💎 EDA를 통해 데이터 탐색하기
🔼 데이터 구성
- Pregnancies : 임신 횟수
- Glucose : 2시간 동안의 경구 포도당 내성 검사에서 혈장 포도당 농도
- BloodPressure : 이완기 혈압 (mm Hg)
- SkinThickness : 삼두근 피부 주름 두께 (mm), 체지방을 추정하는데 사용되는 값
- Insulin : 2시간 혈청 인슐린 (mu U / ml)
- BMI : 체질량 지수 (체중kg / 키(m)^2)
- DiabetesPedigreeFunction : 당뇨병 혈통 기능
- Age : 나이
- Outcome : 768개 중에 268개의 결과 클래스 변수(0 또는 1)는 1이고 나머지는 0입니다.
🔼 데이터 탐색
df.info()
df_null = df.isnull()
df_null.sum()

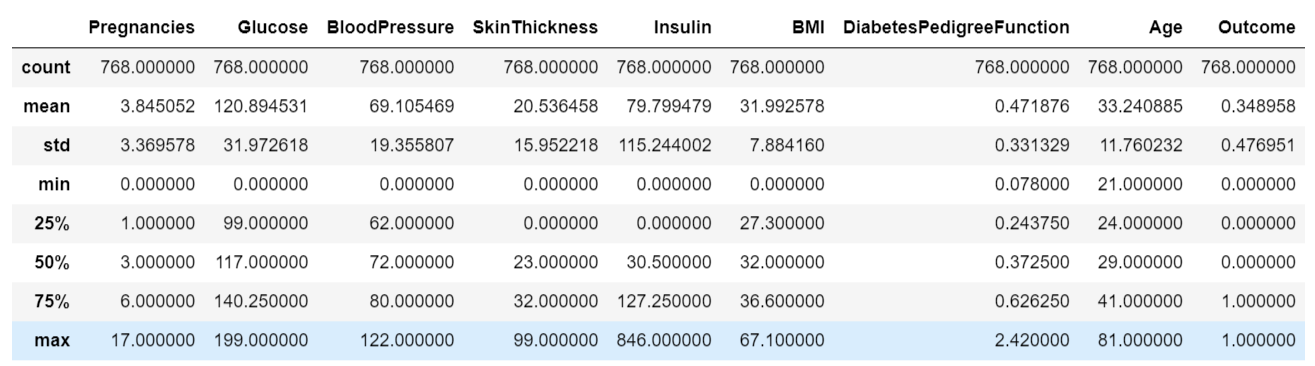
df.describe()
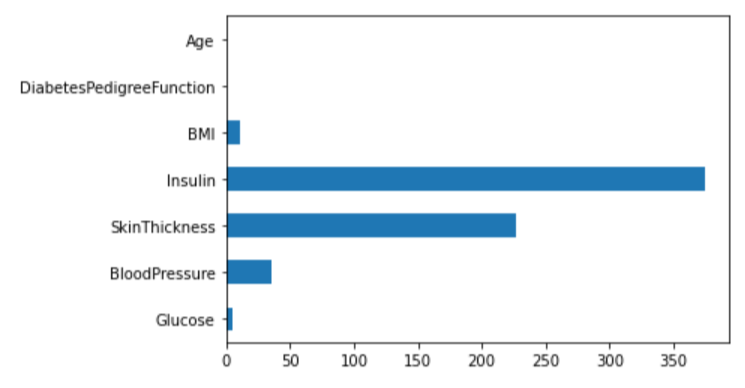
