1. 비지도학습
: 정답(label)없이 데이터의 구조, 패턴, 관계를 학습하는 방법
| 구분 | 지도학습 | 비지도학습 |
|---|---|---|
| 정답(y) | 있음 | 없음 |
| 목표 | 예측 | 구조 발견 |
| 평가 | 정확도, RMSE 등 | 명확하지 않음 |
| 예시 | 분류, 회귀 | 군집, 차원축소 |
2. 군집(Clustering)
: 비슷한 데이터끼리 자동으로 묶는 것
정답은 없지만 데이터 내부의 자연스러운 그룹 구조를 찾는 것이 목적!
1) 거리 기반 - K-Means
: 각 클러스터의 중심(centroid)을 기준으로 데이터를 나누는 모델
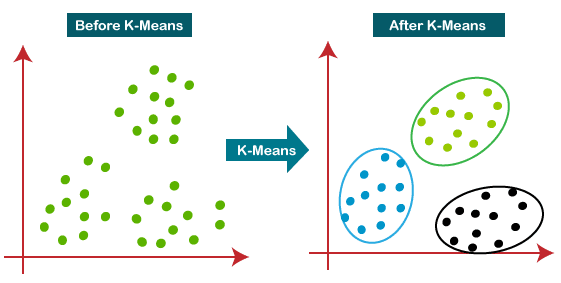
- 동작 과정
- 클러스터 개수 K 지정
- 랜덤하게 K개의 중심점 초기화
- 각 데이터를 가장 가까운 중심에 할당
- 중심을 해당 클러스터 평균으로 업데이트
- 3~4번 반복
- 수식: 각 점과 해당 클러스터 중심 간 거리 제곱합(MSE) 최소화
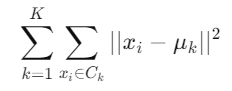
- 장점: 빠르고 구현하기 쉬우며 대용량에 적합함.
- 단점: K를 미리 정해야하고 구형(원형) 클러스터에만 잘 맞으며 이상치에 민감함.
2) 계층 기반 - Hierarchical Clustering
: 데이터를 트리 구조로 묶는 모델
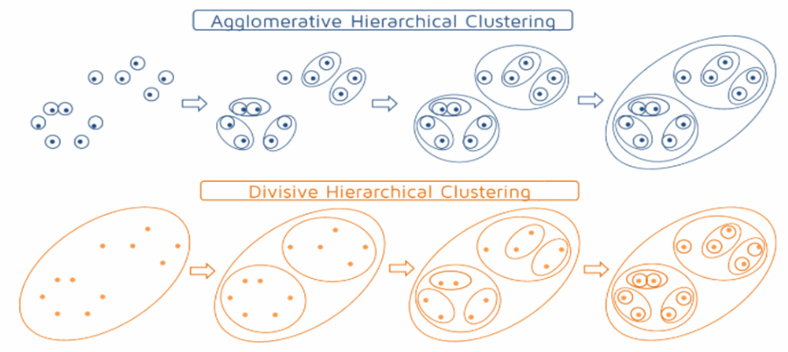
-
Agglomerative(Bottom-up) -> 실무에서 주로 사용
- 처음엔 모든 점이 개별 클러스터
- 가장 가까운 것끼리 계속 병합
-
Divisive(Top-down)
- 하나의 큰 클러스터에서 시작
- 계속 쪼갬.
