
먼저 UNIVEUS 프로젝트의 메인페이지는, offset 기반으로 페이지네이션으로 구현되어있다.
데이터가 많지 않아서 랜더링이 늦지 않았고, JPA Pageable을 이용해 손쉽게 구현할 수 있기 때문에 offset을 택했다.
그러나, 서비스가 정말 잘 돼서 대용량의 데이터를 다루어야 한다면, offset 기반 페이지네이션은 어떤 퍼포먼스를 보일지 의문이 들었다.
0. 실험 환경 구축 - 약 300만 개의 데이터
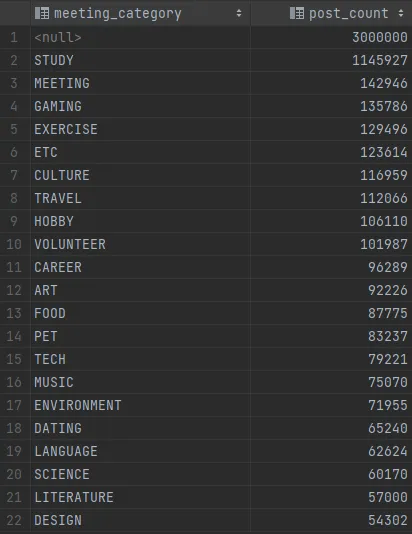
카테고리는 총 20개이고, 전체 게시물 개수는 300만개이다.
그 중 STUDY 카테고리의 비율이 압도적으로 많도록 구성했다. 그 이유는, 실제 웹 사이트를 운영하다보면, 유독 인기가 많은 카테고리가 존재한다.
그 사실을 반영해, 하나의 카테고리가 30% 이상의 점유율을 차지하도록 했다.
1. Offset 기반 페이지네이션의 한계
가장 큰 점유율의 카테고리인 STUDY를 기준으로 쿼리를 실행해보았다.




offset이 증가할수록 실행 시간이 늘어나는 양상을 볼 수 있다.
이는, offset 기반 페이지네이션에서 흔히 발생하는 이슈이다.