feature_columns = df.columns[0:-1].tolist()
cols = feature_columns[1:]
df_null = df[cols].replace(0, np.nan)
df_null = df_null.isnull()
df_null.sum()

df_null.sum().plot.barh()
df["Outcome"].value_counts()
df["Outcome"].value_counts(normalize=True)
df.groupby(["Pregnancies"])["Outcome"].agg(["mean", "count"])
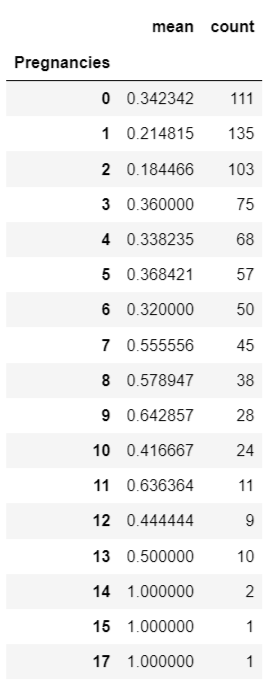
df_po = df.groupby(["Pregnancies"])["Outcome"].agg(["mean", "count"]).reset_index()
df_po.plot()
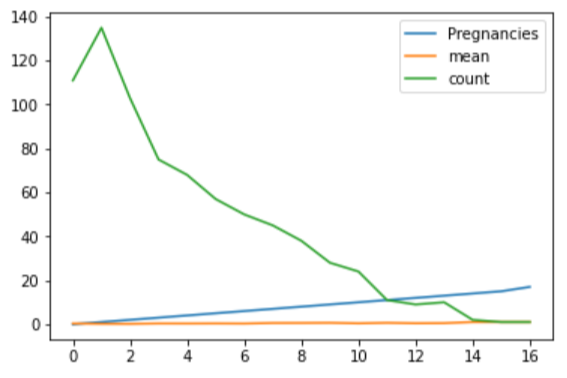
