
What is NLG
natural language generation 테스크는 기본적으로 텍스트를 생성하는 것으로 대표적으로는
- summarization
- machine translation
- dialogue system
- data- to - generation
- visual description
등이 있다.
basic NLG
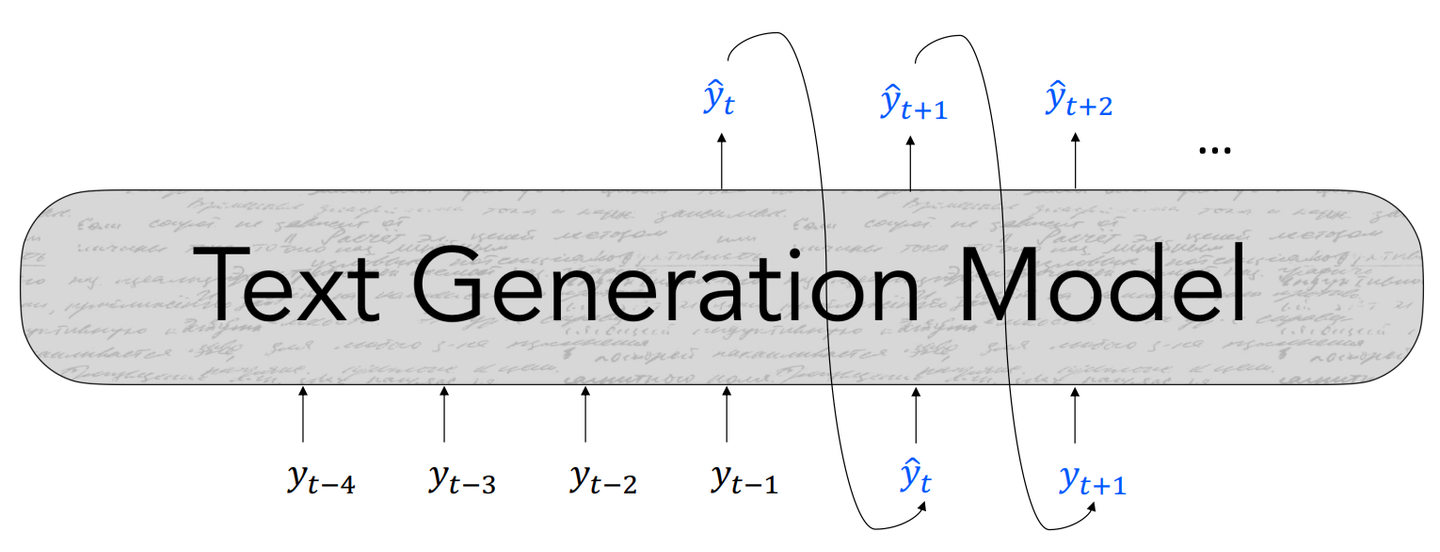
기본적인 텍스트 생성 구조는 다음과 같다.
autoregressive의 형태로써, 모델은 이전까지의 단어 (t시점 이전의 단어)를 입력으로 다음 스템의 단어를 생성한다.
학습 시에는 예측된 토큰과 실제 토큰을 사용한 negative loglikelihood를 minimize하는 방식을 사용한다.
teacher forcing
학습 시 모델이 예측한 토큰이 아닌 실제 문장의 토큰을 다음 단어 생성을 위한 입력으로 사용하는 것이다.
초기에 잘못 생성된 단어로 인해 이 후 계속 잘못된 단어가 생성되는 것을 막아준다.
학습된 모델을 사용하여 decoding 시에는 예측된 단어를 다음 단어 예측을 위한 입력으로 사용한다.
