개요
GIGO

예전에 게임 알고리듬 수업에서 배웠던 GIGO.
아무리 좋은 해결 모델이 있더라도 데이터가 좋지 않으면 결과도 좋지 않다는 것을 표현하는 Garbage In Garbage Out.
[알쓸범잡 e13] 인공지능은 정말로 공정할까?! 기술은 누가 통제하는가
학부 수업에서 인공지능과 관련된 이슈 중에 인간이 만든 데이터가 편향되어 있으면 아무리 객관적으로 데이터를 분류하는 인공지능이라하더라도 결과과 편향되어있기 때문에 그것이 과연 윤리적으로 옳은가, 인간이 살아가는 데에 있어서 생기는 문제를 '잘' 해결하고, 그런 문제가 일어나지 않도록 발전하는 데에 도움이 될 수 있는 자료나 근거가 되는가는 여전히 생각해봐야할 것이라는 이야기를 했던 기억이 난다.
이런 크고 아름다운 이야기(윤리나 기술철학과 같은 이야기)말고도 작고 아름답지 않은 이야기에서도 이는 마찬가지라서 data processing(데이터 전처리)를 거쳐 데이터를 특정 분석에 적합하게 가공해서 데이터의 품질을 일정 수준 이상으로 맞춰야 작고 아름답지 않은 문제들을 해결할 수 있다.
Data Analysis의 과정
데이터 분석의 과정은 크게 아래처럼 표현할 수 있다.
데이터분석의 과정
[문제 정의] -> [데이터 수집] -> [데이터 전처리] -> [데이터 분석(모델링)] -> [리포팅/피드백]
1️⃣ 문제 정의
문제가 제대로 설정되지 않는다면 어떻게 해결할지도 생각할 수 없는 법이다.
해결하고자 하는 문제가 무엇인지 정확하게 알고 이를 설정하는 것이 매우 중요하다.
좋은 문제 정의란 무엇인가는 다음과 같이 표현할 수 있을 것 같다.
- 분석의 대상, 분석의 목적이 명확하다.
- 정의된 문제를 해결하기 위한 구체적인 계획을 수립할 수 있다.
- 문제를 정의할 분야에 대한 도메인 지식이 명확하다.
- 모든 사람들이 명료하게 이해할 수 있도록 구체적으로 표현할 수 있다.
2️⃣ 데이터 수집
비록 빅데이터가 아주 많은 데이터를 의미하지만 데이터의 양이 많다고 좋은 데이터가 아니다.
- 데이터가 존재하지 않거나, 너무 많지 않은가?
- 예산, 법적, 윤리적인 문제가 없는 데이터인가?
- 최근 데이터 수집 방법에는 데이터 구매, 스스로 데이터 생성하기, 웹 크롤링, open datasets을 활용하는 방식들이 있다.
💾 Open datasets
- 국내 : AI hub , 공공 데이터 포털
- 국외 : UCI Repository , MNIST
- 기타 : Fashion-MNIST , Open Images Dataset , Kaggle
3️⃣ 데이터 전처리
Data Processing(데이터 전처리)란 특정 분석에 적합하게 데이터를 가공하는 작업을 의미한다.
가장 많은 effort가 들어가는 과정이라고 한다. 대부분의 데이터가 분석을 분석을 전제로 생성된 것이 아니기도 하고 데이터 자체의 품질이 별로인 경우가 많기 때문이다.
예를 들어 문제를 해결하기 위해서 그의 기반이 될 데이터를 받았는데 그 데이터 안에 문제를 해결하는 데에 필요 없는 값이 포함되어 있거나, NA값이 존재하는 등 수많은 변수는 데이터의 품질을 떨어뜨린다. 이러한 데이터의 품질을 저하하는 요인들을 방지하기 위한 작업을 데이터 전처리라고 한다.
"데이터 과학의 80%는 데이터 클리닝에 소비되고, 나머지 20%는 데이터 클리닝하는 시간을 불평하는데 쓰인다."
-'kaggle' 창립자 Anthony Goldbloom-
데이터 전처리에 앞서: 데이터 탐색
데이터의 특성을 파악하고 여러 관계를 찾기 위해 데이터를 탐색한 뒤 데이터 전처리를 한다고 한다. 데이터 탐색 과정에서는 데이터들의 여러 관계를 찾아야 하기 때문에 많은 방법이 있을 수 있고 가장 핵심적인 부분 중 하나이다.
EDA(Exploratory Data Analysis, 탐색적 데이터 분석)를 하거나 상관 관계 , 분포 확인 , 인과 관계 등을 직접 확인하는 방식으로 해당 데이터를 탐색할 수 있다.
Data Processing의 과정
위의 단계 중 이 포스팅에서 살펴볼 '데이터 전처리'도 일련의 과정을 거쳐야 한다.데이터 혹은 분석 목적, 작업마다 해야하는 데이터의 전처리는 다르지만 크게 다음과 같은 flow를 갖는다.
