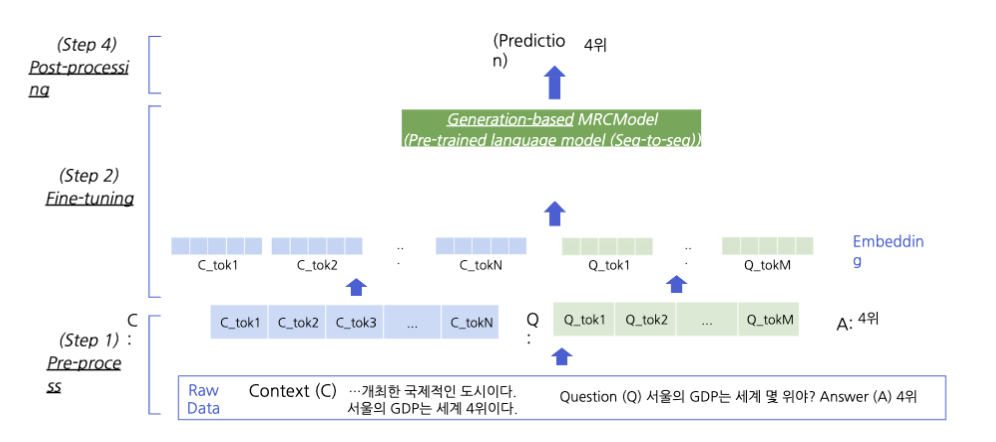
Generation-based MRC
Machine Reading Comprehension(MRC)은 머신이 자연어로 구성된 질문에 대해 주어진 텍스트에서 답변을 추출하거나 생성하는 작업을 의미한다. 전통적으로 MRC는 텍스트 내에 존재하는 정보를 기반으로 특정 답변을 추출하는 Extractive 방식이 주로 사용되었다. 하지만 최근에는 Generative-based 접근 방식이 점점 더 큰 주목을 받고 있다. 이러한 접근 방식은 질문에 대해 텍스트를 "생성"하는 모델을 활용해 보다 유연한 답변을 제공한다.
Generative-based MRC는 사전 학습된 대규모 언어 모델을 활용하여 답변을 생성한다. 이는 단순히 주어진 텍스트에서 정답을 찾는 것을 넘어, 보다 창의적이고 포괄적인 답변을 만들어내는 것을 목표로 한다. 대표적으로 GPT 계열 모델들이 이러한 역할을 수행할 수 있으며, 주어진 질문에 대해 훈련된 지식과 입력된 정보를 바탕으로 자연스러운 텍스트를 생성한다.
Generation-based MRC의 장점
이러한 방식의 장점은 두 가지로 요약할 수 있다. 첫째, Generative-based MRC는 주어진 정보로부터 직접적으로 답변을 추출하기 어려운 경우에도 답변을 만들어낼 수 있다. 예를 들어, 텍스트에 명시적으로 드러나지 않은 정보를 유추하거나 여러 문장을 연결해서 새로운 인사이트를 도출하는 것이 가능하다. 둘째, 인간의 언어와 비슷한 수준의 유연한 표현이 가능하다는 점이다. 따라서 사용자와의 상호작용에서 더 자연스러운 답변을 제공할 수 있으며, 다양한 질문 유형에 대응할 수 있다.
Generation-based MRC의 도전과제
하지만 Generative-based 접근 방식에는 몇 가지 도전 과제도 존재한다. 가장 큰 문제는 답변의 정확성이다. 생성 모델은 실제와 다른 정보를 만들어내는 경향이 있을 수 있어, 신뢰성을 보장하기 위해 추가적인 검증 절차가 필요하다. 또한 모델의 훈련 데이터에 의존하기 때문에, 편향된 데이터가 사용되면 편향된 답변을 생성할 위험도 존재한다.
Generative-based MRC는 이러한 한계를 극복하기 위해 강화 학습(RLHF)이나 인과적 추론(Chain-of-Thought)을 활용하여 더 정확하고 신뢰성 있는 답변을 생성하려는 노력이 지속되고 있다. 이를 통해 MRC 모델이 사람의 질문에 대해 보다 인간적인 방식으로 답변하고, 복잡한 문제를 해결하는 방향으로 발전하고 있다.
