분류문제를 풀어야한다면 데이터가 선형이든, 비선형이든 랜덤포레스트를 적용해보는 것이 좋다.
결정트리모델은 한 개의 트리만 사용해야하기 때문에 한 노드에서 생긴 에러가 하부 노드에서도 계속 영향을 주는 특성이 있으며 트리의 깊이에 따라 과적합되는 경향이 있다. 이러한 문제를 앙상블 모델인 랜덤포레스트를 사용하면 개선할 수 있다.
랜덤포레스트 (feat. 결정트리)
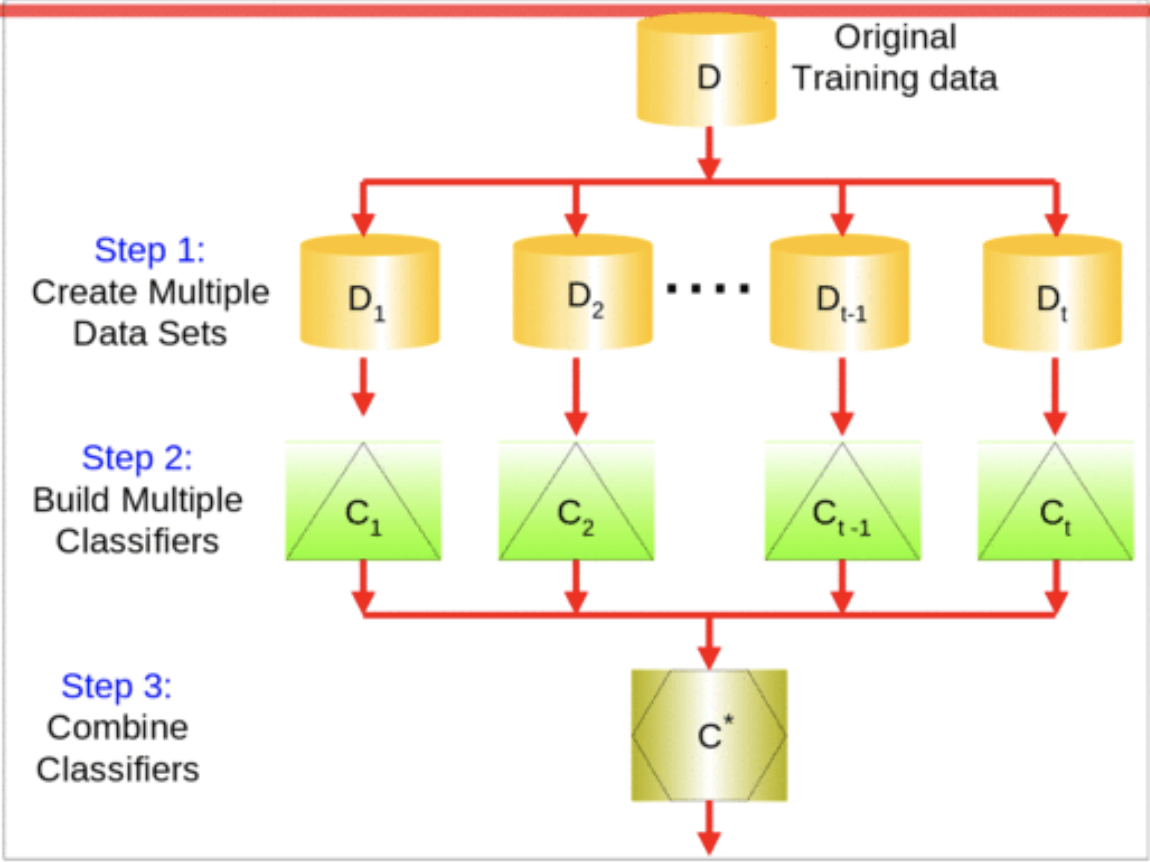
앙상블 방법: 한 종류의 데이터로 여러 머신러닝 학습모델(weak base learner, 기본모델)을 만들어 그 모델들의 예측결과를 다수결이나 평균을 내어 예측하는 방법.