df["Pregnancies_high"] = df["Pregnancies"] > 6
sns.countplot(data=df, x="Pregnancies_high", hue="Outcome")
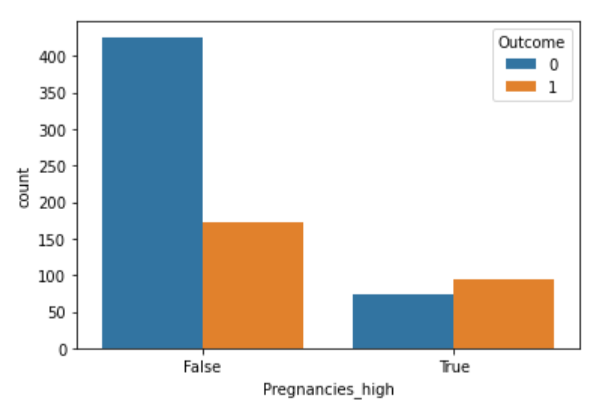
sns.barplot(data=df, x="Outcome", y="BMI")
sns.barplot(data=df, x="Outcome", y="Glucose")
sns.barplot(data=df, x="Outcome", y="Insulin")
sns.barplot(data=df, x="Pregnancies", y="Outcome")
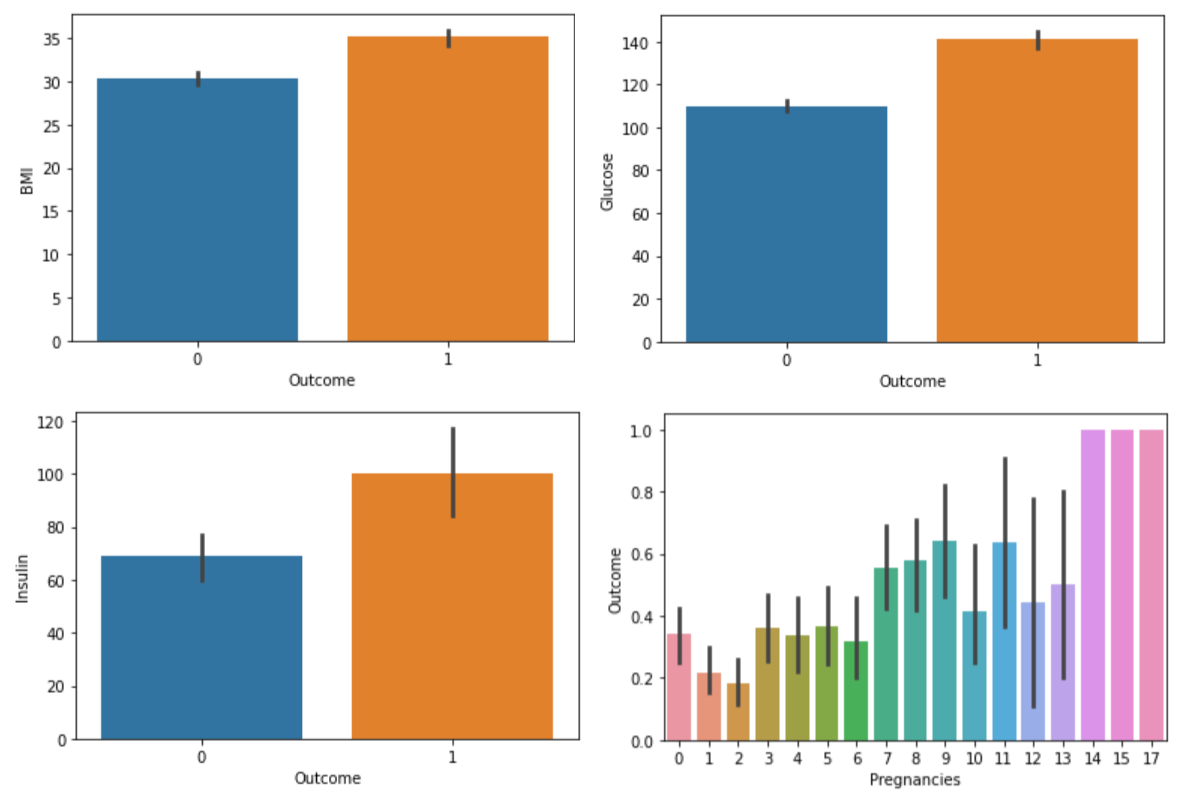
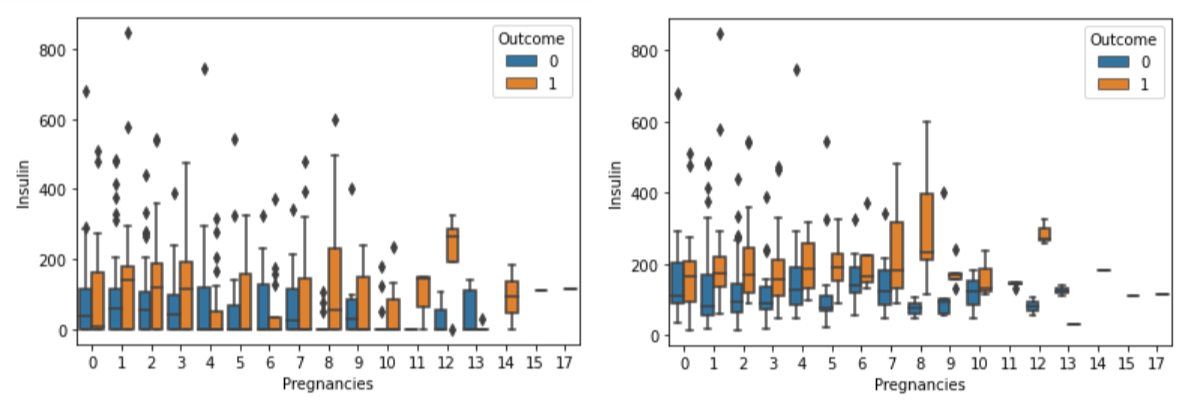
sns.boxplot(data=df, x="Pregnancies", y="Insulin", hue="Outcome")