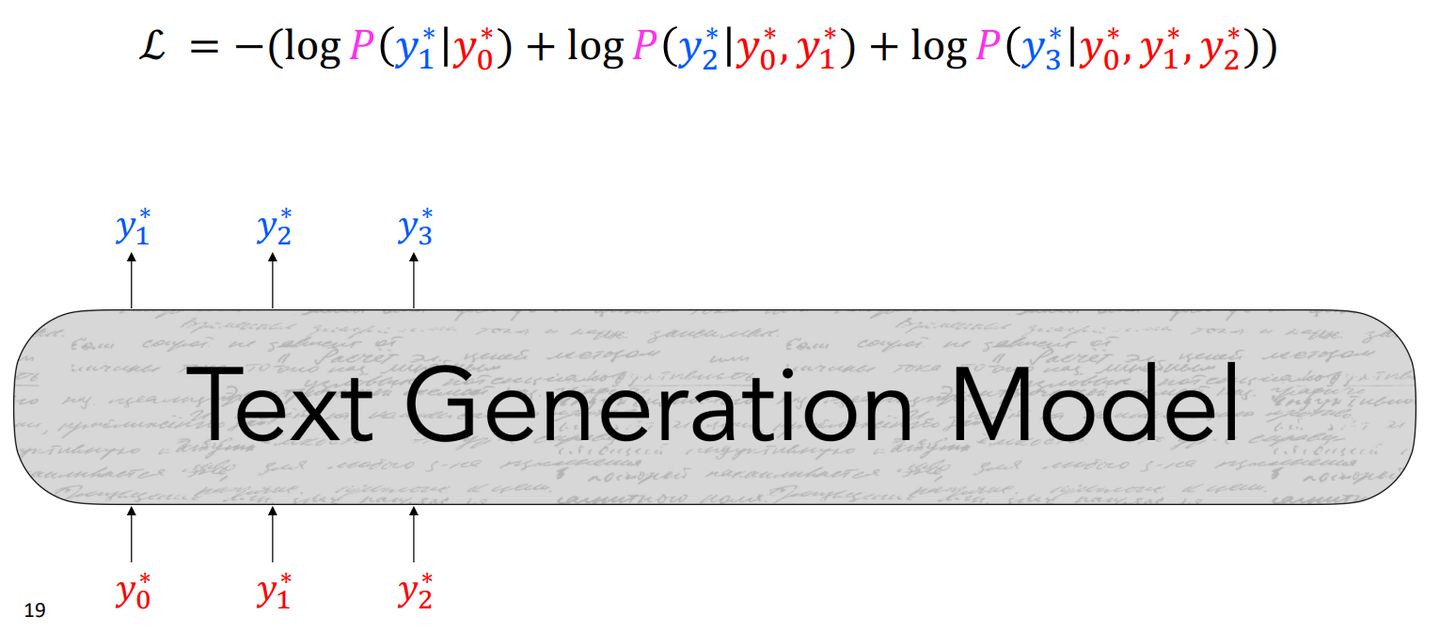
Decoding
greedy methods
1. argmax decoding
매 스텝마다 vocab 내의 단어 중 probability 가 최대가 되는 단어를 선택하는 것 .

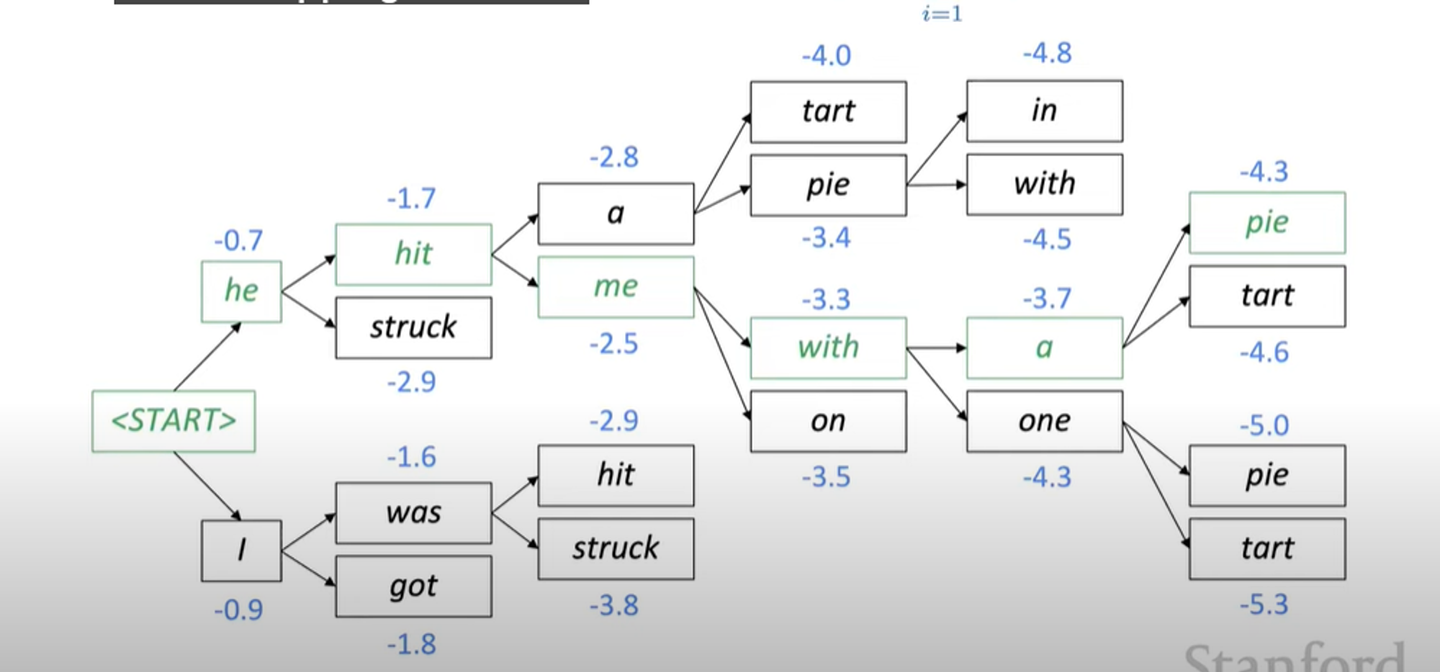
2. Beam Search
argmax 보다 더 많은 후보들 중에서 고를 수 있도록 설정
아래 예시는 k=2가 인 경우.