랜덤포레스트: 결정트리를 기본모델로 사용하는 앙상블 방법
 위의 이미지는 랜덤 포레스트의 의사코드(pseudo code)이다.
위의 이미지는 랜덤 포레스트의 의사코드(pseudo code)이다.
결정트리들은 독립적으로 만들어지며 각각 랜덤으로 예측하는 성능보다 좋을 경우 랜덤포레스트는 결정트리보다 성능이 좋다.
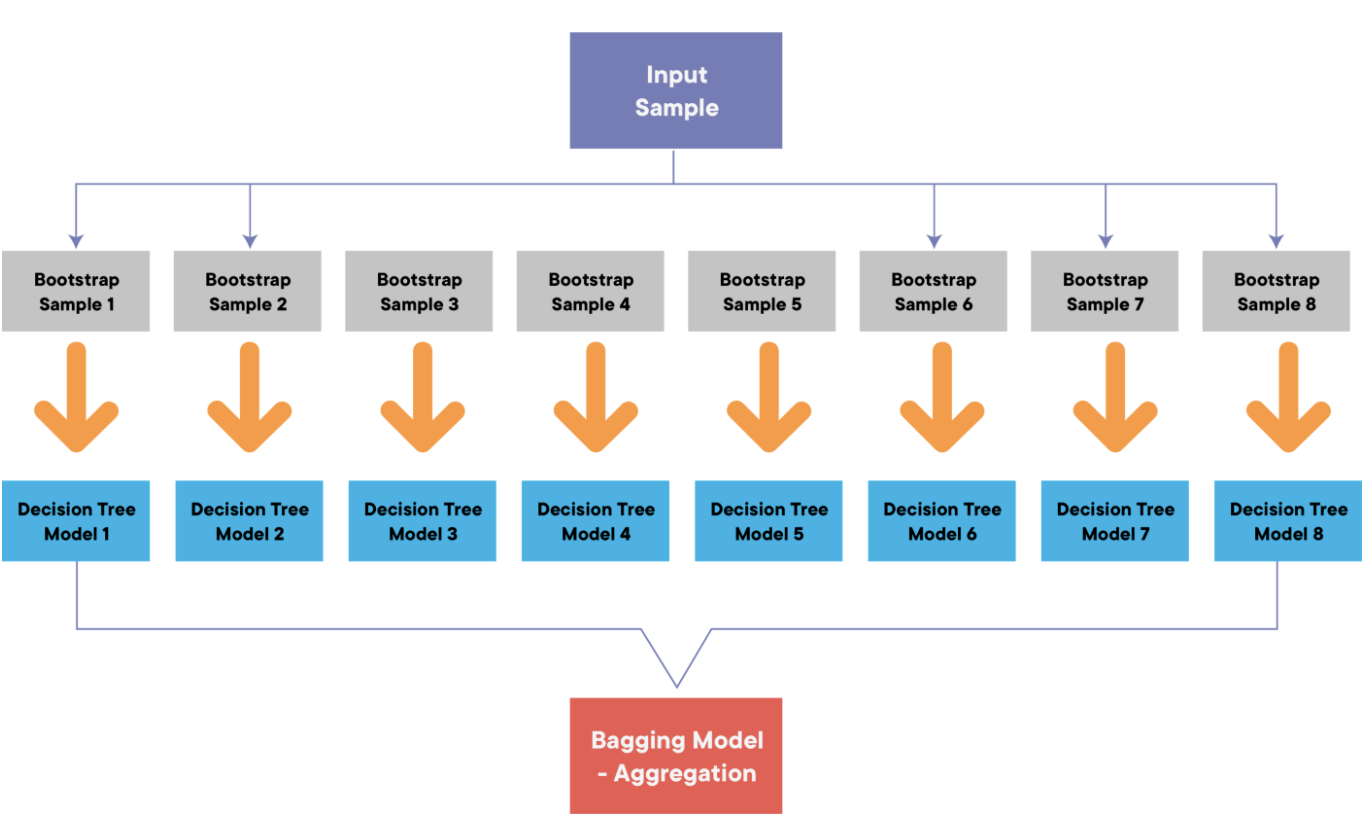
랜덤포레스트는 기본모델들의 트리를 만들 때 무작위로 선택한 특성세트를 사용한다. 랜덤포레스트의 랜덤성은 아래 두 가지에서 나온다. 이러한 랜덤성 때문에 트리 앙상블 모델이 결정 트리 모델보다 상대적으로 과적합을 피할 수 있게 된다.
