What and Why is T5 Model?
현재까지의 transfer learning에 대해 사람들이 제안한 논문들을 보면, 특정 task를 해결하기 위해서 구조를 살짝 바꾸거나 파라미터를 조정하는 시도들이 많다.
하지만, 모든 것을 같게 세팅하는, 최고의 모델을 만들순 없을까?
즉, T5, text-to-text transfer transformer의 아이디어는 다음과 같다.
Treating all text problems in the same format(모든 문제를 같은 포맷으로 해결한다)
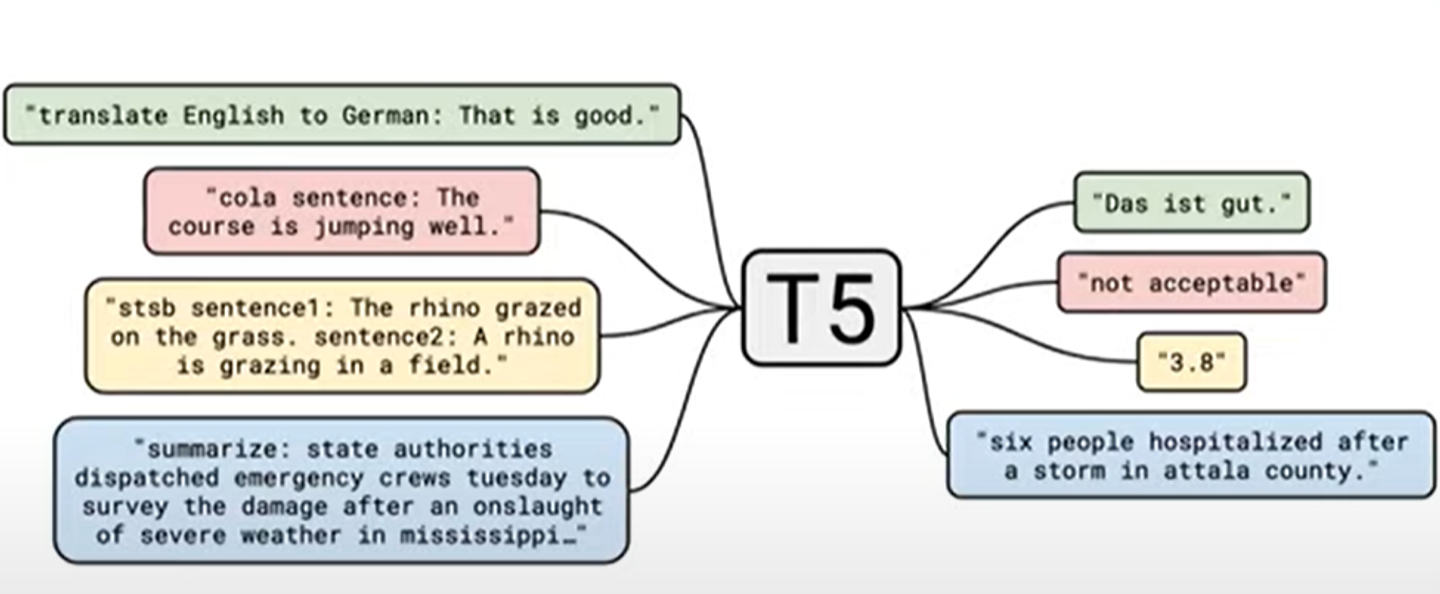
위의 그림은 T5가 할수 있는 task들의 일부를 보여준다.
여기서 다른 모델들과 특이한 다른점이 있다.
예를 들어 위의 그림에서 ‘not acceptable’을 산출한다고 할때, accept과 not acceptable을 0과 1로 라벨링하여 분류하는 모델을 만드는 것이 아니라 accept를 text 자체로 학습하는 것이다.
이는 regression task에서도 다르지 않다.
3.8이라는 숫자도 text로서 학습하는 것이다.
이처럼 모든 task를 같은 방법으로 해결하기 때문에 원래 vanilla tranformer를 제안된 그대로 사용할 수 있다는 장점이 있다.
Data source
T5를 훈련시킨 데이터셋을 어떻게 build하였는지에 대해서 알아보자.
우리는 공공에서 사용가능한 source로 부터의 데이터를 원한다.
common crawl라고 부르는 비영리 단체의 web scrape를 사용하였다.
이를 통해서 인터넷에서의 text를 가능한 많이 다운로드 하고 정제과정을 거치었다.
이를 C4 datasets이라고 부르기로 하자.
colossal clean crawl corpus을 뜻하고, 약 750기가 바이트라고 한다..덜덜
Pretraining objective(목적)

원래의 문장에서 랜덤하게 token(위의 사진에서는 word)을 골라 drop시킨다.
drop된 자리에는 x,y 같이 sentinel token으로 대체된다. 각각은 구별되는 unique token이 된다.
연속한 span은 한묶음 처리된다.
Target문장의 형태는 다음과 같다.
모델의 goal은 쉽게 말하면 빈칸을 채우는 것이다.
이는 BERT와 많이 유사하다. entire sequence가 아니라 missing word를 재건축하는 것이 목적이다.
Baseline experimental procedure
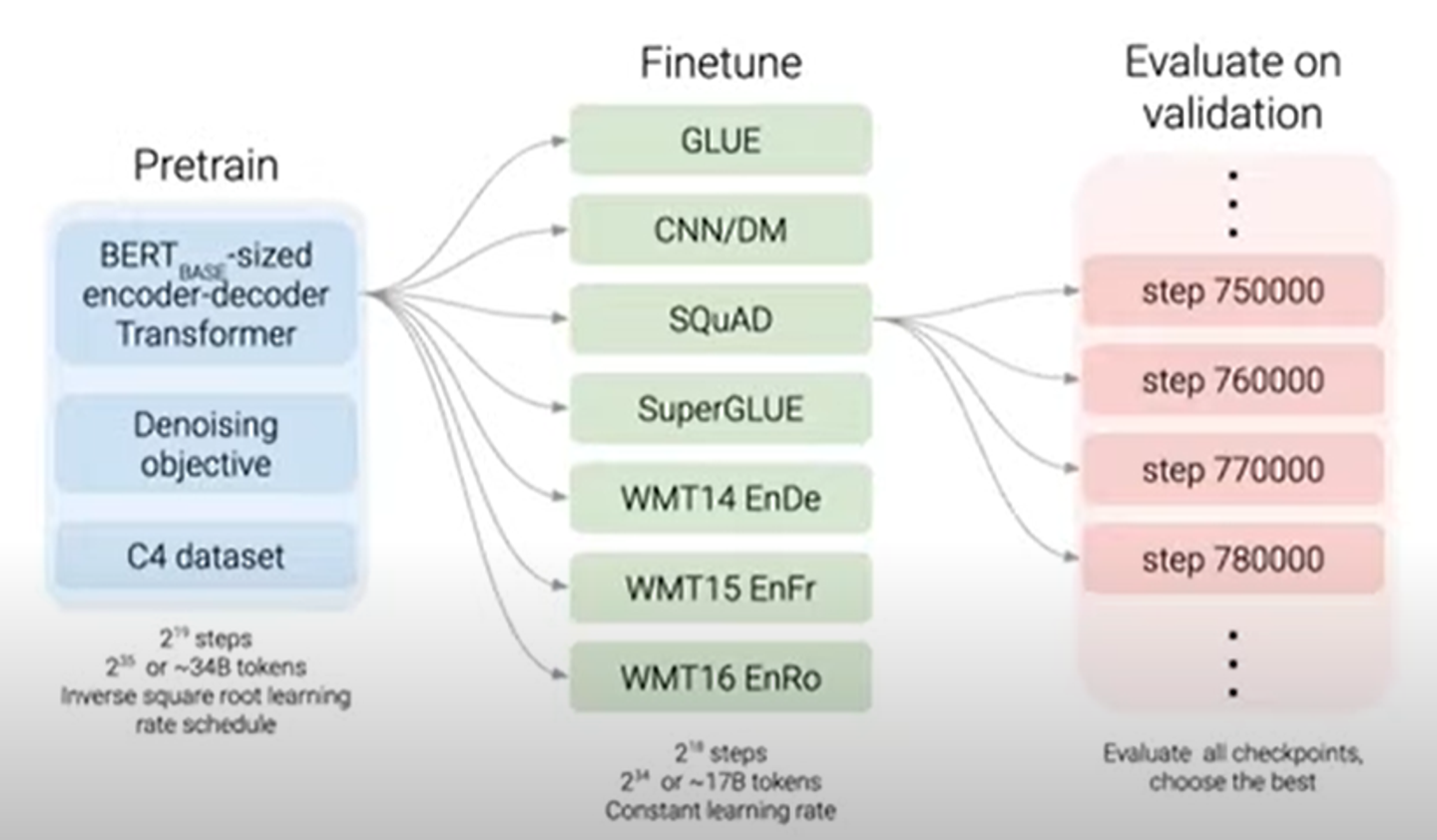
첫번째로 pretrain model에 대해서 얘기해보자.