하지만 이와 같은 greedy methods는 근본적인 문제점을 가지고 있다.
작은 스텝별로 봤을때는 최적의 선택이지만 전체적인 맥락에서 봤을때는 부자연 스러운 문장을 생성해 내는 것이다.

그럼 어떻게 해결해야 하나?
- decoding 단계에서 n-grams의 반복을 막는다.
- decoding 알고리즘을 변경한다.
- random sampling
- top k-sampling
- +scaling randomness Temperature
- re-balancing distributions
- 연속된 문장의 hidden representation similarity를 낮추는 방식 → 문장 내 반복은 막을 수 없음
- 동일한 단어가 등장하는 것을 막는 attention mechanism : converage loss
- 이미 등장한 토큰에 패널티 부여 : unlikelihood objective
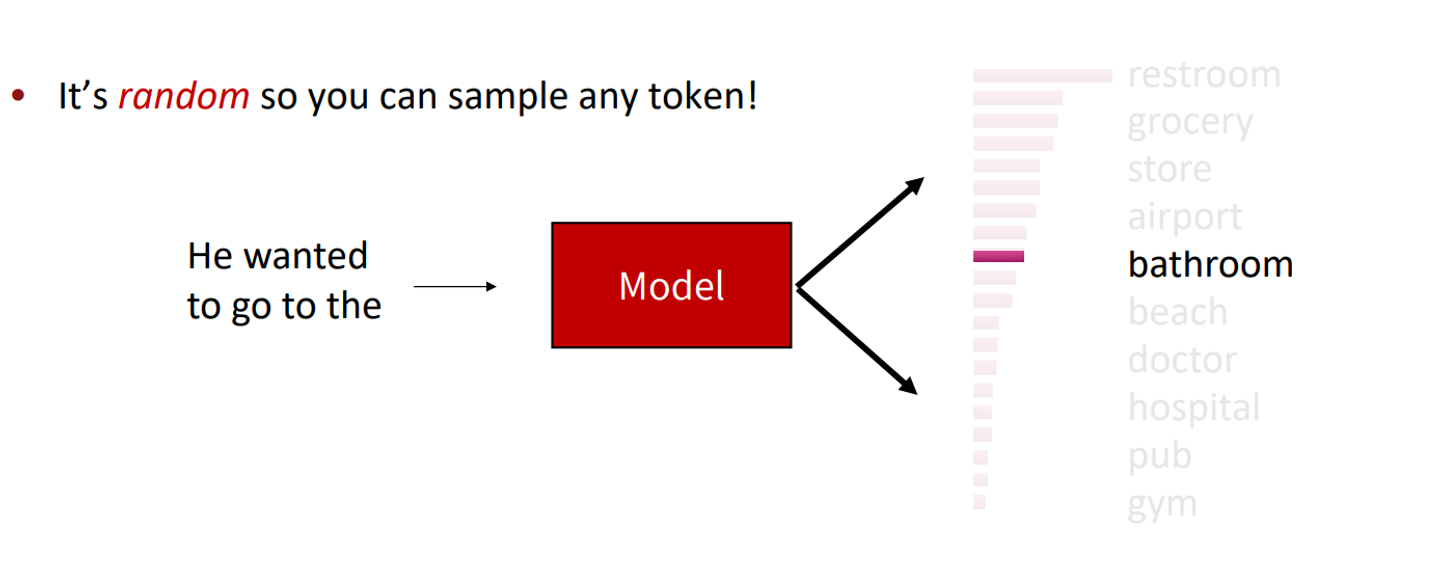
random sampling
모델이 예측한 token distribution을 sampling에 사용한다.
가중치가 0 이 아닌이상, 어떤 단어든 선택될 수 있다.
