🎉기본 연산
b = a # a를 b에 넣는다
a = a + 1 # a+1을 다시 a에 넣는다
num1 = a*b # a*b의 값을 num1이라는 변수에 넣는다
num2 = 99 # 99의 값을 num2이라는 변수에 넣는다- 변수의 이름은 아무렇게나 지어도 사용은 가능하지만 유지보수를 생각해서 다음에 작업할 누구든 알아볼 수 있어야 유지보수가 용이해진다
🎉자료형
-
숫자,문자형
num = 12 # 숫자가 들어갈 수도 있고, is_number = True # True 또는 False -> "Boolean"형이 들어갈 수도 있습니다. -
리스트 형 (Javascript의 배열형과 동일)
a_list = [] a_list.append(1) # 리스트에 값을 넣는다 a_list.append([2,3]) # 리스트에 [2,3]이라는 리스트를 다시 넣는다 # a_list의 값은? [1,[2,3]] # a_list[0]의 값은? 1 # a_list[1]의 값은? [2,3] # a_list[1][0]의 값은? 2 -
Dictionary 형 (Javascript의 dictionary형과 동일)
a_dict = {} a_dict = {'name':'bob','age':21} a_dict['height'] = 178 # a_dict의 값은? {'name':'bob','age':21, 'height':178} # a_dict['name']의 값은? 'bob' # a_dict['age']의 값은? 21 # a_dict['height']의 값은? 178 -
Dictionary 형과 List형의 조합
people = [{'name':'bob','age':20},{'name':'carry','age':38}] # people[0]['name']의 값은? 'bob' # people[1]['name']의 값은? 'carry' person = {'name':'john','age':7} people.append(person) # people의 값은? [{'name':'bob','age':20},{'name':'carry','age':38},{'name':'john','age':7}] # people[2]['name']의 값은? 'john'자료형은 자바와 별 다를바 없어서 배우기 간단했다
Dictionary형과 list 헷갈렸던 묶은 때가 이제야 풀렸다
🎉조건문
if age > 20:
print('성인입니다') # 참이면 성인입니다를 출력
else:
print('청소년이에요') # 거짓이면 청소년이에요를 출력
🎉반복문
파이썬에서의 반복문은, 리스트의 요소들을 하나씩 꺼내쓰는 형태
- 리스트부터 알아보자
fruits = ['사과','배','감','귤']
for fruit in fruits:
print(fruit)- 과일 갯수
fruits = ['사과','배','배','감','수박','귤','딸기','사과','배','수박']
count = 0
for fruit in fruits:
if fruit == '사과':
count += 1
print(count)
- Dictionary 응용
people = [{'name': 'bob', 'age': 20},
{'name': 'carry', 'age': 38},
{'name': 'john', 'age': 7},
{'name': 'smith', 'age': 17},
{'name': 'ben', 'age': 27}]
# 모든 사람의 이름과 나이를 출력해봅시다.
for person in people:
print(person['name'], person['age'])
# 이번엔, 반복문과 조건문을 응용해봅시다.
# 20세 보다 많은 사람만 출력하기
for person in people:
if person['age'] > 20:
print(person['name'], person['age'])- 파이썬 내장함수 응용
-- 문자열 자르기
txt = 'sparta@gmail.com'
result = txt.split('@')[1].split('.')[0]
print(result)-- 문자열 바꾸기
txt = 'sparta@gmail.com'
result = txt.replace('gmail','naver')
print(result)🎉웹 스크랩핑(= 크롤링)
- 신문 스크래핑 📰✂️해보셨나요? 신문에서 원하는 기사만 오려서 정보를 추리는 것을 스크래핑이라고 하죠? 웹 스크래핑도 똑같습니다.
웹 스크래핑(web scraping)은 웹 페이지에서 우리가 원하는 부분의 데이터를 수집해오는 것입니다. (한국에서는 같은 작업을 크롤링 crawling 이라는 용어로 혼용해서 씁니다.)
스파르타코딩 노션에 정리된 내용 그대로가 이해가 너무 쉽게 되어있기때문에 읽고 따라하기 최곤거 같다
우선 라이브러리 다운로드를 해야하고 이를 이용해서
원하는 연예인 사진을 스크래핑 해볼 수 있었다
- dload
- bs4
- selenium
import dload
//이미지를 쉽게 저장할 수 있게 도와주는 라이브러리
from bs4 import BeautifulSoup
from selenium import webdriver
//크롬과 버전을 맞춰 다운해줘야한다
import time
driver = webdriver.Chrome('chromedriver') # 웹드라이버 파일의 경로
driver.get("검색엔진에 원하는 연예인 검색 페이지")
time.sleep(5) # 5초 동안 페이지 로딩 기다리기
req = driver.page_source
soup = BeautifulSoup(req, 'html.parser')
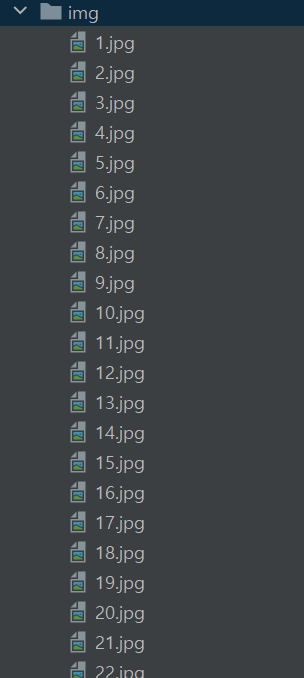
thumbnails = soup.select("#imgList > div > a > img") // 페이지 개발자도구 이미지 select copy
i=1
for thumbnail in thumbnails:
//thumbnail에 thumbnails를 담아서
src = thumbnail["src"]
dload.save(src, f'img/{i}.jpg')
//img라는 폴더를 만들어놓고 그 폴더에 검색결과이미지를
i+=1
//i값 증가하면서
1,2,3,.... 검색결과 원하는 이미지들을 저장
driver.quit() # 끝나면 닫아주기 페이지도 닫힌다