모델로는 BERT base size의 인코더와 디코더를 사용한다. 따라서 BERT보다 파라미터의 수가 두배정도 많다.
다음으로는 Denoising objective로 아까 말한 것처럼 masked language modeling을 실시한다.
그리고 C4 datasets을 적용한다.
pre-train은 34billion의 token을 진행한다. 이는 BERT의 1/4정도의 양이다.
위에 보는 것과같은 여러 task를 진행하기 위한 finetune을 진행한다.
각 task에 대해서 간략히 설명해보겠다.
- GLUE : sentence classification, sentence-pair classification, regresstion task
- CNN/Daliy Mail : summarization
- SQuAD : question answering, reading comprehensive benchmark
- SuperGLUE: GLUE의 difficult version
- WMT14EnDe/WMT15EnFr/WMT16EnRo : translation
우리는 각각의 task에 따라 개별적으로 분리적으로? finetuning한다.
즉, 다시 말하면 pre-train모델을 가지고 각각의 downstream task에 따라 분리하여 fine tune을 진행한다.
약 17 billion token정도로 finetune한다.

다음은 experimental result이다.
확실한 것은 pre-training하지 않은 것은 성과가 매우 좋지 않다.
GLUE,CNNDM, SQuAD는 BERT와 비교해봤을 때도 낮은 성능이 아니다.
T5를 위한 design dicision
이 챕터부터는 매우 많은 실험들이 나오고 비교할 것이다.
하지만 중요한 것은 우리는 tweak any hyperparameter 을 하지 않을 것이다. !
왜냐하면 이를 바꾸면 각각의 방법에 따른 너무 큰 연산 비용이 들기 때문이다.
우리는 모든 문제들을 정확히 같은 framwork로 다루기 원하기 때문에 하이퍼파라미터를 tweak하지 않아도 괜찮다. ( text-to-text maximum likelihood training을 한다고 표현)
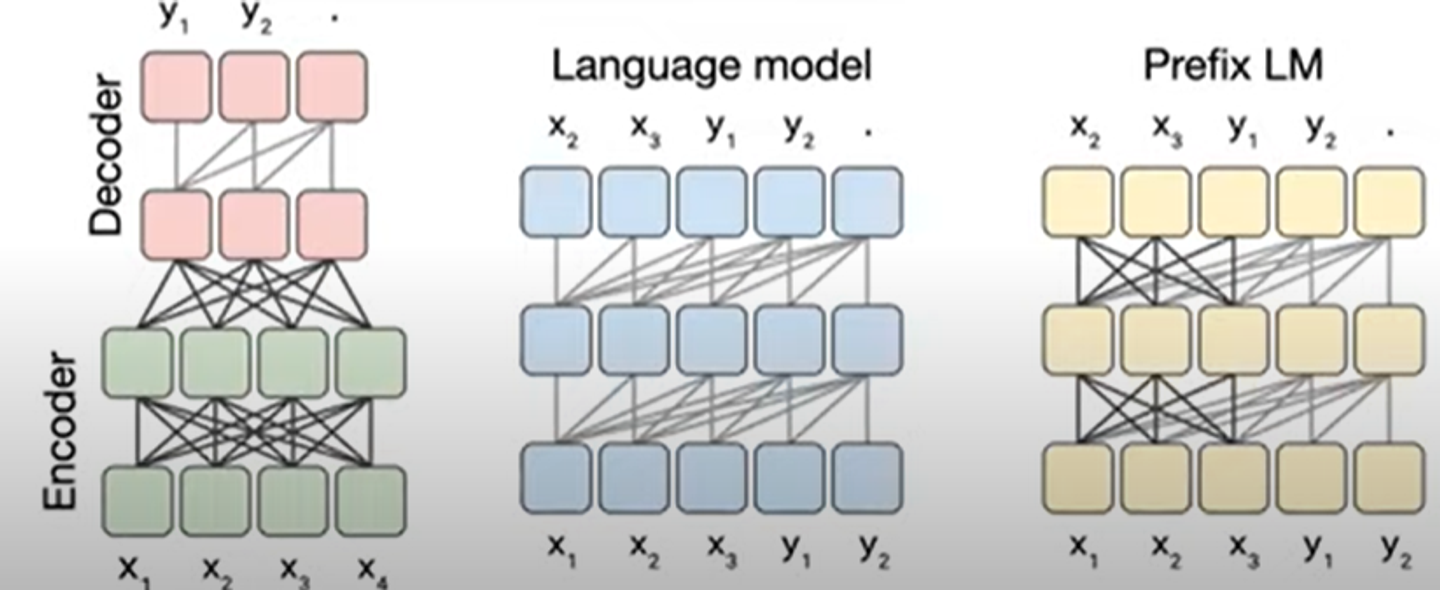
Model structures
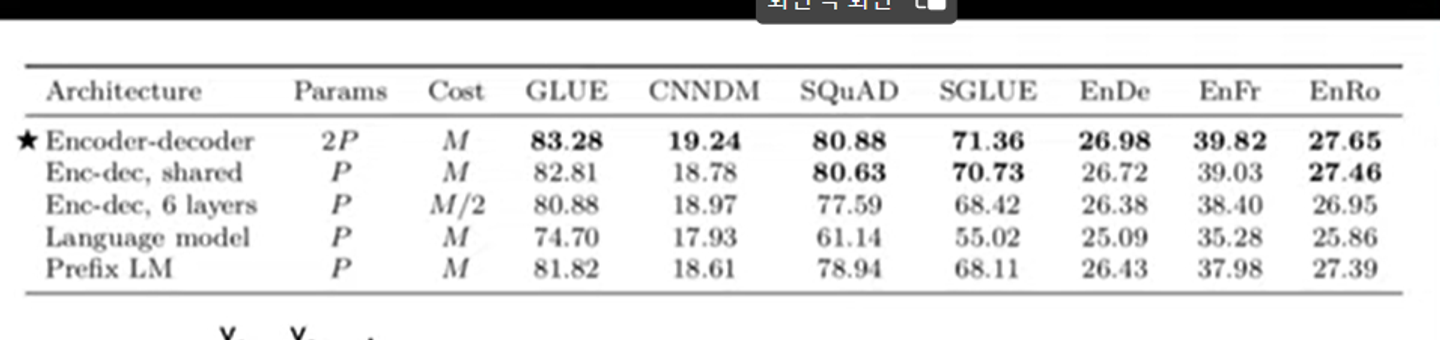
실험한 architecture에는 위의 5개가 있다.
각 모델에 대해서 간략하게 설명해보자.
- encoder-decoder : 우리가 아는 그 모델이다. 문장을 인코딩하는 층과 taget 문장을 디코딩하는 층으로 분리되어있다. target 문장을 한 토큰씩 생성해내는 것인데, 생성해내면서 encoder의 output으로 돌아가 attention을 진행한다.
- enc-doc,shared : 모든 관련된 parameters를 공유한다. 따라서 baseline모델모다 파라미터가 반절로 줄어든다.
- Enc-doc, 6layers : 원래는 각각 encoder와 decoder을 12개씩 쌓는데 6개만 쌓는다.
- language model : 엄격하게 왼쪽에서 오른쪽으로 움직인다. 한 토큰을 소화하고 다음 토큰을 예측한다.
- prefix LM: 위의 언어모델에서 input에 prefix를 추가하여 causal attention patten을 보이게 만든다.
결과, Encoder-decoder모델이 성능이 가장 좋았다.
