
File
정의
- 논리적인 저장 단위로, 관련된 정보 자료들의 집합에 이름을 붙인 것이다.
- 일반적으로 레코드(Record) 혹은 블록(Block)단위로 비휘발성 보조기억장치에 저장된다.
구조
- MetaData : 데이터 영역에 기록된 파일의 이름, 위치, 크기, 시간정보, 삭제유무 등의 파일 정보
- 데이터 영역 : 파일의 데이터
File Attribute (MetaData)
- 파일을 관리하기 위한 각종 정보들이다.
- 파일 자체의 내용은 아니다.
- Name : 사람이 읽을 수 있는 형태의 유일한 정보
- Identifier : 파일 시스템 내부의 유일한 식별 태그(이름)
- Type : 다양한 종류의 File을 지원하기 위해 필요
- Location : 장치내에서 파일의 위치를 위한 포인터
- Size : 현재 파일의 크기
- Protection : 읽기, 쓰기, 실행에 대한 권한 제어
- Time, date, and user identification : 파일 사용에 대한 보호, 보안, 모니터링을 위한 데이터
File System
정의
- 컴퓨터에서 파일이나 자료를 쉽게 발견할 수 있도록, 유지 및 관리하는 방법이다.
- 저장매체에는 수많은 파일이 있기 때문에, 이런 파일들을 관리하는 방법을 말한다.
특징
- 커널 영역에서 동작
- 파일 CRUD 기능을 원활히 수행하기 위한 목적
- 계층적 Directory 구조를 가짐
- 디스크 파티션 별로 하나씩 둘 수 있음
CRUD : 대부분의 컴퓨터 소프트웨어가 가지는 기본적인 데이터 처리 기능인 Create(생성), Read(읽기), Update(갱신), Delete(삭제)를 묶어서 일컫는 말이다.
역할
- 파일 관리
- Create, Write, Read, Reposition, Delete(파일 삭제), Truncate(파일 내부 내용 삭제)
- 보조 저장소 관리
- 파일 무결성 메커니즘
- 파일 원본이 조작되었는지 확인하는 것
- 접근 방법 제공
개발 목적
- 하드디스크와 메인 메모리 사이의 속도 차이를 줄이기 위함
- 파일 관리
- 하드디스크의 용량을 효율적으로 이용하기 위함
Partition (파티션)
정의
- 연속된 저장 공간을 하나 이상의 연속되고 독립적인 영역으로 나누어 사용할 수 있도록 정의한 규약이다.
- 하나의 물리적 디스크 안에 여러 파티션을 두는 게 일반적이다.
- 하지만, 여러 물리적 디스크를 하나의 파티션으로 구성하기도 한다.
Access Methods (접근 방법)
Sequential Access (순차 접근)
- 가장 단순한 접근 방법으로 파일의 정보가 레코드 순서대로 처리된다.
- 카세트 테이프를 사용하는 방식과 동일하다.
- 현재 위치에서 읽거나 쓰면 offset이 자동으로 증가한다.
- 뒤로 돌아가기 위해서는, 되감기가 필요하다.
