
Extraction-based MRC
Extraction-based Machine Reading Comprehension (MRC)은 자연어 처리에서 주어진 텍스트에서 질문에 대한 답을 직접적으로 추출하는 접근법이다. 이 방법은 문서에서 이름, 날짜, 정의와 같은 특정 정보를 효율적으로 찾는 데 유용하며, 많은 질문-응답 시스템의 기반이 된다.
Extractive MRC 시스템은 텍스트와 질문을 입력으로 받아 텍스트 내에서 정답일 가능성이 높은 부분(위치)을 예측한다. 이를 위해 BERT, RoBERTa와 같은 트랜스포머 기반 모델들이 자주 사용된다. 이 모델들은 질문과 텍스트를 함께 인코딩함으로써, 질문의 의미에 맞는 텍스트의 중요한 부분에 집중할 수 있도록 한다.
이 과정은 질문과 텍스트를 동일한 임베딩 공간으로 인코딩하는 것에서 시작한다. 이를 통해 모델은 질문과 텍스트 간의 상관관계를 파악할 수 있게 된다. 모델은 텍스트 내 각 단어의 위치에 대해 소프트맥스 함수를 적용하여 답변이 시작되는 위치와 끝나는 위치를 예측하고, 이를 통해 답변 범위를 추출한다.
Extraction-based MRC의 장단점
Extractive MRC의 장점 중 하나는 텍스트에서 직접 정답을 선택하기 때문에 정보의 정확성을 유지할 수 있다는 것이다. 이는 잘못된 정보 생성의 위험을 줄여주며, 특히 고객 서비스 챗봇, 법률 문서 분석, 학술 연구와 같이 높은 정확성이 요구되는 분야에서 유용하다.
