도입
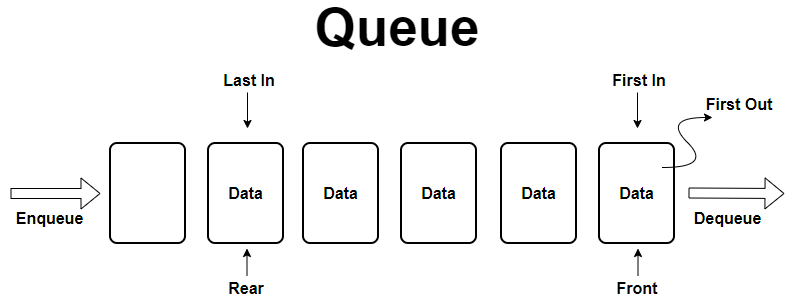
큐는 선입선출(First-In, First-Out - FIFO) 구조의 자료구조이다. 즉 큐는 뒤로 넣고 앞으로 빼는 자료구조이다. 이러한 특징은 후입선출 구조의 스택과 비교된다.
큐는 줄을 서는 것, 터널, 양쪽으로 구멍이 난 초코볼 통 등으로 비유할 수 있다.

큐의 ADT
큐의 핵심 연산은 다음 두 가지이다.
- enqueue : 큐에 데이터를 넣는 연산
- dequeue : 큐에서 데이터를 꺼내는 연산
스택에서 데이터를 넣고 빼는 연산을 각각 push, pop이라고 하는 것처럼 큐에서는 enqueue, dequeue라는 용어를 사용한다.
void QueueInit(Queue* pq): 큐의 초기화를 진행한다. 큐 생성 후 제일 먼저 호출되어야 한다.int IsEmpty(Queue* pq): 큐가 빈 경우 TRUE(1)를, 그렇지 않은 경우 FALSE(0)를 반환한다.void Enqueue(Queue* pq, Data data): 큐에 데이터를 저장한다. 매개변수 data로 전달된 값을 저장한다.Data Dequeue(Queue* pq): 저장순서가 가장 앞선 데이터를 삭제하고 반환한다. 이 함수를 호출하려면 하나 이상의 데이터가 큐에 존재해야 한다.Data Peek(Queue* pq): 저장순서가 가장 앞선 데이터를 반환하되 삭제하지 않는다. 이 함수를 호출하려면 하나 이상의 데이터가 큐에 존재해야 한다.
큐의 구현 방법
큐는 배열과 연결 리스트를 사용해서 구현할 수 있다.
배열 기반 큐
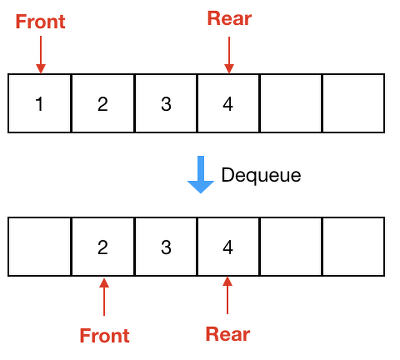
배열을 이용해서 큐를 구현하면 Enqueue와 Dequeue를 할 때마다 계속 데이터가 뒤로 밀려나는 문제가 생긴다. 왜냐하면 뒤쪽은 채워지고 앞쪽은 빠져나가기 때문이다. 이렇게 되면 배열에 빈 공간이 있지만 데이터를 큐에 넣지 못 할 수 있다.
이러한 문제를 해결하기 위해, 배열 기반 큐는 주로 원형 큐 형태로 구현한다.
원형 큐

원형 큐는 배열을 위와 같은 형태로 바라보는 것이다.
머리를 가리키는 변수 F(front)와 꼬리를 가리키는 변수 R(rear)을 사용해서 연산을 진행한다.
하지만 배열이 꽉 찬 경우와 배열이 텅 빈 경우는 F와 R만으로는 구분이 안 된다.

