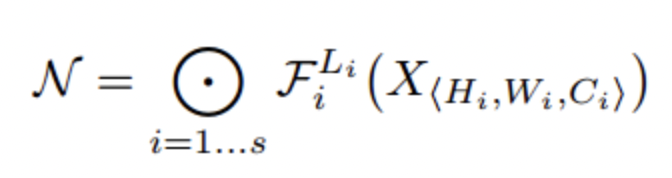
[Abstact]
기존의 CNN 모델들과는 다른, 새로운 scaling 방법을 제안하는 이 모델은 모든 차원의 depth, width, resolution의 scale을 통일시켜요.
기존의 MobileNets과 ResNet의 방법에서 착안된 EfficientNet은 ImageNet에서 정확도 84.3%로 가장 높다고 합니다.
1. Introduction
일반적으로 모델의 성능을 높이기 사용하는 scaling up을 방법은 세 가지가 있어요.
- Network Depth
- Channel Width
- Image Resolution
Network의 Depth를 깊게 하는 방법이 첫번째 방법인데요, ResNet의 발전 동향을 보면 ResNet-18부터 ResNet-200은 이 Depth를 깊게하면서 성능을 올린 케이스랍니다. 그리고 Channel의 Width를 크게 하는 방법과 아주 보편적이지는 않지만 Image Resolution(해상도)를 높이는 방법도 있어요.
하지만 이러한 작업들은 왜 성능을 높이는 지는 아직 잘 모르는 상태라고 해요.
해당 방법이 성능을 높이는 데에는 효과가 있다는 것을 ResNet과 MobileNet을 통해 알아보았으니 이 논문에서는 Scaling up하는 과정 중 성능을 높이는 중요한 방법이 무엇인지 연구를 합니다.
단순히 높인다고 성능이 좋은 건 아니기에, optimal한 지점을 찾으려면 상당한 노력이 필요해서 이 부분을 좀 더 효율적으로 찾는 거에 중점을 둔 거라고 생각해요.
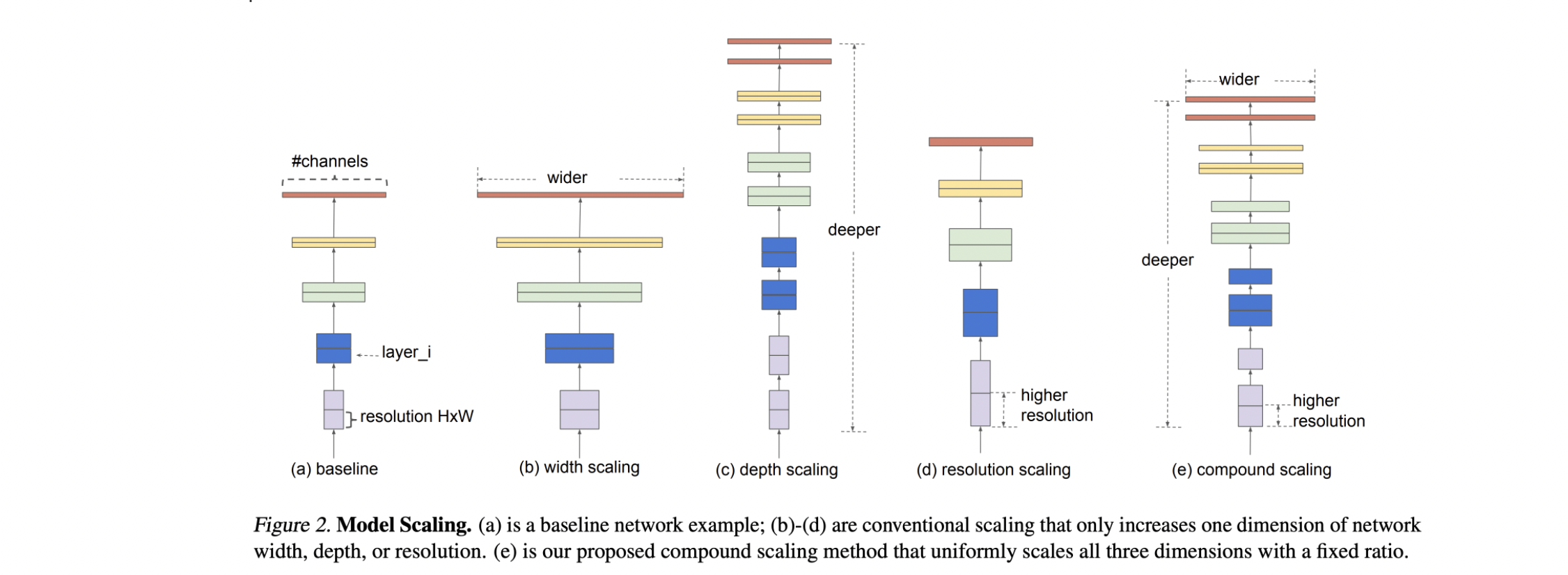
해당 그림은 앞서 말한 세가지 방법을 그림으로 표현한 것입니다.
