Abstract
- 본 논문은 GAN 논문 중에서도 가장 많이 인용된 논문 중 하나이다.
- 본 논문의 Contribution은 크게 아래 2가지로 요약할 수 있다.
- Conditional Generative Adversarial Network(CGAN)을 사용하여 한 이미지를 다른 domain(style)의 이미지로 변환하는 방법 제안
- 특정 task마다 loss나 architecture를 다르게 적용하였던 기존 방식과는 다르게, 하나의 structure를 사용하여 모든 tasks에 적용할 수 있도록 base model을 제공
1. Introduction
- 기존 Traditional Methods의 문제점?
- Computer Vision(CV) 분야에는 무수히 많은 Task들이 존재하는데, 이를 단순히 생각했을때 input image를 어떠한 다른 양상의 output image로 변환하는 것이라고 볼 수 있음.
ex) 흑백이미지 -> 컬러이미지 변환, Edge 이미지 -> Semantic 이미지 변환 등 - 이러한 여러가지 Task들에 대해 기존 방법론은 이들을 별개의 Task로 생각하여 각 Task마다 적합한 모델과 학습방식(loss function 등)을 고안하였으나, "input image를 어떠한 다른 양상의 output image로 변환하는 것" 이라는 관점에서 보면 결국 input image의 pixel로부터 output image의 pixel을 예측하는 공통의 목표를 가진다고 볼 수 있고 이는 여러가지 task들에 대해 공통으로 사용가능한 일반적인 framework의 개발이 가능하다는 점을 의미한다.
- Computer Vision(CV) 분야에는 무수히 많은 Task들이 존재하는데, 이를 단순히 생각했을때 input image를 어떠한 다른 양상의 output image로 변환하는 것이라고 볼 수 있음.
- 공통으로 사용가능한 일반적인 framework의 모델으로, 본 논문에서는 CGAN을 제안함. 단순히 이미지 간 매핑이 아니라 이미지 pixel 간 분포를 비슷하게 가지도록 이미지를 생성하기 때문에 현실에 존재할법한 이미지를 생성해내는데 특화되어 있고 blur하지 않는 결과가 나오기 때문.
3. Method
3.1 Objective
- 본 논문은 CGAN을 base로 하며 CGAN의 기반이 되는 GAN 모델의 objective loss는 아래와 같음.
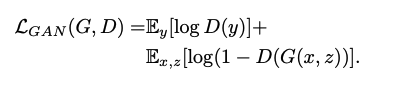
- 일반적으로 GAN의 Loss는 Generator G에 대해 minimize하고, Discriminator D에 대해서는 Maximize를 시키며 서로 대칭적 학습을 진행함.
- 즉 G는 생성한 이미지가 D가 진짜인지 가짜인지 판별할 수 없을 정도로 real한 이미지를 생성하는데 최적화되며, D는 G가 만든 fake 이미지를 최대한 잘 판별할 수 있도록 학습되어진다.
- 본 논문의 base가 되는 CGAN은 기존 GAN의 loss function에서 condition x만 추가된 형태임.
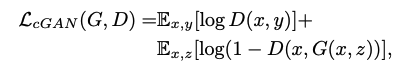
- 기존 GAN에서 생성하는 Output image는 어떤 image가 생성될지 예측 및 제어가 불가능했는데, condition x를 추가하면서 원하는 class의 정보를 D와 G의 input에 동시에 넣어주게 되고 따라서 Generator가 생성하는 image를 제어가 가능하게 만들 수 있음.
- 본 논문인 Pix2Pix 모델에서 사용되는 최종 Loss는 아래 수식과 같이 CGAN loss를 base로 하며 L1 loss를 추가하여 함께 사용하고 있다.
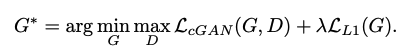
- Pix2Pix에서는 학습과정에서 input image x 자체를 condition x가 됨.
- 선행연구에서 tradition loss 와 GAN loss를 함께 사용하는 것이 효과적으로 나타났기 때문에, L1 loss항을 추가하였음.(L2보다는 L1이 output image 결과가 blur 될 확률이 낮기 때문이 L1 사용) 이로인해 G가 D를 속이는 것 뿐 아니라 ground truth 이미지와도 비슷해지도록 학습됨.
- 또한 기존에 일반적으로 사용된 random noise z를 사용하지 않음. 그 이유는 G가 noise를 무시하도록 학습이 되기 때문인데, z를 사용하지 않음으로서 deterministic한 결과를 생성함.
3.2 Network Architectures
- Pix2Pix는 이미지를 조건으로 받아, 이미지를 출력으로 내보낸다.
- 이를 효과적으로 처리할 수 있는 U-Net 기반의 네트워크 아키텍처를 사용하고 있음.
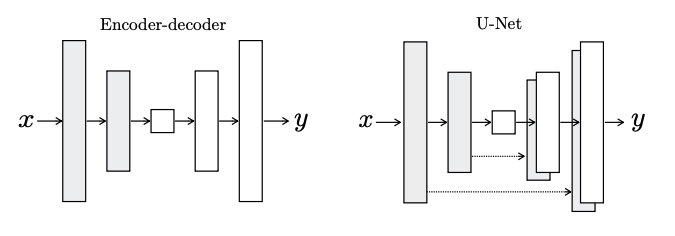
- Image-to-Image Translation 에서는 structure를 그대로 유지하면서 surface apperance만 바꾸어 input의 structure가 거의 그대로 Output에 사용되는 특성을 가짐.
- 이를 기반으로 논문에서는 Encoder-Decoder network에 residual connection을 사용하여 input information을 공유하고 채널들끼리의 단순 concat을 통해 decoder의 feature와 합치게 됨.
- Pix2Pix 모델의 Discriminator는 convolutional PatchGAN 분류 모델을 사용함.
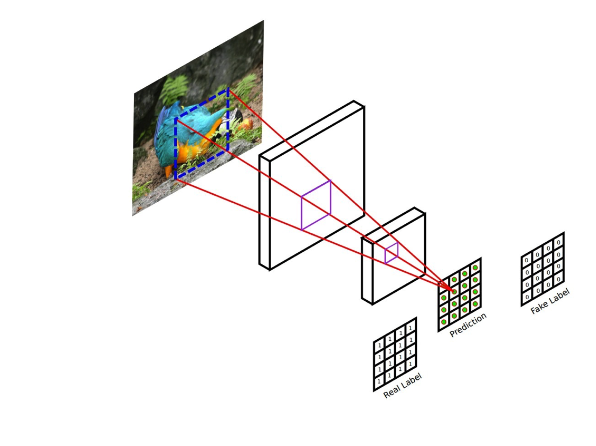
- 이미지 전체에 대해 진위를 판별하지 않고, 이미지 내 N*N 패치 단위로 진짜/가짜를 판별
- patch size N은 전체 이미지 크기보다 훨씬 작으므로 더 작은 parameter와 빠른 predict 시간을 가지는 것이 장점.
3.3 Optimization and inference
- 본 논문에서 제안한 방식은 train 과정에서 몇가지 특이한 점을 가짐.
- Generator G를 학습할 때 log(1-D(x,G(x,z))를 minimize하기 보다는 log(D(x, G(x,z))를 maximize하도록 함.
- Discriminator D를 학습시킬 때 목적함수를 2로 나누어 Generator G보다 더 천천히 학습되도록 함.
-> 이는 학습 초기에 Generator가 가짜 이미지를 너무 못 만들기 때문에 상대적으로 Discriminator D의 task가 쉬워서 학습이 진행되지 않는 문제를 해결하기 위함이라고 생각됨.
- 또한 Test 과정에서 특이한 점은,
- Dropout 그대로 사용
- Batch Normalization에서 train batch의 statistics을 사용하지 않고 Test batch의 statistics을 사용
-> Stochastic을 더해주기 위함으로 생각
4. Experiments
-
Segmantic images -> 실제 image로 Translate