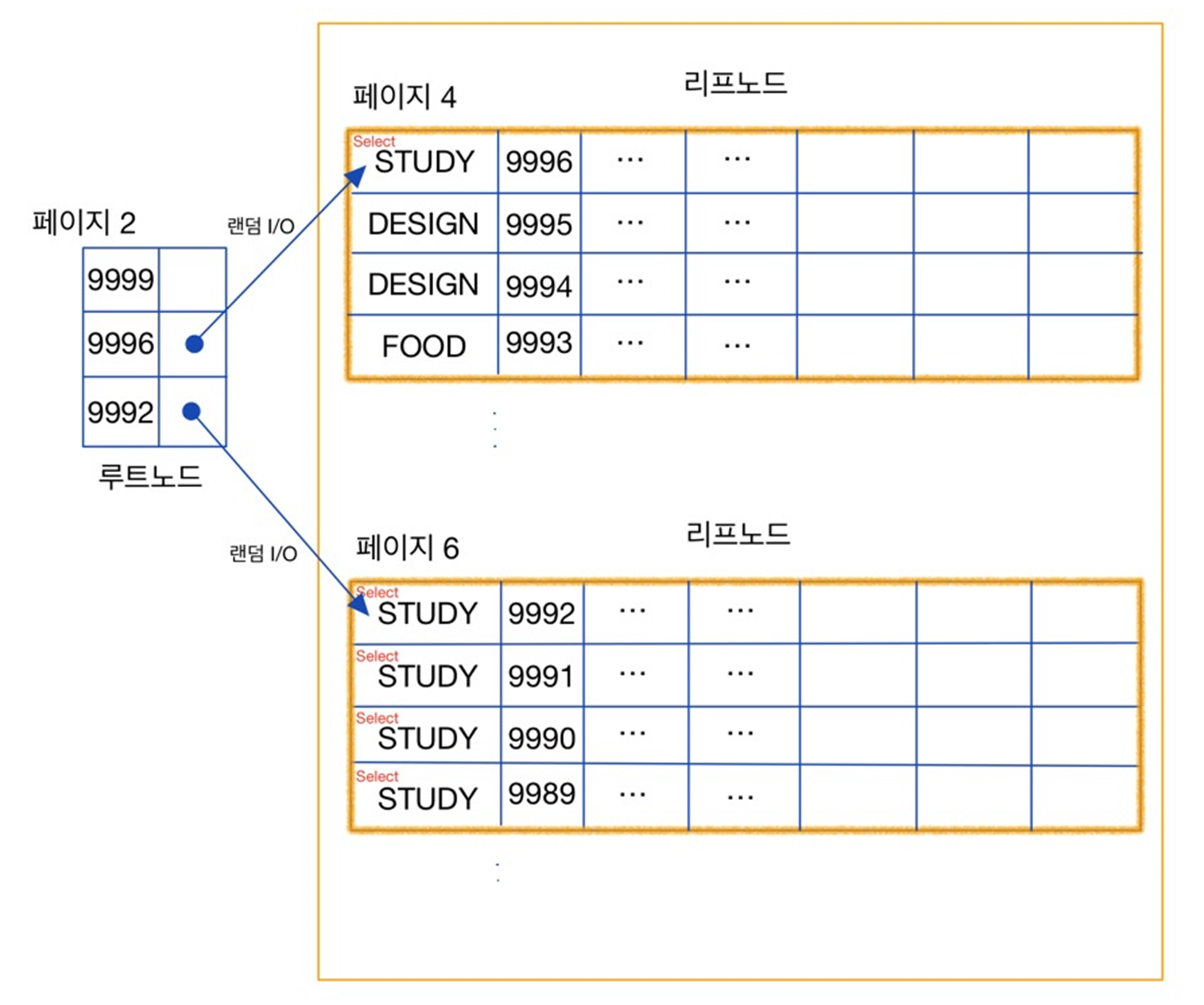
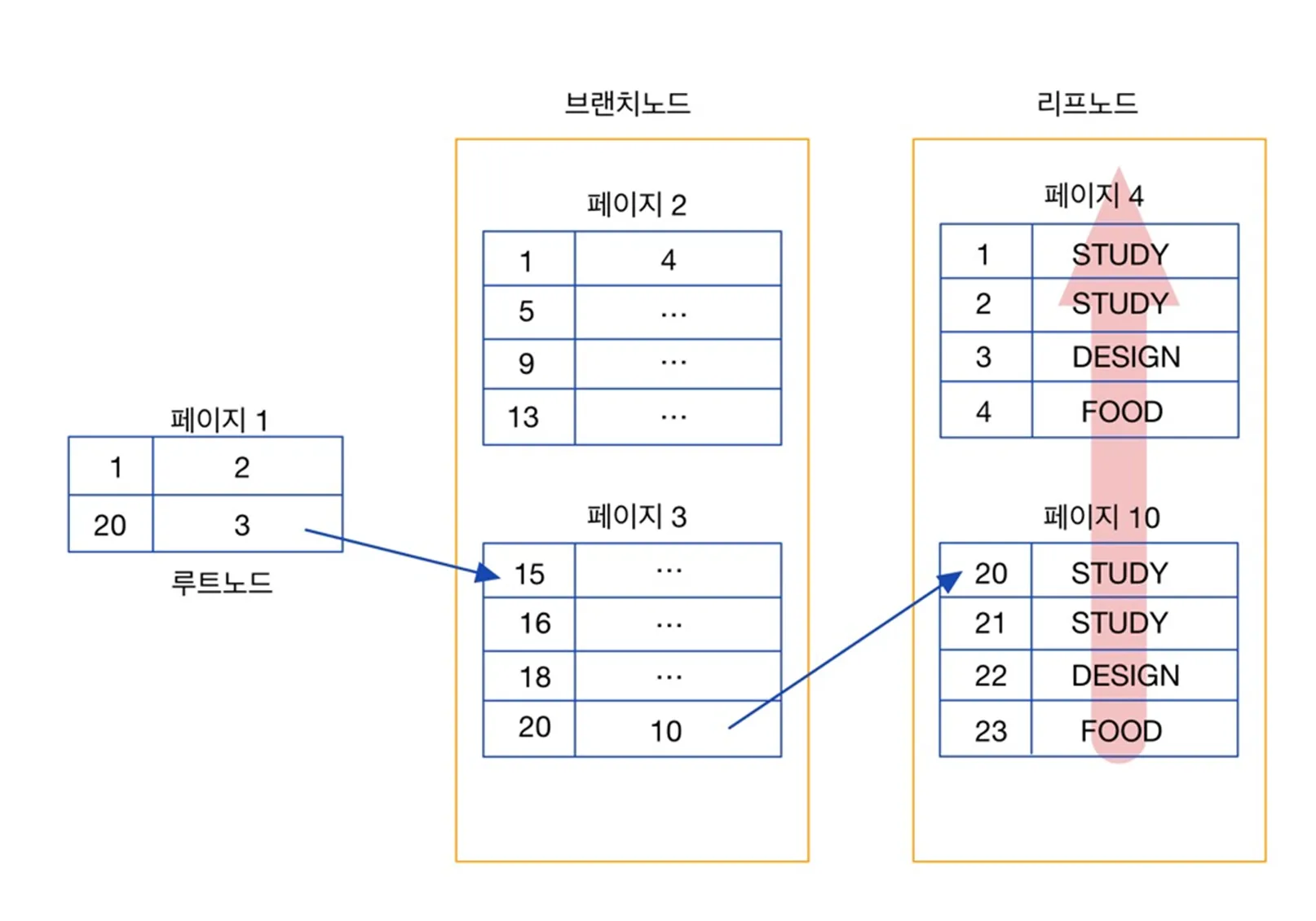 위 쿼리의 동작 방식을 간략하게 시각화 (offset 기반)
위 쿼리의 동작 방식을 간략하게 시각화 (offset 기반)
offset 기반의 페이지네이션의 성능 이슈는, offset 만큼의 행은 무조건 건너뛰어야하는데에서 나온다.
위 그림을 참고해서 설명해보자면, PK 1, 2만 읽고 싶다고 해도, 23번부터 차례로 읽어서 offset 만큼의 행의 개수를 계산을 해야 된다.
정리하자면, offset 크기가 N이라면 최소 N개 데이터를 무조건 스캔해야 한다.
LIMIT 10 OFFSET 1000000 이라는 쿼리를 실행하면, MySQL은 최소 100만 개의 행을 읽고 나서 그다음 10개만 반환한다는 뜻 이다.
즉, 필요 없는 데이터도 읽기 때문에, 데이터가 많아지고 뒤 페이지를 조회해야 할수록 속도가 느려지는 문제가 발생한다.
2. 쿼리에 인덱스 적용
SELECT *
FROM meeting_post p
WHERE meeting_category = :category
ORDER BY p.id DESC