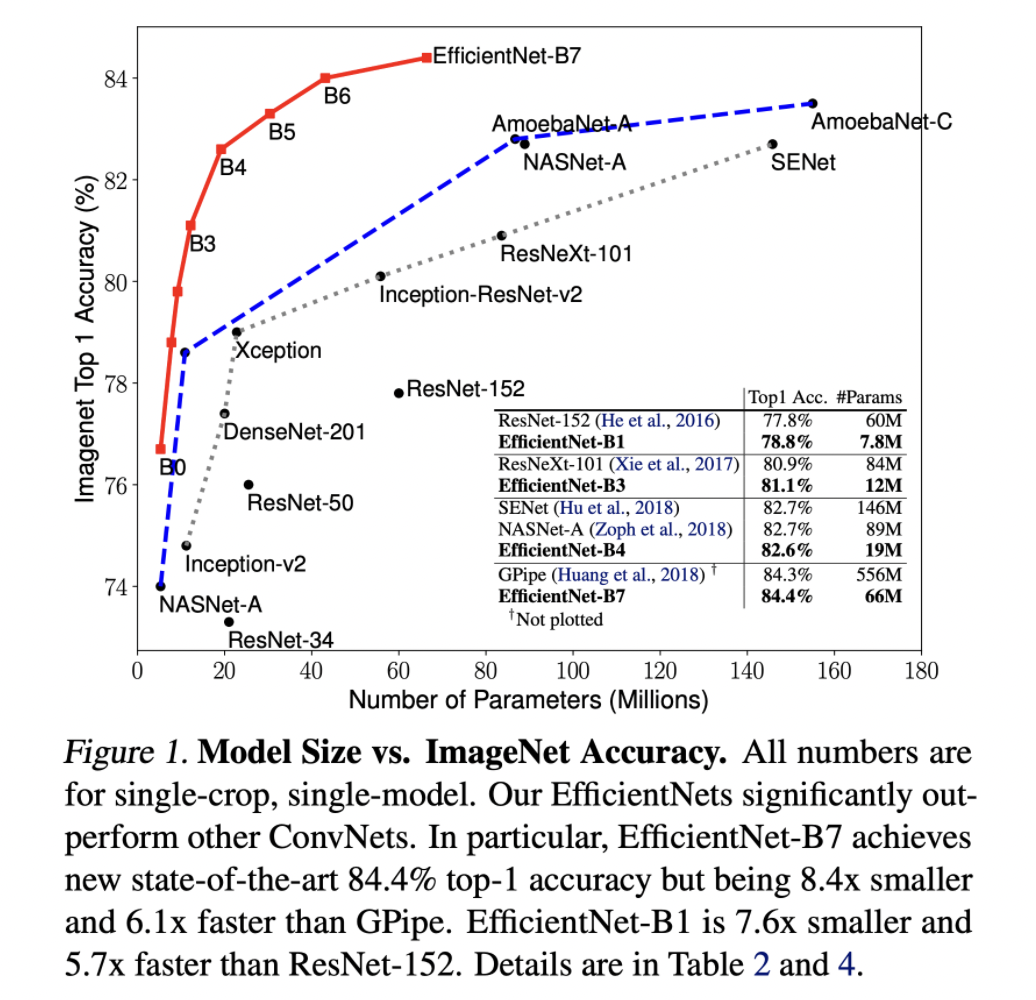
이 논문에서 말하는 EfficientNet-B7은 GPipe에 비해 높은 정확도를 보이지만 Parameter수는 1/8정도로 적고 inference 실행 시간도 6배나 따르다고 해요.
inference : 학습을 통해 만들어진 모델을 새로운 입력 데이터에 적용하여 결과를 내놓는 단계
2. Related Work
-
ConvNet Accuracy :
최근에 나온 GPipe같은 경우 84.3%의 정확도를 보이지만 557M개의 Parameter를 사용하여 모델 자체가 굉장히 무거워요.