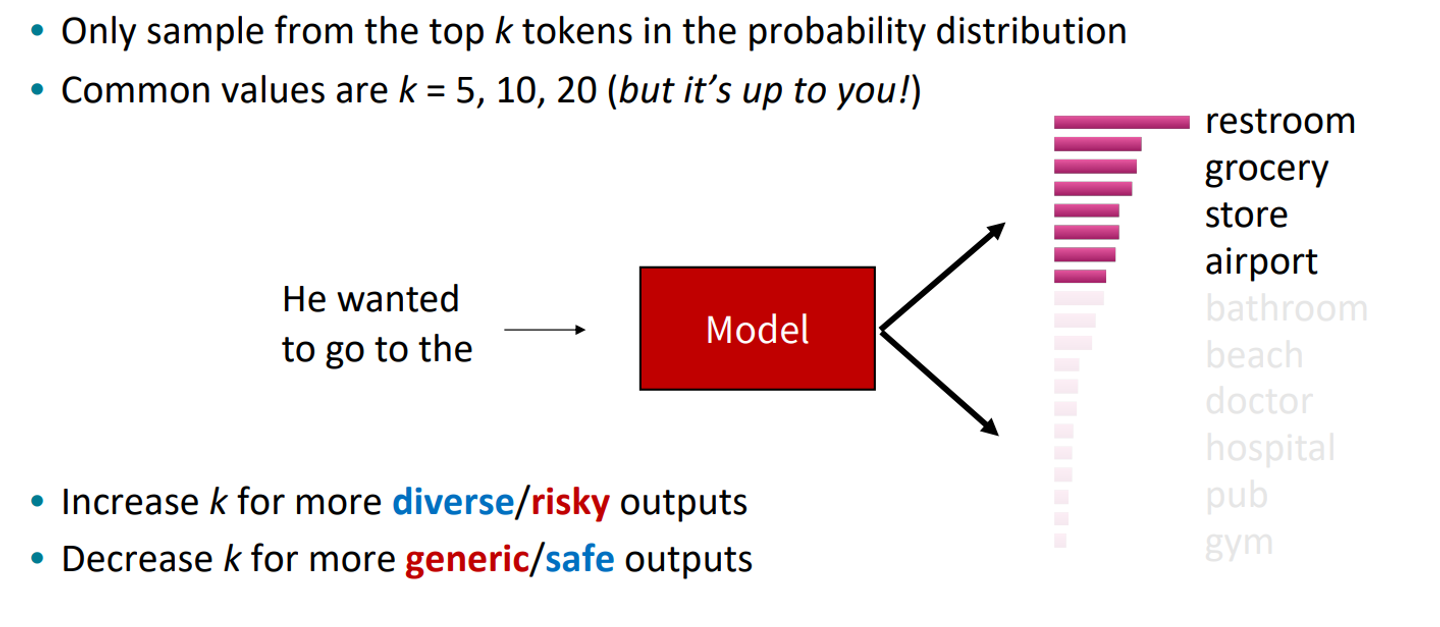
top k-sampling
랜덤으로 인해 부자연스러운 문장이 생성될 수 있기 떄문에 그중에서 값이 높은 것만 골라서 sampling에 사용. distribution이 가중치로 사용된다는 점에서 beam 과 다름
보통 k는 5,10,20 사용됨.
top p-sampling
누적확률 값이 p보다 작은 상위 토큰들만 샘플링에 사용한다.
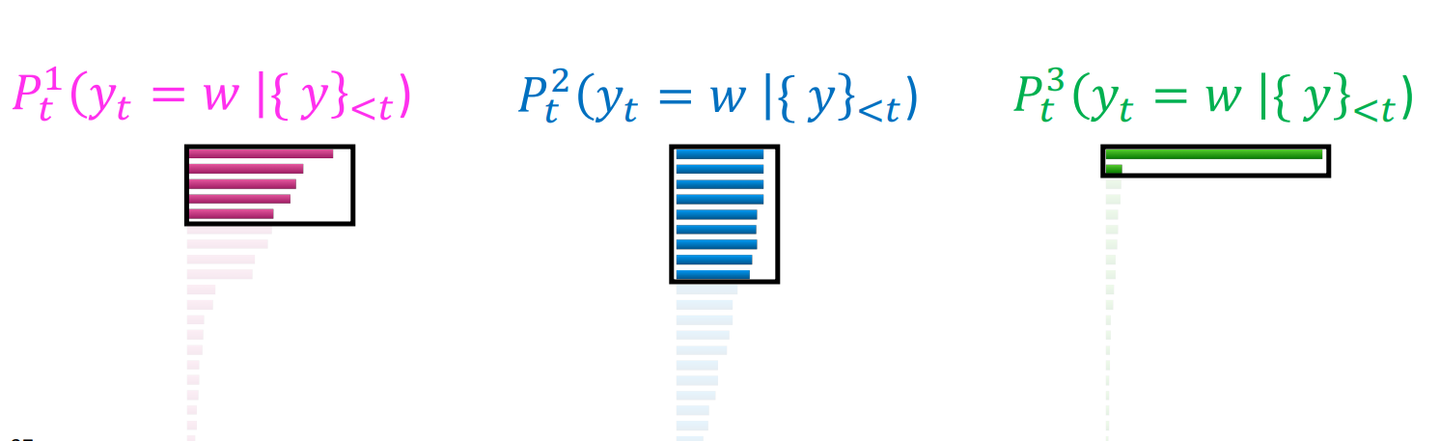
scaling randomness
이 자체가 decoding방식은 아니고, softmax에 들어가기전 처리 방식이다.
logits 값을 상수T로 나누고, softmax의 입력으로 사용한다.
T가 클 수록 vocab내의 확률 값 차이가 작아진다.