Generation-based MRC와 Extraction-based MRC 비교
- 모델 구조: Seq-to-seq PLM(Generative) vs. PLM + Classifier(Extraction)
- 답변 형태: 자유형 텍스트(Generative) vs. 지문 내 답 위치(Extraction)
- Extraction-based MRC는 F1 계산을 위해 텍스트로 변환하는 과정이 필요하다.
Generation-based MRC Overview
Preprocessing
입력 텍스트는 토큰화 과정을 거친다. Word Piece Tokenizer가 주로 사용되며, 텍스트를 작은 단위로 나누어 인덱스로 변환한다. 모델의 기본 입력은 이러한 인덱스(input_ids)이다.
Special Tokens
PAD, CLS, SEP 토큰을 사용하거나, 대신 자연어를 이용하여 정해진 텍스트 포맷(format)으로 데이터를 생성할 수도 있다.
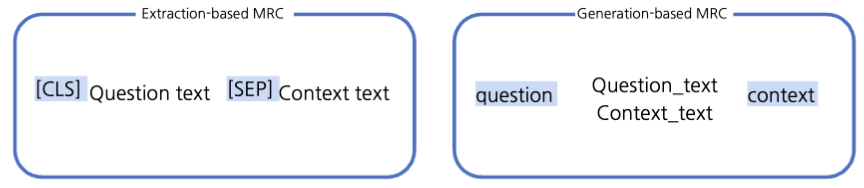
추가 정보 - 입력 표현
- Attention Mask: 어텐션 연산을 수행할지 결정한다.
- Token Type IDs: BART에는 token_type_ids가 없어 Extraction-based MRC의 BERT와 차이를 보인다.
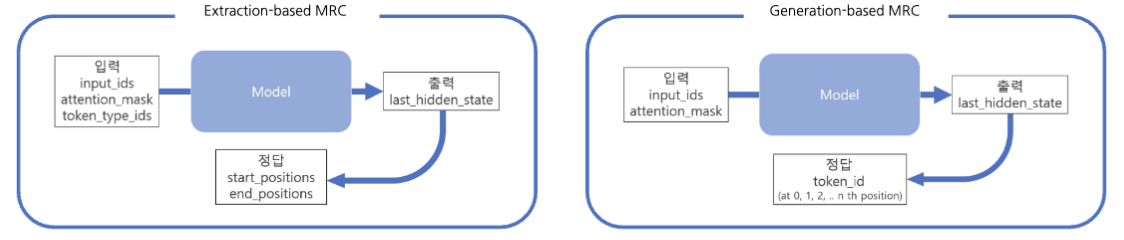
Outputs - 정답 생성
- Extraction-based MRC는 시작/끝 토큰 위치를 출력하며, Generation-based MRC는 실제 텍스트 생성을 목표로 한다.(전체 시퀀스의 각 위치마다 모델이 아는 모든 단어들 중 하나의 단어를 맞추는 Classification 문제)
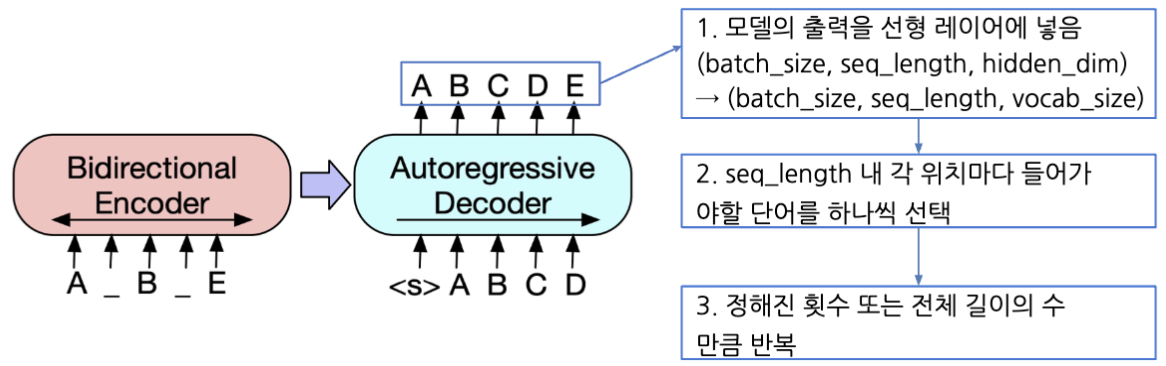
Models
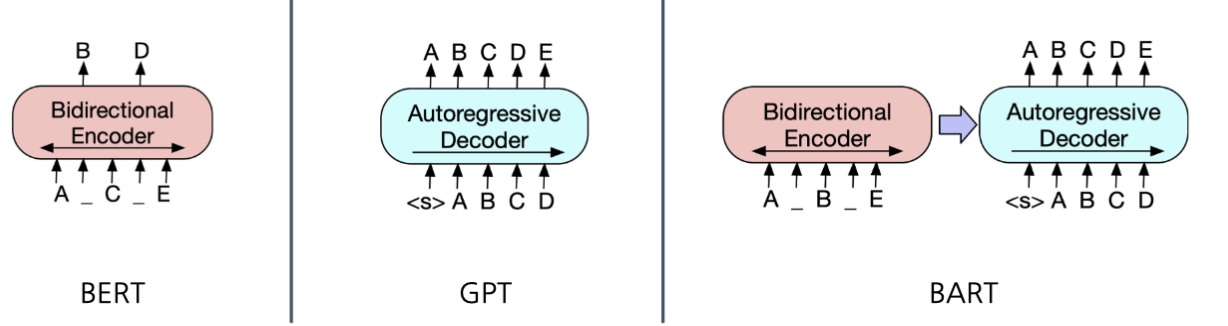
BART
BART는 기계독해, 기계번역, 요약 등 sequence-to-sequence 문제의 사전 학습을 위한 디노이징 오토인코더 모델이다. 인코더는 BERT처럼 양방향(bi-directional), 디코더는 GPT처럼 단방향(uni-directional)이다.