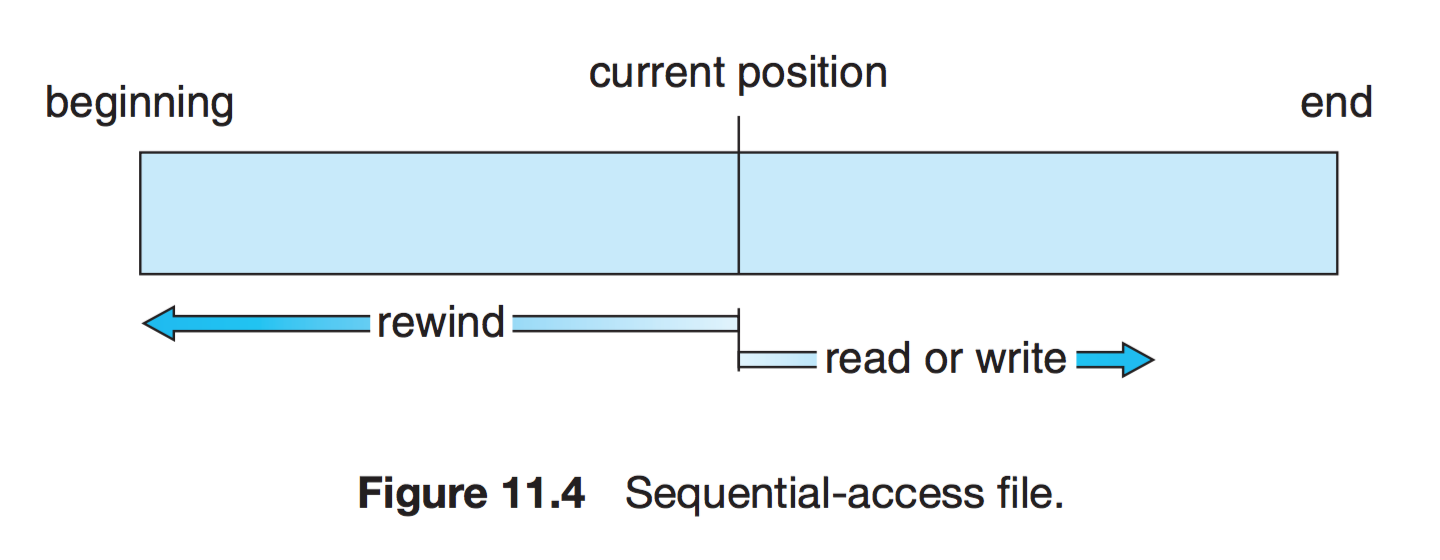
- 제공하는 연산
- read next : 오직 앞의 방향으로만 작동한다.
- write next : 오직 앞의 방향으로만 작동한다.
- reset : Pointer 초기화
Direct Access (직접 접근)
- 파일의 레코드를 임의의 순서로 접근 할 수 있다.
- 순서에 상관없이, 빠르게 레코드를 읽고, 쓸 수 있다.
- 제공하는 연산
- read n : n번째에 접근
- write n : n번째에 접근
- position to n : n번째 위치로 Pointer를 이동한다.
- rewrite n
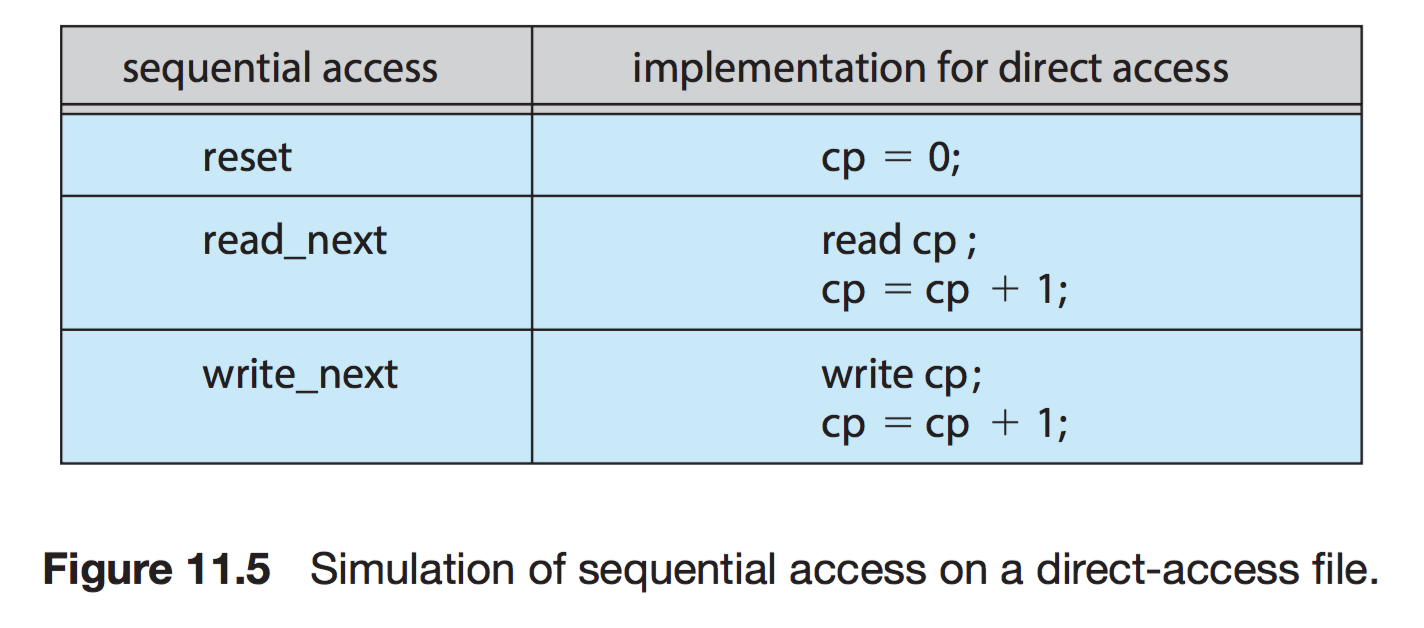
- 현재 위치를 가리키는 cp변수만 유지하면, 순차 파일 기능을 쉽게 구현이 가능하다.
- 대규모 정보를 접근할 때 유용하기 때문에 '데이터 베이스'에 활용된다.