계속해서 성능이 좋아질 수록 모델의 크기가 커지고 있는데, 이미 하드웨어의 기술력은 한계에 다다랐다고 해요..!
그렇기 떄문에 여기서 성능을 더 높이기 위해서는 efficiency를 고려를 할 수 밖에 없는 상황인 것이죠. -
ConvNet Efficiency :
깊은 CNN 신경망은 대부분이 overparameterization 되어있어요.
이걸 효율적으로 해결하는 방안이 보통 두 가지가 있는데요- Model Compression : Reduce model size
- NAS (Neural Architecture Search)
하지만 위와 같은 방법은 큰 모델에 적용시키는 부분이 아직 명확하지 않아서 써먹기가 힘들어요. 논문은 이 부분을 연구하는 내용입니다.
-
Model Scaling :
width와 depth의 scaling에 대해 앞서 말한 내용을 다시 말하고 있어요.
input image의 크기가 클수록 FLOPS 연산량이 많아져서 효율적으로 scaling을 한다고 말이죠.
3. Compound Model Scaling
-
3.1 Problem Formulation

기본적인 CNN을 식으로 표현하면 위와 같아요.
여기서 i는 하나의 stage를 뜻하는데 아래의 ResNet구조에서 channel의 크기가 같은 부분을 한 stage라고 해요.
하나의 stage에 5개의 Layer가 있으니 구조는 이해가실거라 생각합니다.

보통 F의 구조를 바꾸면서 optimal한 CNN을 디자인하려하지만 이 논문에서는 scale에 집중하기 위해 F를 고정시켜 버립니다.
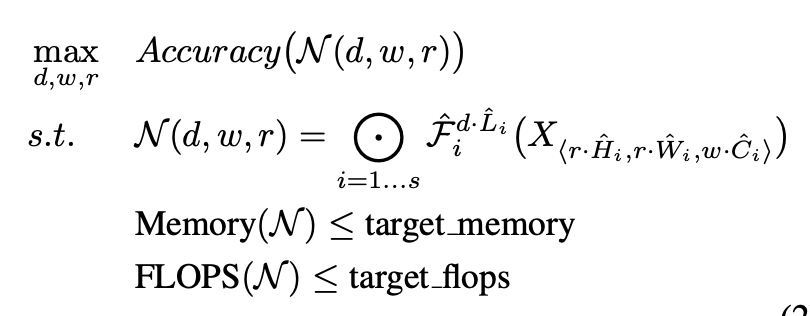
은 depth, width, resolution의 Scaling 계수이고, 는 pretrained된 parameter에요.
는 layer의 개수와 연관이 있으니 에 곱해주고,
은 이미지의 크기와 연관이 있으니 에 곱해주고,
는 channel과 연관이 있으니 에 곱해줘서 Scaling 작업을 해준다는 걸 수식으로 표현한 거랍니다.
이 작업들의 목표가 Efficiency니깐 목표로 하는 memory와 FLOPS는 기존보다 작아야겠죠?