위의 그림처럼 배열이 꽉 찬 경우와 배열이 텅 빈 경우 모두 F와 R이 같은 곳을 가리킨다.
이러한 문제를 해결하기 위해 일반적으로 원형 큐를 구현할 때는 배열을 꽉 채우지 않는다. 꽉 차면 텅 빈 경우와 구분이 되지 않기 때문이다. 즉 배열의 길이가 N이라면 데이터가 N-1개 채워졌을 때, 이를 꽉 찬 것으로 간주한다.
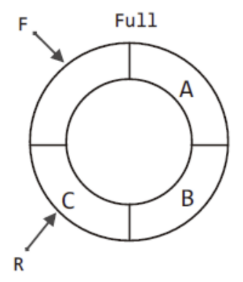
따라서 F와 R이 동일한 위치를 가리키면 원형 큐가 텅 빈 상태이고, R이 가리키는 위치의 앞을 F가 가리키면 원형 큐가 꽉 찬 상태이다.
이러한 원형 큐에서의 enqueue 연산과 dequeue 연산 과정은 다음과 같다.
- enqueue : R이 가리키는 위치를 한 칸 이동시킨 다음에, R이 가리키는 위치에 데이터를 저장한다.
- dequeue : F가 가리키는 위치를 한 칸 이동시킨 다음에, F가 가리키는 위치에 저장된 데이터를 반환 및 소멸시킨다.
연결 리스트 기반 큐
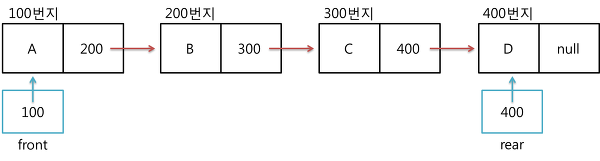
연결 리스트를 이용해서 큐를 구현하는 것은 배열을 이용한 경우보다 신경 쓸 부분이 적다.
우선 연결 리스트의 앞 부분을 F(front), 뒷 부분을 R(rear) 변수로 가리킨다.
enqueue는 R이 가리키는 곳 뒤에 새로운 데이터를 추가하고 R이 가리키는 곳을 한 칸 뒤로 옮기면 된다.
dequeue는 F가 다음 노드를 가리키게 하고 F가 이전에 가리키던 노드를 소멸시키면 된다.
큐의 시간복잡도
- 탐색 : O(n)
- 삽입(enqueue) : O(1)
- 삭제(dequeue) : O(1)
큐의 삽입(enqueue)은 항상 front에서만 일어나고 삭제(dequeue)는 항상 rear에서만 일어나므로 삽입과 삭제에 소요되는 시간복잡도는 O(1)로 고정된다.
큐의 활용
큐는 주로 데이터가 입력된 순서에 따라 처리되어야 할 때 사용된다.
- 프로세스 관리
- 너비 우선 탐색(BFS, Breadth-First Search) 구현
- 캐시(Cache) 구현
덱(Deque, Double-ended queue)
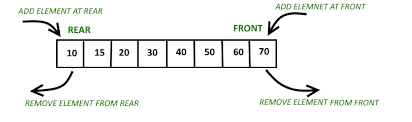
위에서 큐는 뒤로 넣고 앞으로 빼는 자료구조라고 했다. 덱은 앞으로도 뒤로도 넣을 수 있고, 앞으로도 뒤로도 뺄 수 있는 자료구조이다.
덱의 full-name인 Double-ended queue는 양방향으로 넣고 뺄 수 있다는 사실에 초점을 맞춰 지은 이름이다.
덱의 ADT
덱은 양방향으로 넣고 뺄 수 있는 자료구조이기 때문에 덱의 ADT를 구성하는 핵심 함수 네 가지는 다음과 같다.
- 앞으로 넣기
- 뒤로 넣기
- 앞에서 빼기
- 뒤에서 빼기
위의 기능을 중심으로 한 덱의 ADT는 다음과 같다.
void DequeInit(Deque* pdeq): 덱의 초기화를 진행한다. 덱 생성 후 가장 먼저 호출되어야 하는 함수이다.int IsEmpty(Deque* pdeq): 덱이 빈 경우 TRUE(1)를, 그렇지 않은 경우 FALSE(0)를 반환한다.void AddFirst(Deque* pdeq, Data data): 매개변수 data로 전달된 데이터를 덱의 머리에 저장한다.void AddLast(Deque* pdeq, Data data): 매개변수 data로 전달된 데이터를 덱의 꼬리에 저장한다.Data RemoveFisrt(Deque* pdeq): 덱의 머리에 위치한 데이터를 반환 및 소멸한다.Data RemoveLast(Deque* pdeq): 덱의 꼬리에 위치한 데이터를 반환 및 소멸한다.Data GetFirst(Deque* pdeq): 덱의 머리에 위치한 데이터를 소멸하지 않고 반환한다.Data GetLast(Deque* pdeq): 덱의 꼬리에 위치한 데이터를 소멸하지 않고 반환한다.
덱의 구현 방법
덱은 배열과 연결 리스트를 기반으로도 구현이 가능하지만, 양방향 연결 리스트를 이용하여 구현하는 것이 가장 좋다. 이유는 다음 함수의 구현과 관련이 있다.
Data RemoveLast(Deque* pdeq)이 함수는 꼬리에 위치한 노드를 삭제하는 함수이다. 노드가 양방향으로 연결되어 있지 않으면, 꼬리에 위치한 노드의 삭제는 간단하지 않다. 따라서 덱을 구현할 때 양방향 연결 리스트를 사용하는 것은 매우 좋은 선택이다.

덱의 시간복잡도
(양방향 연결 리스트를 이용한 경우)
- index를 이용한 random access : O(n)
- 머리, 꼬리에 삽입 : O(1)
- 머리, 꼬리 삭제 : O(1)
- 머리, 꼬리 접근 : O(1)
덱을 연결 리스트를 이용해서 구현했다고 가정했기 때문에 random access의 시간복잡도는 O(n)이다.
head와 tail 변수를 사용하기 때문에 머리, 꼬리에 접근/삽입/삭제 연산 모두 O(1)의 시간복잡도를 가진다.
덱의 활용
덱은 앞과 뒤에서 모두 삽입, 삭제가 이루어질 때 사용한다.
예를 들어 검색 기록 기능을 구현할 때 사용할 수 있다.
새로운 웹사이트는 덱의 끝에 추가된다. 검색 기록이 너무 많을 경우 덱의 앞에서부터 오래된 기록 순서대로 삭제할 수 있다. 만약 사용자가 지난 1시간 동안 검색 기록을 지우도록 요청하면 덱의 끝에서 한 시간 동안 추가되었던 기록을 삭제할 수 있다.
