp+Fn)
오차행렬(confusion matrix)
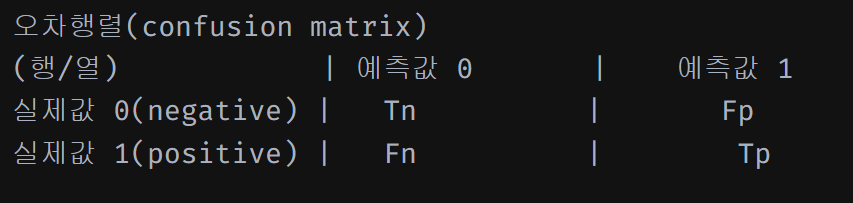
실제값이 치우쳐져있으면 예측값도 치우쳐질 것이기 때문에 데이터 불균형을 해소하기 위한 방안들을 고려해야 함.
분류를 결정하기 위한 기준값(임계값)
threshold
0.5
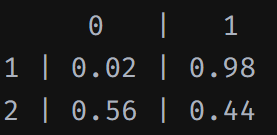
0.4로 바꾸면 0.4보다 크면 1, 그렇지 않으면 0으로 판단.
4) f1 score : 정밀도와 재현율의 조화평균
5) G- measure: 정밀도오 재현율의 기하평균 sqrt(정밀도*재현율)
6) ROC curve : TPR(민감도) / FPR(특이성)

7) AUC

💛 공부 블로그 💛