Abstract
- 해당 논문은 ViT에서 모든 패치가 self attention을 수행하는 것이 계산량을 불필요하게 증대시켜 computation cost가 높아진다는 문제점을 언급하며, 각 patch를 window로 나누어 해당 윈도우 안에서만 self attention을 수행하고 그 윈도우를 한번 shift 후 다시 self attention 하는 구조를 제안함.
- 또한 일반적인 Transformer 구조와 다르게 Hierarchical 한 구조를 제안하면서 Image Classification 뿐 아니라 Object Detection, Segmentation 등에서 백본 모델로 활용되어 좋은 성능을 나타냄.
Introduction
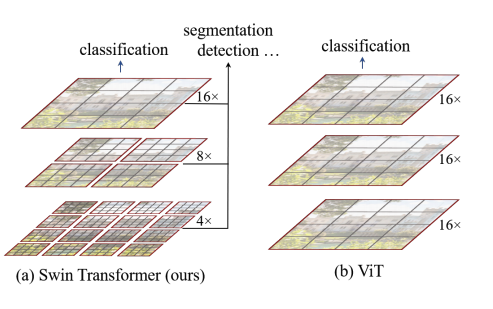
- 위 그림에서 ViT를 나타내는 오른쪽 그림은 각 패치 사이즈를 16*16으로 동일하게 만들어 유지하고 각 패치와 나머지 전체 패치에 대한 self attention을 수행하는 구조임.
- 그러나, 본 논문에서 제안하는 Shifted Window 방식은 작은 4*4 패치 사이즈에서 시작하여 점점 각각의 패치들을 merge 해나가는 방식으로 동작함. 빨간색으로 구분된 각각의 패치들을 window라고 부르며, Swin Transformer 모델에서는 각 Window 내 patch들 끼리만 Self-Attention을 수행함.
- 본 논문에서는 이렇게 패치들 끼리 merge 하였을때 효과로, hierarchical representation을 학습시킬 수 있다고 제안하며, 이는 FPN 구조나 U-Net과 같은 모델처럼 다른 해상도에서 얻은 정보들을 같이 고려하는 것과 같은 맥락이라고 볼 수 있음. 또한 Image resolution이 커지더라도 패치 크기가 Linear 하게 complexity를 가지게 되므로 quadratic하게 complexity가 증가하는 기존의 Transformer 기반 모델들과는 큰 차이가 있다고 볼 수 있음.
Method
- Swin Transformer의 Overall Architecture는 아래 그림과 같음.
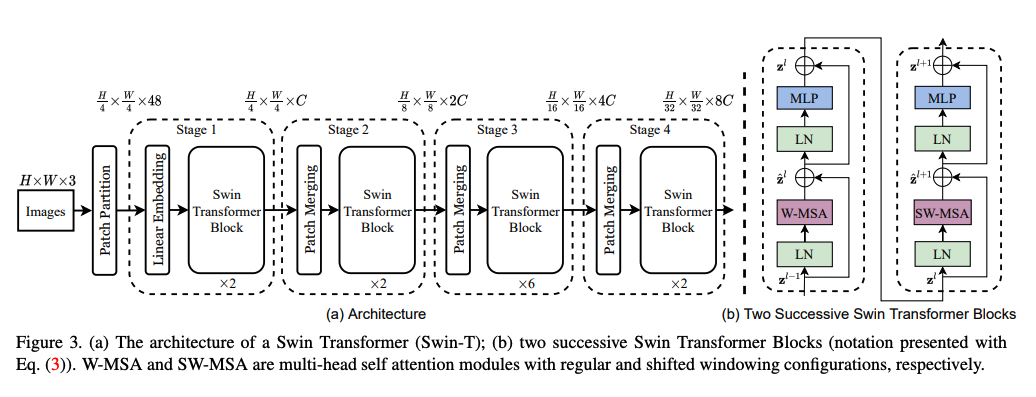
- 위 구조에서 확인할 수 있듯이, 크게 Patch Partition, Linear Embedding, Swin Transformer, Path Merging으로 구분이 되며 4개의 Stage로 이루어짐.
