그래프 graph
그래프란? graph
그래프는 정점(Vertex)과 간선(Edge)으로 이루어진 자료구조이다.
그래프의 정점(Vertex)은 객체를 나타내며, 간선(Edge)은 객체 사이의 관계를 나타낸다.
간선(Edge)은 두 개의 정점(Vertex)을 연결하며, 방향성이 있는 경우도 있고, 없는 경우도 있다.
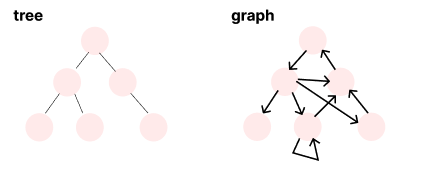
앞서배운 트리는 그래프의 한 형태이다
트리는 루트가 있고, 사이클이 없는! 아래로만 흐르는 방향 그래프다.
그래프는 트리와 같은 제약이 없다
그래프의 특성
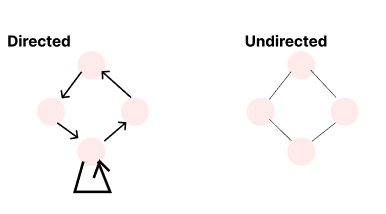
1. 그래프는 방향이 있을 수도 있고, 없을 수도 있다.
1) 방향이 있는 그래프 Directed Graph
화살표가 있는 그래프, 여기에 더해서 self edge라고 하는 자기자신을 가리키는 화살표가 있다.
(트리는 방향이 있는 그래프, 원래는 화살표를 그려줘야하지만, 항상 위에서 아래로 흐르니까 생략한다.)
2) 방향이 없는 그래프 Undirected Graph
화살표가 없다.
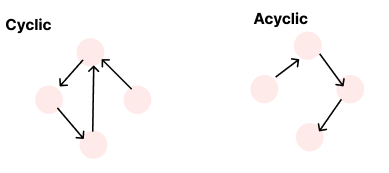
2. 그래프는 싸이클이 있을 수도 있고, 없을 수도 있다.
1) 싸이클이 있는 그래프 Cyclic
싸이클이 하나라도 있는 그래프
2) 싸이클이 없는 그래프 Acyclic
싸이클이 하나도 없는 그래프
그래프를 표현하는 방법
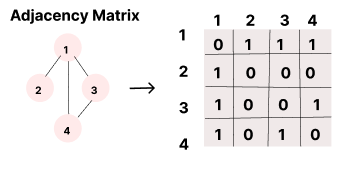
1. 인접 행렬 Adjacency Metrix
이차원 배열에 표현하는 방법
(그래프를 표에다가 표현하는 방법)
서로 연결된 노드들은 '1', 연결안된 노드들은 '0'으로 2차원 배열을 채우는 것
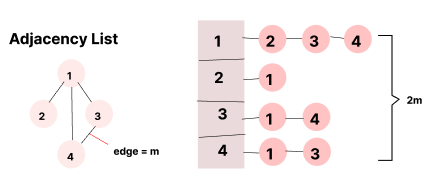
2. 인접 리스트 Adjacency List
(배열에 노드들을 나열하고 관계를 연결리스트로 표현하는 방법)
배열 방에다가 모든 노드들을 집어넣고, 각 배열 방에 있는 해당 노드와 인접한 노드들을 연결리스트로 쭉 나열해서 저장한다.
연결리스트로 나열 시 순서 상관없이 쭉 나열한다.
그리고 여기서 연결된 노드들은 총 몇개가 될까?
이 노드들은 관계를 나타내는 것!
간선(edge)의 개수를 m이라고 할때, 총 노드의 개수는 2m개이다.
왜? 예를 들면 3과 4를 봤을때 서로 연결되었다고 표시를 하잖아? 그래서 2배가 된다.
인접 행렬은 연결 가능한 모든 경우의 수를 저장하기 때문에 상대적으로 메모리를 많이 차지하므로 메모리를 효율적으로 사용하고 싶을 때 인접 리스트를 사용한다
그래프 검색
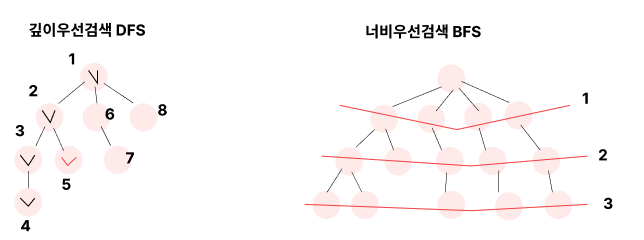
1. 깊이우선검색 Depth-First Search (DFS)
Binary Tree를 순회할때 사용했던, inorder, preorder, postorder 순회방법이 깊이우선검색에 속한다.
