✔ Supervised larning
- 정답이 있는 데이터
- 분류와 회귀로 나눌 수 있음 (Classification / Regression)
- ex) 고객의 구매 패턴에 따라 구매를 한다 / 안한다로 나눌 수 있는 데이터가 있다면 새로운 고객이 들어왔을 때 그 고객이 구매를 할 것이다 / 안 할 것이다 를 예측할 수 있음
💎 DecisionTreeClassifier
- 특정 조건에 따라 왼쪽과 오른쪽으로 트리를 타고 내려가며 분류를 진행
from sklearn import tree
X = [[0, 0], [1, 1]]
Y = [0, 1]
clf = tree.DecisionTreeClassifier()
clf = clf.fit(X, Y)
clf.predict([[2., 2.]])
clf.predict_proba([[2., 2.]])
💎 의사결정나무로 당뇨병 데이터 분류 예측 모델 만들기
🔼 데이터 구성
- Pregnancies : 임신 횟수
- Glucose : 2시간 동안의 경구 포도당 내성 검사에서 혈장 포도당 농도
- BloodPressure : 이완기 혈압 (mm Hg)
- SkinThickness : 삼두근 피부 주름 두께 (mm), 체지방을 추정하는데 사용되는 값
- Insulin : 2시간 혈청 인슐린 (mu U / ml)
- BMI : 체질량 지수 (체중kg / 키(m)^2)
- DiabetesPedigreeFunction : 당뇨병 혈통 기능
- Age : 나이
- Outcome : 768개 중에 268개의 결과 클래스 변수(0 또는 1)는 1이고 나머지는 0입니다.
🔼 데이터셋 만들기
import pandas as pd
import numpy as np
import seaborn as sns
import matplotlib.pyplot as plt
pd.read_csv('diabetes.csv')
train = df[:614].copy()
test = df[614:].copy()
feature_names = train.columns[:-1].tolist()
label_name = train.columns[-1]
X_train = train[feature_names]
print(X_train.shape)
X_train.head()
y_train = train[label_name]
print(y_train.shape)
y_train.head()

X_test = test[feature_names]
print(X_test.shape)
X_test.head()
y_test = test[label_name]
print(y_test.shape)
y_test.head()

🔼 의사결정나무로 학습과 예측하기
from sklearn.tree import DecisionTreeClassifier
model = DecisionTreeClassifier()
model.fit(X_train, y_train)
y_predict = model.predict(X_test)
y_predict

🔼 예측한 모델의 성능 측정 및 분석
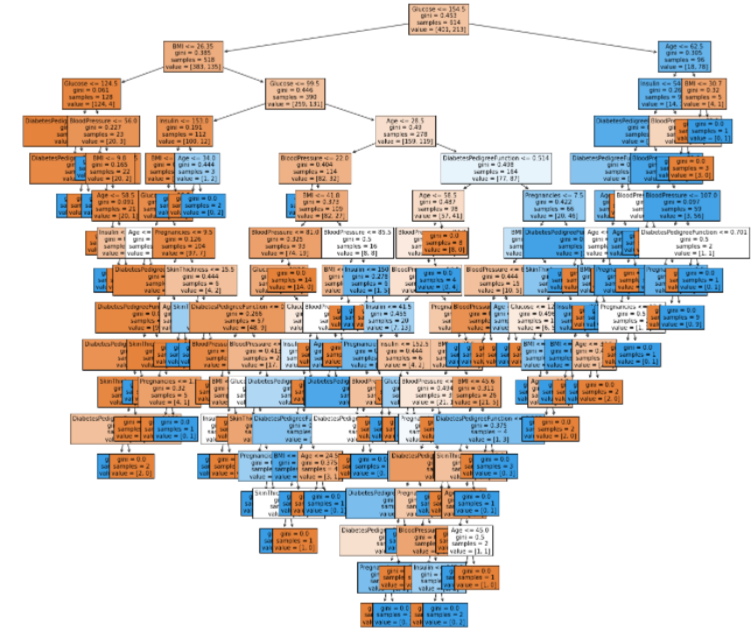
from sklearn.tree import plot_tree
plt.figure(figsize=(20, 20))
tree = plot_tree(model,
feature_names=feature_names,
filled=True,
fontsize=10)
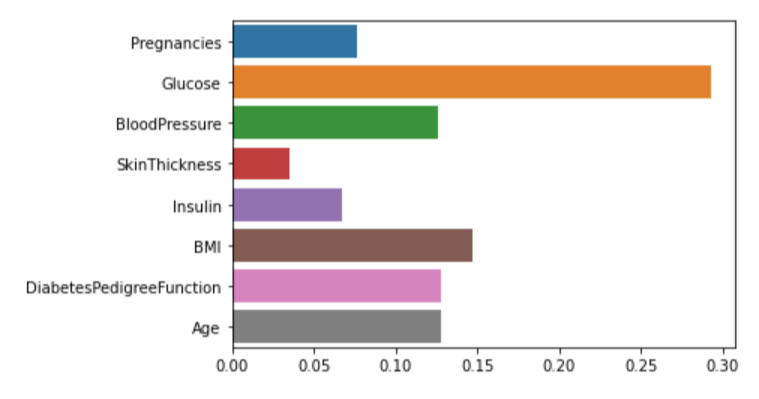
model.feature_importances_
sns.barplot(x=model.feature_importances_, y=feature_names)
diff_count = abs(y_test - y_predict).sum()
(len(y_test) - diff_count) / len(y_test) * 100
from sklearn.metrics import accuracy_score
accuracy_score(y_test, y_predict)
model.score(X_test, y_test) * 100