-
거리 기준(Linkage 방식)
- Single linkage -> 최소 거리
- Complete linkage -> 최대 거리
- Average linkage -> 평균 거리
- Ward -> 분산 증가 최소화
-
K를 미리 정하지 않아도 되고 덴드로그램으로 시각화 가능
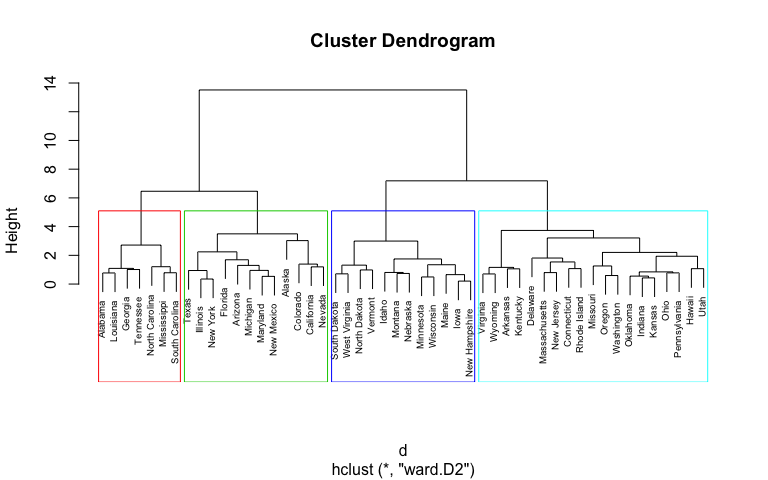
-
계산량이 크고 큰 데이터에 비효율적임
-
데이터가 많지 않고 계층 구조를 보고 싶을 때 주로 사용
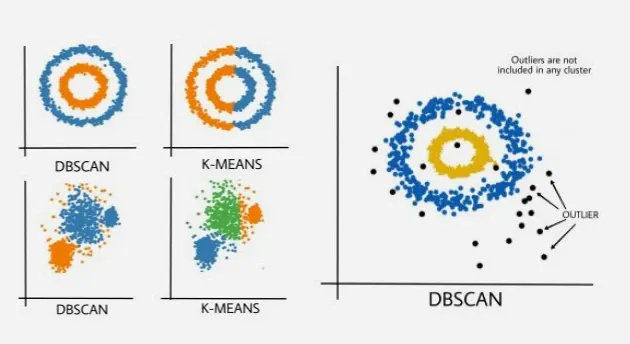
3) 밀도 기반 - DBSCAN
: 밀도가 높은 영역을 하나의 클러스터로 보는 모델
-
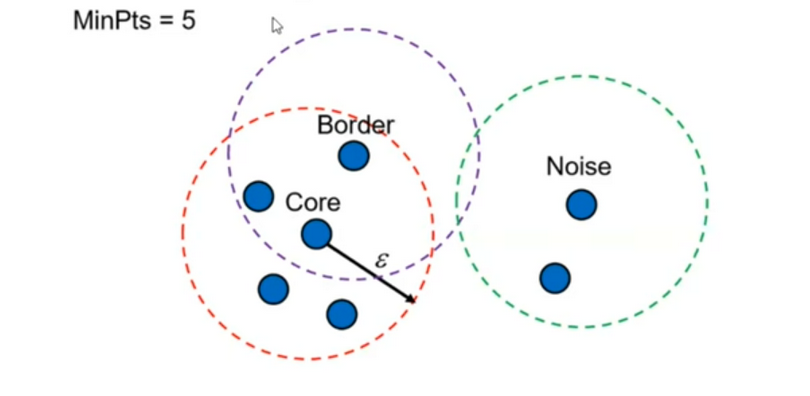
ε (입실론): 반경, MinPts: 최소 이웃 개수
-
Core point: 이웃이 충분히 많음, Border point: 코어 근처, Noise: 어디에도 속하지 않음
-
클러스터 개수 자동 결정, 이상치 자동 탐지, 비구형 클러스터 가능
-
입실론 선택 어려우며 밀도 차이가 큰 데이터에 약함
-
이상치 탐지가 중요할 때와 클러스터 모양이 복잡할 때 주로 사용
4) 확률 기반 - Gaussian Mixture Model(GMM)
: 각 클러스터가 "가우시안 분포"라고 가정
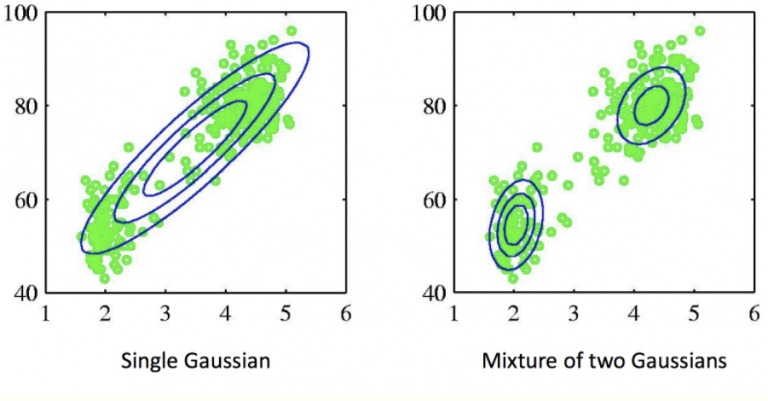
K-Means는 "딱 잘라 나누는"방식이라면 GMM은 각 점이 각 클러스터에 속할 확률을 가짐 -> soft assignment(확률 기반 소속)
- 학습 방식 (EM 알고리즘 사용)
- E-step: 각 점의 소속 확률 계산
- M-step: 평균/공분산 업데이트
- 반복
- 타원형 클러스터와 확률 해석 가능
- K 필요하고 계산 비용이 크며 초기값...?