Index Access (색인 접근)
- 파일에서 레코드를 찾기 위해 색인을 먼저 찾고 대응되는 포인터를 얻는다.
- 이를 통해 파일에 직접 접근하여 원하는 데이터를 얻을 수 있다.
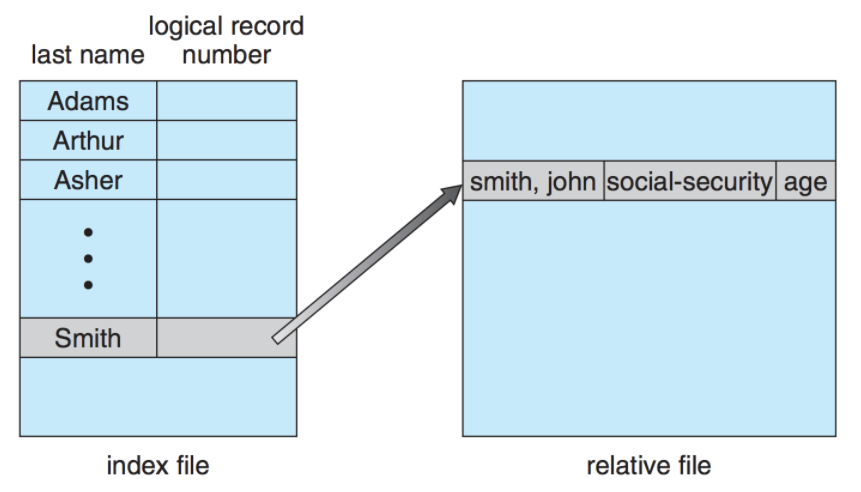
- 크기가 큰 파일을 입•출력 탐색할 수 있게 도와주는 방법이다.
Directory Structure (디렉터리 구조)
정의
- Directory는 파일의 메타데이터 중 일부를 보관하고 있는 일종의 특별한 파일이다.
- 해당 Directory에 속한 파일 이름과 속성들을 포함하고 있다.
기능
- Search (파일 찾기)
- Create (파일 생성)
- Delete (파일 삭제)
- List (Directory 나열)
- Rename (파일 이름 수정)
- Traverse (파일 시스템 순회)
구성
- Efficiency : Directory는 파일을 빠르게 탐색할 수 있어야 한다.
