
1. 모델 수정 없이 성능 향상하기 (Without Model Modification)
모델을 수정하지 않고 데이터 중심 접근 방식으로 NLP 모델의 성능을 향상시키는 다양한 방법들이 존재합니다. 대표적인 방법으로는 서브워드 토큰화(Subword Tokenization), 데이터 증강(Data Augmentation), 데이터 필터링(Data Filtering), 합성 데이터(Synthetic Data), 훈련 전략(Training Strategies) 등이 있습니다.
1.1 서브워드 토큰화 (Subword Tokenization)
서브워드 토큰화는 OOV(Out-Of-Vocabulary) 문제, 희귀 단어, 신조어 등으로 인해 발생하는 어려움을 해결하는 데 유용합니다. 한국어처럼 교착어의 특성을 가진 언어에서 형태소 기반 서브워드 토큰화가 효과적입니다.
- BPE(Byte Pair Encoding): 가장 빈도 높은 유니그램 쌍을 하나의 유니그램으로 통합하는 방식으로, 바텀업(bottom-up) 접근법을 사용해 딕셔너리를 생성합니다. 이를 통해 자주 사용되는 단어 조합을 효과적으로 표현할 수 있습니다.
- 형태소 기반 서브워드 토큰화: 한국어와 같이 교착어를 위한 토큰화 방식으로, 형태소 분석기(Mecab-ko) 등을 이용해 BPE를 적용하여 어휘 집합(vocab)을 구성합니다. 예를 들어 KLUE(Korean Language Understanding Evaluation)에서는 32K의 어휘 집합을 생성해 사용합니다.
1.2 데이터 증강 (Data Augmentation)
데이터 증강은 데이터의 다양성을 높이고 오버피팅을 방지하기 위해 원본 데이터를 변형하거나 새로운 데이터를 추가하는 기법입니다.
Rule-Based Techniques: 사전에 정의된 변형 방식을 이용해 데이터를 쉽게 증강합니다.
-
Easy Data Augmentation(EDA)
- SR(Synonym Replacement): 동의어로 치환
- RI(Random Insertion): 임의 삽입
- RS(Random Swap): 임의 교환
- RD(Random Deletion): 임의 삭제
-
Unsupervised Data Augmentation(UDA):
UDA는 레이블이 없는 데이터를 활용해 모델의 성능을 향상시키는 기법입니다. 원본 데이터에 무작위 변형을 가해 모델이 다양한 데이터 변형에 대해 일관된 예측을 하도록 훈련함으로써 일반화 능력을 향상시킵니다. 이를 통해 레이블이 부족한 상황에서도 높은 성능을 유지할 수 있으며, 텍스트와 이미지 분류 등 다양한 분야에서 활용됩니다.
Example Interpolation Techniques: 여러 예시 데이터를 보간하여 새로운 데이터를 생성합니다.
-
MixUp: 두 개 이상의 예시의 입력값과 레이블을 혼합하여 새로운 데이터를 생성하는 기법입니다.
-
Mixed Sample Data Augmentation(MSDA): MSDA는 여러 샘플의 데이터를 혼합하여 새로운 샘플을 생성하는 데이터 증강 기법입니다. 이를 통해 데이터의 다양성을 증가시키고, 모델이 더욱 일반화된 성능을 보일 수 있도록 돕습니다. MixUp과 유사하게 여러 입력과 레이블을 혼합하여 학습 데이터를 생성함으로써, 모델이 다양한 데이터 조합에 대해 더 잘 대응하도록 합니다.
Model-Based Techniques: Seq2seq 모델이나 언어 모델을 사용해 데이터를 증강하는 방식입니다.
-
Back-Translation (BT): 문장을 다른 언어로 번역한 후, 다시 원래 언어로 번역하여 새로운 데이터를 생성하는 방법입니다.