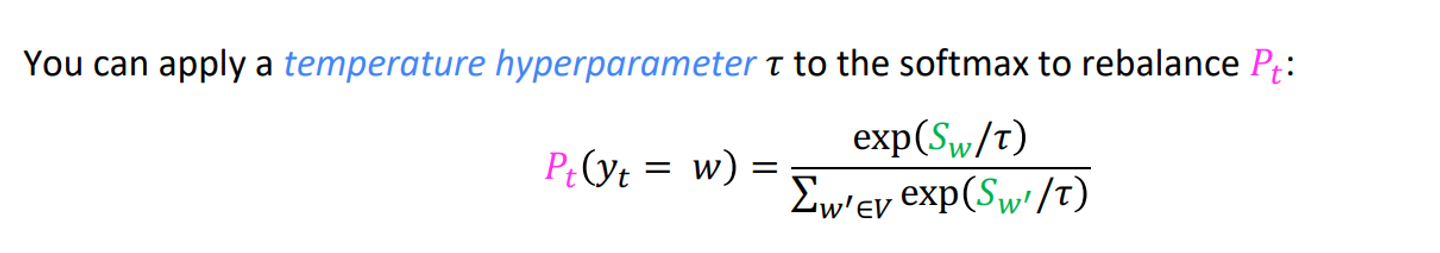
Unlikelihood Traning
이미 생성된 토큰이 생성될 확률을 낮추는 패널티를 기존 loss function에 추가한다.
반복된 단어, 구의 생성을 줄일 수 있다.
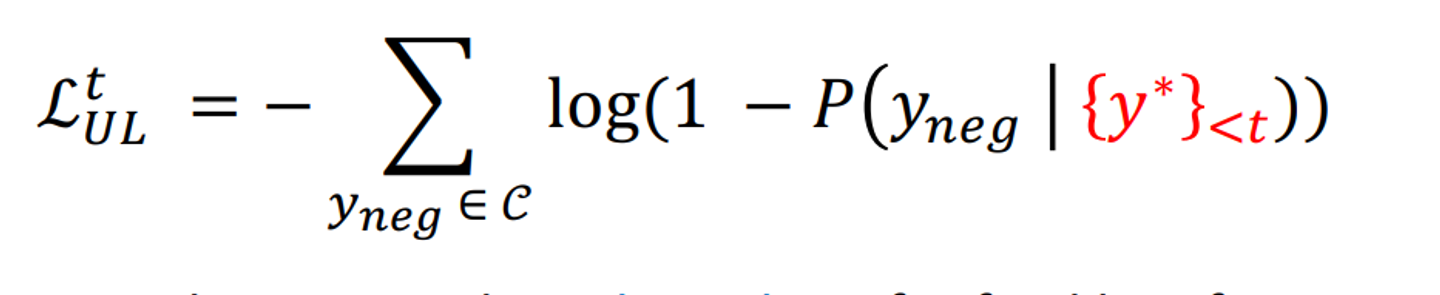
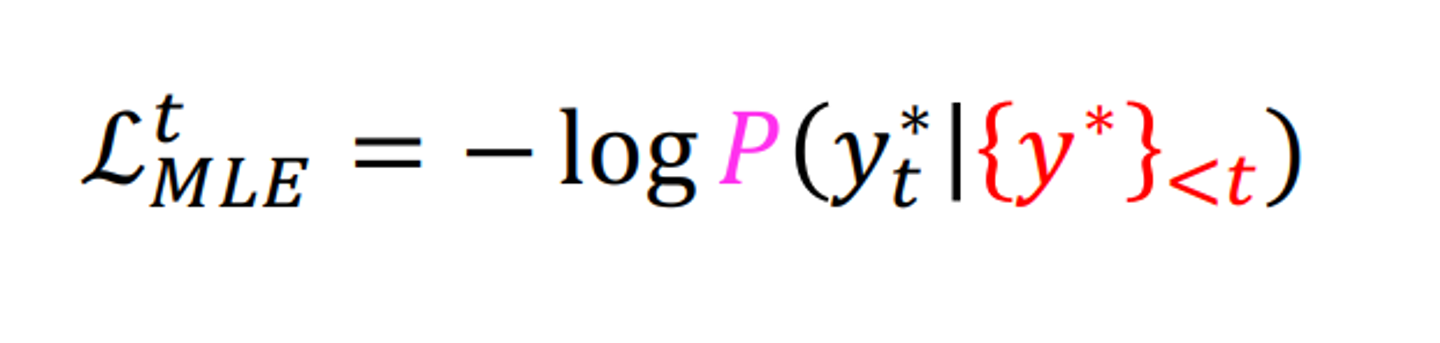
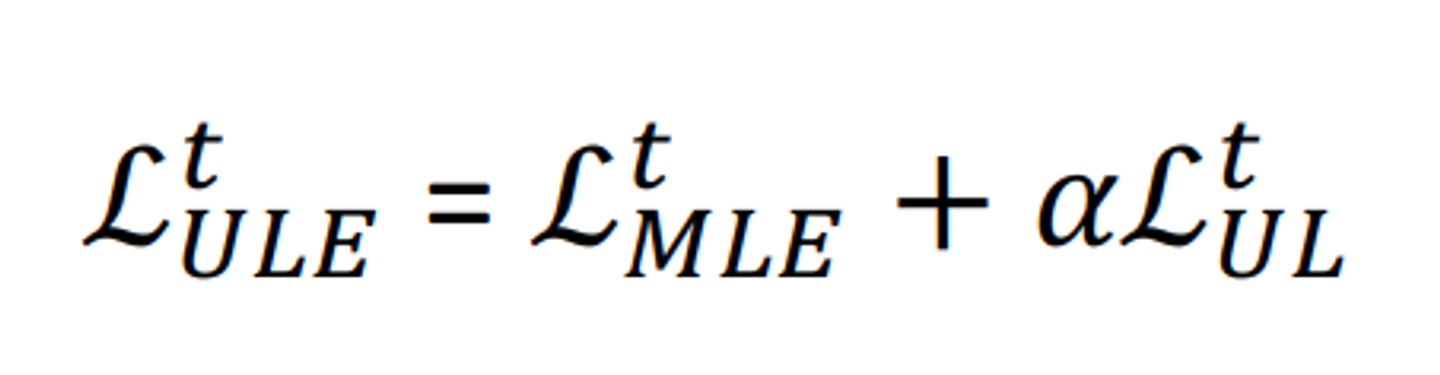
Training
다음은 teacher forcing 방식의 학습을 문제의 원인으로 보는 연구들이다.
