
DMOps (Data Management Operations)
개요
DMOps는 데이터 관리 작업과 절차(Data Management Operation and Recipes)를 의미합니다. AI 모델의 성능을 높이기 위해 데이터셋의 품질을 유지하고 관리하는 일련의 단계로 구성됩니다.
주요 목적
- NLP 데이터 제작의 중요성: 고품질의 데이터셋을 통해 AI 모델의 신뢰성과 일관성을 유지하며, 서비스 요구 사항을 충족하도록 설계된 데이터 관리 절차를 제안합니다.
- 효율적 가이드라인 제공: 데이터 관리의 모든 과정을 체계적으로 설명하고 실행할 수 있도록 단계별 지침을 제공합니다.
데이터 구축 및 관리 절차
데이터 구축을 위한 단계
-
프로젝트 목표 설정:
- 데이터 구축의 목적과 요구 사항을 이해하고, 해당 프로젝트에 필요한 데이터의 종류와 분량을 정의합니다.
-
원시 데이터 확보:
- 크롤링, 공공 데이터 활용, 크라우드소싱 등 다양한 출처에서 원시 데이터를 수집합니다.
- 데이터 수집 시, 개인정보와 법적 제약사항을 준수합니다.
- 원시 데이터 수집 시 고려해야 할 주요 사항
- 신뢰성: 신뢰할 수 있는 출처에서 데이터를 수집해야 합니다. 신뢰성 높은 데이터를 확보함으로써 AI 모델이 정확하고 일관된 학습을 할 수 있도록 돕습니다.
- 다양성: 데이터의 다양성을 확보하여 AI 모델이 여러 경우에 대해 일반화할 수 있도록 합니다. 특정 환경이나 조건에 편중되지 않도록 다양한 출처, 상황, 인구 그룹 등의 데이터를 포함하는 것이 중요합니다. 수집된 데이터는 실제 세상의 특성과 변동성을 반영해야 합니다. 이를 통해 AI 모델이 다양한 상황을 처리할 수 있는 유연성을 갖출 수 있습니다.
- 획득 가능성: 데이터가 쉽게 획득되고 가공할 수 있는지를 고려합니다. 이는 수집 및 처리에 필요한 시간과 비용을 줄이는 데 중요합니다.
- 법적 및 제도적 준수: 개인정보가 포함된 데이터를 수집할 때는 법적 요구 사항을 준수해야 하며, 필요한 경우 데이터 수집과 활용에 대한 동의를 받아야 합니다.
-
데이터 전처리:
- 데이터의 품질을 높이기 위해 중복 제거, 비식별화, 개인정보 필터링 등의 작업을 수행합니다.
- 비윤리적 데이터나 노이즈 데이터를 필터링하여 데이터의 정확성을 보장합니다.
-
데이터 스키마 설계:
- AI 모델의 학습에 필요한 주석 체계를 정의합니다. 이를 통해 데이터가 모델의 요구 사항에 부합하는지 확인합니다.
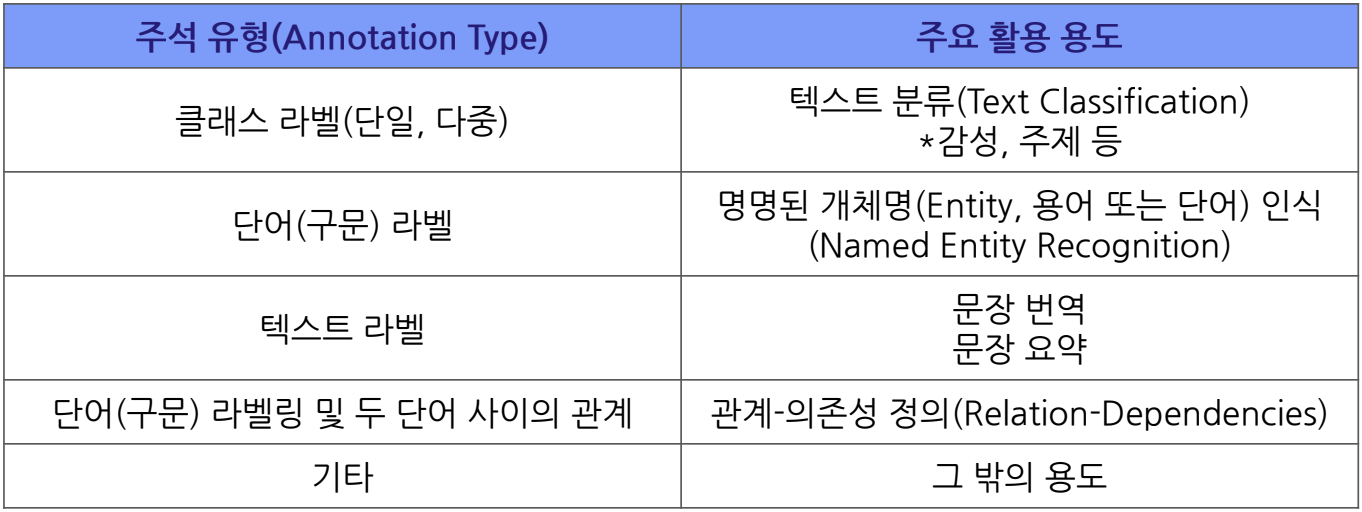
- AI 모델의 학습에 필요한 주석 체계를 정의합니다. 이를 통해 데이터가 모델의 요구 사항에 부합하는지 확인합니다.
