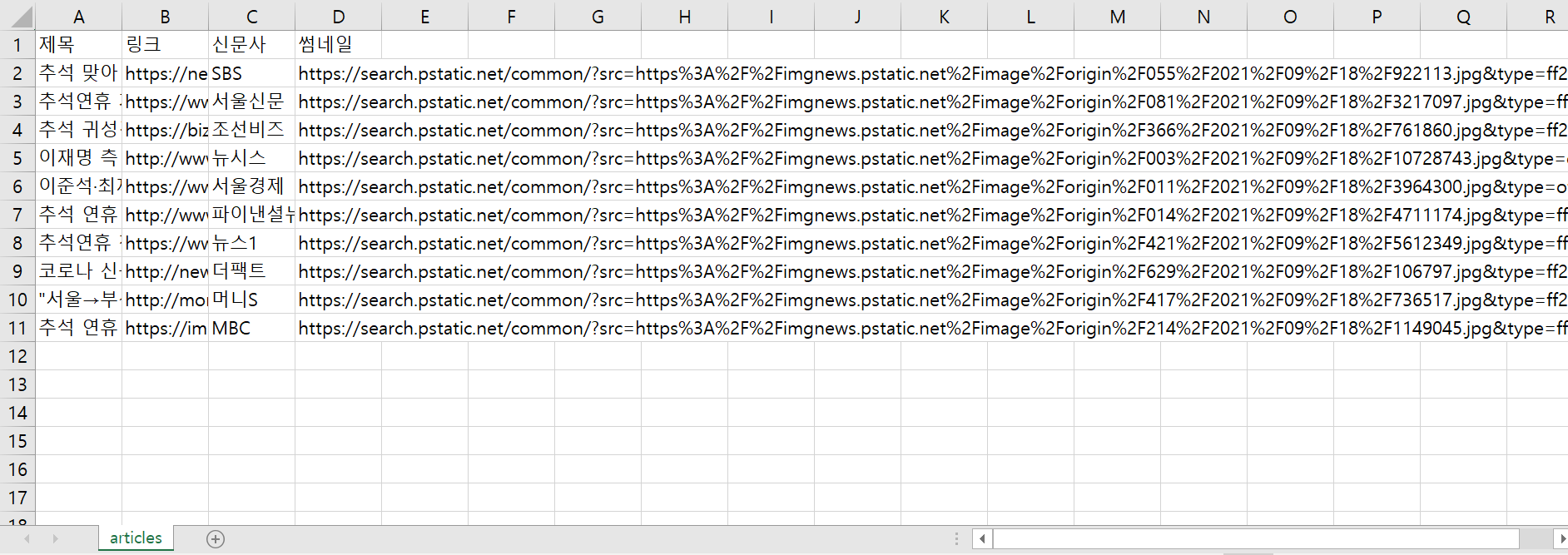
- 뉴스기사 크롤링
(필요한 라이브러리: openpyxl) 엑셀에 담게 도와준다- smtp 사용해보기
앞서 1주차에 했던 수업의 연장선으로 html의 구조에 대해 더 자세하게 배울 수 있었다. 구조에 따라 읽어오는 부분이 틀리기 때문에 그저 보고 그대로 베껴쓰는게 아닌 정말 구조에 대해 다시 정확히 짚어보고 갈 수 있는 시간이였다.
선생님 말씀대로 크롤링은 규칙이 없어서 이걸 찾아가는게 묘미라고 하셨는데 여러개를 적용시켜보며 해보면 그렇게 느껴지지 않을까 싶다 어렵게만 다가왔던 크롤링에 대해 조금 재미있다 라는 생각으로 바뀔 수 있었다
❤️ 뉴스기사
articles = soup.select("#main_pack > div.news.mynews.section._prs_nws > ul > li") for article in articles: a_tag = article.select_one("dl > dt > a") print(a_tag.text)
select를 말그대로 구조대로 크롤링 하기 때문에 구조를 정확히 복습하는 느낌이였다 😊
❤️ 뉴스기사 내 제목, 언론사명
for article in articles: a_tag = article.select_one('dl > dt > a') title = a_tag.text url = a_tag['href'] comp = article.select_one('dd.txt_inline > span._sp_each_source').text.split(' ')[0].replace('언론사','') print(title, url, comp)
이렇게 반복문을 사용해 html 구조에서 담긴 제목이나 url 언론사명도 따로 크롤링 할 수 있다.