말 그대로, 하나의 child노드 방문했으면, 그 해당 child노드의 child노드, 그 child노드의 child노드들을 끝까지 파고드는 것
child노드들의 마지막 노드를 만날때까지 갔다가 다시 올라와서 옆의 형제노드들을 방문한다.
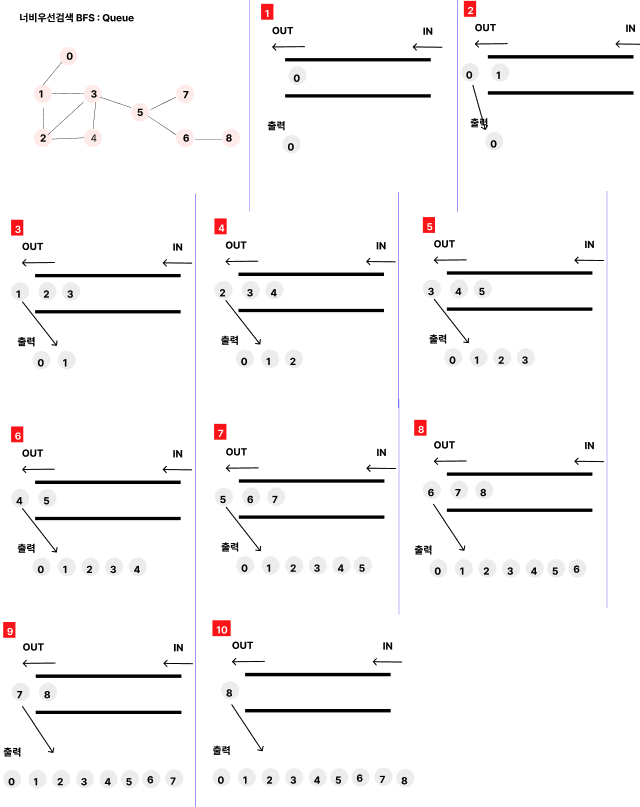
2. 너비우선검색 Breadth-First Search (BFS)
시작점에서 자기 child노드들을 먼저 다 방문하고, 그 다음의 자식의 자식을 방문하는 식으로 레벨 단위로 검색을 하는 것이 너비우선검색이다.
이걸 어떻게 구현하는지 보기
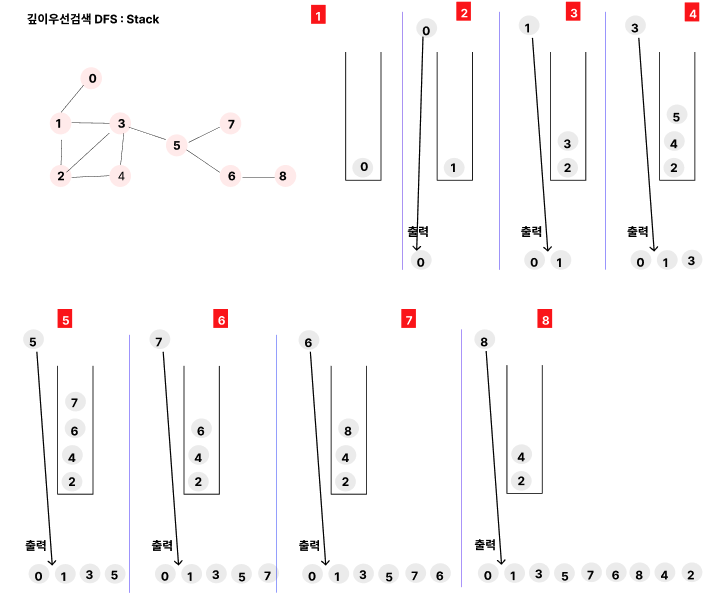
깊이우선검색DFS : Stack
깊이우선검색DFS
스택을 이용하여 구현한다.DFS를 진행하는 순서는 우선 stack을 만들고, 처음에는 스택에 노드가 없으므로, 시작할 노드를 일단 넣고, 그 다음부터 시작한다.
스택에서 노드를 하나 꺼내서 그 해당 child노드를 전부 스택에 넣고, 꺼낸 노드는 출력하는 것이다.
여기서 child노드를 스택에 넣을때는, 한번 스택에 담았던 노드는 다시 넣지 않는다.
너비우선검색BFS : Queue
너비우선검색BFS
큐를 이용하여 구현한다BFS를 진행하는 순서는 우선 Queue를 만들고, 처음에는 큐에 노드가 없으므로, 시작할 노드를 일단 넣고, 그 다음부터 시작한다.
