
규칙 기반 NLP (Rule-Based NLP) – 전문가의 시대
규칙 기반 NLP는 언어 처리 작업을 위해 전문가가 직접 정의한 규칙을 이용해 시스템을 구성하는 방식입니다. 이 접근법은 언어학적 지식에 대한 깊은 이해를 바탕으로, 형태소 분석, 구문 분석, 의미 분석 등 다양한 언어 처리 작업을 수행합니다.
특징:
- 전문가 의존성: Task를 수행하기 위해서는 언어에 대한 깊은 전문 지식이 필요하며, 규칙을 구성하는 데 많은 시간이 소요됩니다.
- 기계 번역: 규칙기반 기계번역(Rule-Based Machine Translation) 시스템은 두 언어의 문법적, 어휘적 규칙을 바탕으로 번역을 수행합니다.
규칙 기반 NLP의 주요 한계는 새로운 언어적 변형에 대한 유연성이 떨어진다는 점입니다. 규칙을 모두 정의하기 어려운 복잡한 언어적 상황에서 한계가 명확하게 드러났습니다.
통계 기반 NLP (Statistical NLP) – 모두의 시대
통계 기반 NLP는 대규모 텍스트 데이터(빅데이터)를 이용해 언어를 모델링하는 방식입니다. 대량의 데이터를 활용해 단어 간의 동시 발생 빈도를 기반으로 언어의 의미를 추론합니다.
특징:
- 빅데이터 활용: 통계 기반 접근법은 "모두(군중)"가 무의식적으로 생성한 데이터를 활용하여 모델을 학습합니다.
- Sparsity 문제: 데이터의 부족으로 인해 모델링에 한계가 발생하는 'Sparsity Problem'이 주요 이슈로 등장했습니다.
- 전문가의 중요성 감소: 통계 기반 NLP는 규칙 기반 NLP에 비해 전문가의 중요성이 감소되었습니다.
- 더 많은 데이터 필요: 규칙 기반 접근법보다 더 많은 데이터가 필요합니다.
- 개발 용이성: 통계적 접근법은 규칙 기반 접근법에 비해 개발이 쉽고 빠릅니다.
Statistical Machine Translation (SMT): 두 언어의 평행 코퍼스(Parallel Corpus)를 이용해 번역을 수행하는 방식입니다. 단어 단위에서 시작해 구(Phrase) 단위로, 이후에는 구문 구조를 고려한 번역 방식으로 발전했습니다.
Statistical Machine Translation의 발전 과정
- 단어 단위 번역: 초기에는 단어(word) 단위로 번역을 수행했습니다.
- 구 단위 번역: 2003년에는 여러 개의 단어로 이루어진 구(Phrase) 단위로 번역하는 방식이 제안되었습니다.
- Hierarchical Phrase-Based SMT: 구 내에 변수 개념을 도입한 Hierarchical Phrase-Based SMT 방식이 제안되었습니다. 예를 들어, "eat an apple -> 사과를 먹다" 대신 "eat X -> X"로 문장을 표현하여, X에 apple, banana 등 다양한 단어를 수용할 수 있는 유연성을 갖추게 되었습니다.
- Prereordering-based SMT: 번역하기 전에 어순을 바꾸어 성능을 향상시키는 Prereordering-based SMT 방식이 도입되었습니다.
- Syntax-Based SMT: Hierarchical Phrase-Based SMT에서 "eat X"를 "eat NP(명사구)"로 변경하여, 모든 구가 올 수 있는 것이 아닌 명사구만 올 수 있도록 한정하여 불필요한 번역 후보를 사전에 제거했습니다.
머신러닝 및 딥러닝 기반 NLP – 전문가와 군중의 공존
머신러닝 및 딥러닝 기반의 NLP는 규칙 기반 접근법과 달리 데이터로부터 직접 학습하는 방식입니다. 이 접근법은 데이터를 직접 전문적으로 생산하는 전문가의 역할과 우리 모두(군중)로 부터 생성되는 빅데이터의 결합을 통해 발전해 왔습니다.
특징:
- 데이터의 질과 양: 학습에 사용되는 데이터의 질과 양이 충분하다면, 인간의 능력을 초월할 수 있습니다. 예를 들어, 알파고와 이세돌의 대결에서 보듯이 딥러닝 모델은 새로운 방식의 문제 해결을 보여줄 수 있습니다.