파라미터의 개수에는 차이가 있어도 총 문장의 길이는 모두 같다. (same input sequence, same target sequence)
pre-training objective
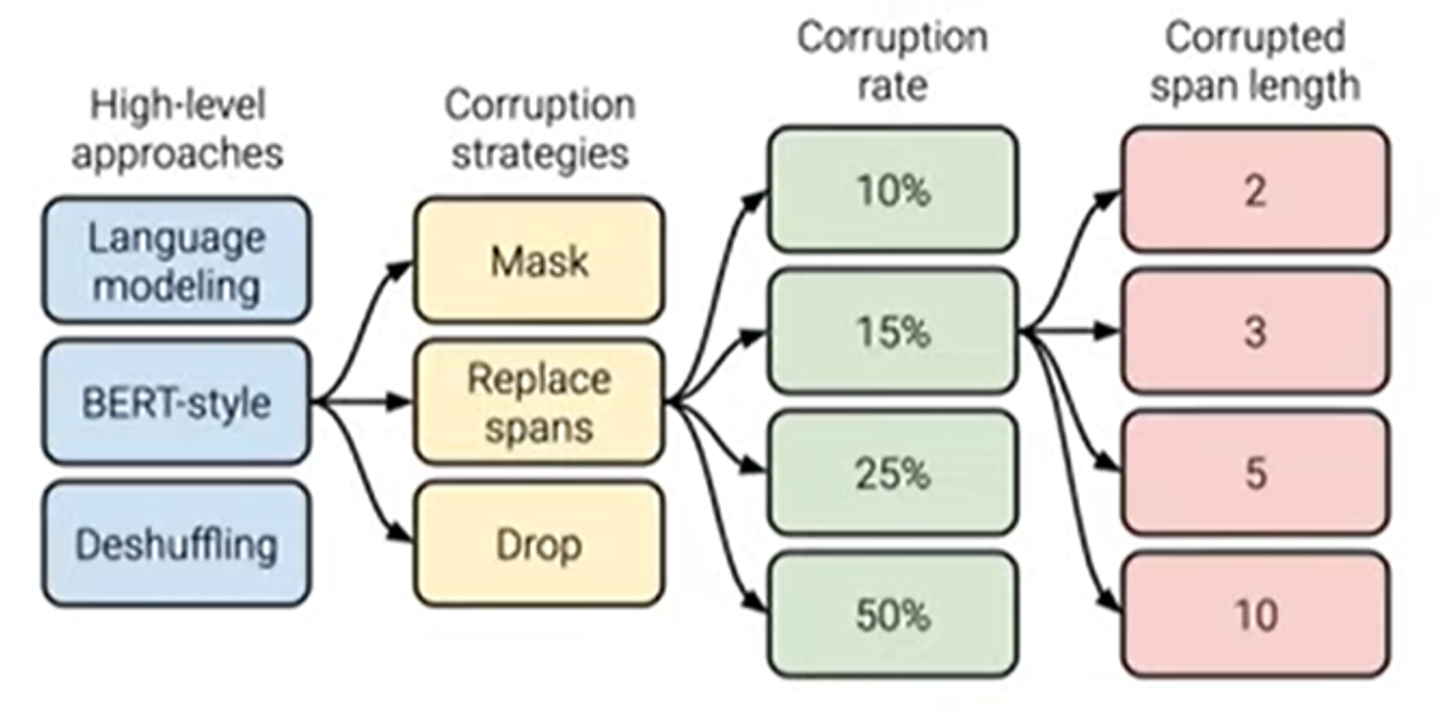
다음으로 결정 해야하는 것은 pre-training objective이다. 다시 말하면 사전 훈련 과정에서 모델이 학습하고자 하는 것을 정해야 한다.
따라서 우리는 high level approach들을 비교할 것이다.
-
language model: 이는 아까 말했던 것처럼 왼쪽에서 오른쪽으로 엄격하게 작용하여 다음 token을 예측하기 위해 모델을 훈련한다.
-
Desuffling: input sentence를 shuffle하고 모델을 훈련하여 unshuffled sentence를 예측한다.
-
BERT-style은 BERT모델이다..
3-1. Mask : 전체의 원래 uncorrupted input sentence를 예측한다.
3-2 Replace Span : 아까 말했던 그 masked 모델이다.
3-3 Drop : mask token을 drop하고 이 drop token을 예측하기 위해서 모델을 훈련한다.

성능은 다음과 같다.
위의 두 개는 전체 input sequence를 예측하는 것도 포함이지만, 마지막 두 개는 masked out token만 예측하기 때문에 target sentence가 더 짧아서 overall cost가 상대적으로 낮다.
T5에서는 마지막 두 개는 best approach로 결정하고, masking strategy에서 다른 하이퍼 파라미터들을 고려한다. ( 얼마나 많은 token들을 mask할지 등 )
variants of pre-training dataset
다음으로는 pre-training dataset을 어떻게 사용 할지에 대한 실험이다.
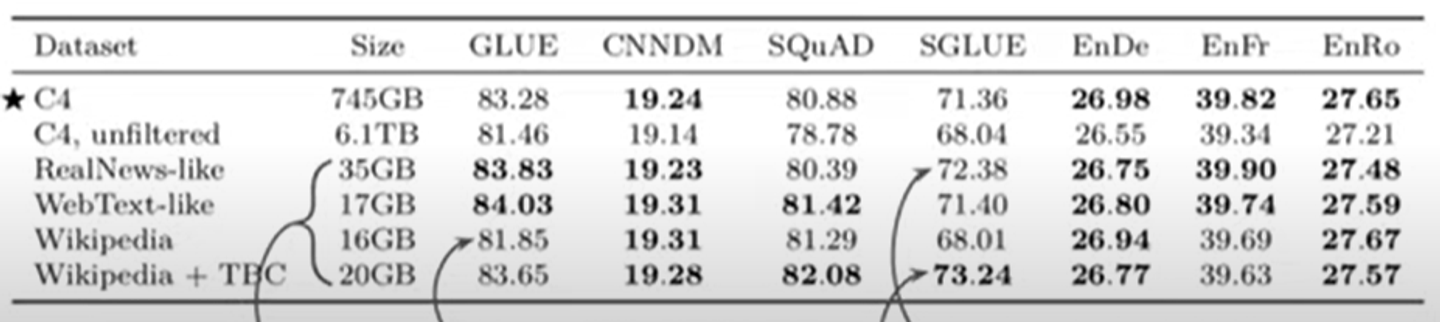
wikipedia+ TBC가 SuperGLUE에서 가장 좋은 성능을 보였다.
SuperGLUE는 multi RC라고 불리는 task를 포함하는데 이는 reading comprehension task이다.
하고자 하는 downstream task와 비슷한 data를 pretrain하면 성능이 매우 좋아진다.
wikipedia만을 사용하는 것은 C4보다도 안좋은 성능을 보였다. wikipedia는 very little unacceptable text이기 때문이다.
또한 위의 2개보다 아래 4개가 상대적으로 데이터의 양이 작지만 그렇게 큰 performance를 희생하지 않은 것을 알 수 있다.
