[배경지식]
- Instance Segmentation : 각 픽셀마다 픽셀이 어떤 class에 해당하는지 예측하는 작업 수행(일반적인 segmentation 이라고 불림). 즉 이미지 내에 있는 각 물체들을 의미 있는(Semantic) 단위로 분할(Segmentation)하는 작업을 말함. 단, 같은 클래스 내에서 물체를 구분하지는 않음!!
- 결과적으로 이미지가 주어졌을때 이미지의 각 픽셀마다 클래스가 할당되며, 한장의 segmentation map을 생성
- (장점) 일반적인 CNN 분류 모델의 구조와 유사하며 네트워크 구조가 어렵지 않다.
- (단점) segmentation 학습을 위한 데이터셋 생성 비용은 매우 비쌈....각 픽셀마다 어떤 class에 분류되는지 일일이 labeling을 해주어야 하기 때문
- U-Net : Biomedical 분야에서 image segmentation 수행을 위해 제안된 Conv net이다.
[논문 요약]
1. 제안된 모델구조
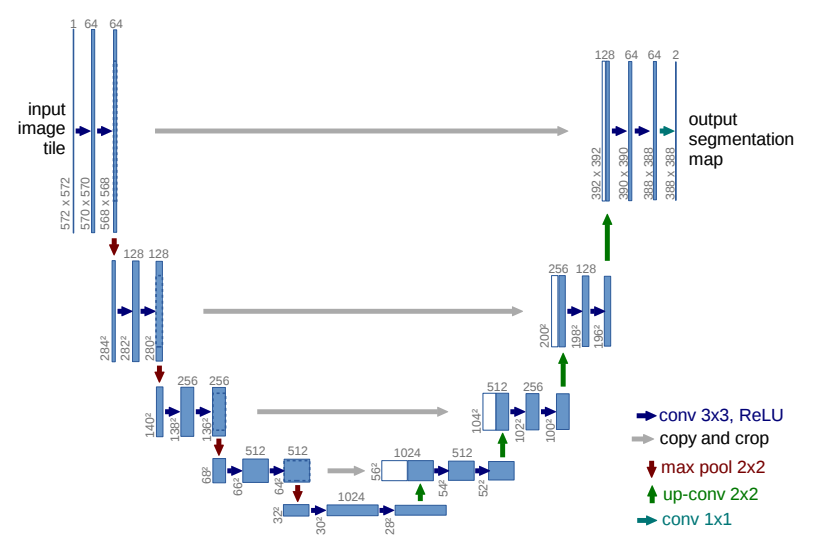
- 본 논문에서는 U자 형태로 생긴 네트워크인 U-Net 아키텍처를 제안
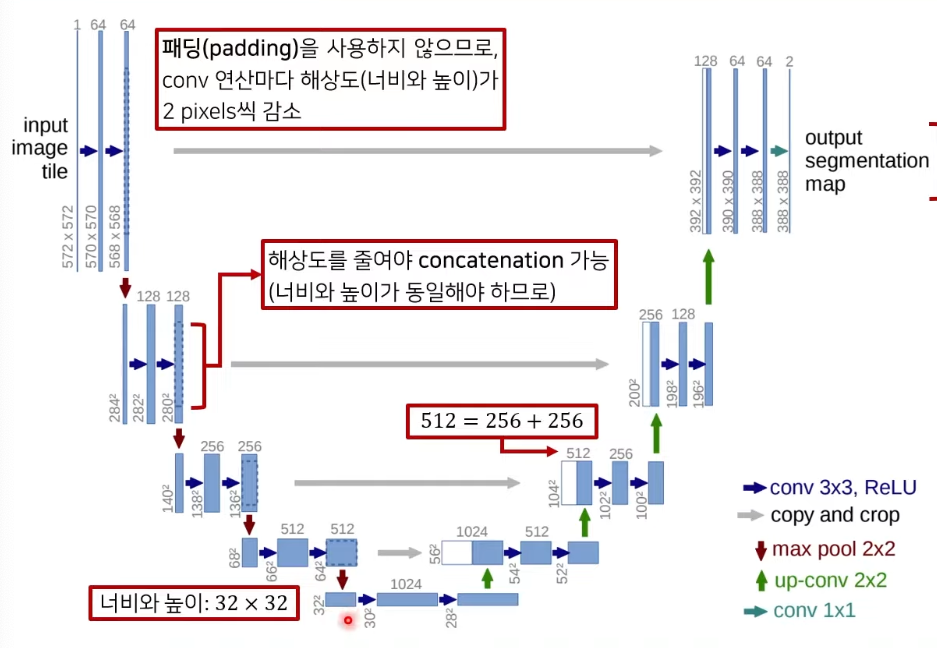
- 모델의 Input data와 Output Data의 형태를 보면 U자형의 앞선 절반에서는 해상도가 점차 줄어들었다가, 이후 절반 부분에서는 다시 해상도가 원래 이미지 수준으로 증가하는 형태를 보임.
- 기존의 Image Classification 모델에서 이미지를 단순 분류할때는 Input Image의 Dimension을 점차 줄여서 분류하고자 하는 class 갯수와 같은 Dimension으로 만드는 것이 일반적이지만, Image segmentation에서는 전체 이미지를 단순히 분류하는 것이 아니라 Input Image의 각 픽셀별로 Class가 할당된 Output Image가 나와야하기 때문에 Image Dimension을 복구시켜주는 구조를 추가함.