- Neural Machine Translation (NMT): 신경망 기반 기계 번역은 SMT의 한계를 극복하고자 등장했으며, 번역 품질이 크게 향상되었습니다.
지도학습 데이터(전문가) vs 비지도학습 데이터(군중)
-
지도학습 데이터(Supervised Learning Approach):
- 정답(레이블)을 필요로 하는 데이터
- Named-Entity Recognition(NER), Relation Extraction(RE), Sentiment analysis 등 - 데이터 구축에 시간 및 금전적 비용이 발생
- 대량으로 구축하기 어려움
- 대부분의 딥러닝 시스템 구축에는 지도학습 과정이 필요하며, 이를 위한 데이터 확보 방법에 대한 계획이 중요합니다.
- 정답(레이블)을 필요로 하는 데이터
-
비지도학습 데이터(Unsupervised Learning Approach):
- 정답(레이블)이 필요하지 않은 데이터 (예: 입력과 출력이 동일한 Auto-Encoder 학습 방법)
- 손쉽게 대량으로 구축할 수 있음. 이 후 대규모 말뭉치를 통해 언어모델을 학습 (빅데이터)
- 일부 예외적인 경우를 제외하고는 실제 사용 가능한 수준의 성능을 낼 수 있음
- 지도학습을 보완하여 성능을 더욱 향상시키는 방법으로 사용됨 (예: BERT, GPT-3와 같은 Pretrain 언어 모델)
Pre-training & Fine-tuning 기반 NLP – 대중과 전문가의 협력
Pre-training & Fine-tuning 접근법은 대규모 말뭉치를 사용해 사전 학습(Pre-training)한 후, 특정 작업에 맞게 미세 조정(Fine-tuning)하는 방식입니다. 이는 대중이 만든 데이터(Pre-train)와 전문가가 만든 데이터(Fine-tune)을 결합하여 하나의 고성능 모델을 만드는 방식입니다.
Transformer 모델
- Pre-training & Fine-tuning 기반 NLP 접근법의 핵심은 Transformer 아키텍처입니다. Transformer는 이후 다양한 변형 모델(BERT, GPT 등)의 기반이 되었으며, NLP 연구의 주요 트렌드로 자리 잡았습니다.
벤치마크의 등장
- Task-specific benchmark dataset의 대량 등장: 특정 작업에 맞춘 벤치마크 데이터셋들이 대량으로 등장했습니다.
- Leaderboard에서의 성능 경쟁: 다양한 모델들이 벤치마크 데이터셋을 활용해 성능을 경쟁하며, 리더보드에서의 순위를 겨루는 경쟁이 시작되었습니다.
Neural Symbolic NLP – 전문가의 데이터 활용
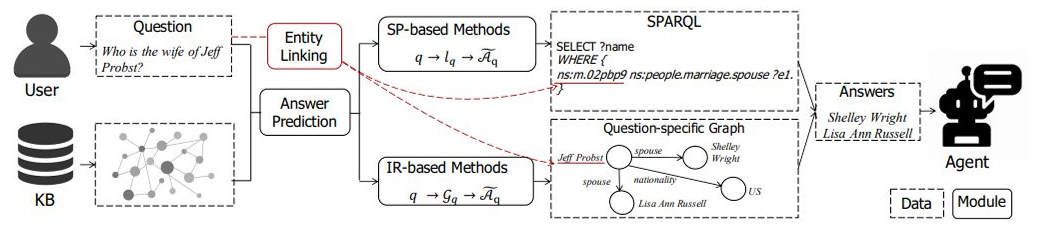
Neural Symbolic NLP는 딥러닝 모델의 한계를 보완하기 위해 상식 정보와 추론 능력을 도입한 방식입니다. 전문가의 데이터를 전면활용하여 구축한 지식 그래프(knowledge graph)를 이용해 추론을 수행하며, 딥러닝의 학습된 패턴과 결합해 더 나은 결과를 도출합니다.