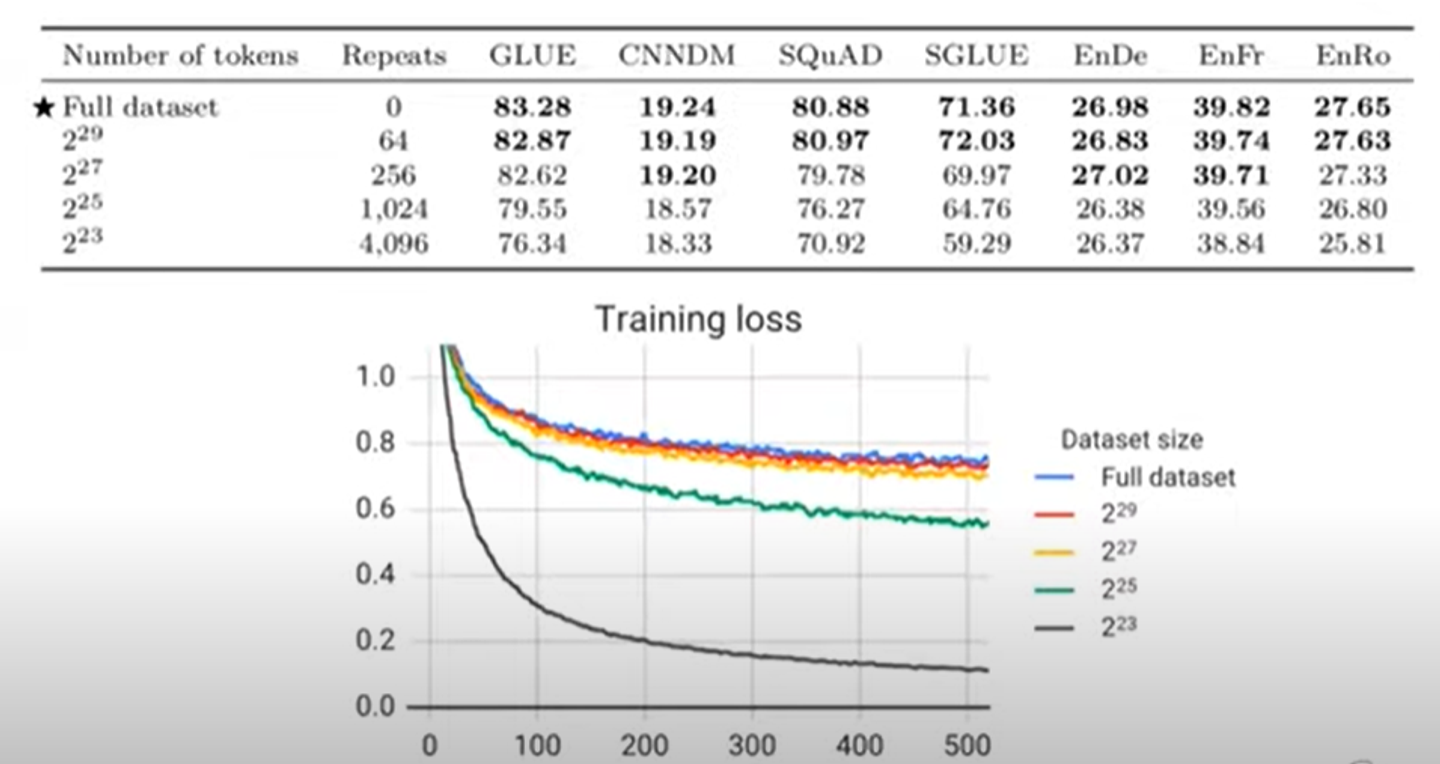
위의 표와 그래프는 데이터의 양에 따른 training loss와 정확도를 나타낸 것이다.
반복 횟수에 따라서 데이터의 총 양이 늘어난다.
2의 27제곱의 양까지는 원래 데이터와의 loss차이가 별로 크지 않다.
하지만 그 이후에는 degradation을 볼 수 있다.
따라서 당신의 데이터셋은 pre-training을 할때 오버피팅이발생하지 않을 정도로 커야하고, 나중에 model을 scale up하고, 더 많은 데이터로 pre-train해야할 때, we would do enough repeats of the smaller sort of more domain.
multi-task pretraining
multi-task learning을 할때, multi task에 대하여 model training을 한번에 진행한다.
즉, 모든 downstream task를 같이 훈련을 진행하는 것이다.
따라서 여기에서 파생되는 문제는 각각의 task에 데이터를 어떻게 배정해야하는 것이다.
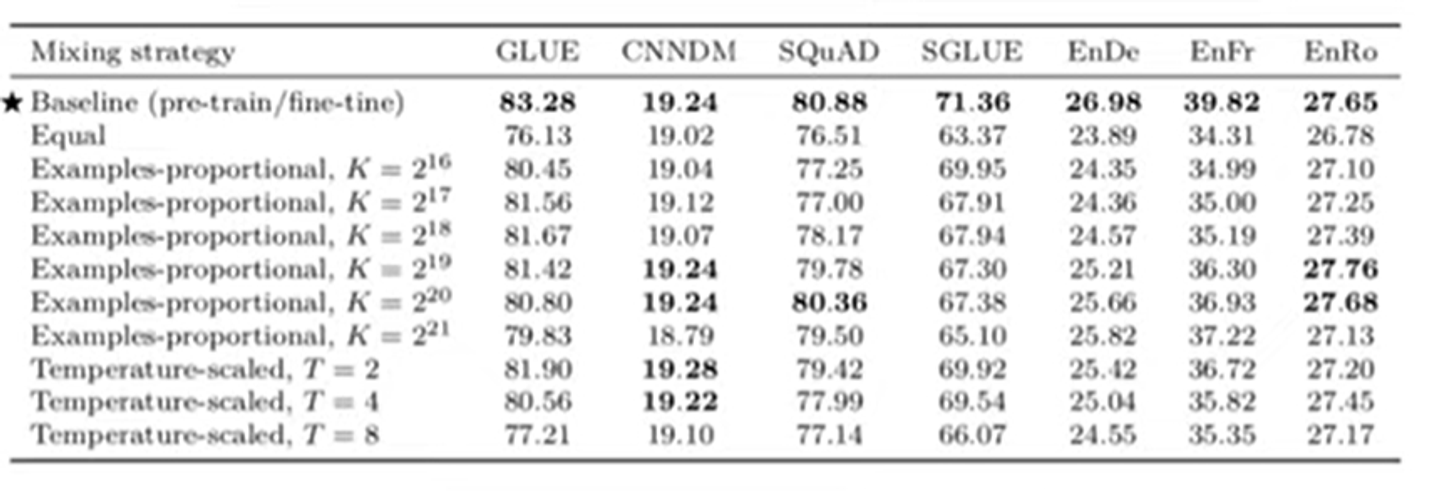
첫번째 방법은 모든 task에 동일한 비율로 sample하는 것이다.
두번째는 example proportional mixing방법이다.
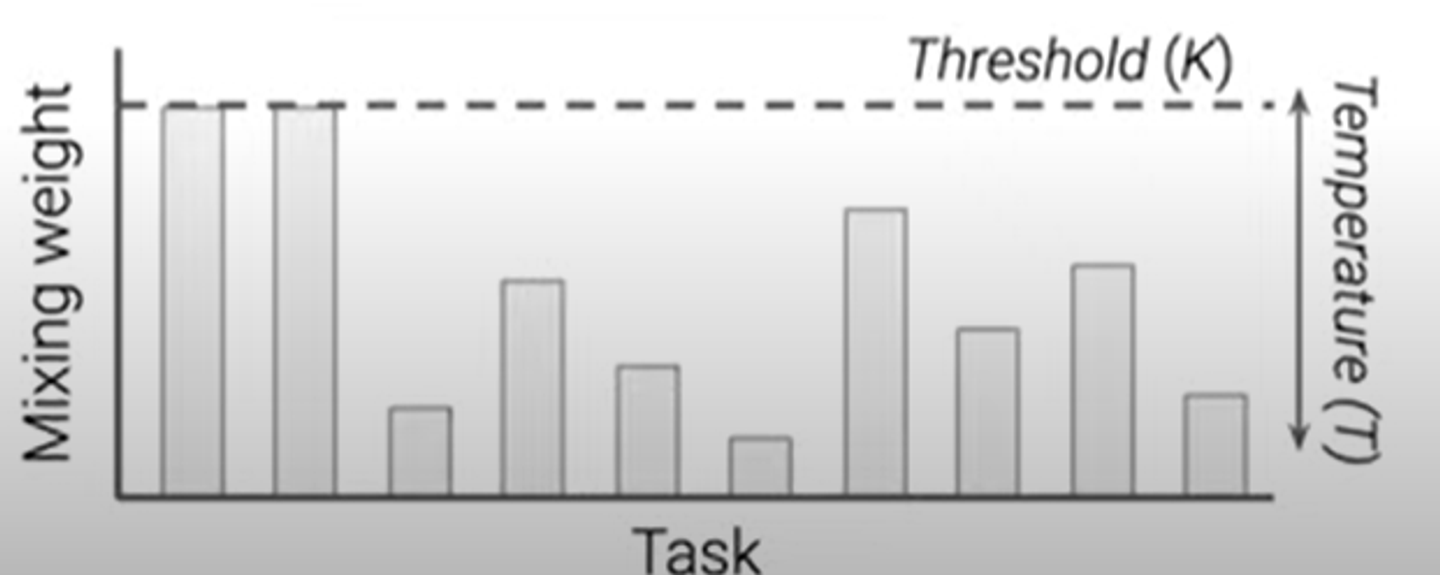
하이퍼파라미터 k를 정해서 최대로 가질 수 있는 데이터셋의 개수를 정한다.
그리고 각 데이터셋의 개수를 temperature(T)로 scale한다.
temperature가 클수록 equal mixing에 가까워진다.
표의 결과를 보면, mixing strategy만 잘해서 분리하면 pre-train하는 것과 비슷한 성능을 가진다.