- Naming : 적절한 이름으로 사용자들이 편리하게 사용할 수 있으면 좋을 것이다.
- Grouping : 파일들을 적절한 분류로 그룹화 해두면 사용하기 편리할 것이다.
이를 위해 Directory의 논리적 구조를 정의하는 여러 방법들이 있다.
Single Level (1단계) Directory
- 가장 간단한 구조
- 모든 파일들이 디렉터리 밑에 존재하는 형태이다.
- 파일들은 서로 유일한 이름을 갖습니다.
- 서로 다른 사용자라도, 같은 이름의 파일들을 사용할 수 없습니다.
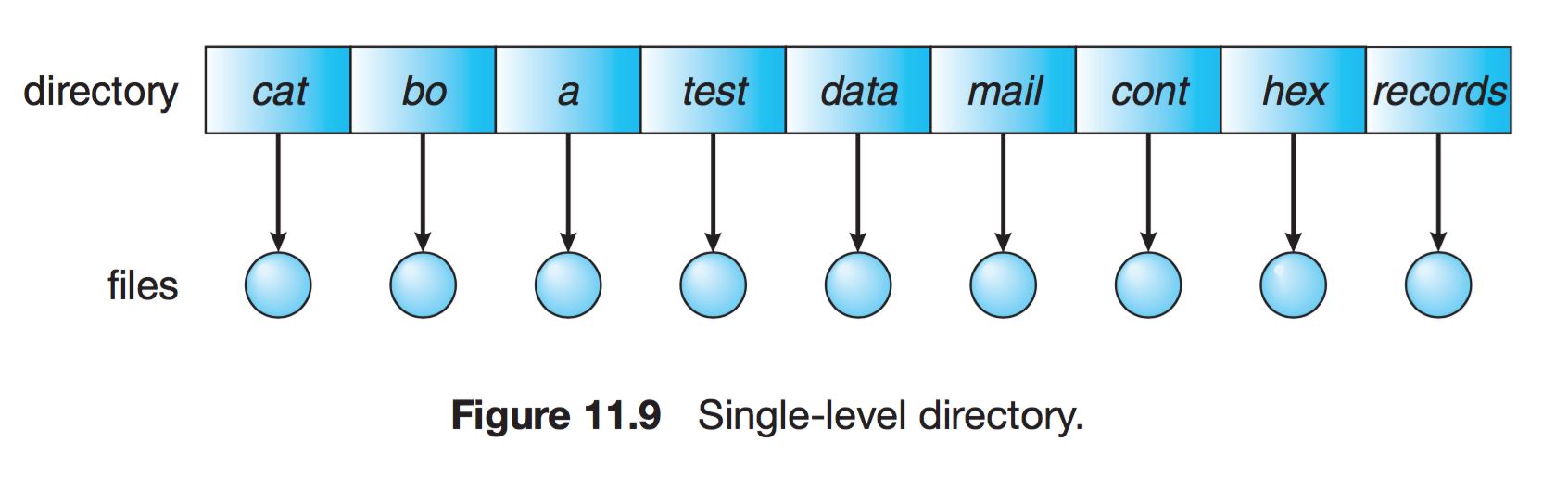
- 파일이 많아지거나 다수의 사용자가 사용하는 시스템 이라면, 문제가 발생합니다.
- Naming Problem
- Grouping Problem : 시스템에 오직 1개의 Directory만 있기 때문에 Grouping이 불가능
Two Level (2단계) Directory
- 각 사용자별로 별도의 디렉터리를 갖는 형태이다.
- 서로 다른 사용자들은 동일한 파일의 이름을 사용할 수 있습니다.
- 효율적인 탐색 가능 : 각 파일들은 경로 명으로 찾아가야 합니다.
- 종류
- UFD : 자신만의 사용자 파일 디렉터리
- MFD : 사용자의 이름과 계정 번호로 색인되어 있는 디렉터리. 각 엔트리는 사용자의 UFD를 가리킨다.