sns.boxplot(data=df[df["Insulin"] > 0], x="Pregnancies", y="Insulin", hue="Outcome")
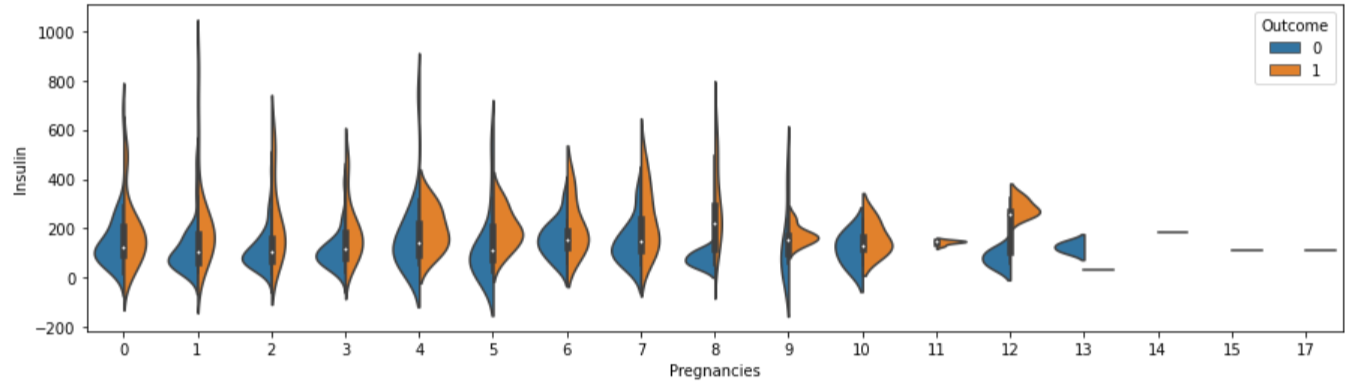
plt.figure(figsize=(15, 4))
sns.violinplot(data=df[df["Insulin"] > 0], x="Pregnancies", y="Insulin", hue="Outcome", split=True)
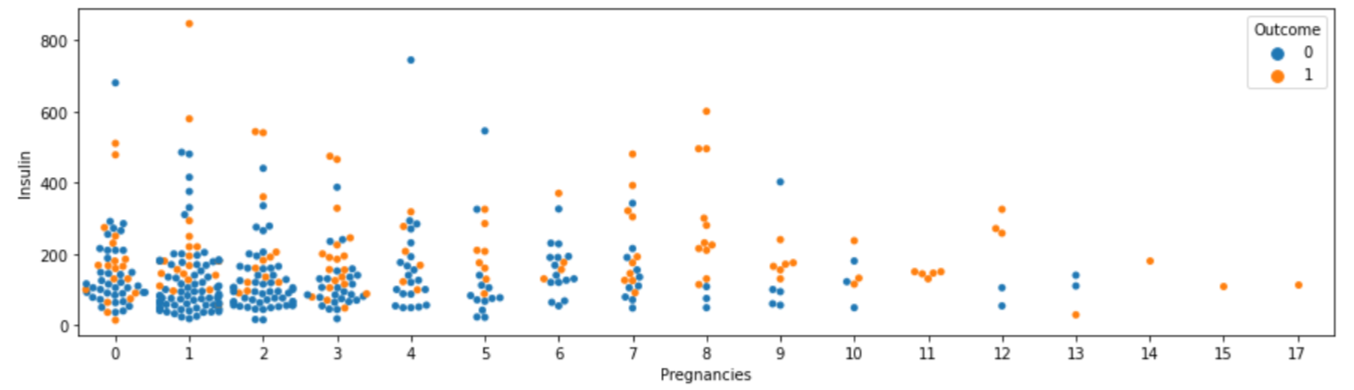
plt.figure(figsize=(15, 4))
sns.swarmplot(data=df[df["Insulin"] > 0], x="Pregnancies", y="Insulin", hue="Outcome")
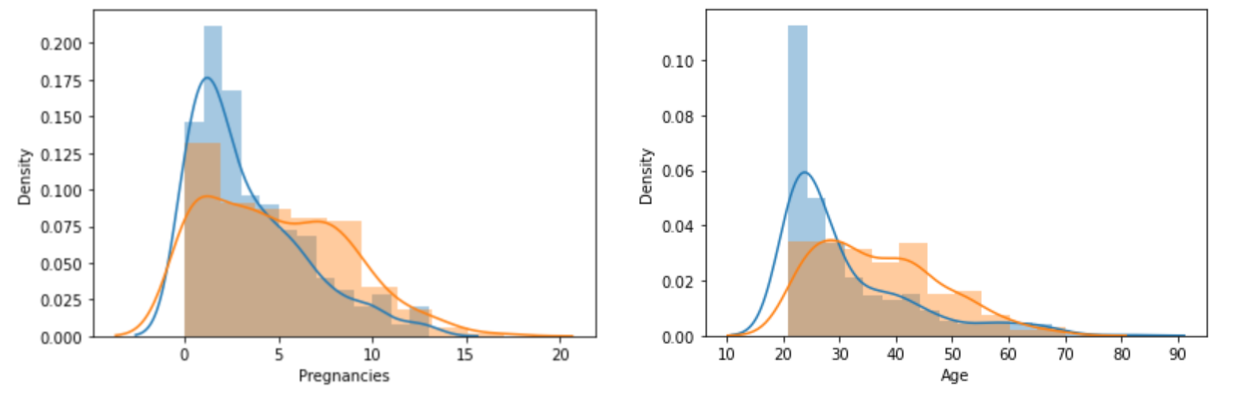
df_0 = df[df["Outcome"] == 0]
df_1 = df[df["Outcome"] == 1]