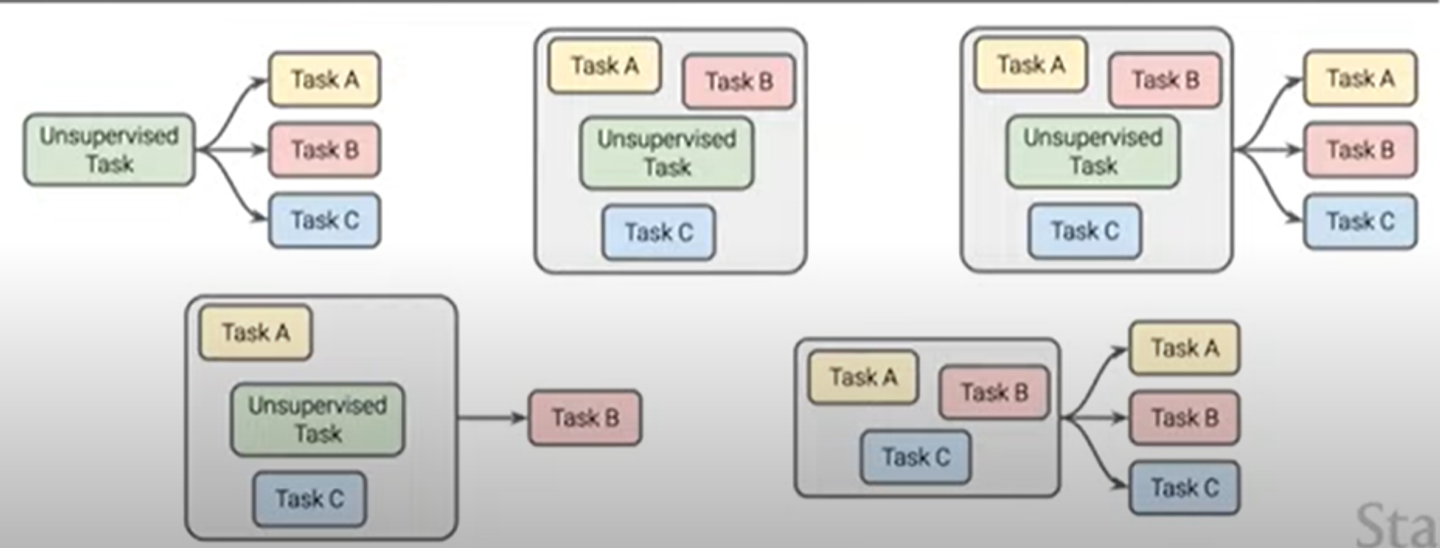
다음은 multi-task training 방법들을 다르게 하여 실험한 것이다.
이는 multi-task training과 분리된 fine tuning을 하여 pre-training하는 모델 사이의 차이를 줄이기 위한 방법이 있는지 보기 위한 실험이다.
여러가지 방법들이 있다. strictly multi tasking, doing multi-task training followed by individual task finetuning, multi-tasking without unsupervised data.. 등등
이 모든 실험에서 알아야 하는 것은 unsupervised task를 포함해서 multi-task를 먼저 한 다음에 각 task에 따라 fine tuning을 각각하는 것도 성능에 큰 악영향을 미치지 않는다.
이 방법을 하면 좋은 점은 각각의 task의 성능에 대해서 모니터링 할 수 있다는 점이다. (pre-training하면서)
scaling strategy(모델을 크게 만들기 위한 방법)
만약에 연산을 크기를 갑자기 늘려야한다면 우리는 아래 표에 나와있는 여러 방법들을 생각해볼 수 있다.
예시로 4배의 연산을 가중시켰다고 하자.
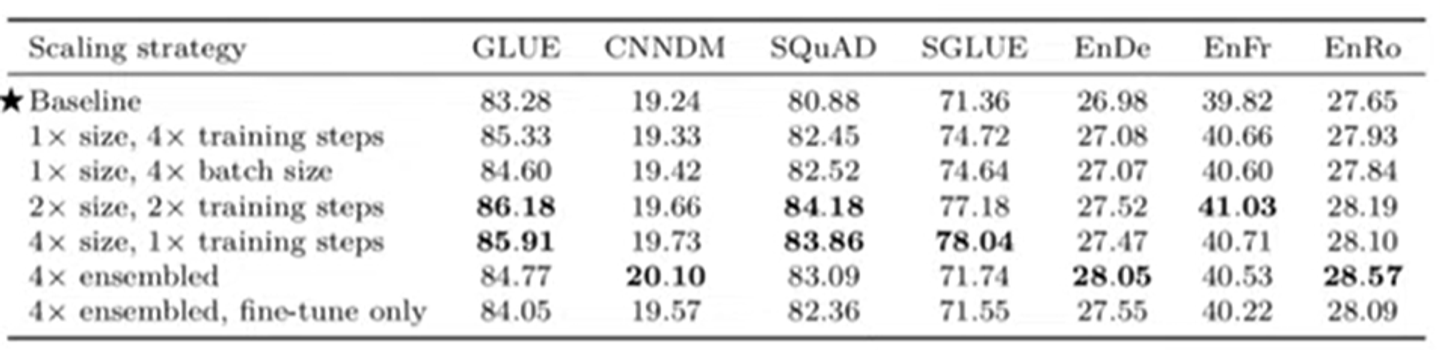
그냥 단순히 training 사이즈를 늘리는 것만이 좋은 것이 아니다. 여러 수단이 있다.
모델의 사이즈를 2배로, taining 사이즈를 2배로 늘리는 것이 가장 성능이 좋다.
Results
지금까지 결정한 것들에 대해서 정리해보자.
- 우리는 Encoder-Decoder architecture을 사용한다. text-to-text format에 최적이기 때문
- 우리는 span prediction objective을 택한다. 처음에 보여주었던 baseline과 같음.
- 우리는 C4 dataset을 이용. 가장 성능이 좋았다. 과적합되지 않을만큼의 충분한 양또한 가짐
- 우리는 multi-task pretraining을 진행한다. 그 이후에 fine tuning 진행
- 우리는 scaling strategy로 큰 모델을 사용한다.
영어가 아닌 경우 어떻게 작동할까? (mT5)
T5는 영어 모델이다.
다른 언어에 대해 지원하는 모델을 multilingual T5라고 부른다.
이것은 다른 부분은 모두 같지만 multilingual corpus로 train한다는 것이 다르다.
C4 dataset에 여러 다른 언어들이 포함된 것을 사용한다.
이 데이터셋은 27TB정도의 사이즈를 갖는다.
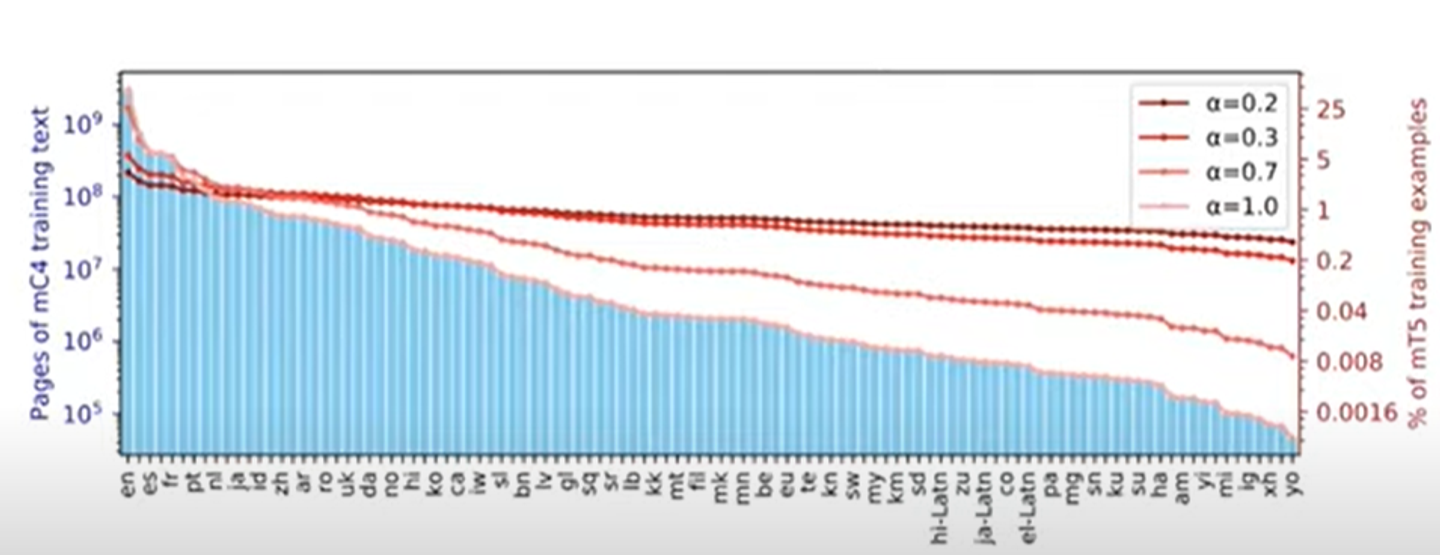
하지만 각 언어별로 텍스트의 양이 다르다.