그러나 이 접근법에는 몇 가지 한계가 존재한다. 텍스트에서 정확히 일치하는 답을 찾아야 하므로, 답이 명시적으로 나타나 있지 않거나 여러 문장에 걸쳐 종합적인 이해가 필요한 경우 모델이 어려움을 겪을 수 있다. 또한, 모호한 질문이나 추론을 필요로 하는 질문에 대해서는 잘 대응하지 못하는 경우가 많다. 이러한 점은 생성적 또는 요약 기반의 MRC 접근법에 비해 한계로 작용한다.
Extraction-based MRC Overview
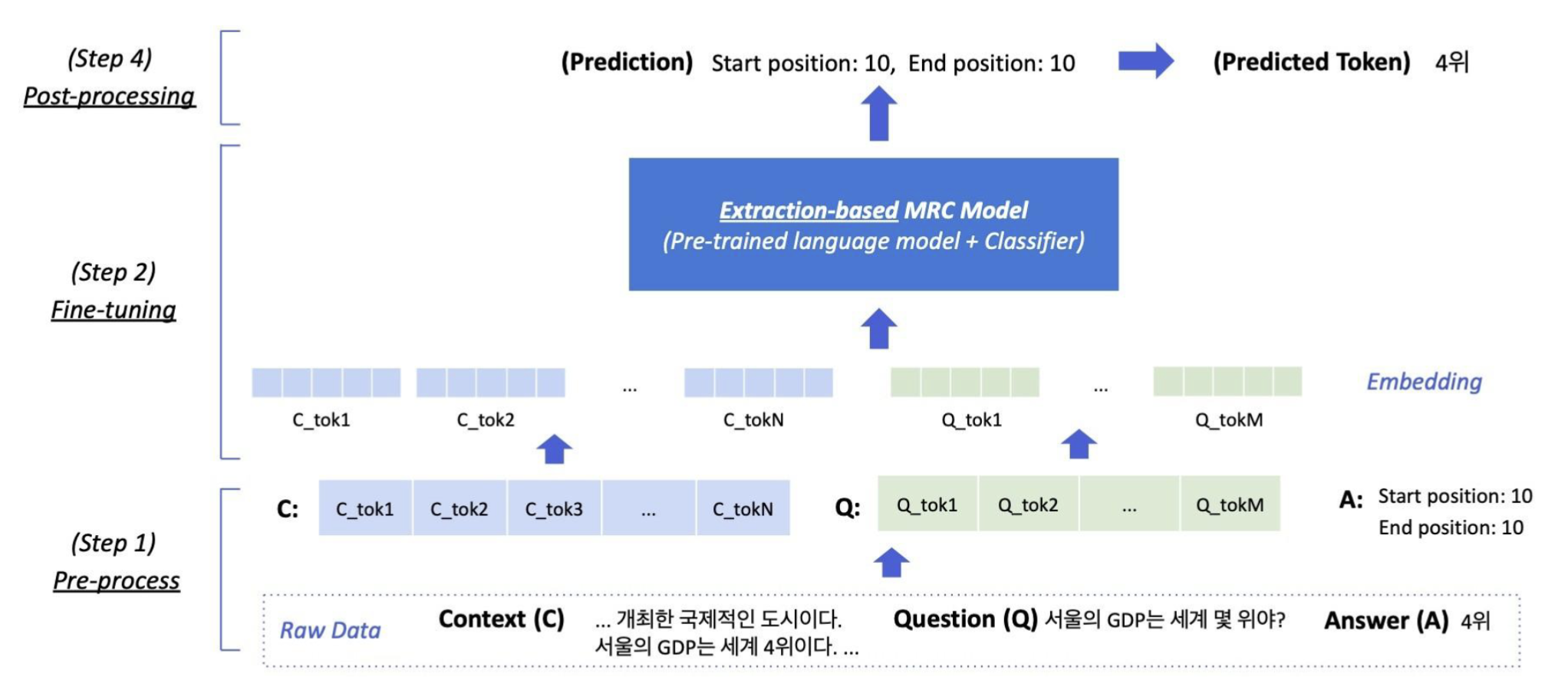
1. Pre-processing for Extractive MRC (전처리)
Tokenization
- Special Tokens: 문서와 질문을 구분하기 위해 특별한 토큰([CLS], [SEP] 등)을 사용한다.
- Attention Mask: 모델이 유효한 토큰에만 집중하도록 마스크를 사용한다.
- Token Type IDs: 문서와 질문을 구별하기 위해 각 토큰에 문서 또는 질문의 타입을 표시한다.
Text Normalization
- 대소문자 통일, 공백 처리, 특수문자 제거 등을 통해 입력 텍스트를 정규화한다.
- 불필요한 토큰이나 기호를 제거하여 모델의 학습 성능을 높인다.
2. Processing for Extractive MRC
정답은 문서 내에 있는 연속된 단어 토큰(span)이기 때문에, span의 시작과 끝 위치를 알면 정답을 찾을 수 있다. 따라서 Extraction-based 접근법에서는 답안을 새로 생성하는 대신, 시작 위치와 끝 위치를 예측하도록 모델을 학습시킨다. 이는 곧 Token Classification 문제로 변환하는 것과 같은 방식이다.
모델 아키텍처
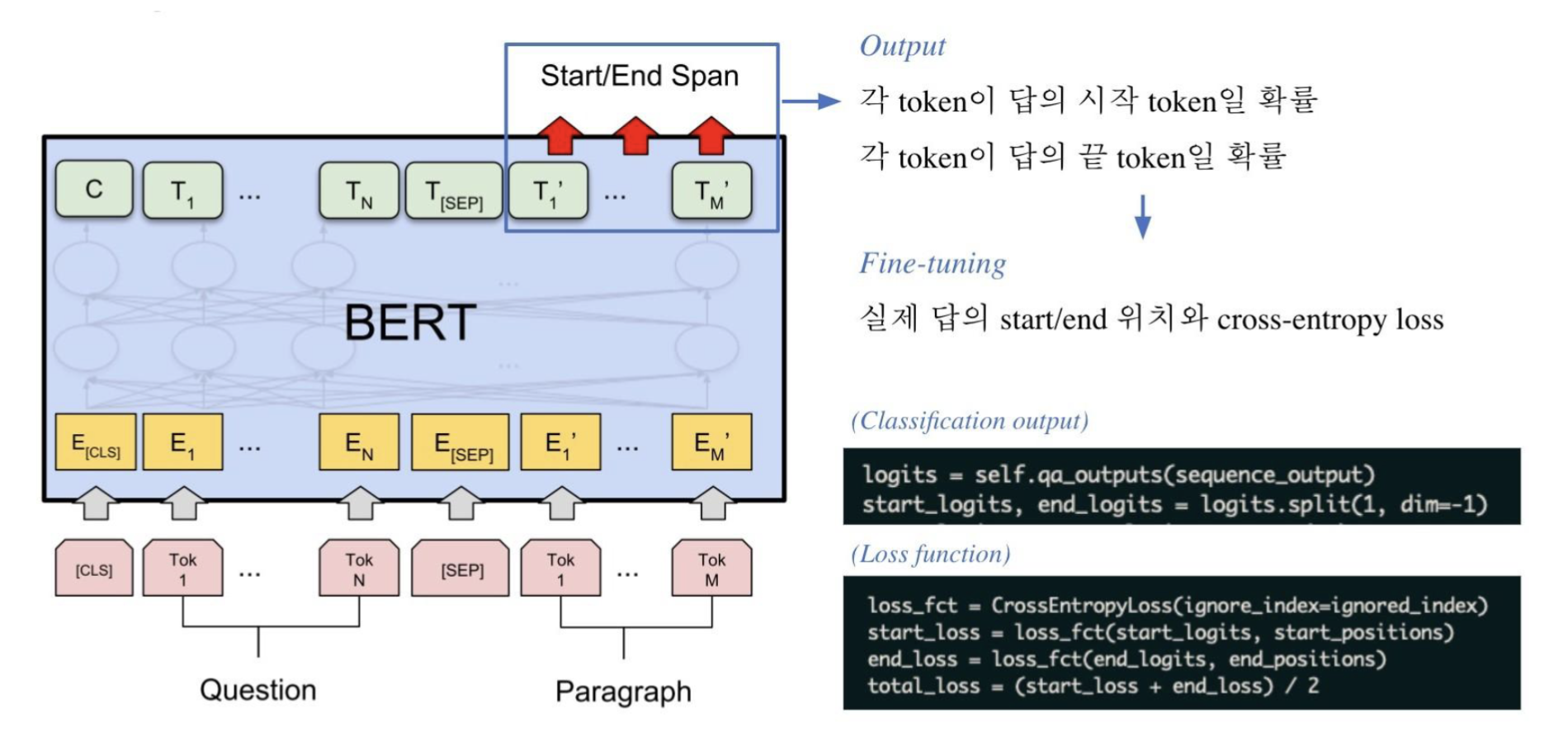
- Transformer 기반 모델(BERT, RoBERTa 등)을 사용하여 문서와 질문을 함께 인코딩한다.