랜덤포레스트의 랜덤성의 원인
- 1) 랜덤포레스트에서 학습되는 트리들은 bagging을 통해 만들어진다.(
bootstrap = true) 이 때, 각 기본트리에 사용되는 데이터가 랜덤으로 선택된다.- 2) 각 트리는 무작위로 선택된 특성을 가지고 분기를 수행한다. (
max_features = auto)
랜덤포레스트는 기본 모델들의 트리를 만들 때 무작위로 선택한 특성 세트를 이용한다.
랜덤포레스트 vs 결정포레스트
결정트리: 데이터의 일부에 과적합하는 경향이 있다.
랜덤포레스트: 다르게 샘플링된 데이터로 과적합된 트리를 많이 만들고 그 결과를 평균내어서 사용하는 모델로 과적합을 줄이고 성능을 유지한다.
랜덤포레스트와 결정포레스트가 기본모델 트리를 만드는 방법의 차이점.
- 결정트리: 분할을 위한 특성을 선택할 때, 모든 특성(n개)를 고려하여 최적의 특성을 고른다.
- 랜덤포레스트: 특성 n개 중 일부분 k개의 특성을 선택(sampling)하고 이 k개에서 최적의 특성을 찾아내어 분할한다. 이 때 k는 일반적으로 를 사용한다.
랜덤포레스트에서는 학습 후 특성들의 중요도 정보(gini importance)를 기본으로 제공한다. 중요도는 노드들의 지니불순도(gini impurity)를 가지고 계산하며 노드가 중요할수록 불순도가 크게 감소한다는 사실을 이용한다. 노드는 한 특성의 값을 기준으로 분리가 되기 때문에 불순도를 크게 감소하는데 많이 사용된 특성이 중요도가 올라간다.
bagging(Bootstrap AggraGating)
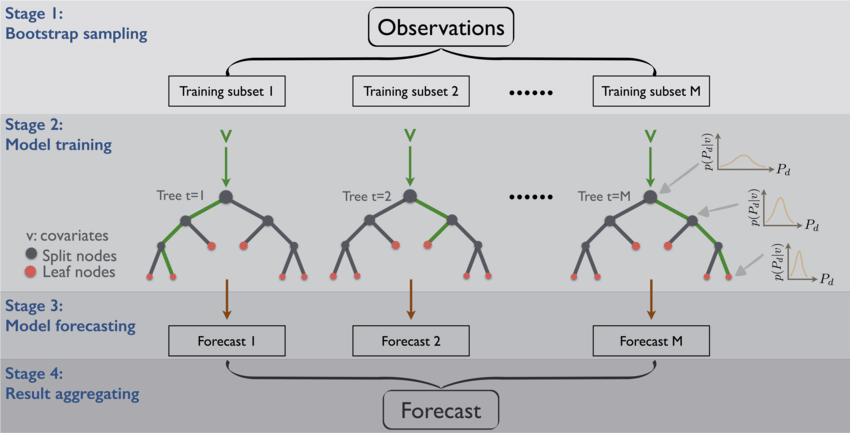
Bootstrap sampling
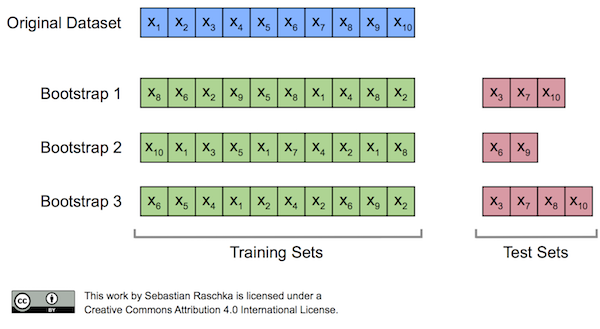
앙상블에 사용하는 작은 모델들은 부트스트래핑(bootstrapping)이라는 샘플링 과정으로 얻은 부트스트랩세트를 사용해서 학습을 한다. 이는 원본 데이터에서 복원추출로 샘플링을 한다는 것으로 복원추출이란 샘플을 뽑아 값을 기록하고 제자리에 돌려놓는 것을 말한다.