따라서 앞에서 봤던 temperature scaling을 사용한다.
여기서는 temperature이 작으면 작을수록 uniform distribution에 가까워진다.
temperature이 작으면 low resource language에서 성능이 좋고, temperature이 크면 반대로 작용한다.
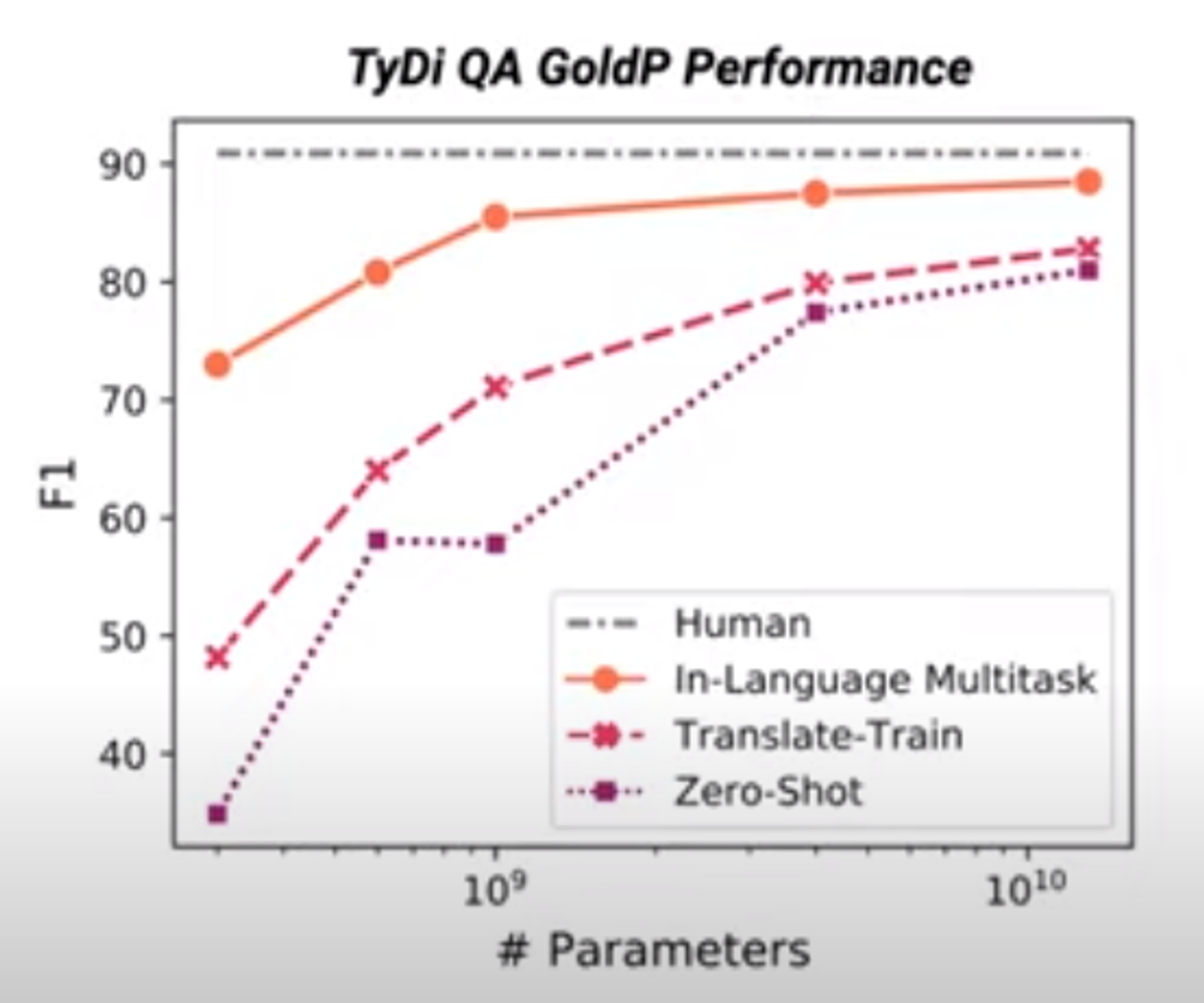
이 그래프에 대해서 간단히 말하자면 더 많은 양의 파라미터를 사용할 수록 더 넣은 언어 분포를 학습할 수 있다는 것이다.
언어 모델이 사전 훈련 동안 얼마나 많은 지식을 습득하나요?(closed-book question)
question answering task에는 reading comprehension이나 open-domain이 있는데,
T5모델에서는 closed book question을 제안한다.
이것은 외부 지식 source와 연결할 수 없고, 모델이 가지고 있는 지식을 베이스로 답을 해야한다.
모델은 pre-train할때 쌓은 지식들 안에서 답을 골라야한다.
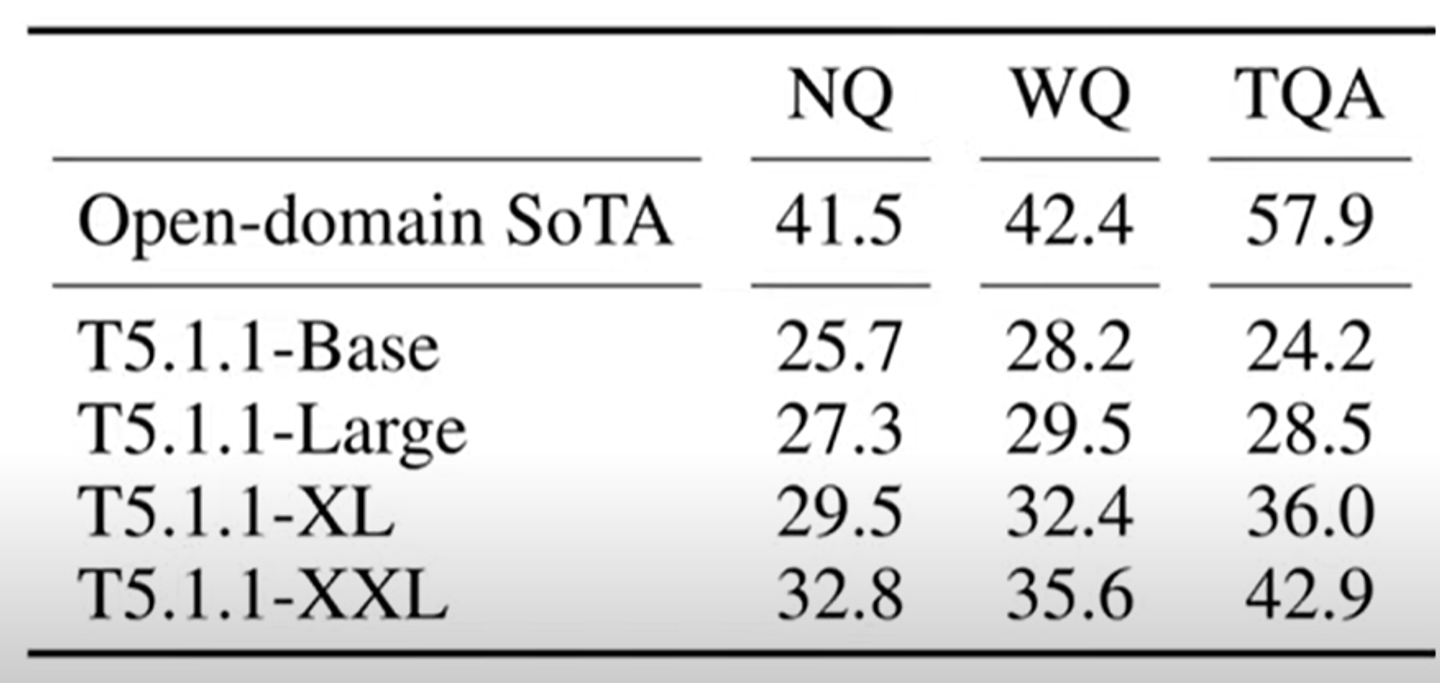
모델의 크가 클수록 더 많은 지식들은 pick up한다.
open-domain과 성능차이가 있긴 함.