- 수축경로(Contracting path) : 이미지의 Dimension이 줄어드는 부분으로, 이미지에 존재하는 넓은 문맥 정보를 처리 -> Down Sampling Conv 연산 수행(일반적인 classification task에서 수행되는 conv 연산)
- U-Net 아키텍처의 앞선 절반 부분에 해당
- 2x2 Max Pooling 사용하여 Image Dimension이 2배씩 감소함.
- 일반적인 Conv 모델 구조처럼, Conv연산 -> ReLu -> Max Pooling 반복. 따라서 실제 U-Net 사용할 때 수축경로의 모델은 Pre-trained 된 Conv 모델을 그대로 가져와 Encoder 역할로 사용하는 경우도 많음!!
- 확장경로(Expanding path) : 이미지의 Dimension이 다시 증가(복구)되는 부분으로, 픽셀별로 할당한 클래스의 정밀한 지역화가 가능하도록 함. -> Up Sampling 연산 수행
- U-Net 아키텍처의 후반 절반 부분에 해당
- 2x2 Up Convolution(Up Sampling) 사용하여 Image Dimension이 2배씩 증가
- 수축경로에서 처리된 Feature map을 그대로 가져와서 확장경로 연산에 사용하여, 앞서 수행한 연산을 통해 추출된 이미지의 특성을 가져와서 사용할 수 있으므로 보다 좋은 학습결과를 얻을 수 있음.(ResNet에서 Residual Connection의 역할과 비슷하다고 할 수 있음)
- 제안된 U-Net은 Image Segmentation을 목적으로 만들어진 모델로, 최종 layer에서 별도의 FC Layer가 필요하지 않음. 따라서 Fully Convolution Network 구조로 구성됨.
- 위 이미지에서 Data Dimension 변동 결과에서 알 수 있듯이, U-Net에서는 Output Image의 해상도가 Input Image의 해상도보다 작음. 즉, 출력결과로 얻고싶은 Output Image 영역보다 더욱 큰 사이즈의 Image를 Input Image로 넣어주어야 한다. 이미지가 겹치는 부분에 대해선 Extrapolation 사용함.
- Object Function
- Image 픽셀별 class 할당을 위해, 픽셀 단위로 확률값을 출력하도록 픽셀 단위의 Softmax 함수 사용

- Loss Function : 학습을 위해 cross-entropy 손실 사용. 단 추가적인 가중치(weight) 함수를 사용(각각의 픽셀마다 가중치 부여해서 학습이 더 혹은 덜 수행되도록 하기 위함)
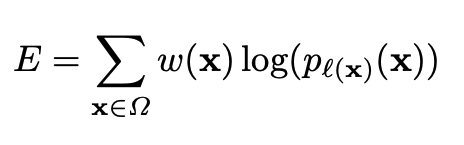
- 각각의 class 구분 간 서로 인접한 class 사이에 있는 배경 label에 대해 높은 가중치를 부여하여 명확한 분리를 위해 가중치 함수 사용
- 레이블링 된 데이터가 적을 때 효율적인 데이터 Augmentation 기법 제안
- 의료데이터 특성상 labeling 된 데이터의 수가 매우 적어 효율적 학습을 위해서는 Data Augmentation 필요.
- 본 논문에서는 일반적인 Data Augmentation 기법(rotate, contrast 등)도 사용하면서 추가적으로 Elastic Deformation 방법을 사용함.
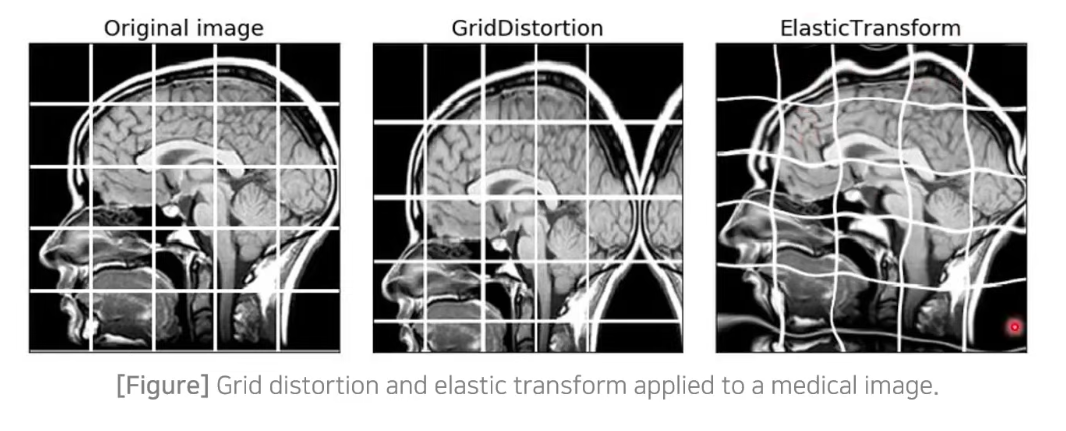
- Elastic Deformation : 간단히 말해서, 각각의 grid로 구분된 image에 대해 비선형적인 변형을 줌.
[출처]

📚 IT 지식과 최신 기술 트렌드, 금융 관련 내용을 공유합니다.