- Knowledge Base(KB)에서의 정보(지식 그래프)를 바탕으로 질문에 대답하는 Knowledge Base Question Answering
대규모 언어 모델 (Large Language Models) – 모두의 시대
대규모 언어 모델(LLM)은 대량의 데이터를 바탕으로 학습된 거대한 신경망 모델입니다. 대표적인 예로 OpenAI의 GPT-3, Google의 PaLM 등이 있으며, 이들은 수많은 파라미터를 통해 다양한 언어 작업을 수행할 수 있습니다.
특징:
- 무의식적 데이터 생성: LLM은 대중이 생성한 방대한 데이터를 활용해 학습되며, 학습된 내용을 바탕으로 인간처럼 언어를 생성할 수 있습니다.
- Few-shot Learning: LLM은 적은 수의 예제만으로도 특정 작업을 수행할 수 있는 능력을 가지고 있습니다.
Foundation Models와 In-Context Few-Shot Learning & Prompt Engineering
-
Foundation Models는 대규모 데이터로 학습된 범용 인공지능 모델을 의미합니다. 이 모델들은 다양한 Task에 걸쳐 활용될 수 있는 공통된 기반을 제공하며, NLP뿐만 아니라 컴퓨터 비전 등 여러 분야에서 사용됩니다. 대표적인 예로 BERT, GPT-3, PaLM 등이 있으며, 이들은 사전 학습(Pre-training) 과정을 거쳐 이후 특정 작업에 맞게 미세 조정(Fine-tuning)됩니다.
-
In-Context Few-Shot Learning은 AI 모델이 새로운 작업을 학습할 때, 특정 작업에 대한 예제 몇 개를 "문맥 내(in-context)"에 제공함으로써 적은 데이터로 학습할 수 있는 능력을 의미합니다. 이 방법에서는 모델을 재훈련하지 않고도 입력 데이터에 포함된 예제들을 기반으로 모델이 주어진 작업을 수행할 수 있도록 합니다. 새로운 작업을 위한 몇 가지 예시를 Prompt와 함께 제공하여 모델이 그 패턴을 학습하여 이후 입력에 맞는 답변을 생성하는 방식입니다.
-
Prompt Engineering은 대규모 언어 모델이 특정 작업을 수행하도록 유도하기 위해 입력 프롬프트를 설계하고 최적화하는 과정입니다. 이를 통해 모델이 적절한 답변을 생성하도록 하며, 학습된 내용을 최대한 효과적으로 활용할 수 있도록 돕습니다. 예를 들어, OpenAI의 GPT-3와 같은 모델은 주어진 프롬프트에 따라 다양한 형태의 언어 생성 작업을 수행할 수 있습니다.
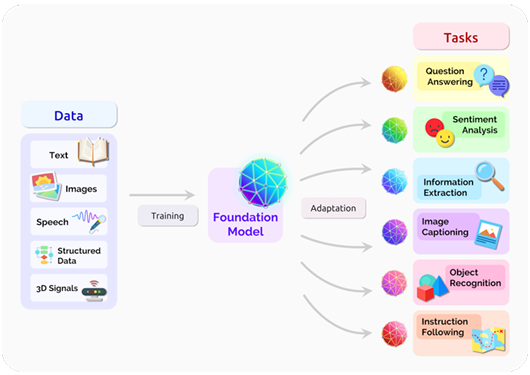
즉, LLM(대형 언어 모델)과 같은 Foundation Models은 학습된 범용 지식을 바탕으로, In-Context Few-Shot Learning과 Prompt Engineering을 통해 재학습 없이도 특정 작업을 수행할 수 있도록 유도할 수 있습니다.
Human Feedback Data 기반 NLP – 의식적 데이터 생성
Human Feedback Data 기반 NLP는 모델이 더 나은 성능을 낼 수 있도록 인간이 직접 피드백을 제공하는 방식입니다. 대표적인 예로 ChatGPT가 있으며, 이는 인간의 피드백을 반영해 성능을 향상시킵니다.
Reinforcement Learning: 이러한 피드백 기반 접근법은 강화 학습(Reinforcement Learning)을 통해 모델의 성능을 지속적으로 개선합니다.
References
- OntheOpportunitiesandRisksofFoundationModels(Bommasanietal.,2021)
- ComplexKnowledgeBaseQuestionAnswering:ASurvey(Lanetal.,2021)