이를 줄이기 위해서 “Retrieval augmented language model pre-training”을 진행한다.
이는 mask를 랜덤하게 하는 것이 아니라, 사람이름, 장소, 날짜 등의 entities를 mask하는 것이다.
언어 모델이 traingin data를 기억하나요?
얼마나 많은 양의 지식들이 모델에 기억되어지는가?
개인정보나 이름같은 기억되지 않고 싶은 정보까지 기억되는가?
그렇다. 가 아마 대답인 듯하다.
GPT2로 하나의 예시를 들면 이상한 prefic를 넣었을 때, 실제 이름과 주소를 알려주었다고 한다( 인터넷에 나타나는). 하지만 이는 6번정도밖에 발생하지 않음.
이 예시는 GPT2가 pre-training dataset에서 어느 정도 사소하지 않은 양의 정보들을 기억하고 있는 것처럼 보인다.
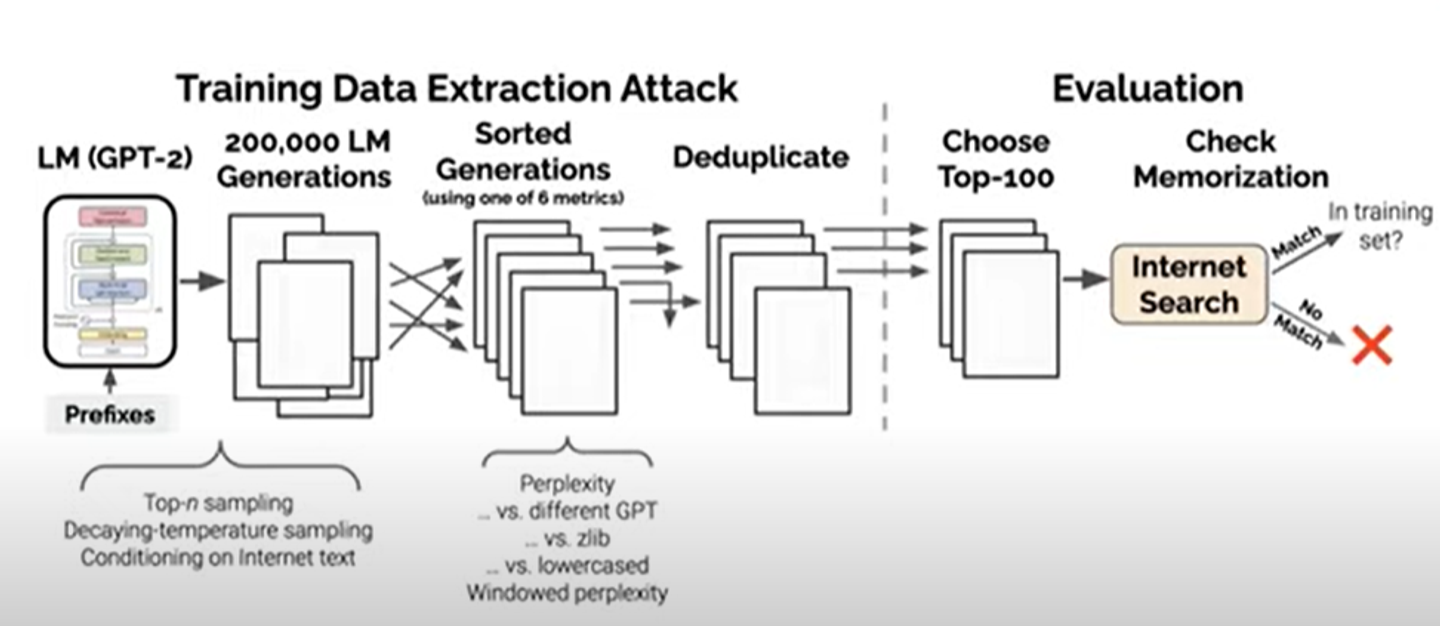
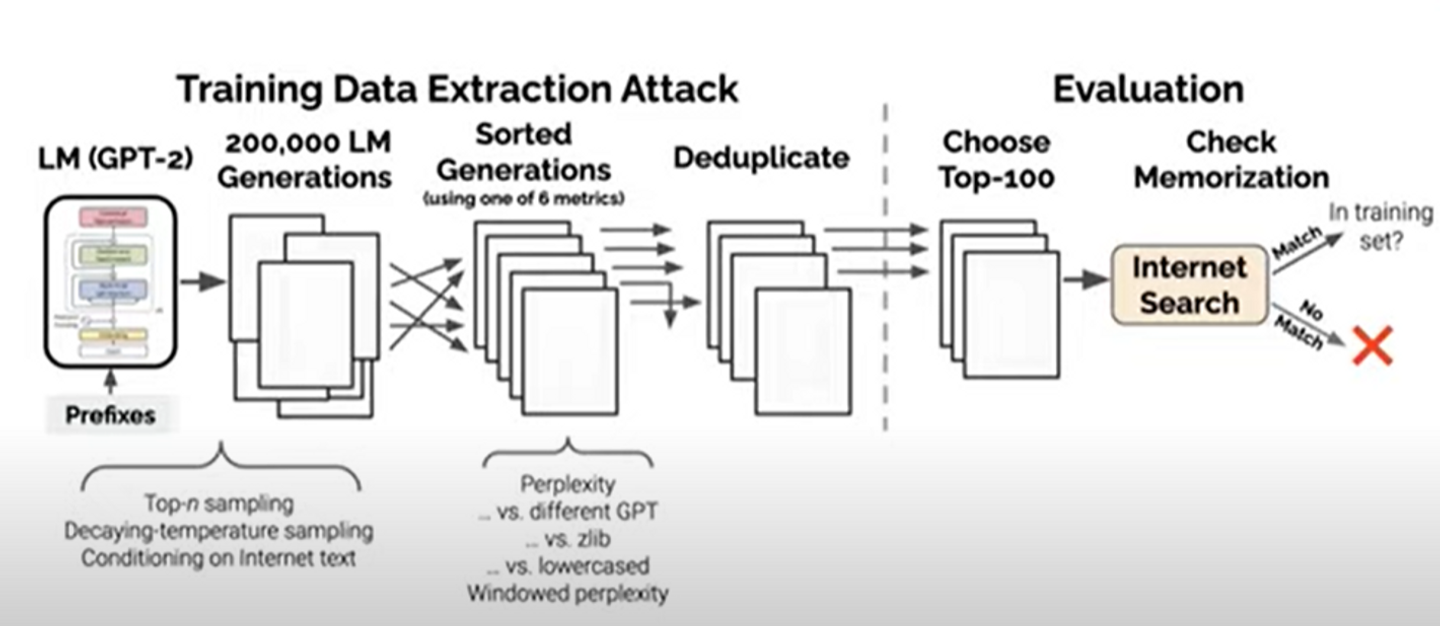
이 과정을 구체화 하면 다음과 같다.
- language model에서 data를 sampling한다. 세가지 방법이 있다.
- sample auto -regressively
- sample auto -regressively but with decay in temperature(model을 더 confident하게 만들겠다)
- take random text from the internet and use that as conditioning to GPT-2 before asking it to generate whar comes next
1번 과정을 통해 200,000의 generation을 얻는다.
- 이제 우리는 이 것을 기억할지 안할지를 예측하기 위한 방법을 원한다. 여기에 6가지 metrics중에 하나를 사용하면 된다. 이 메트릭스는 모두 기본적으로 GPT-2의 perplexity가 사용된다.
perplexity는 GPT-2의confident를 측정하기 위한 것이다. compression의 측도라고 생각가능.
여러가지 방법들을 설명하심 .
- GPT-2가 generate한 것에 대하여 perplexity를 계산함
- 다른 variiant of GPT의 perplexity와 비교 / 혹은 zlib 이라고 불리는 text compression library와 비교
- 또는 original text와 lowercase version의 perplexity비교
- small window를 사용할 때의 perplexity비교
- duplicate on the generation
- choose the top 100 generation according to each of these metrics. ultimately gives us 600 possible memorized generation
- basif google search. to see if we can find the text that GPT-2 generated ont he internet somwhere > 인터넷에 있는지 없는지 체크한다. 그리고 gpt가 training dataset에 있는 것을 뱉었는지 확인한다.