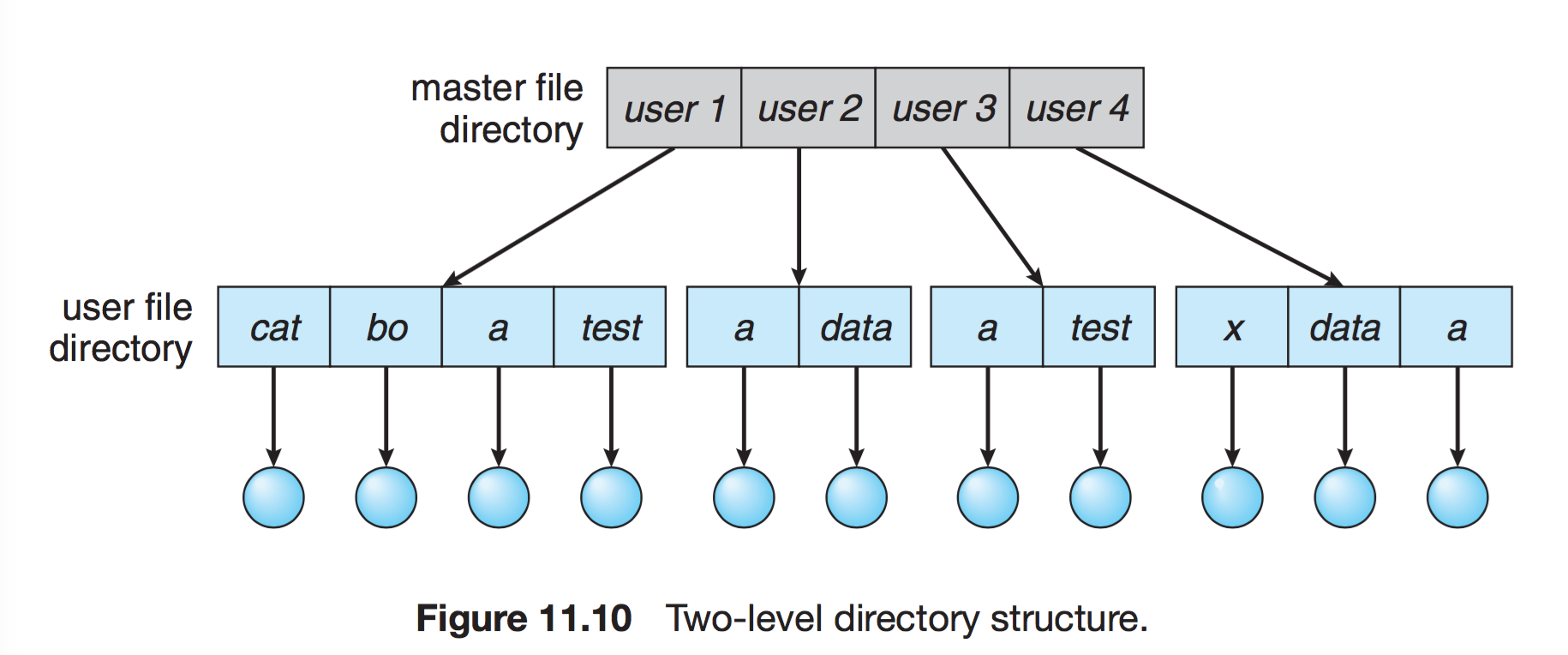
- Grouping 기능이 존재하지 않습니다.