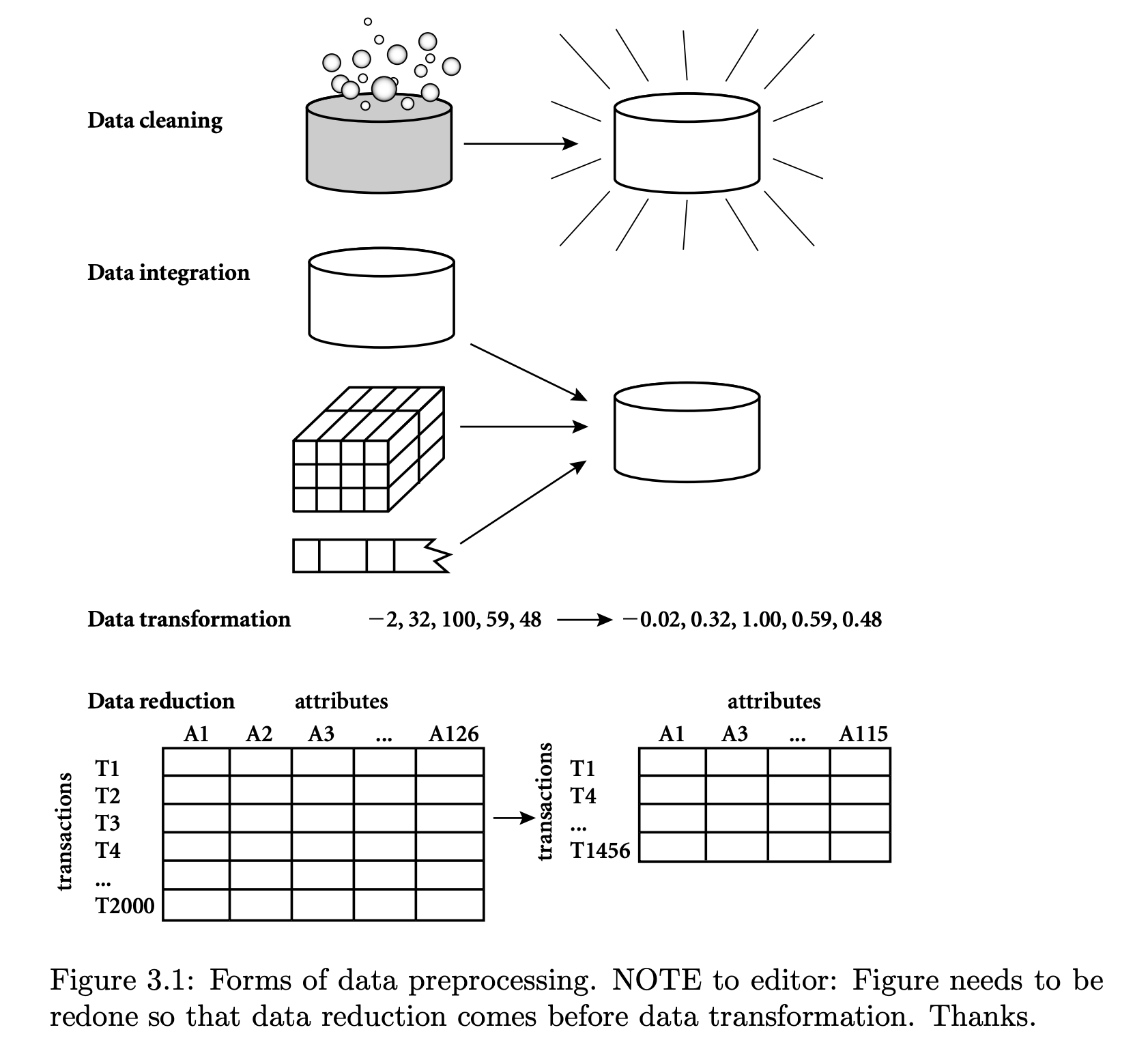
데이터 전처리 개요
- 필요한 이유: 분석에 부적합한 구조, 누락된 항목, NA(결측값) 존재 등으로 인해 전처리 과정이 필요하다.
- 데이터 전처리에서 하는 일 : 노이즈 제거 , 중복값 제거 , 결측값 보정 , 데이터 연계/통합 , 데이터 구조 변경(차원 변경) 등
- 데이터 전처리에서 사용하는 것들: 데이터 벡터화 , outlier detection, Feature Engineering 등이 있다.
데이터 전처리의 과정
1. cleansing
2. Integration
3. Transformation
4. Reduction
💙 cleansing
Missing Values
Missing Value(결측치)에 대해서는 전에 포스팅에서 자세하게 알아봤었다.
아래와 같은 방법으로 처리할 수 있다.