LIMIT :pageSize OFFSET :offset;CREATE INDEX idx_category_id ON meeting_post (meeting_category, id DESC);인덱스를 위와 같이 구성한 이유
- Cateogry와 ID를
복합 인덱스로 지정한다 - WHERE 절에서 Category 사용하도록 한다
- Order By 절에서 내림차순 정렬을 고려하여, 인덱스의 두번째 컬럼을 id를 DESC로 지정한다
- offset이 커질수록 리프노드에서 대량의 데이터 레코드를 읽어야한다.
- 많은 데이터를 읽어야 하는 상황에서는, 인덱스 정순 스캔이 인덱스 역순 스캔보다 속도가 빠르다. 따라서 내림차순 정렬을 고려해서 ID를 정순 스캔하도록 만들었다
인덱스 적용 결과
 인덱스 적용 전
인덱스 적용 전
 인덱스 적용 후
인덱스 적용 후
 인덱스 적용 전의 실행 계획
인덱스 적용 전의 실행 계획
 인덱스 적용 후의 실행 계획
인덱스 적용 후의 실행 계획
실행 계획을 살펴보면, 인덱스가 사용되고 있다는 것을 볼 수 있다.
그러나 인덱스 적용 후가 전 보다 약 1초 느린 것을 볼 수 있다.
그렇다면, 우리가 기대한 만큼 성능을 못 보이는 이유는 무엇일까?