정리
| 알고리즘 | 기준 | K 필요 | 이상치 처리 | 모양 |
|---|---|---|---|---|
| K-Means | 거리 | O | 약함 | 원형 |
| Hierarchical | 거리 | 선택적 | 약함 | 다양 |
| DBSCAN | 밀도 | X | 강함 | 자유 |
| GMM | 확률 | O | 보통 | 타원형 |
3. 차원축소(Dimensionality Reduction)
- 압축: 정보를 최대한 유지하며 차원을 줄이는 과정 -> 모델 학습/저장/노이즈 제거
- 시각화(2D/3D 구조 보기) -> 군집/이상치/구조 탐색
1) PCA(Principal Component Analysis)
: 데이터를 가장 많이 퍼져있는 방향(분산 최대)로 회전시켜, 중요한 축부터 남기는 선형 차원축소
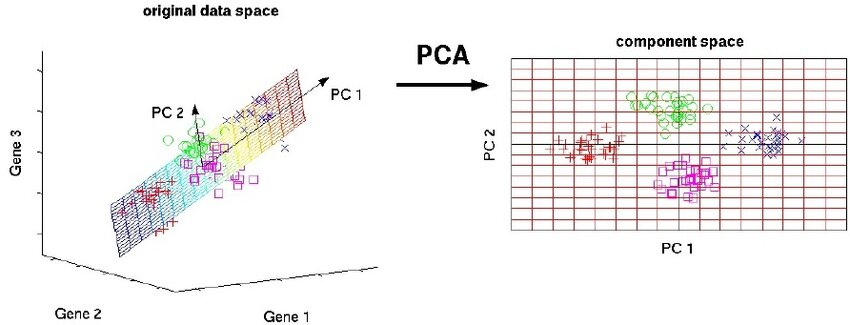
- 분산이 가장 큰 방향을 찾기 -> 직교하는 다음 방향 찾기 -> 상위 몇 개 축만 남기기
- 노이즈를 제거하고 다중공산성을 완화하며 차원 줄여서 모델 안정화시키고 빠른 압축
- 선형 구조만 잡고 곡선/비선형 구조는 못 잡고 스케일에 민감하여 표준화 필수
- 수치형 tabular 데이터, 모델 전처리, 노이즈 제거, 속도 개선에서 주로 사용
2) t-SNE
: 가까운 점은 2D에서도 가깝게 만들도록, 국소 이웃 구조를 보존하는 시각화 특화 비선형 차원축소
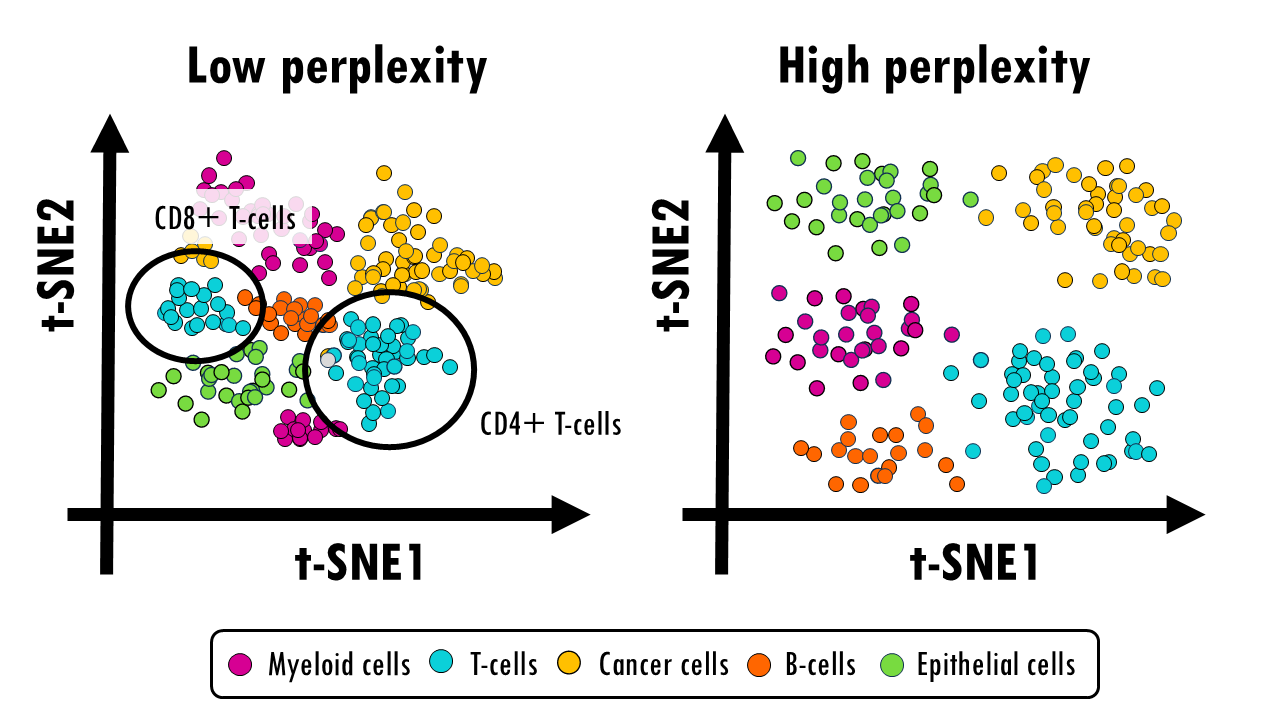
- 전역 구조보다 로컬 구조에 집중
- 가까운 점끼리는 확률적으로 높은 유사도를 가지며 이 확률을 저차원에서도 유지
- 클러스터 간 거리가 진짜 거리가 아니고 전역 구조 왜곡 가능하기 때문에 시각화용으로 자주 쓰임(모델 전처리X)