-
Fine-Tuning GPT for Paraphrasing: GPT-3 등 대규모 생성 모델을 미세 조정하여 문장을 바꿔 쓰는 기법입니다. 이 방식은 대규모 언어 모델을 이용해 입력 문장을 다양한 방식으로 재구성하거나 의미를 유지하면서도 표현을 다양화하는 데 사용됩니다. 이를 통해 모델이 문장 표현의 다양성을 학습하고, 텍스트 생성이나 요약, 문장 유사도 측정과 같은 작업에서 더 나은 성능을 발휘할 수 있습니다.
1.3 데이터 필터링 (Data Filtering) vs. 데이터 클리닝 (Data Cleaning)
데이터 필터링과 데이터 클리닝은 데이터 품질을 개선하는 과정에서 각각 다른 목적과 역할을 수행합니다.
-
데이터 필터링: 데이터의 질을 높이기 위해 불필요하거나 부적절한 데이터를 제거하는 과정입니다. 병렬 말뭉치를 필터링하거나 특정 기준에 따라 데이터를 걸러내는 방식으로, 주로 데이터의 유효성과 일관성을 확보하는 데 초점을 둡니다. 예를 들어, 잘못된 번역이나 부적합한 문장을 제거하여 데이터의 품질을 높입니다.
-
데이터 클리닝: 데이터의 전처리 과정으로, 불용어 제거, 오탈자 수정, 중복 데이터 제거 등 데이터를 정제하여 품질을 향상시키는 작업입니다. 데이터 클리닝은 모델이 학습할 수 있도록 데이터를 정제하고 일관되게 만들어 사용하는 과정에 초점을 맞춥니다.
따라서 데이터 필터링은 데이터의 불필요한 부분을 제거해 데이터의 유효성과 일관성을 확보하는 데 중점을 두는 반면, 데이터 클리닝은 데이터를 정제하여 모델 학습에 적합한 상태로 만드는 데 중점을 둡니다.
병렬 말뭉치 필터링 (Parallel Corpus Filtering)
- 언어 감지 필터: 문장 쌍이 원하는 언어로 되어 있는지 확인합니다.
- 수용 가능성 필터: 문장 쌍의 내용이 서로 유사하여 의미적으로 수용 가능한지 확인합니다.
- 도메인 필터: 문장이 원하는 주제 범위 내에 있는지 확인하여, 범위를 벗어난(out-of-domain) 문장을 걸러냅니다.
1.4 합성 데이터 (Synthetic Data)
합성 데이터는 실제 크롤링, 크라우드소싱 등으로 수집한 데이터가 아닌 통계적, 전산학적 기법으로 생성한 데이터를 의미합니다. 최근에는 GPT-3와 같은 대규모 언어 모델을 이용해 생성된 합성 데이터가 많이 사용되고 있으며, 합성 데이터는 레이블링 비용을 줄이고 모델 학습에 필요한 데이터 양을 보충하는 데 유용합니다.
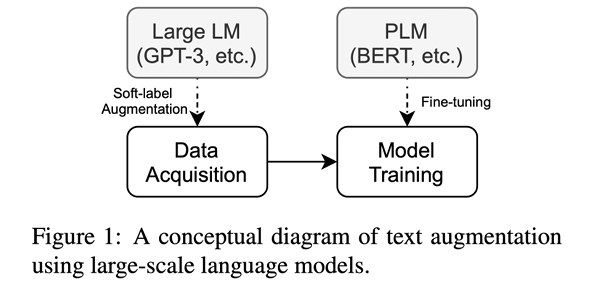
1.5 훈련 전략 (Training Strategies)
훈련 전략은 모델 학습의 효과를 높이기 위해 데이터를 처리하고 모델을 학습시키는 방법을 다룹니다. 대표적인 전략으로는 커리큘럼 학습(Curriculum Learning)이 있습니다. 커리큘럼 학습은 쉬운 내용부터 어려운 내용으로 단계적으로 모델을 학습시켜 모델의 학습 효율을 높이고 성능을 개선합니다. 이러한 전략은 모델이 점진적으로 더 복잡한 문제를 다룰 수 있도록 돕습니다.