3. 성능 저하 이유와 인덱스 손익 분기점
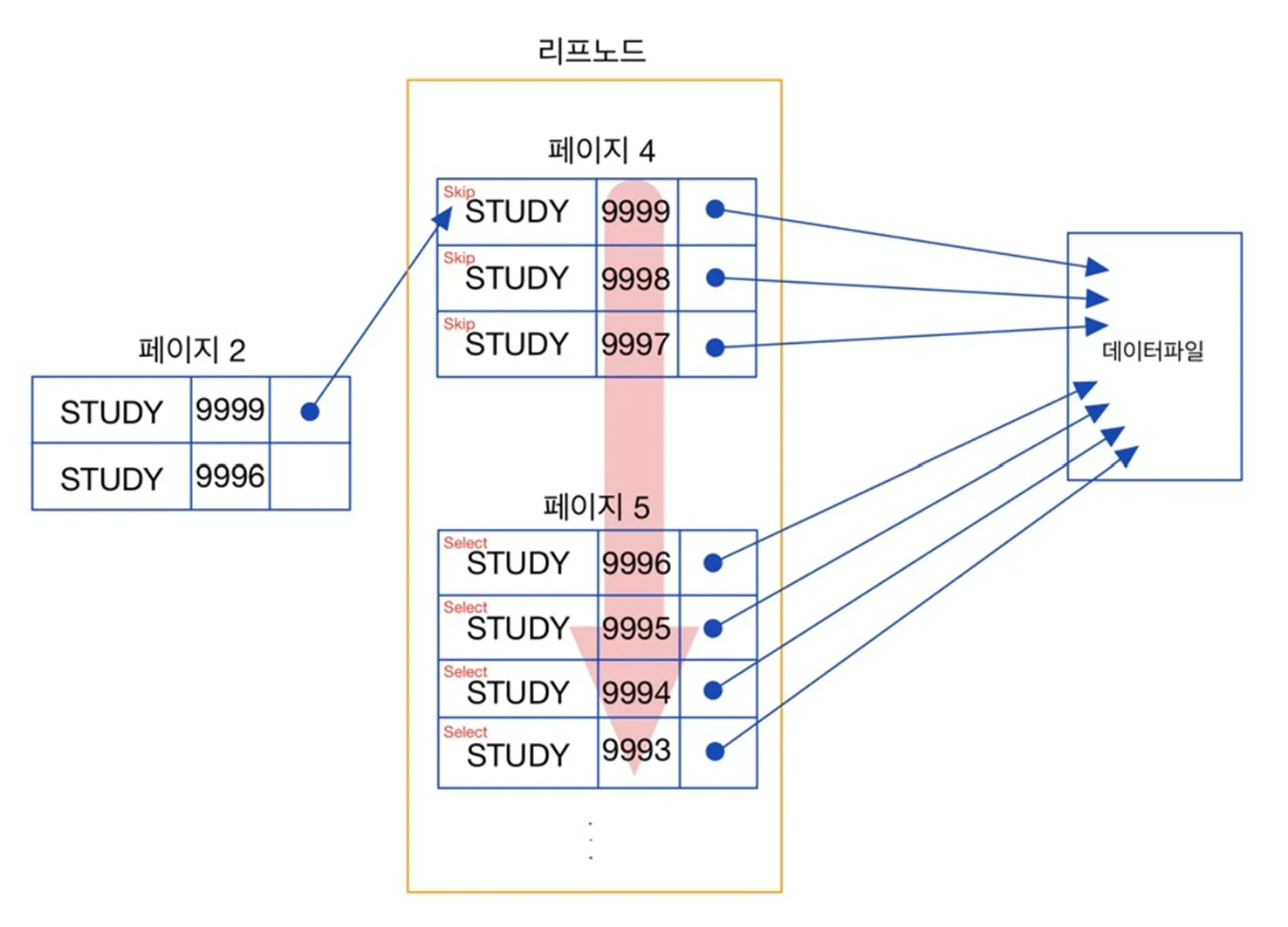 인덱스 적용 후 동작을 간략하게 시각화
인덱스 적용 후 동작을 간략하게 시각화
-
STUDY카테고리는 데이터 분포의 약36.67%를 차지하고 있다 -
인덱스로
STUDY카테고리를 빠르게 필터링 하고 역순으로 조회한다고 해도, 대부분의 데이터셋을 차지하고 있기 때문에, 상위 N건을 읽을 때 발생하는 비용이 여전히 크다 -
또한, 위 그림을 예시로 들면, offset으로 데이터 행을 건너뛰는 과정에서, select 절에 존재하지 않는 컬럼으로 인해 인덱스에서 건너 뛰는 것이 아닌, 데이터 레코드를 접근하고 이 과정에서 다량의 랜덤 I/O가 발생한다
-
또한, 데이터를 읽어야 하는 숫자가
20~25%를 넘어가는 경우, 인덱스를 통해 데이터를 읽는 것 보다 데이터 레코드를 순차 I/O로 읽는 것이 더 빠른데, offset이 커질수록 랜덤 I/O로 읽어야하는 데이터 수는 증가한다
🗨️ 인덱스의 손익 분기점
일반적으로 DBMS의 옵티마이저에서는 인덱스를 통해 레코드 1건을 읽는 것이, 테이블에서 직접 레코드 1건을 읽는 것보다 `4~5`배 정도 비용이 더 많이 드는 작업인 것으로 예측한다.