- 군집 구조 탐색하고 임베딩 시각화하고 라벨 품질 점검할 때 주로 쓰임
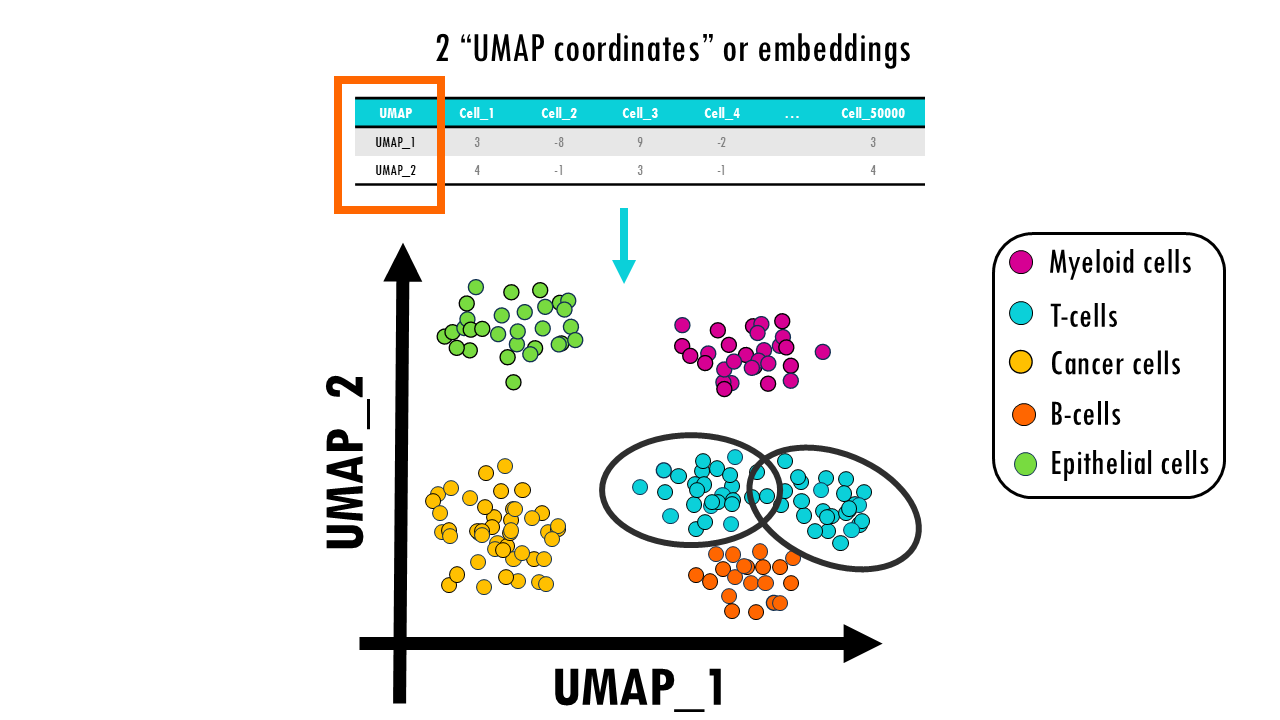
3) UMAP
: t-SNE처럼 이웃 구조를 보존하면서도, 더 빠르고 전역 구조도 어느 정도 유지하는 비선형 차원축소
- 데이터가 어떤 "곡면" 위에 있다고 가정
- 핵심 파라미터
- n_neighbors -> 로컬 vs 전역 균형
- min_dist -> 군집이 얼마나 뭉칠지
- 대규모 데이터 시각화하고 임베딩 생성하고 클러스터링 전 단계에서 주로 사용
| 항목 | t-SNE | UMAP |
|---|---|---|
| 속도 | 느림 | 빠름 |
| 전역 구조 | 약함 | 조금 더 유지 |
| transform | 약함 | 지원 좋음 |
| 실무 활용 | 시각화 중심 | 임베딩/클러스터링 |
4) AutoEncoder
: 신경망으로 입력 -> 압축 -> 복원을 학습해서, 압축 공간(latent)을 차원축소 표현으로 쓰는 방식
입력 x -> Encoder -> 압축된 표현 z(latent) -> Decoder -> 복원
- 복잡한 비선형 구조 학습이 가능하며 이미지/텍스트가 강력하고 임베딩 생성에 좋음.
- 과적합 위험이 있고 튜닝이 필요하며 학습 비용이 크다는 단점이 있음.
- 이미지, 고차원 임베딩, 비선형 구조가 강한 데이터, 재구성 오차 기반 이상치 탐지에서 주로 사용
| 항목 | PCA | AutoEncoder |
|---|---|---|
| 구조 | 선형 | 비선형 가능 |
| 학습 | 고유값분해 | 신경망 학습 |
| 복잡성 | 낮음 | 높음 |
| 데이터 요구량 | 적어도 됨 | 많을수록 좋음 |