2. 데이터 측정 (Data Measurement)
데이터의 품질을 측정하기 위해서는 Inter-Annotator Agreement(IAA)를 이용해 어노테이터 간 일관성을 평가합니다. 주요 메트릭으로 Cohen’s Kappa, Fleiss’ Kappa, Krippendorff’s Alpha가 사용됩니다. 이 지표들은 어노테이터들이 생성한 레이블이 얼마나 일관성 있는지를 수치화하여 데이터 품질을 평가하는 데 도움을 줍니다.
- Cohen’s Kappa: 두 명의 어노테이터 간 일치도를 평가합니다. 0.6 이상일 경우 높은 일치도를 나타냅니다.
- Fleiss’ Kappa: 세 명 이상의 어노테이터 간 일치도를 평가합니다. Cohen’s Kappa와 비슷한 기준으로 평가됩니다.
- Krippendorff’s Alpha: 다수의 어노테이터 간 일치도를 평가하며, 0.8 이상일 경우 신뢰할 수 있는 데이터로 판단합니다.
3. 인간-컴퓨터 상호작용 (HCI) 및 좋은 데이터의 특성
데이터의 품질은 AI 모델의 성능에 직접적인 영향을 미치며, 이를 위해 데이터 캐스케이드(Data Cascade)와 같은 개념이 중요합니다. 데이터 캐스케이드는 데이터의 품질 저하가 모델의 성능 저하로 이어지는 복합적인 문제를 의미합니다.
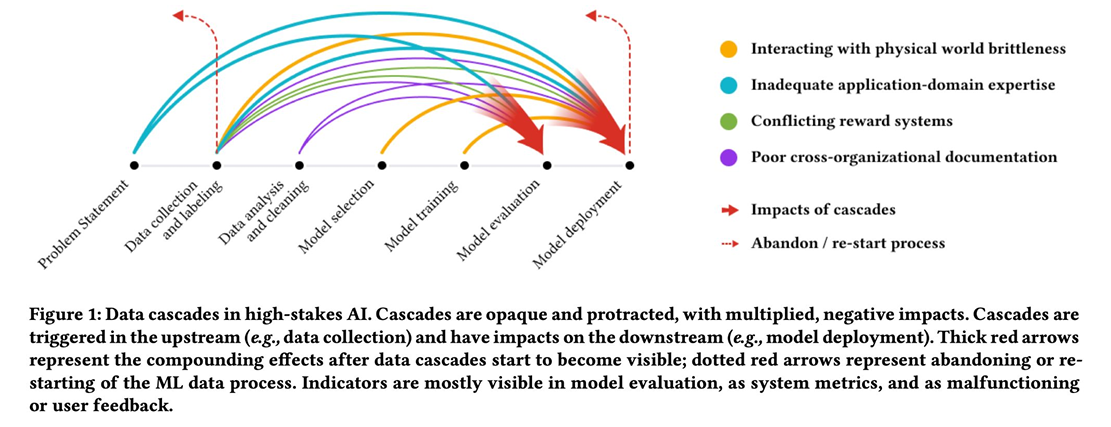
좋은 데이터의 특성은 다음과 같습니다:
- 일관성: 동일한 데이터가 일관성 있게 라벨링되어야 함
- 다양성: 예상치 못한 케이스를 포함한 데이터를 수집해야 함
- 적절한 크기: 모델 학습에 충분한 양의 데이터를 제공해야 함
좋은 데이터를 유지하기 위한 라이프사이클은 데이터의 구성, 수집, 전처리, 클리닝, 라벨링 등 여러 단계로 이루어지며, Datasheets for Datasets와 같은 체계적인 관리 방식을 도입해 데이터를 관리하는 것이 중요합니다.
References
- GPT3Mix:LeveragingLarge-scaleLanguageModelsforTextAugmentation(Yooetal.,2021
- “Everyonewantstodothemodelwork,notthedatawork”:DataCascadesinHigh-StakesAI(Nithyaetal.,2021)