그 이유는, 인덱스를 통해 데이터를 읽으면 레코드 한 건 단위로 `랜덤 I/O`가 발생하기 때문이다.따라서, 읽어야 하는 레코드 수가 전체 테이블 레코드의 `20~25%`를 넘기게 된다면, 인덱스를 이용하지 않고 테이블을 모두 직접 읽어서 필요한 레코드만 가려내는 방식(필터링 방식)이 더 효율적이다.
그렇다면, 작은 데이터 분포를 가진 카테고리에서의 실행시간은 어떨까?
실제로 아래와 같이, 가장 작은 분포인 (약 2% 차지) DESIGN 카테고리의 인덱싱 전 후를 비교하게 된다면, 인덱스 적용 전에 비해 후가 약 869ms 단축 된 거를 볼 수 있다.
 인덱스 적용 전
인덱스 적용 전
 인덱스 적용 후
인덱스 적용 후
4. 커버링 인덱스를 활용한 쿼리 최적화
인덱스를 지우는 것은?
⇒ 작은 데이터 분포를 가지고 있는 데이터에 대해서, 좋은 퍼포먼스를 보이기 어려울 것이다.
인덱스를 그냥 적용하는 것은?
⇒ 손익 분기점을 넘어가는 데이터 분포 환경에서 사용하기에는, 성능적 이슈가 여전히 존재한다.
인덱스를 더 효과적으로 사용할 수 있는 방법은 없을까?
⇒ 커버링 인덱스 를 이용해서 조회할 ID만 추출해서 PRIMARY INDEX로 바로 접근 하는 건 어떨까?
최종 쿼리
SELECT p.*
FROM meeting_post p
JOIN (
SELECT id
FROM meeting_post