정리
| 방법 | 선형 | 목적 | 빠름 | 시각화 | 전처리 |
|---|---|---|---|---|---|
| PCA | O | 압축 | 매우 빠름 | 보통 | 좋음 |
| t-SNE | X | 시각화 | 느림 | 매우 좋음 | 거의 안 씀 |
| UMAP | X | 시각화/임베딩 | 빠름 | 매우 좋음 | 가능 |
| AutoEncoder | X | 압축/임베딩 | 느림 | 보통 | 가능 |
4. 밀도추정/이상치 탐지
이상치 탐지란?
: 데이터의 일반적인 패턴에서 벗어난 "비정상적인 관측치"를 찾는 문제
- 이상치를 정의하는 3가지 관점
- 고립되기 쉬운 점 (Isolation)
- 정상 영역 밖에 있는 점 (Boundary)
- 주변보다 밀도가 낮은 점 (Density)
1) Isolation Forest
정상 데이터는 뭉쳐있고 랜덤하게 분기해도 쉽게 혼자 남지 않는 반면, 이상치는 외딴 곳에 있고 몇 번만 나눠도 혼자 떨어짐 -> 분리 경로가 짧음
- 동작 원리
- 랜덤으로 feature 선택
- 랜덤으로 split value 선택
- 데이터를 분리
- 이 과정을 트리 형태로 반복
- 어떤 점이 고립되기까지의 깊이(path length) 계산
-> 평균 path length가 짧으면 이상치
- 장점: 빠르고 고차원에서도 비교적 잘 작동하고 스케일 크게 문제 안 되고 기본 baseline으로 좋음.
- 단점: contamination(이상치 비율) 설정이 필요하고 아주 복잡한 경계 표현은 어려움.
- 대규모 tabular 데이터, 빠른 이상치 후보 추출, baseline 모델에 주로 사용
2) One-Class SVM
: "정상 데이터만 감싸는 경계를 학습하고 그 밖은 이상치다."