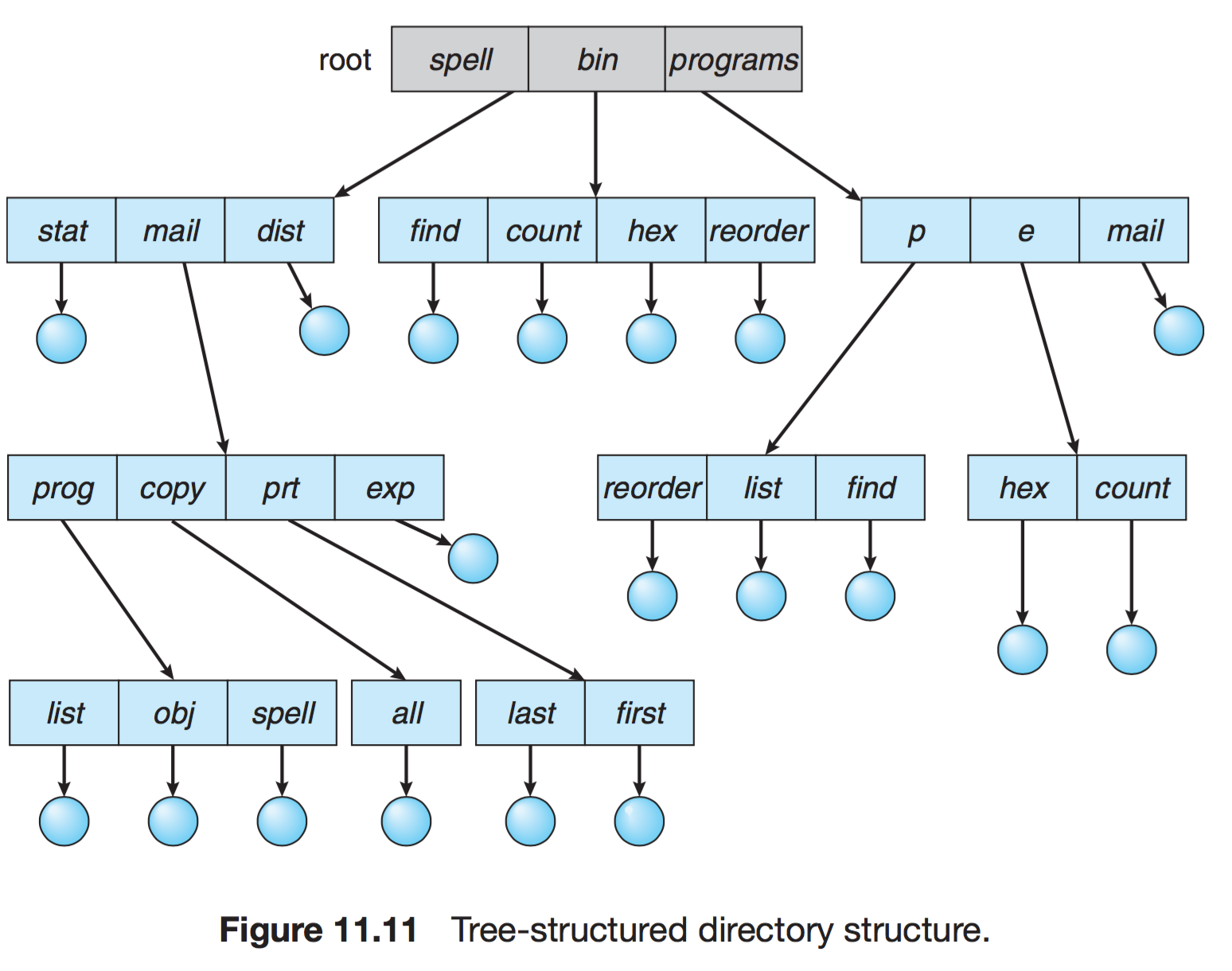
Tree Structured Directories
- 사용자들이 자신의 서브 디렉터리(Sub Directory)를 만들어서 파일을 구성할 수 있다.
- 각 사용자는 하나의 루트 디렉터리를 가지면, 모든 파일은 고유한 경로 (절대 경로/상대 경로) 를 갖는다.