WHERE meeting_category = :category
ORDER BY id DESC
LIMIT :pageSize OFFSET :offset
) sub ON p.id = sub.id;- 서브쿼리에서는 ID만 가져오도록 한다
커버링 인덱스 - 메인 쿼리에서는, 가져온 20개의 ID에 대해서만 데이터 파일에 접근한다
[STEP 1] 커버링 인덱스로 데이터 파일에 접근하지 않고, ID 만 SELECT한다
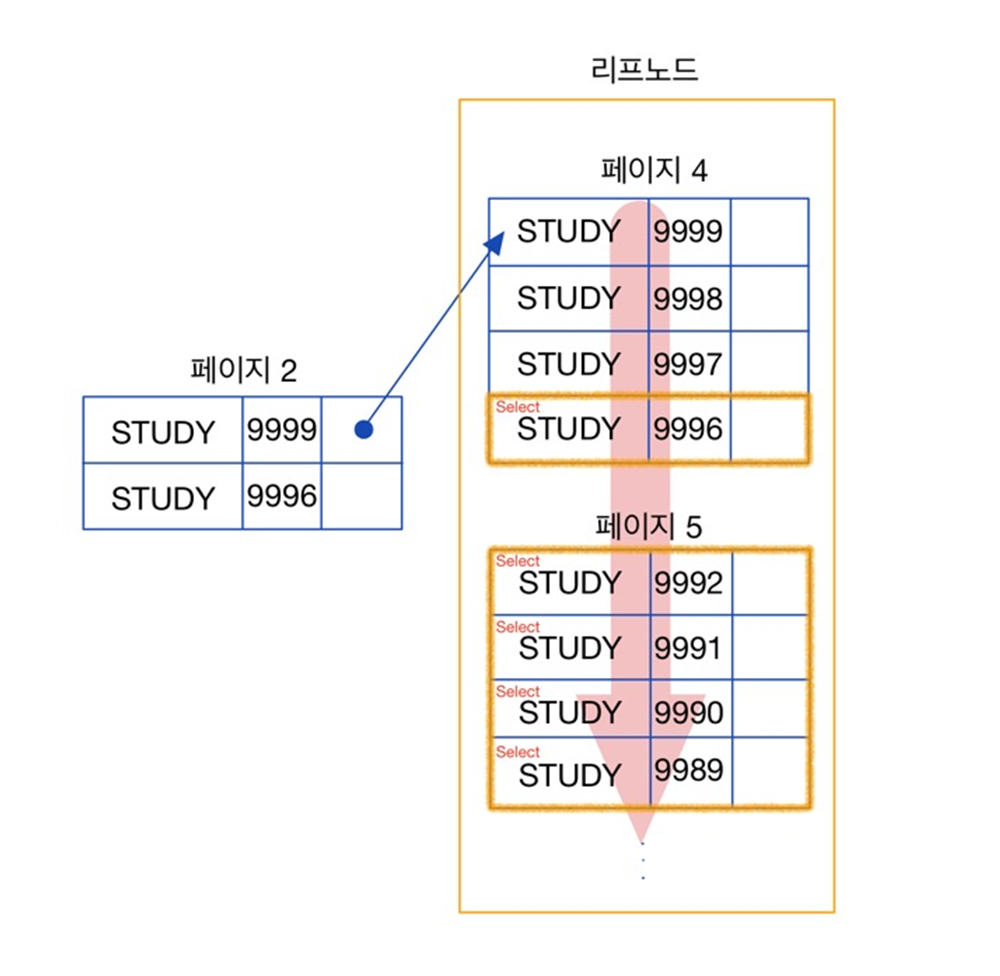
[STEP 2] SELECT한 ID(클러스터링 인덱스)를 이용해서 데이터 파일에서 레코드를 읽어온다
위 쿼리의 장점
- SELECT절에 ID만 있기 때문에,
커버링 인덱스를 통해 offset으로 건너뛰는 데이터들에 대한 테이블 접근하는 것을 회피한다 ⇒ 페이지네이션 자체를 인덱스 레벨에서 해결하여, LIMIT 20에 대한 랜덤 I/O만 발생한다.
- 서브쿼리는 인덱스 탐색만 수행하여 최소한의 데이터만 가져오고, 메인 쿼리에서는 클러스터링 인덱스인 id를 이용해서 빠르게 데이터에 접근한다.
O(1) 수준
쿼리 튜닝 전 후 테스트
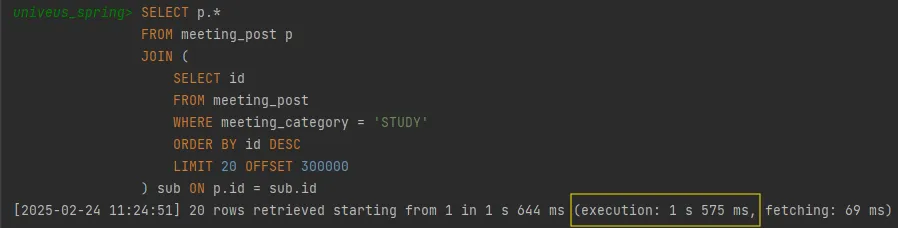
쿼리 튜닝 전
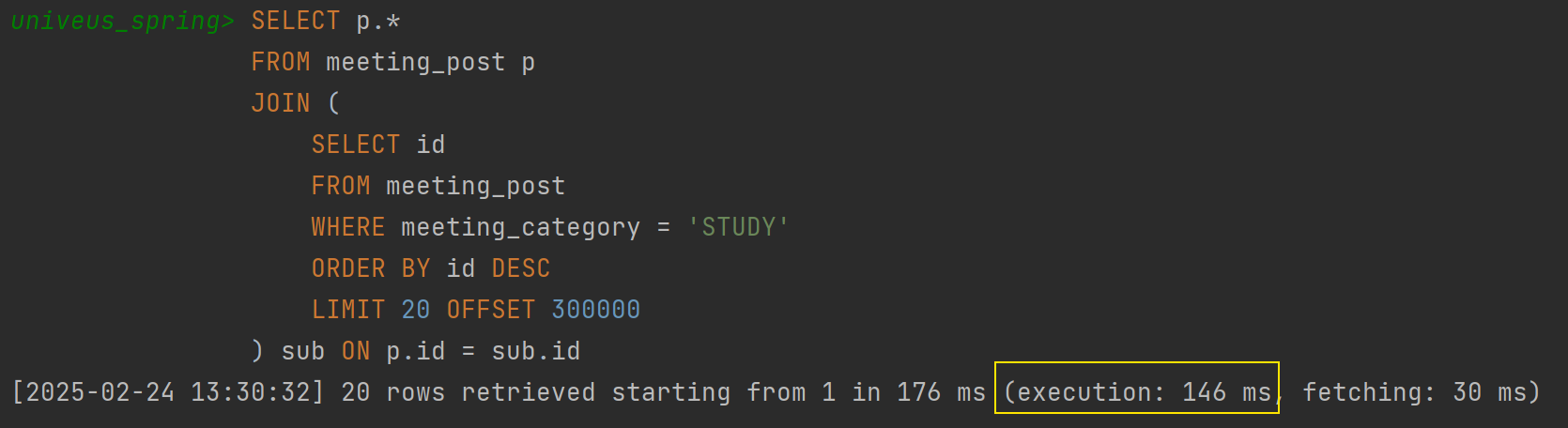
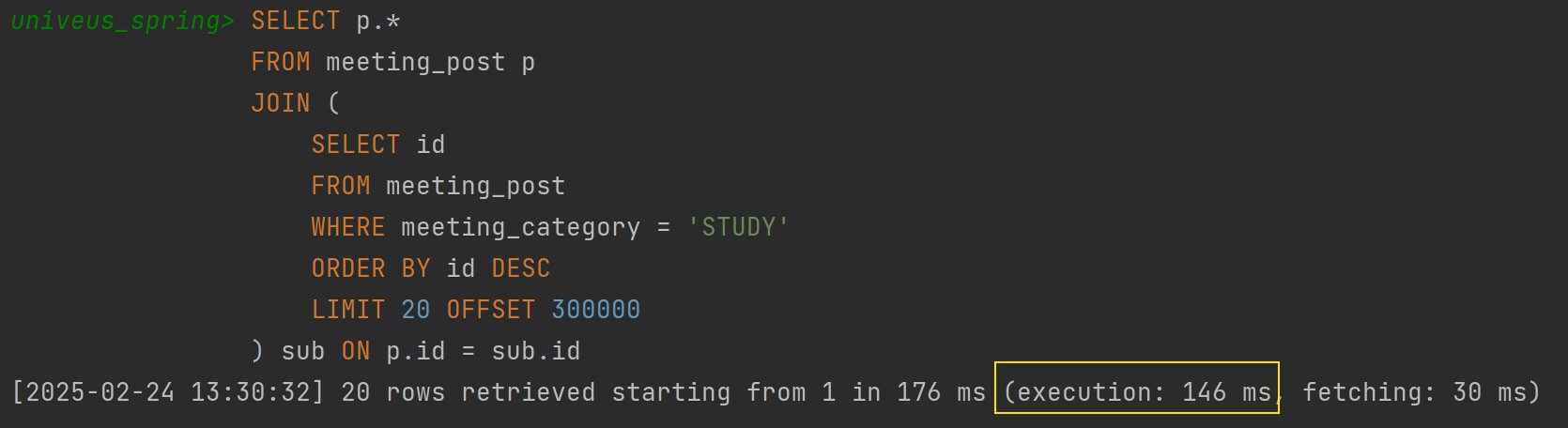 쿼리 튜닝 후