- 커널 공간에서 정상 데이터 대부분을 포함하는 최대 마진 경계 찾기
- 핵심 파라미터
- ν (nu): 이상치 비율 상한
- gamma: 커널 복잡도 조절
- 유연한 비선형 경계 가능하고 정상 분포가 명확할 때 강력
- 느리고 스케일링 필수고 파라미터 민감하고 대용량 부적합함.
- 데이터 크지 않고 정상 패턴이 명확하고 경계 기반 탐지 필요할 때 주로 쓰임
3) LOF
: "내 주변보다 밀도가 낮으면 이상치" -> 로컬 밀도 비교
- 동작 방식
- k개 이웃 찾기
- 이웃들의 밀도 계산
- 나의 밀도와 이웃 밀도 비교
- 비율이 크면 이상치
- 로컬 이상치 탐지에 강하고 복잡한 분포에서도 유리
- KNN 기반으로 느리고 고차원에서 거리 의미 약해지고 새 데이터에 대해 transform 불편
- 군집 여러 개 존재하고 특정 클러스터 내부에서 튀는 점 탐지할 때 주로 사용
정리
| 항목 | Isolation Forest | One-Class SVM | LOF |
|---|---|---|---|
| 철학 | 고립 | 경계 | 밀도 |
| 속도 | 빠름 | 느림 | 중간 |
| 대규모 | 가능 | 어려움 | 어려움 |
| 고차원 | 비교적 강함 | 민감 | 약함 |
| 이상치 종류 | 전역 | 경계 밖 | 로컬 |
| baseline 추천 | ⭐⭐⭐ | ⭐ | ⭐⭐ |
5. 연관규칙
: 거래(transaction) 데이터에서 "A가 있으면 B도 같이 있다" 같은 패턴을 찾는 것
| 거래 ID | 상품 목록 |
|---|---|
| T1 | {우유, 빵, 버터} |
| T2 | {우유, 기저귀} |
| T3 | {빵, 버터} |
| T4 | {우유, 빵} |
이렇게 집합 형태가 기본 구조임
- Support(지지도): 전체 거래 중 해당 아이템셋이 등장한 비율
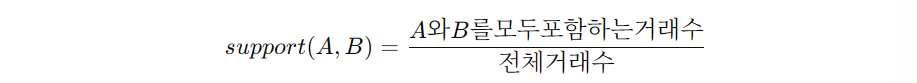
- Confidence(신뢰도): A를 사면 B도 살 확률
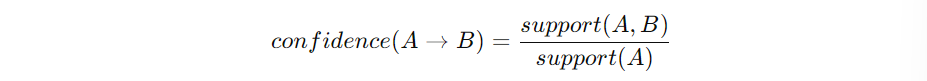
- Lift(향상도): 원래 B가 많이 팔리는 상품이라서 그런 건 아닌지 보정
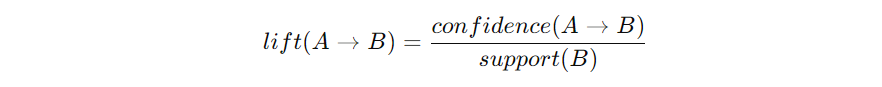
1) Apriori
: 자주 등장하는 아이템셋의 부분집합도 자주 등장
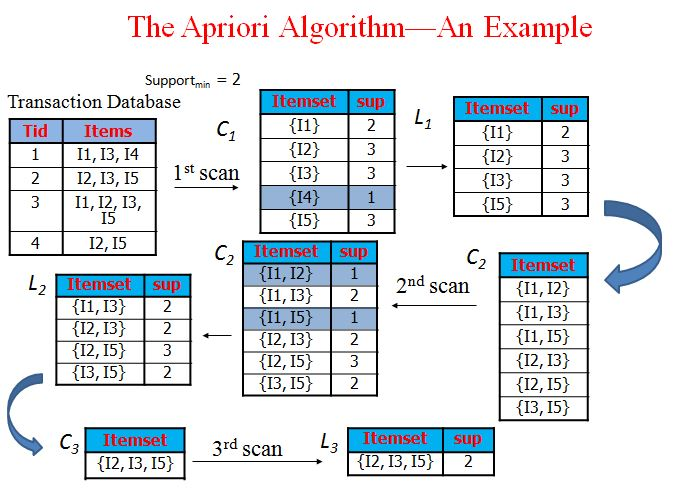
- 동작 과정
- 1-아이템셋 중 support >= min_support인 것 찾기
- 이들을 조합해 2-아이템 후보 생성
- support 검사 -> 살아남은 것만 유지
- 3-아이템 후보 생성
- 반복
- 개념 이해가 쉽고 구현이 직관적
- 후보가 폭발적으로 증가 가능하고 min_support가 낮으면 계산량 폭증하고 아이템 종류 많으면 매우 느림