- 본 논문의 핵심 Contribution인 Swin Transformer Block은 두개의 Encoder로 묶인 구조이며 Transformer 모델에서 사용되는 Multi Head Self Attention이 아닌, W-MSA & SW-MSA로 이루어져 있다.
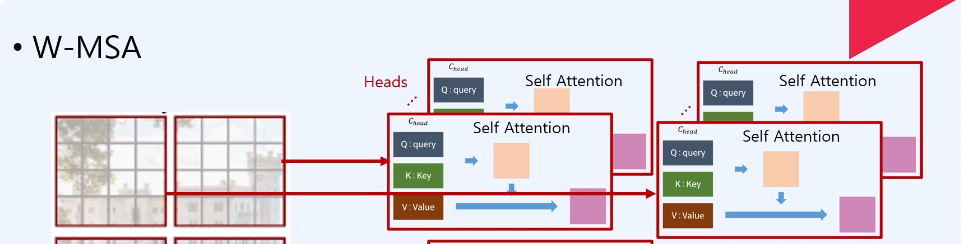
- W-MSA(Windows-Multi Self Attention) : Local Window 내에서 self attention 수행. 즉 현재 윈도우 내에 있는 패치들끼리만 Self attention을 수행하는 개념으로, 이미지는 주변 픽셀들끼리 서로 연관성이 높으므로 윈도우 내에서만 self-attention을 써서 computation cost를 효율적으로 관리할 수 있음. 기존의 Multi-head attention은 image resolution이 증가하면 quadratic하게 복잡도가 증가하지만, 이 방법으로는 linear 하게 복잡도가 증가하게 되는 원리. 따라서 기존 Transformer 동작방식보다 scalable 하다는 점이 강점이다.
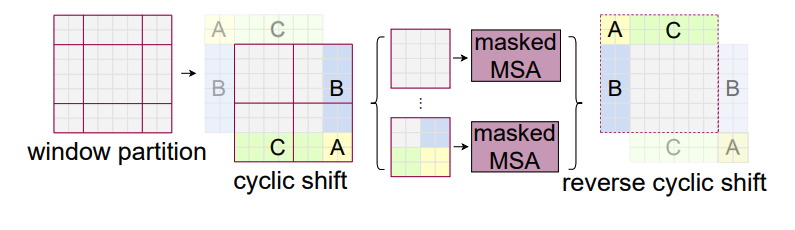
- SW-MSA(Shifted Windows-Multi Self Attention) : 위 W-MSA 방식대로 단순히 window 내에서만 attention을 수행하게 되면 window 간 connection에 대한 고려가 부족해지는 문제점이 발생함. 이렇게 된다면 이미지의 global한 feature들을 고려하기 어려워질 것이며 따라서 computation cost를 효율적으로 가져가면서 동시에 windows간 connection을 고려하여 global한 Feature를 추출하기 위해 본 논문에서는 Cyclic Shift, Reverse Cyclic Shift를 통해 윈도우를 이동시키며 Local Window 간의 연결성 부여해줌.
- W-MSA(Windows-Multi Self Attention) : Local Window 내에서 self attention 수행. 즉 현재 윈도우 내에 있는 패치들끼리만 Self attention을 수행하는 개념으로, 이미지는 주변 픽셀들끼리 서로 연관성이 높으므로 윈도우 내에서만 self-attention을 써서 computation cost를 효율적으로 관리할 수 있음. 기존의 Multi-head attention은 image resolution이 증가하면 quadratic하게 복잡도가 증가하지만, 이 방법으로는 linear 하게 복잡도가 증가하게 되는 원리. 따라서 기존 Transformer 동작방식보다 scalable 하다는 점이 강점이다.
Contribution
- Swin Transformer는 local attention을 window로 나누어 각 windows 내에서 수행하며 효율적인 계산과 함께 multi scale을 고려한 계층적으로 잘 구성된 모델을 제안하였음.
- ImageNet을 통해 학습된 모델을 Backbone으로 사용하였을 때, Object Detection, Segmentation 쪽에서도 SOTA를 달성하였고 다양한 Vision Task에서 EfficientNet B7을 능가하거나 맞먹는 수준의 높은 성능을 보여줌.

📚 IT 지식과 최신 기술 트렌드, 금융 관련 내용을 공유합니다.