쿼리 튜닝 후
✅ 3.188s → 146ms (약 3.04s 감소, 약 95.4% 향상)
✅ 기존 3.188s에서 146ms로 최적화됨 (약 21.8배 개선)
튜닝 쿼리 인덱싱 전 후 비교
 인덱스 적용 전
인덱스 적용 전
 인덱스 적용 후
인덱스 적용 후
✅ 1.575s → 146ms (약 1.43s 감소, 약 90.7% 향상)
✅ 기존 1.575s에서 146ms로 최적화됨 (약 10.9배 개선)
5. 결론 - 더 고민해야 할 부분
커버링 인덱스로 데이터 접근을 최소화 하여, 실행 시간이 많이 줄었다.
그렇지만, 근본적인 원인인 offset 만큼의 불필요한 인덱스를 읽는 것 은 해결하지 못했다.
offset이 커질수록 어떤 장애가 또 생길지 모른다는 것이다.
그렇다면, 이를 해결할 수 있는 페이지네이션 기법은 없을까?
⇒ 다음 포스팅에서는, NO OFFSET 기반 페이지 네이션을 통해 성능 개선을 완료하도록 하겠다.
=> 파티셔닝 & 샤딩에 대해 공부도 추가적으로 하도록 하겠다.
📘 참고 서적
Real MySQL 8.0 백은빈, 이성욱 지음
📗 참고 블로그
「기억보단 기록을」 https://jojoldu.tistory.com/529
📂 도움이 되었던 영상
「우아한 테크코스」 https://youtu.be/edpYzFgHbqs?feature=shared