샘플링을 특정한 수만큼 반복하면 하나의 부트스트랩세트가 완성된다.
Aggragation
부트스트랩세트로 만들어진 기본모델들을 합치는 과정을 aggregation이라고 한다.
- 회귀 문제: 기본모델의 결과들의 평균으로 예측한다.
- 분류 문제: 다수결로 가장 많은 모델들이 선택한 범주로 예측한다.
OOB(Out-of-Bag)
부트스트랩세트의 크기가 n이라면
- 한 번의 추출 과정에서 어떤 한 샘플이 추출되지 않을 확률 =
- n회의 복원추출을 진행했을 때 그 샘플이 추출되지 않았을 확률 =
n을 무한히 크게 했을 때 식은 다음처럼 나타낼 수 있다.
데이터가 충분히 크다면 한 부트스트랩세트는 표본의 63.2%에 해당하는 샘플을 가지게 된다. 여기서 추출되지 않은 36.8%의 샘플이 out-of-bag 샘플이며 이것을 사용해 모델을 검증할 수 있다.
pipe.named_steps['randomforestclassifier'].oob_score_랜덤포레스트 특성 중요도 비교
랜덤포레스트에서는 학습 후에 특성들의 중요도 정보(Gini importance)를 기본으로 제공한다.
중요도 정보(Gini importance)는 노드들의 지니불순도(Gini impurity)를 가지고 계산하며 노드가 중요할수록 불순도가 크게 감소한다는 점을 이용한다.
한 개의 노드에는 한 개의 특성의 값을 기준으로 데이터를 분리하기 때문에 특성의 중요도가 높을수록 불순도를 크게 감소한다고 할 수 있다.
인코딩 방식에 따라 결과값이 달라질 수 있다.
#특성 중요도 by One-Hot encoding
rf = pipe.named_steps['randomforestclassifier']
colnames = pipe.named_steps['onehotencoder'].get_feature_names()
importances = pd.Series(rf.feature_importances_,colnames)
n = 10
plt.figure(figsize = (10, n/4))
plt.title(f'Top {n} features with onehotencoder')
importances.sort_values()[-n:].plot.barh();#특성 중요도 by Ordinal encoding
rf = pipe_ord.named_steps['randomforestclassifier']
importances_ord = pd.Series(rf_ord.feature_importances_,X_train.columns)
n = 10
plt.figure(figsize = (10, n/4))
plt.title(f'Top {n} features with ordinalencoder')
importances_ord.sort_values()[-n:].plot.barh();Ordinal Encoding할 때 범주들을 숫자형으로 바꾸게 되면 범주의 순서 정보가 생긴다. 백기와 청기를 1,2로 구분한다 했을 때 백기가 청기보다 우위에 있다던가 그러한 관계가 생길 수 있는 것이다. 따라서 순서형 인코딩은 범주들 간에 분명한 순위가 있을 때 순서의 연관성에 맞게 숫자를 정해주는 것이 좋다. 이 예로는 영화 평점(매우 싫다, 싫다, 보통이다, 좋다, 아주 좋다 등)을 들 수 있다.