Absolute(절대) 경로 : 파일을 읽기 위한 파일 전체 경로 (root 부터 현재 파일 위치까지 포함)
Relative(상대) 경로 : 현재 위치를 기준으로 하여 목적지까지의 상대적인 경로 - 해당 경로를 통하여 효율적인 탐색 및 그룹화가 가능하다.
- 디렉터리는 일종의 파일이므로, 일반 파일인지 디렉터리인지 구분할 필요가 있다.
- 이를 bit를 사용하여 구분한다.
- 0 : 일반 파일
- 1 : 디렉터리
Acyclic Graph (비순환 그래프) Directory
- 디렉터리들이 서브 디렉터리들과 파일을 공유할 수 있도록 한다.
- 서로다른 사용자가 동일한 파일에 대해서 서로 다른 Alias(별칭)을 사용 가능하다.
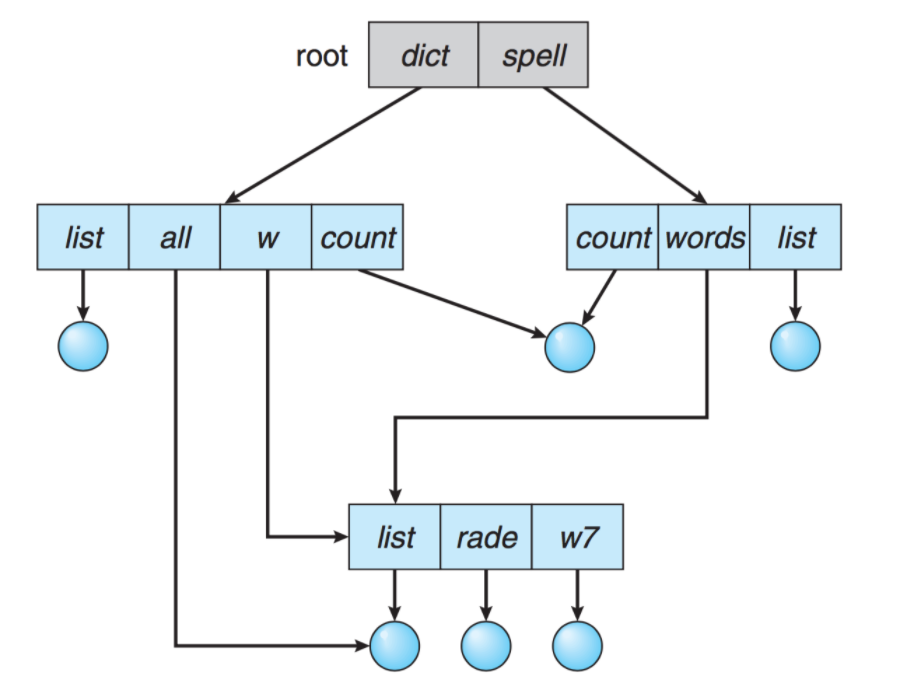
- 파일을 무작정 삭제하게 되면, 현재 파일을 가리키는 포인터는 대상이 사라지게 된다.
해당 포인터를 Dangling Pointer라고 한다. - 따라서, 참조되는 파일에 참조계수를 둔다.
참조계수가 0이 되면, 파일을 참조하는 링크가 존재하지 않는다는 의미이므로 그때 파일을 삭제할 수 있도록 한다.
General Graph (일반 그래프) Directory
- 순환을 허용하는 그래프 구조이다.
- 순환이 허용되면 무한 루프에 빠질 수 있기때문에, 잘 쓰이지 않는다.