학습할때는 teacher forcing으로 정답 텍스트를 보면서 문장을 생성하지만, test decoding시에는 그렇지 않기 때문에, 모델이 불필요한 bias를 학습하게 된다고 본다.(오버피팅)
- scheduled sampling
- dataset aggregation
- sequence re-writing
- reinforcement learning
scheduled sampling
학습시 teacher forcing을 매번 사용하는 것이 아니라, 특정확률로 사용하는 것이다.
teacher forcing을 사용하는 확률값은 학습량이 늘어남에 따라 점점 줄어들게 하여, test 상태와 동일하게 만들도록 한다.
sequence re-writing
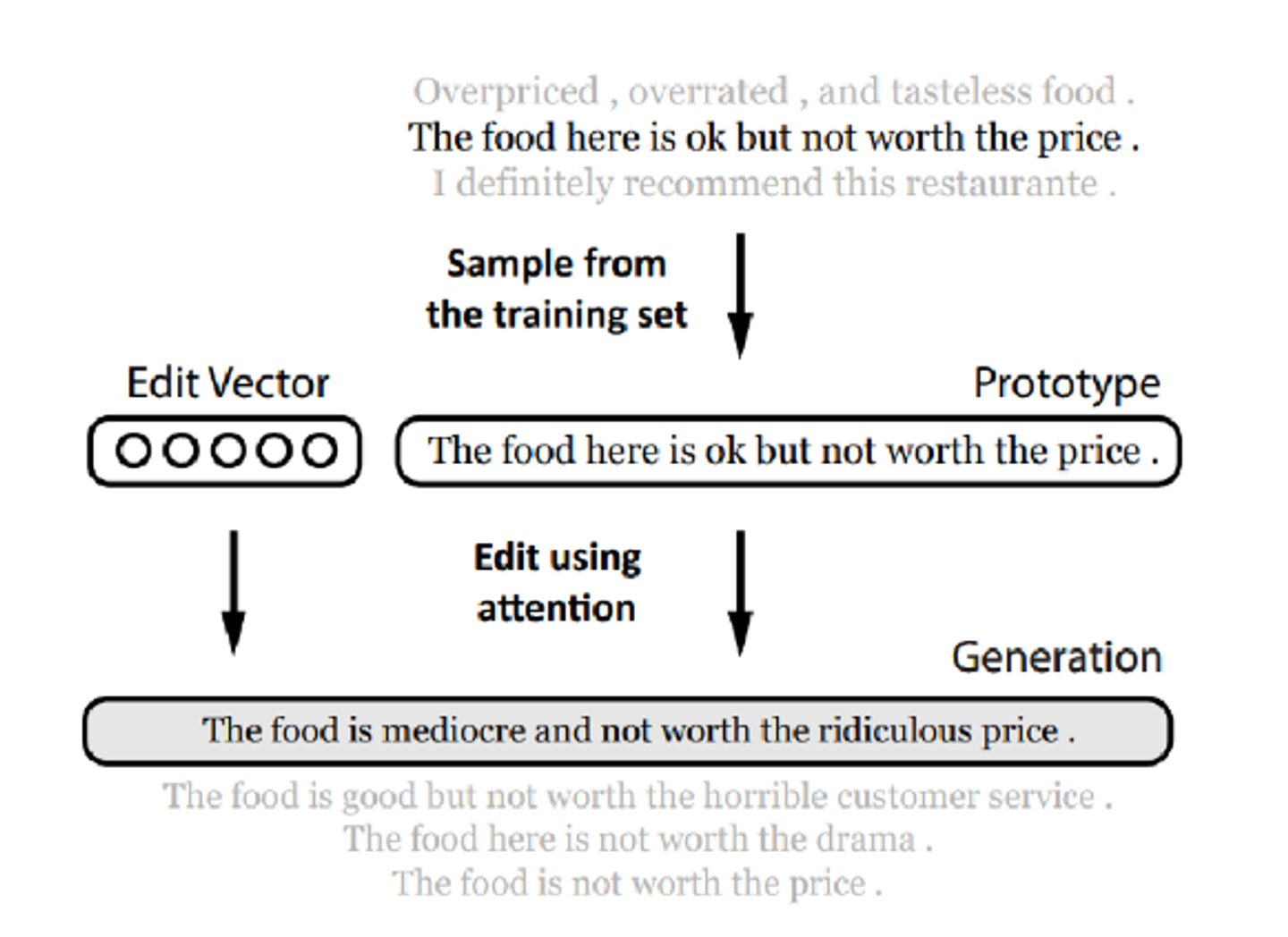
샘플링한 prototype을 edit vector을 사용해 변형한다.
edit vector에는 adding, removing, modifying tokens을 사용한다.