- 모델은 질문과 문서의 관계를 파악하여, 문서 내에서 답변이 될 수 있는 span의 시작과 끝 위치를 예측한다.
3. Post-processing for Extractive MRC (후처리)
불가능한 답 제거하기
다음과 같은 경우 candidate list에서 제거
- End position이 start position보다 앞에 있는 경우 (e.g. start=90, end=80)
- 예측한 위치가 context를 벗어난 경우 (e.g. question 위치 쪽에 답이 나온 경우)
- 미리 설정한 max_answer_length보다 길이가 더 긴 경우
최적의 답안 찾기
- Start/end position prediction에서 score(logits)가 가장 높은 N개를 각각 찾는다.
- 불가능한 start/end 조합을 제거한다.
- 가능한 조합들을 score의 합이 큰 순서대로 정렬한다.
- Score가 가장 큰 조합을 최종 예측으로 선정한다.
- Top-k가 필요한 경우 차례대로 내보낸다.
정답 후보 필터링 및 가중치 조정
- 여러 개의 가능한 답변이 있는 경우, 각 답변의 확률을 기반으로 필터링하고, 필요에 따라 가중치를 조정하여 최종 정답을 선정한다.
- 모델의 예측 결과가 여러 답변 후보를 포함할 때, 각 후보의 가중치를 평가하여 최적의 답변을 선택한다.
Error Analysis
- 모델이 오답을 선택한 경우 그 원인을 분석하여 학습 데이터나 모델 구조를 개선할 수 있는 인사이트를 제공한다.
- 정답이 여러 문장에 걸쳐 있거나, 문맥적으로 복잡한 질문에 대해 모델이 오류를 범하는 경우를 파악하고 이를 개선하기 위한 방법을 도출한다.