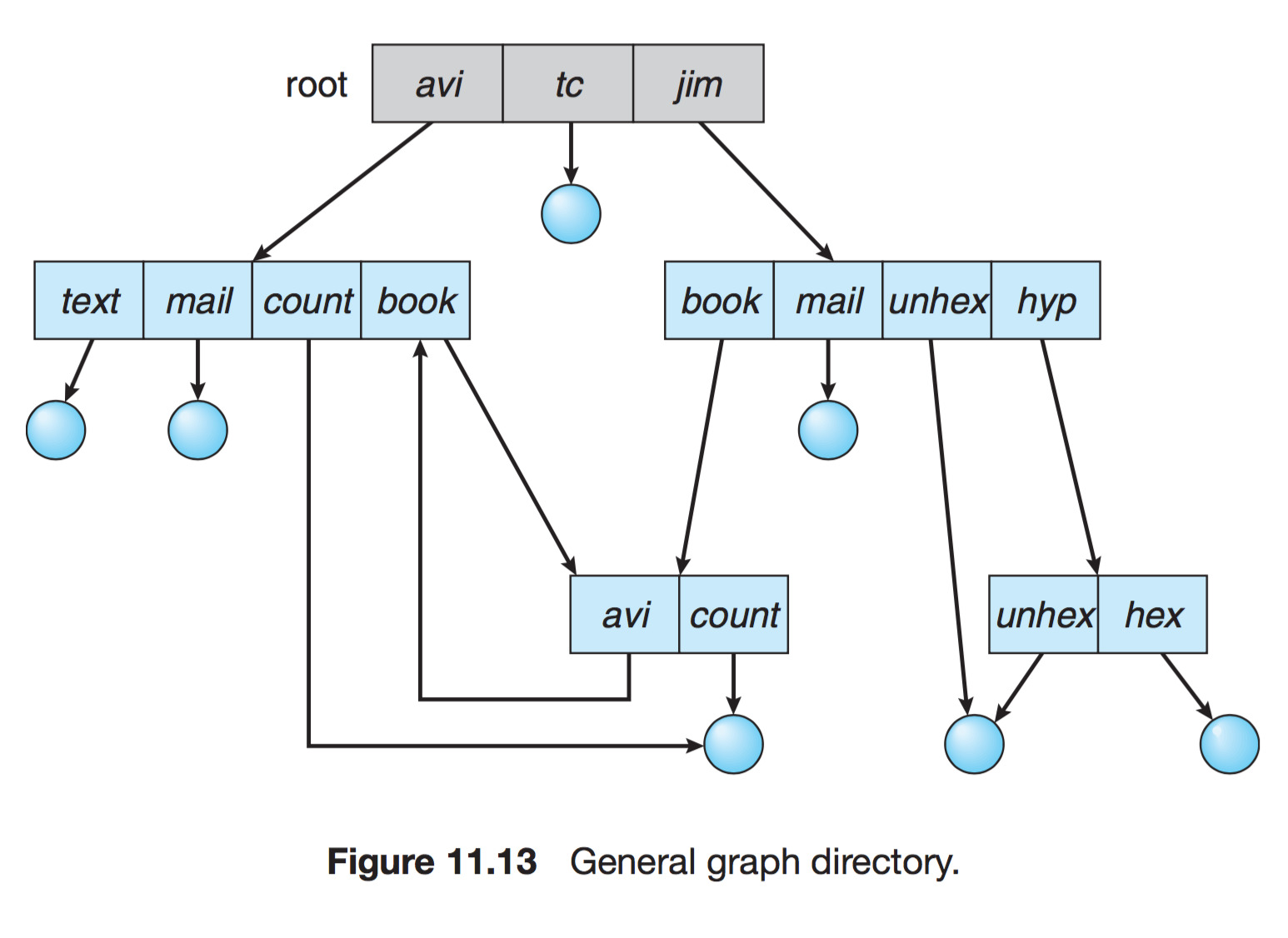
- 순환이 발생하지 않도록 하위 디렉터리가 아닌 파일에 대한 링크만 허용하거나,
Garbage Collection을 통해 전체 파일 시스템을 순회하고, 접근 가능한 모든 것을 표시한다.

소통을 중요하게 여기며, 정보의 공유를 통해 완전한 학습을 이루어 냅니다.