즉, prototype을 참고해서 약간 다른 느낌의 같은 문장을 만들어내는 것으로 blue스코어나 human evaluation 성능은 좋게 나온다고 한다.
reinforcement learning
텍스트 생성에 주로 사용되는 성능평가 지표인 blue score, rouge score등은 학습 과정에서는 사용될 수 없다. 업데이트 되지 않기 때문이다.
따라서, 강화학습을 이용하여 이 성능지표를 바탕으로 학습시킨다.
하지만 reward fucntion을 잘 정의해야한다는 점이 큰 문제로 남아있다.
Evaluating
n-gram overlap metrics : BLEU

실제 문장 대비 짧은 문장을 생성할 경우 패널티를 부여한다.
n-gram precision의 기하평균을 사용한다.
일반적으로 많이 사용된다.
N-gram overlap metrics: ROUGE
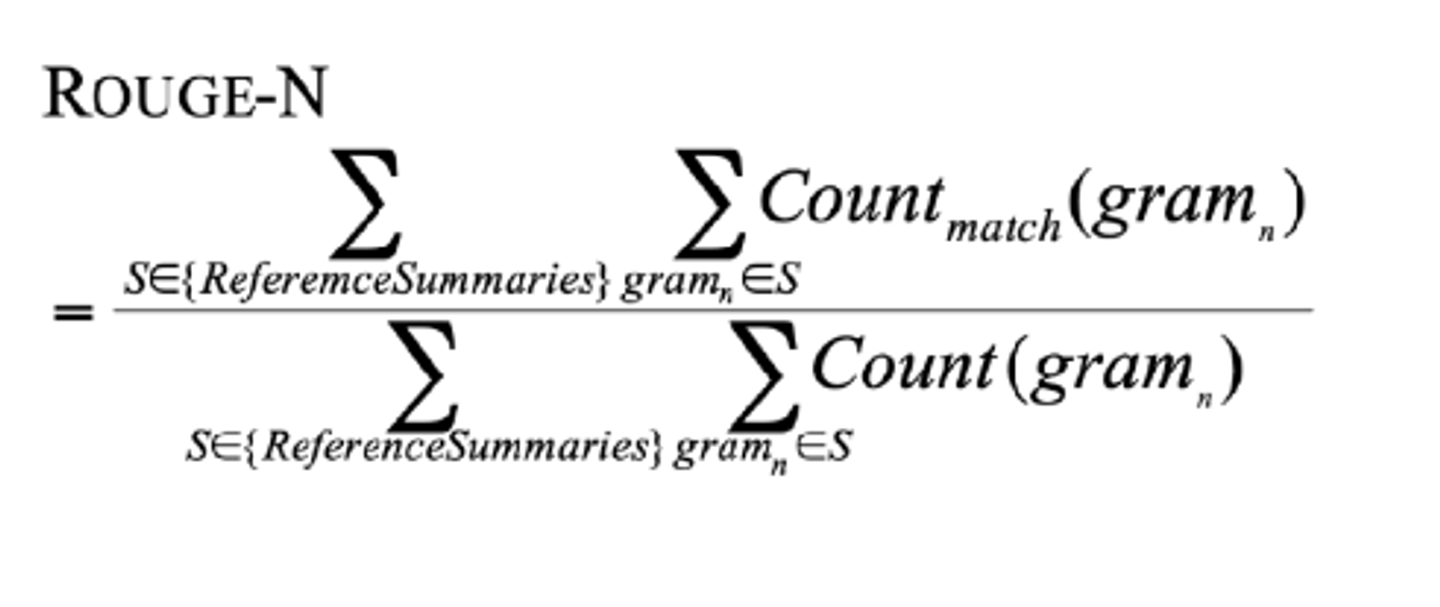
n-gram recall을 사용한다.
brevity penalty가 따로 없다.
blue와 달리 n-gram 별로 따로 비교한다.
하지만 이런 지표들은 단어의 문맥적의미를 반영할 수 없고, 사람의 평가와 상관성이 낮다.
해결방법으로는
word Mover’s distance
생성 text와 reference text의 단어 또는 문장의 semantic similarity 를 계산할 수 있다는 점을 이용한다.
모든 단어의 word2vec embedding을 계산한 뒤, document 1의 모든 단어들의 document 2까지의 최소 거리 합으로 거리를 계산한다.