- 데이터가 크지 않고 이해 목적의 baseline에서 주로 사용
2) FP-Growth
: 후보를 만들지 않고 거래를 트리 구조로 압축해 빈발 패턴을 찾는 과정
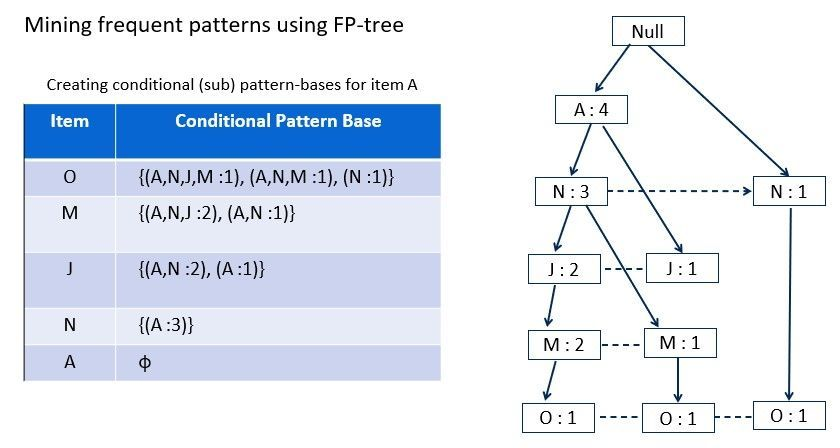
Apriori는 후보를 생성하고 후보 하나하나 support 검사를 하는 반면, FP-Growth는 전체 거래를 FP-tree로 압축하고 공통 prefix를 공유하고 후보 폭발을 줄임
- Apriori보다 빠르고 대규모 데이터에 적합하고 후보 폭발을 방지
- 구현 복잡하고 이해 난이도 높음
정리
| Apriori (후보 만들고 검사) | FP-Growth (압축해서 탐색) |
|---|---|
| 1️⃣ 1개짜리부터 개수 세기 | 1️⃣ 1개짜리 개수 세기 (같음) |
| 우유4, 빵4, 버터2, 기저귀2 | 우유4, 빵4, 버터2, 기저귀2 |
| -------------------------------- | -------------------------------- |
| 2️⃣ 2개 조합 전부 만들기 | 2️⃣ 거래를 빈도순으로 정렬 |
| 우유-빵, 우유-버터, 우유-기저귀, 빵-버터, 빵-기저귀… | 예: 우유→빵→버터 |
| -------------------------------- | -------------------------------- |
| 3️⃣ 각 조합마다 등장 횟수 전부 다시 계산 | 3️⃣ 공통 prefix를 하나의 경로로 압축 |
| 우유-빵(3) ✔ | 우유(4) |
| 우유-기저귀(2) ✔ | └─ 빵(3) |
| 빵-버터(2) ✔ | ├─ 버터(1) |
| 나머지 탈락 | └─ 기저귀(1) |
| -------------------------------- | -------------------------------- |
| 4️⃣ 3개 조합 다시 생성하고 검사 | 4️⃣ 트리에서 조건부 패턴 바로 추출 |
| 우유-빵-기저귀(1) 탈락 | 우유-빵(3), 우유-기저귀(2), 빵-버터(2) 바로 계산 |
| -------------------------------- | -------------------------------- |
| 핵심: 후보를 계속 만들어서 검사 | 핵심: 트리로 압축해서 후보 폭발 방지 |
| 항목 | Apriori | FP-Growth |
|---|---|---|
| 방식 | 후보 생성 후 검사 | 트리 압축 |
| 속도 | 느릴 수 있음 | 빠름 |
| 후보 폭발 | 있음 | 거의 없음 |
| 구현 난이도 | 쉬움 | 어려움 |
| 실무 사용 | 적음 | 많음 |
연관규칙의 한계
인과관계가 아니고 단순 동시 발생 패턴일 뿐임!
lift 해석 주의가 필요하고 너무 낮은 support는 노이즈일 수 있음!