sns.distplot(df_0["Pregnancies"])
sns.distplot(df_1["Pregnancies"])
sns.distplot(df_0["Age"])
sns.distplot(df_1["Age"])
df["Pregnancies_high"] = df["Pregnancies_high"].astype(int)
h = df.hist(figsize=(15, 15), bins=20)
df.iloc[:, :-2].replace(0, np.nan)
df_matrix = df.iloc[:, :-2].replace(0, np.nan)
df_matrix["Outcome"] = df["Outcome"]
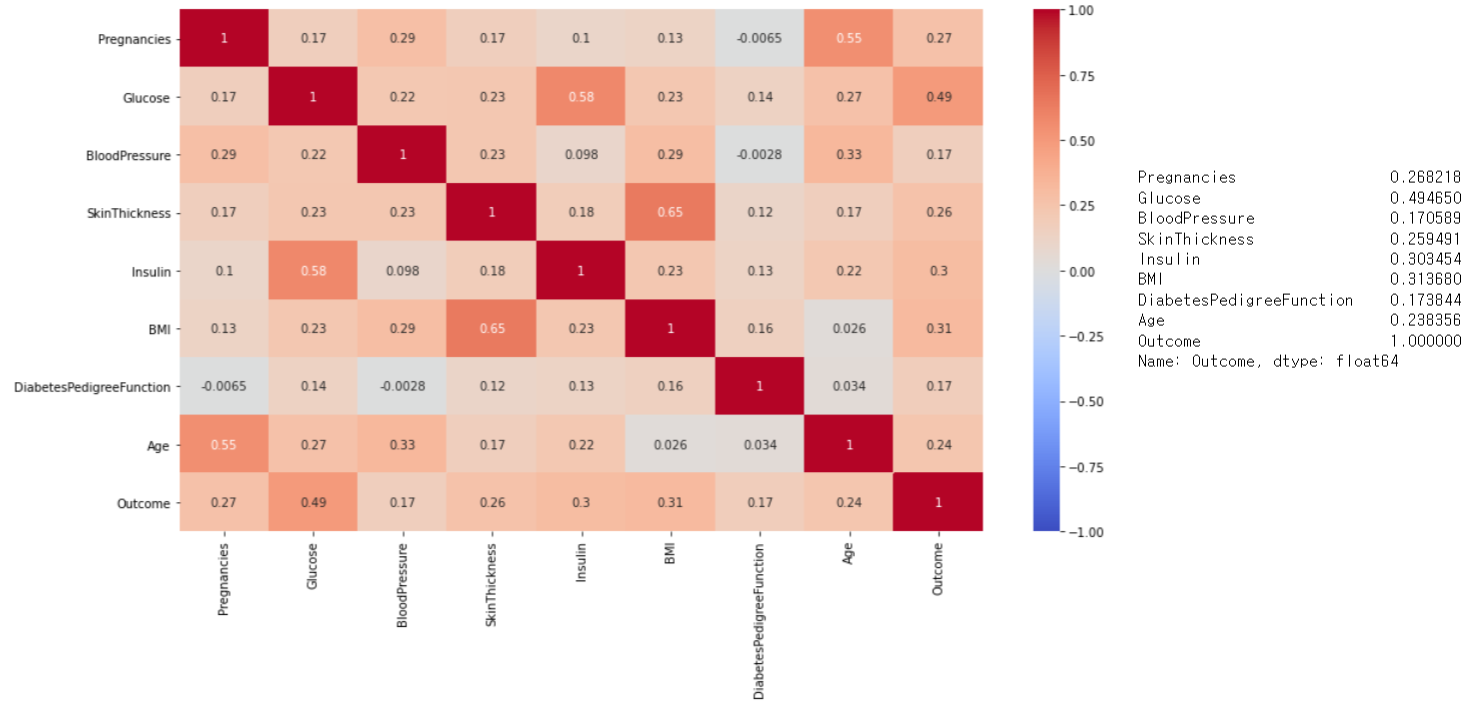
df_corr = df_matrix.corr()
plt.figure(figsize=(15, 8))
sns.heatmap(df_corr, annot=True, vmax=1, vmin=-1, cmap="coolwarm")
df_corr["Outcome"]