-
가이드라인 준비:
- 작업자나 크라우드소싱 참여자에게 제공할 작업 지침서를 작성합니다. 명확하고 체계적인 지침을 통해 엣지 케이스에 대비할 수 있습니다.
-
작업자 모집:
- 데이터셋의 품질을 유지할 수 있도록 적절한 경험을 가진 작업자를 모집합니다. 작업자의 보상과 작업 환경 또한 고려해야 합니다.
-
작업자 교육:
- 작성된 가이드라인을 바탕으로 작업자와의 양방향 소통을 통해 교육을 실시합니다. 질문을 유도하여 가이드라인에 대한 이해도를 높입니다.
-
데이터 주석:
- 주석 작업을 통해 실제 데이터를 구축하며, 작업자의 언어적/시각적 직관을 활용하여 데이터의 품질을 관리합니다.
-
데이터 검수:
- 작업의 일관성과 신뢰성을 위해 내부 및 외부 요인을 점검하며, IAA(Inter-annotator Agreement) 등의 방법을 통해 데이터를 검수합니다.
-
모델을 통한 데이터 평가:
- 모델을 이용해 데이터의 품질을 평가하고, 데이터의 효율성과 일관성을 검증합니다.
-
데이터 전달물 작성:
- 최종 데이터와 분석 보고서를 유관 부서에 전달하고, 데이터셋의 버저닝과 라벨 분포를 명시하여 관리합니다.
데이터 주석 도구 및 소프트웨어
주석 도구
- Doccano: 텍스트 분류와 시퀀스 라벨링을 지원하는 오픈소스 주석 도구로, NLP 데이터 주석에 자주 사용됩니다.
- Brat: 개체 간 관계 주석에 적합한 도구로, 외부 데이터베이스(Wikipedia, Freebase 등)를 활용할 수 있습니다.
- TagEditor: 텍스트에 빠른 주석을 달 수 있도록 설계된 도구로, 데스크톱 애플리케이션 형태로 제공됩니다.
- LightTag, Tagtog 등: 작업자의 효율을 높이고, 데이터의 일관성과 정확성을 보장하기 위해 사용됩니다.
- Label-Studio: 사용자 친화적인 인터페이스와 강력한 기능을 갖춘 주석 도구로, 다양한 데이터 작업에 효율적으로 활용될 수 있습니다.
데이터 소프트웨어 도구
- CleanLab: 데이터셋 내 오류를 감지하고 데이터를 정리하여 신뢰할 수 있는 학습 데이터를 제공합니다.
- Snorkel: 약한 감독 학습을 통해 데이터의 품질을 높이며, 프로그램을 통한 데이터 라벨링을 지원합니다.
- Great Expectations: 데이터 품질 테스트 및 문서화를 통해 데이터팀이 데이터의 신뢰성과 일관성을 확보하도록 돕습니다.
크라우드소싱 기반 데이터 수집 및 가공
크라우드소싱을 통해 대규모 데이터셋을 수집하고, 가공할 수 있습니다. 대표적인 크라우드소싱 플랫폼으로는 Crowdworks, Appen, Scale.ai 등이 있습니다. 이들 플랫폼은 전 세계 다양한 작업자를 대상으로 데이터 수집 및 가공 작업을 수행하며, AI 모델의 성능을 높이기 위한 고품질 데이터를 제공합니다.
데이터 품질 관리 및 윤리적 고려사항
- 품질 관리: 일관성, 다양성, 신뢰성, 프라이버시, 보안, 윤리적 적합성 등을 평가하여 데이터를 검수합니다.
- 윤리적 고려: 데이터 수집과 주석 작업 시 프라이버시 보호와 윤리적 책임을 고려해야 합니다.

생각, 기술, 회고 등 다양한 분야를 기록합니다.