- Ignore the tuple (결측치가 있는 데이터 삭제)
- Manual Fill (수동으로 입력)
- Global Constant ("Unknown")
- Imputation (All mean, Class mean, Inference mean, Regression 등)
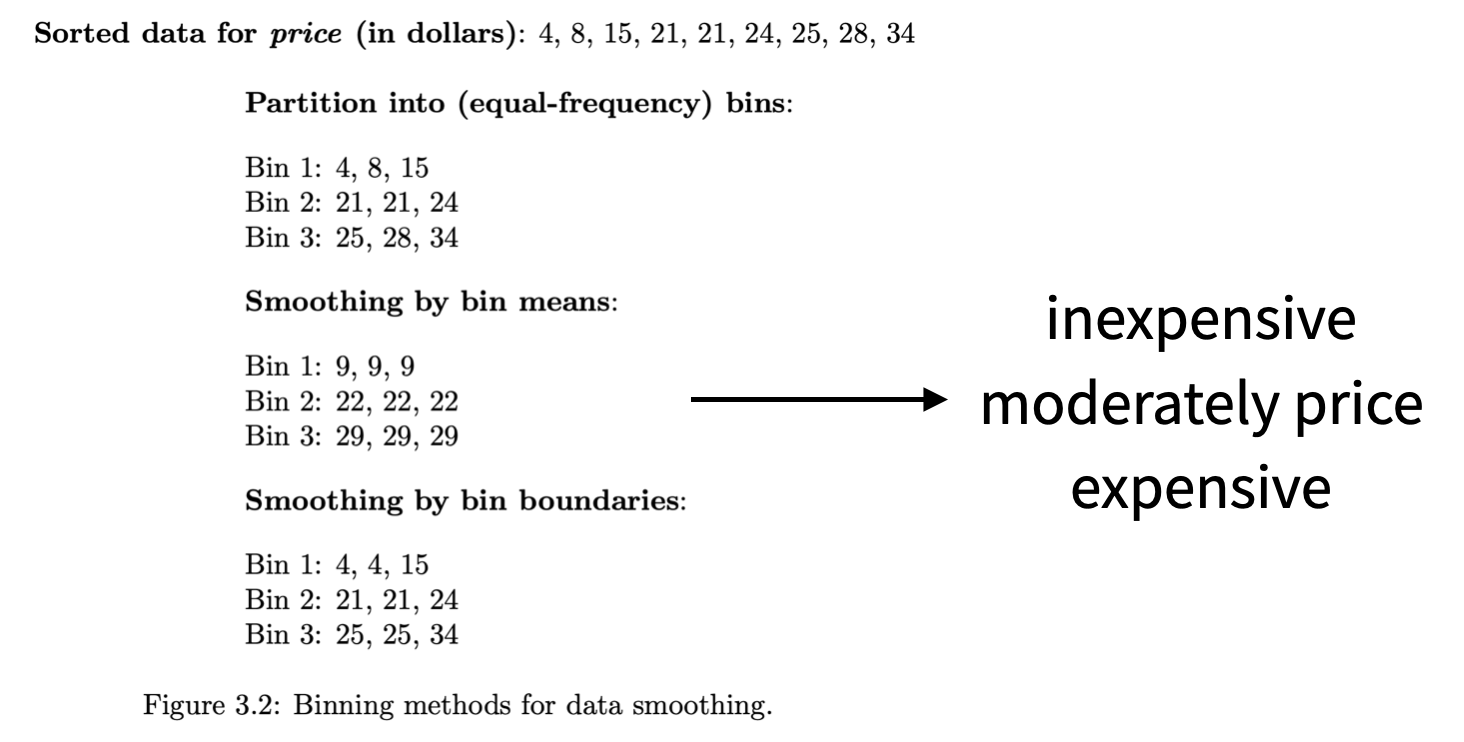
Noisy data
Noisy data 혹은 Noise란, 큰 방향성에서 벗어난 random error 혹은 variance를 포함하는 데이터이다.
대부분 descriptive statistics 혹은 visualization 등(EDA)을 통해 Noisy data를 처리할 수 있다.
혹은 binning, regression, outlier analysis를 통해 처리할 수 있다.
💙 Integration
여러 개로 나누어져 있는 데이터들을 분석하기 편하게 하나로 합치는 과정이다.
ex) merge
💙 Transformation
데이터의 형태를 변환하는 작업으로, scaling이라고 부르기도 한다.
ex) normalize
💙 Reduction
데이터를 의미있게 줄이는 것을 의미하며, dimension reduction과 유사한 목적을 갖는다.
ex) pca
4️⃣ 모델링
원하는 결과를 도출하기 위해서 예측이나 분류, 회귀를 통해 작업을 진행하는 단계이다. 즉 전처리된 데이터를 관점별로 나누고 쪼개어서 분석하는 과정이다. 성능을 높이기 위해 parameter 튜닝 작업을 진행할 수 있다. 이 과정에서 많은 비용이 발생할 수 있으며 다양한 머신러닝 기법들 (DT, randomForest, SVM, k-NN 등)을 사용할 수 있다.
5️⃣ 리포팅/피드백
이러한 과정을 거쳐 도출된 결과를 시각적으로 표현하거나 해석할 수 있다. 정의했던 문제와 도출된 결과를 연관시켜 문제를 해결하는 방법을 모색하는 단계이다. 이 때,시각화를 통해 도출된 결과를 알아보기 쉽게 표현할 수도 있고, 도출된 결과가 적합하거나 정확한지 피드백을 받거나 이를 근거로서 활용할 수 있는지 등을 확인할 수 있는 단계이다.
더 찾아볼 것
❓binning
❓regression
❓outlier analysis