- L1 + CGAN loss를 함께 사용하였을때 가장 높은 성능을 보이며, 퀄리티 측면에서도 좋은 것을 확인 가능
- CGAN loss만을 사용하였을 때 좀 더 선명한 결과가 나오지만, 이미지의 인공적인 왜곡이 생기는 문제가 발생
-
Encoder+Decoder와 U-Net 구조를 비교하였을 때, detail 측면에서 큰 차이를 볼 수 있다.

- patch size를 변경하면서, 1x1의 경우 매우 blurry한 것을 볼 수 있고 16x16은 충분히 sharp하지만 artifacts가 다수 생겨났고 70x70 일 때 그러한 artifacts가 사라진 것을 볼 수 있다. 마지막으로 full image인 286x286에 대해서는 quality 측면에서 큰 변화가 없고 오히려 FCN-score가 낮은 결과가 나왔다. 저자들의 추측으로는 full image GAN이 70x70 PatchGAN보다 훨씬 많은 파라메터 수와 더 큰 depth를 가지고 있기 때문에 학습이 더 어려워 나타난 결과라고 함.
Conclusion
- 본 논문에서 발표한 pix2pix의 첫 발표 이후 community에서 다양한 모델이 나옴.
ex) 스케치를 고양이로 바꾸거나, 배경을 지우거나, 스케치를 초상화 등으로 바꾸는 등 - pix2pix는 단순히 label과 image 간을 상호 변환하는 모델이 아니라, 일반적인 image-to-image translation 문제를 해결할 때 사용할 수 있다는 가능성을 보여준 논문임.
출처(참고자료)

📚 IT 지식과 최신 기술 트렌드, 금융 관련 내용을 공유합니다.