큐에서 노드를 하나 꺼내서 그 해당 child노드를 전부 큐에 넣고, 꺼낸 노드를 출력한다.
여기서 child노드를 큐에 넣을때는, 한번 큐에 담았던 노드는 다시 넣지 않는다.
출력값
DFS(0) : 0 1 3 5 7 6 8 4 2
BFS(0) : 0 1 2 3 4 5 6 7 8
주의할점!
그래프는 트리가 아니기 때문에 꼭 0에서부터 시작할 필요가 없다
만약 3에서 시작했다고 하면,
예) DFS(3) : 3 5 7 6 8 4 2 1 0
예) BFS(3) : 3 1 2 4 5 0 6 7 8
<참고>
DFS를 구현할 때, 재귀호출을 사용하면 코드가 훨씬 간결해진다고 합니다~~
재귀함수를 이용한 순회방법은,
일단 노드에 방문하면 데이터를 출력하고 자식들을 순서대로 재귀로 호출해주는 것이다.
자식들이 호출을 받으면 마찬가지로 자기를 출력하고 자기 자식들을 재귀 호출하게 된다.
그렇게 호출을 받으면 반환하기 전에 자식들을 먼저 호출하기 때문에 재귀호출로 깊이우선검색이 가능하게 된다.
가중치 그래프
그래프의 각 간선(edge)에 가중치(weight)가 부여된 그래프를 의미한다.
각 간선(edge)의 가중치는 해당 간선을 통과하는데 필요한 비용, 거리, 시간 등을 나타내는 값이다.
가중치 그래프는 경로찾기, 최소 비용문제, 최단 경로 문제 등 다양한 문제에서 활용된다.
예를 들면, 도시 간의 도로망을 가중치 그래프로 모델링해 최소한의 비용으로 여행할 수 있는 경로를 찾거나, 내비게이션 같이 최단 경로를 찾는 등 활용할 수 있다.
대표적으로 다익스트라 알고리즘, 벨만-포드 알고리즘 등이 있다.
참고) 다익스트라 알고리즘
https://m.blog.naver.com/ndb796/221234424646
최단 경로를 찾는 알고리즘 중 하나로, 가중치 그래프에서 사용되는 알고리즘이다.
특히 음의 가중치를 가진 간선이 없는 경우에 사용할 수 있다.
여기서 음의 가중치란? 마이너스 값을 의미한다고 보면 된다.
현실 세계에서는 음의 간선 즉 마이너스값이 존재하지 않기 때문에 다익스트라는 현실 세계에서 사용하기 적합한 알고리즘이다.
비가중치 그래프
그래프에서 간선(edge)에 가중치가 없는 경우를 말한다.
즉, 그래프의 간선에는 가중치가 없으며, 모든 간선의 가중치는 1로 동일하게 처리된다.
비가중치 그래프는 가중치가 있는 그래프와는 달리 경로를 찾는 문제에서 가중치를 고려하지 않아 간단하게 처리할 수 있다.
대표적으로 BFS, DFS가 있다.
하지만, 비가중치 그래프에서도 간선의 방향성이 존재할 수 있으며,
이 경우에는 방향 그래프 Directed graph라고 부르고,
방향성이 없는 그래프는 무방향 그래프 Undirected graph라고 한다.
그래프와 트리 차이점
트리와 그래프는 모두 연결되어있는 객체들의 집합이지만, 사이클 여부, 루트노트, 간선방향, 구조 등에 대해서 차이점이 있다.
- 사이클 여부
트리는 사이클이 없는 비순환 그래프이다. 반면 그래프는 사이클이 있을 수도 있고 없을 수도 있다.
- 루트노드
트리는 루트노드가 있다. 이는 다른 모든 노드에 연결되어있는 유일한 노드이다. 반면에 그래프는 루트노드가 없다.
- 간선 방향
대부분의 트리는 방향성이 있는데, 루트 노드에서 리프노드로 가는 방향이다. 반면에 그래프는 방향성이 있을 수도 있고 없을 수도 있다.
- 구조
트리는 계층구조를 가진다. 그러나 그래프는 계층구조를 가지지 않을 수도 있다.
즉,
트리는
그래프의 특수한 형태 중 하나로, 사이클이 없고 방향성이 있으며, 계층 구조를 가지고, 루트노드가 있다.
그래프는
루트 노드가 없을 수도, 방향성이 없을 수도, 계층 구조를 가지지 않을 수도, 사이클이 있을 수도 있다.