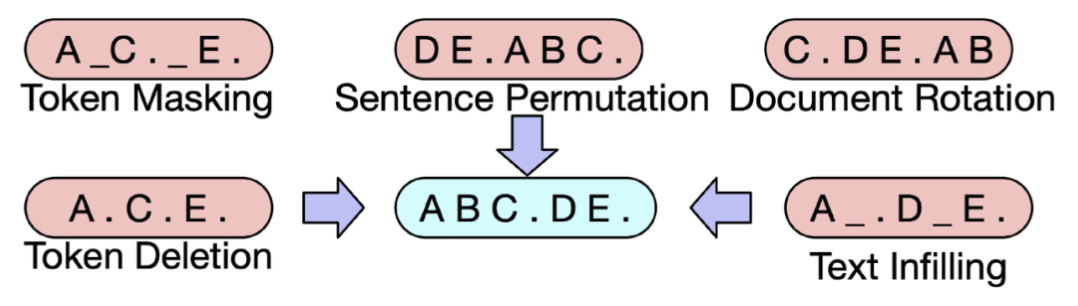
- BART의 사전 학습(Pre-training): 텍스트에 노이즈를 주고 원래 텍스트를 복구하는 문제를 풀며 학습한다.
T5 (Text-to-Text Transfer Transformer)
T5는 모든 텍스트 처리 문제를 'text-to-text' 문제로 취급한다. 즉, 텍스트를 입력으로 받아 새로운 텍스트를 생성하는 것을 출력으로 하는 접근 방식을 사용한다. 이를 통해 번역, 요약, 질의응답 등 다양한 작업을 하나의 통일된 방식으로 처리할 수 있다.
Text-to-Text Framework
-
입출력 포맷:
T5는 모든 작업을 자연어 문장이 들어가고 자연어 문장이 나오는 형태로 정의한다. 예를 들어 번역 작업에서는 'translate English to French: [입력 텍스트]'와 같은 형식으로 입력을 받으며, 요약 작업에서도 'summarize: [입력 텍스트]' 형태로 진행된다. 이처럼 각 작업에 대해 명시적인 지시어(prefix)를 사용하여 다양한 작업을 단일 모델로 수행할 수 있도록 설계되었다. -
Relative Position Encoding:
Transformer 모델에서 위치 정보를 인코딩하는 방식으로, 기존의 절대적 위치 인코딩 대신 상대적 위치 인코딩을 사용하여 더 효과적인 문맥 이해를 가능하게 한다. 이는 특히 긴 문장이나 문맥에서 문장 간의 관계를 잘 포착하는 데 유리하다. -
Prefix 사용:
다운스트림 작업에 대한 fine-tuning 시, 각 작업에 대해 특정 prefix(예: 'translate', 'summarize', 'question answering' 등)를 입력에 추가한다. 현재는 Instruct라는 prefix 방식을 사용하여 모델이 특정 작업을 수행하도록 지시한다. 이를 통해 모델은 입력된 문장이 어떤 작업에 해당하는지를 이해하고, 해당 작업에 맞는 출력을 생성하게 된다.