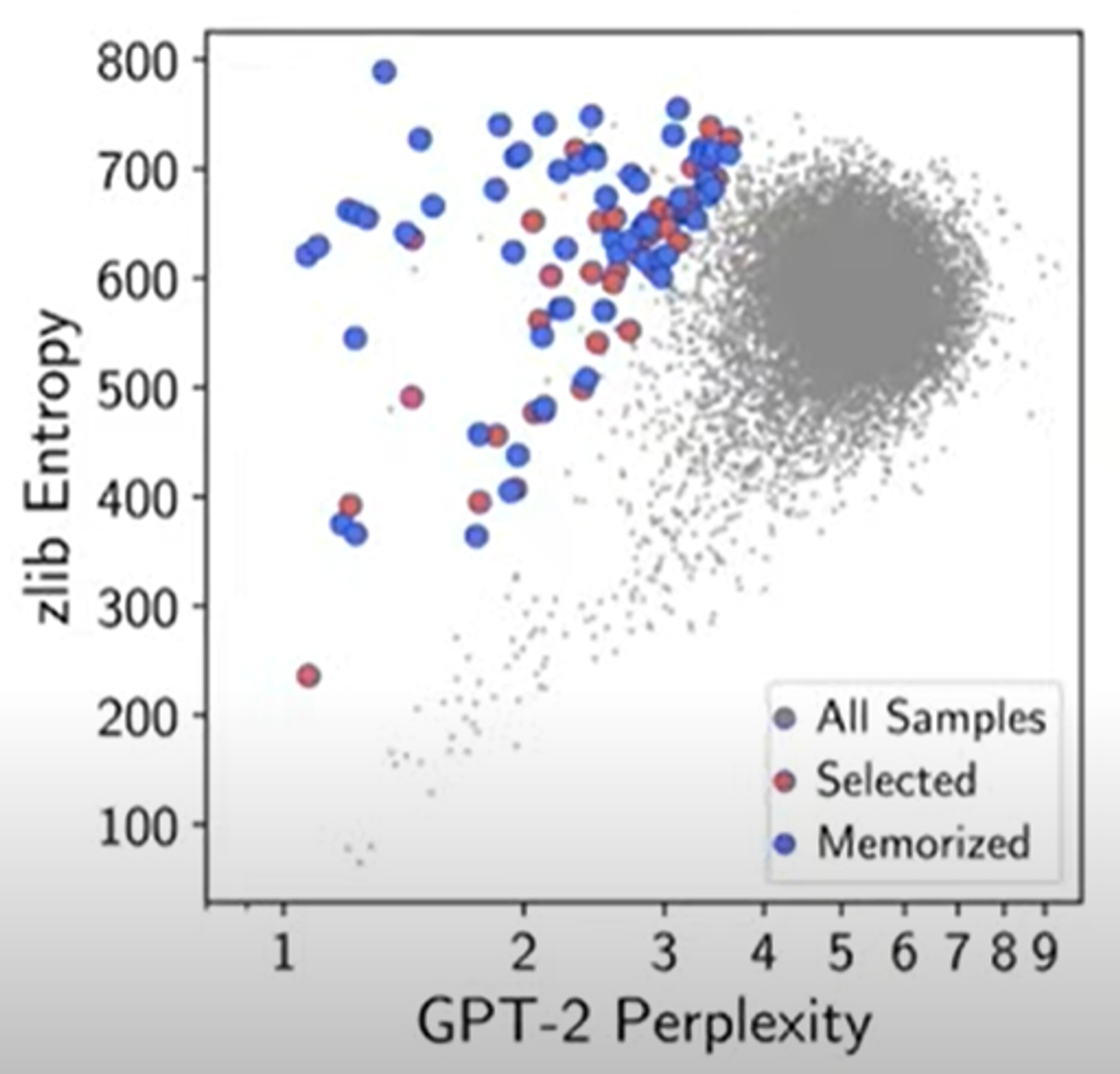
위의 그래프 분포를 통해서 GPT-2가 다음에 무엇이 올지 예측하는 것을 굉장히 잘 할 수 있음을 보여준다. 왜냐하면 GPT는 outliens같은 정보도 기억을 하기 때문이다.
왼쪽 상단의 점들은 possible memorized samples이다.
파란점은 실제로 training data에 있었고, gpt가 기억했던 ㄳ이다.
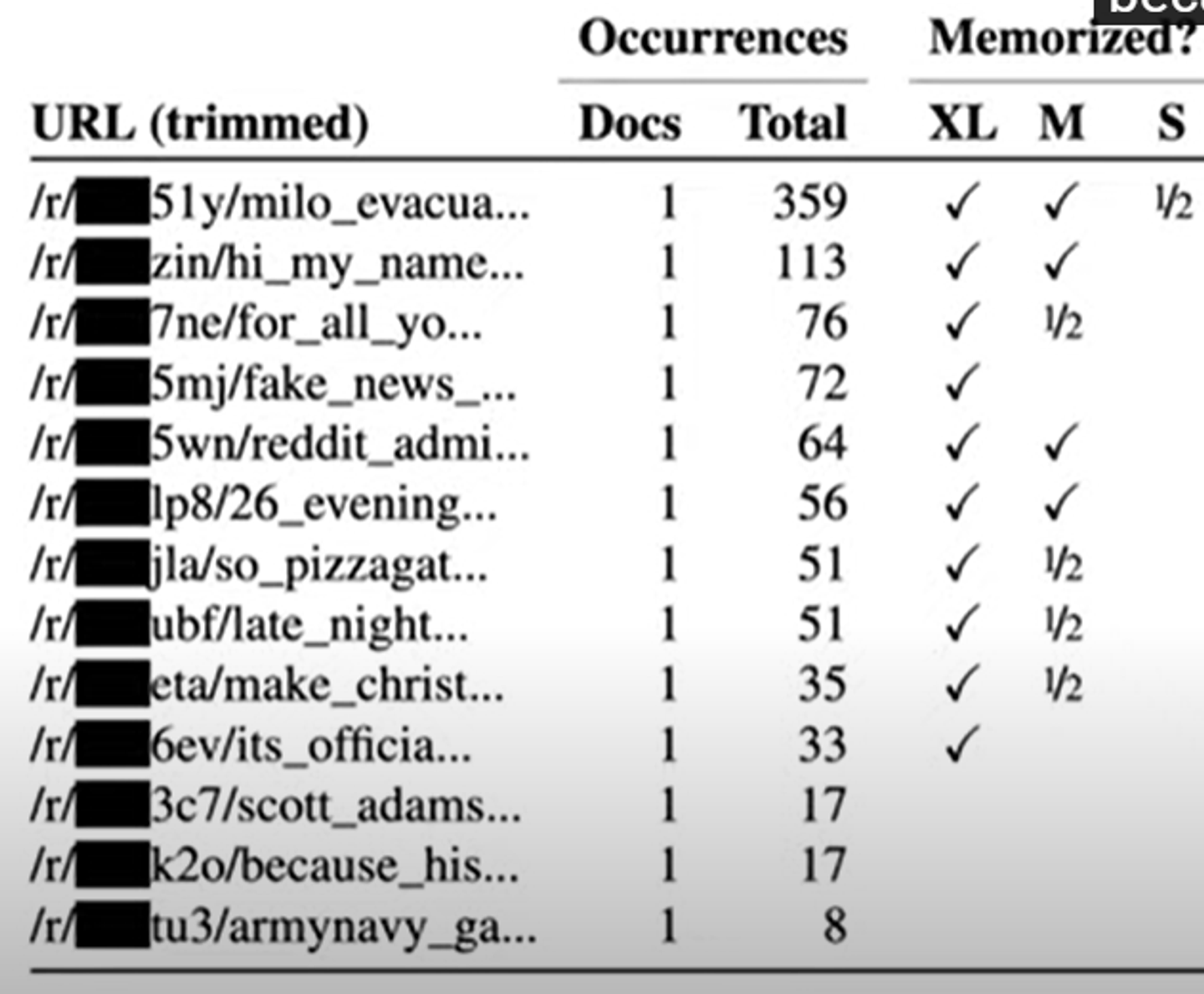
모델의 사이즈가 클수록 가장 빈도수가 낮은 것까지 예측하는 것을 볼 수 있다.
즉 모델이 클 수록 기억하는 데이터의 양이 많은 것이다.
데이터의 양이 큰 모델과 작은 모델사이의 성능 차이를 줄일 수 있나요?