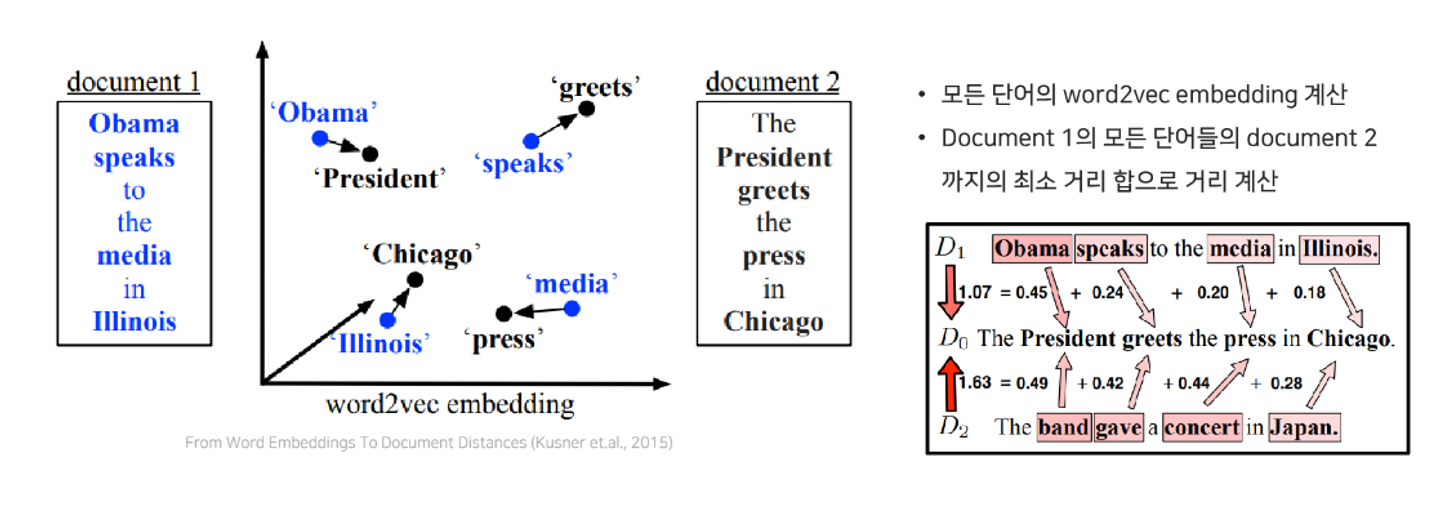
타겟 단어와 겹치는 단어는 하나도 없지만 의미적으로 유사함.
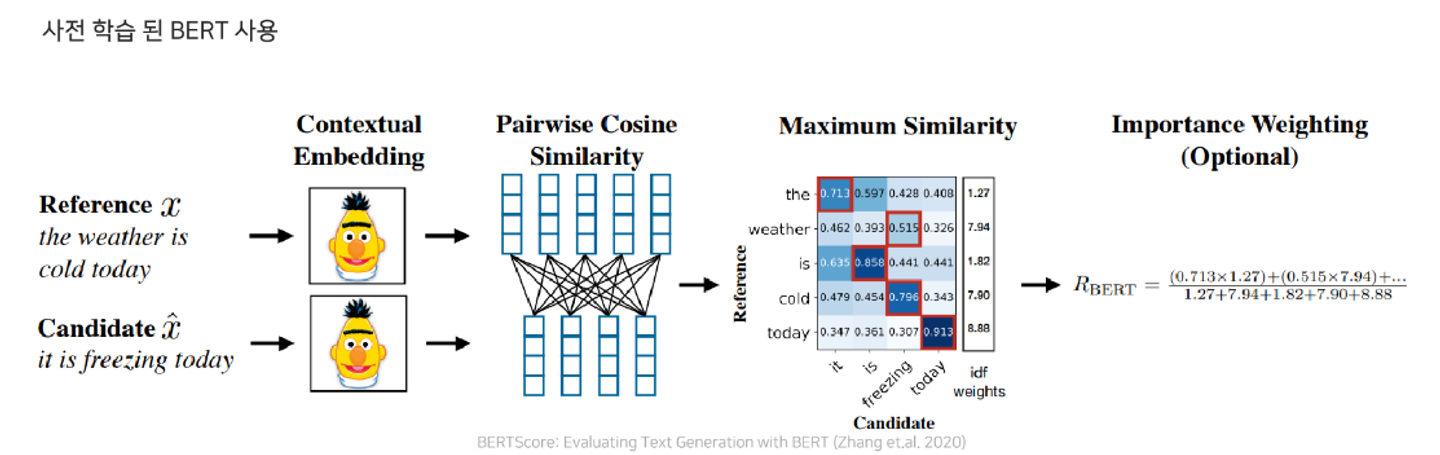
BERTSCORE
bert를 이용하여 임베딩을 하고, 코사인 similarity를 이용하여 계산한뒤 greedy matching 후 weighted average를 구한다.
sentence Mover’s similarity
앞의 매트릭을 문장범위까지 늘려, 문장과 단어 레벨에서 모두 similarity를 계산하는 것이다.