T5의 사전 학습
Span 단위의 Masking(Replace corrupted spans)을 통해 원래 텍스트를 순차적으로 복구하는 문제를 품으로써 사전 학습한다.
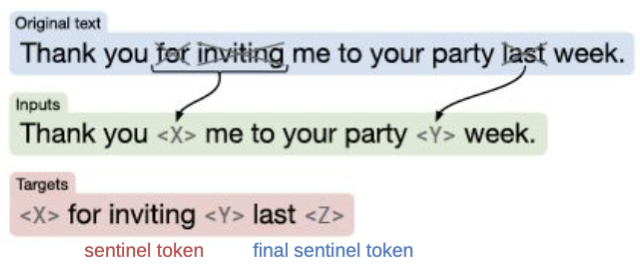
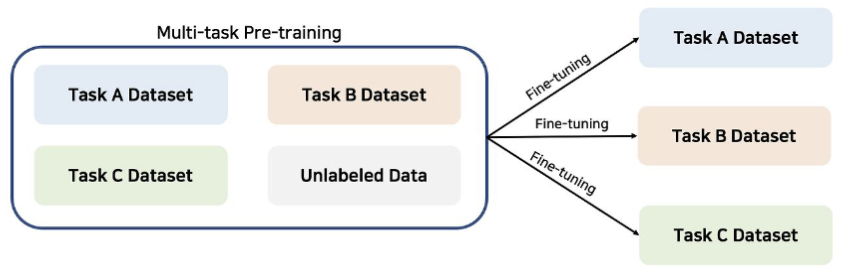
다중 작업 학습(Multi-task Pre-training)
사전 학습 데이터셋과 self-supervised task로 변환된 다운스트림 작업들의 데이터셋을 결합하여 동시에 학습한다. 이 방식은 모델이 다양한 작업을 한꺼번에 학습하면서 일반화 능력을 높일 수 있도록 돕는다. 사전 학습 데이터셋은 대규모로 수집된 일반적인 텍스트 데이터를 사용하고, 다운스트림 작업들은 구체적인 문제(예: 번역, 요약, 질의응답 등)에 맞춰 변환된 데이터셋을 의미한다.
Post-processing
Decoding: 디코더의 출력이 다음 스텝의 입력으로 들어가는 autoregressive 방식이다. 맨 처음 입력은 문장 시작을 뜻하는 스페셜 토큰이다.
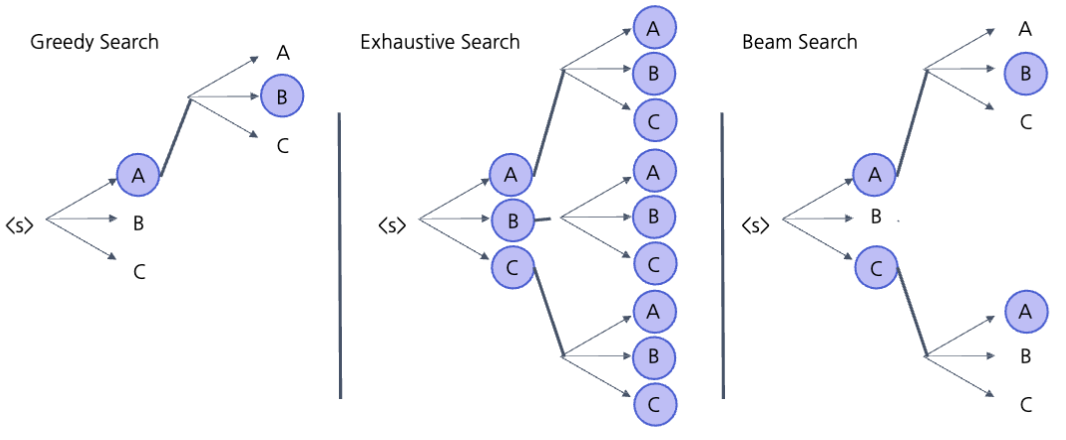
Searching: 보통 Beam Search나 Sampling 기법을 이용해 답변을 생성한다. Beam Search는 여러 후보를 동시에 탐색하여 가장 가능성이 높은 답변을 선택하는 방식이며, Sampling 기법은 확률적으로 다양한 답변을 생성해 더 창의적인 답변을 제공할 수 있다.