- 3.2 Scaling Dimensions
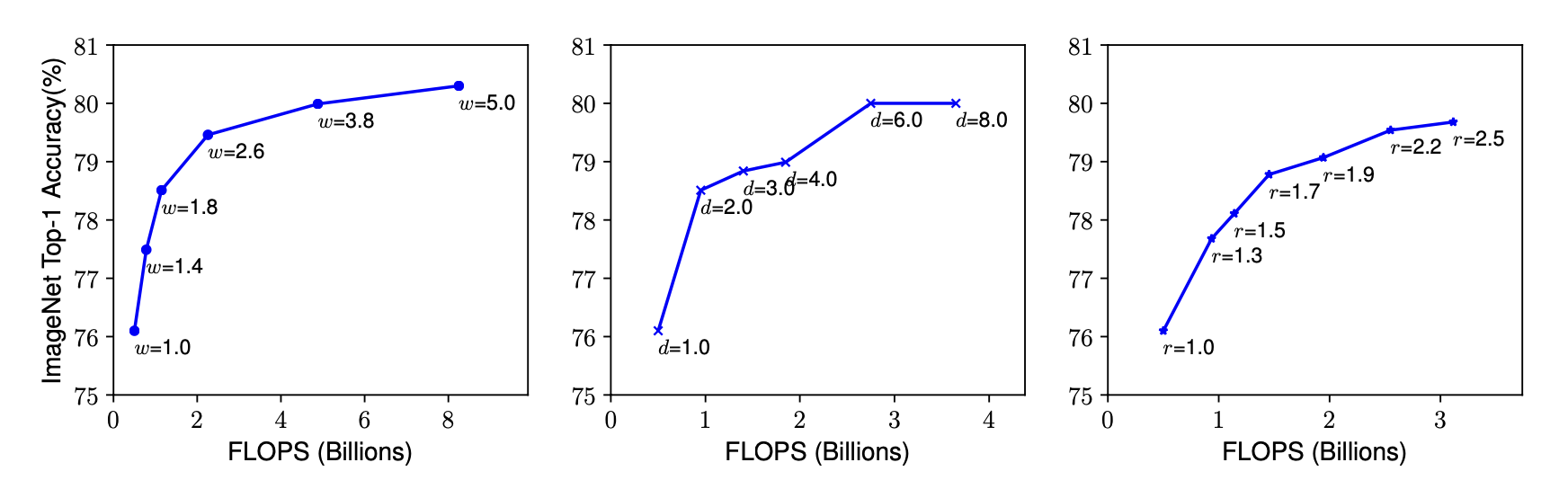
- Depth
직관적으로 보면 망의 깊이가 깊을수록 저 복잡한 정보를 얻을 수 있기 때문에 정확도가 오르지만, 과도하게 늘린다면 Vanishing Gradient문제가 생기게 됩니다. - Width
Channel을 늘리게 되면 model의 크기를 좀 줄이는 경향이 있어요. 이 부분은 Parameter수가 과도하게 늘어나는 것을 방지하기 위해서라고 생각해요. channel이 많아졌으니 좀 더 세밀한 정보를 얻을 수 있으나 모델의 깊이가 얕기 때문에 고차원의 추상적인 특징들은 잡아내기 어렵다는 단점이 있답니다. - Resolution
고수준의 해상도는 좀 더 세밀한 정보를 얻을 수 있어서 최근에 발표된 논문들을 보면 입력 resolution이 이전에 비해 되게 높다고 해요. (224x224 -> 600x600)
그러나 높아질수록 정확도가 증가하는 폭이 점점 줄어드는 것을 위의 그래프에서 확인 할 수가 있어요. - Observation
Scaling up any dimension of network width, depth, or resolution improves accuracy, but the accuracy gain diminishes for bigger models.
- Depth
-
3.2 Compound Scaling
-
다른 Scaling demension들은 서로 독립적이지 않은 것을 관찰할 수 있어요.
Input image가 크다면? -> Receptive Field가 커버하는 부분이 적어져서 Depth를 늘린다 + Fine-grained_세밀한 패턴을 보기 위해 Width를 늘린다.
이러한 이유로 우리는 각 Scaling 값들의 balance를 맞출 필요가 있어요.
-
Observation2
In order to pursue better accuracy and efficiency, it is critical to balance all dimensions of network width, depth, and resolution during ConvNet scaling.
-
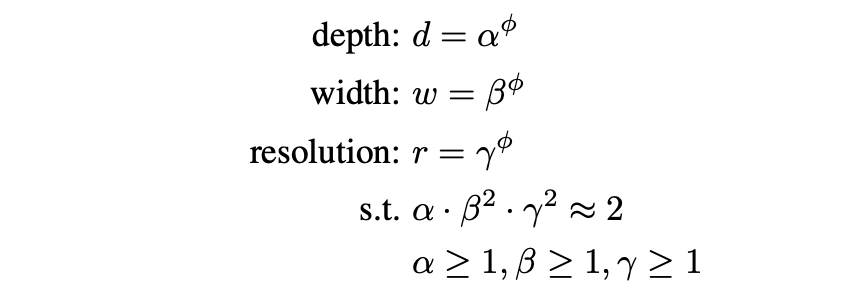
각 연산량은 위와 같이 비례해요.
α β γ는 각각 optimal parameter를 찾는 방법인 Grid Search를 통해 구한 값이고,
φ는 사용자의 resource에 따라 임의로 설정하는 값이에요.
보면 depth는 크기가 커질수록 연산량이 1:1로 비례하는데 나머지 두 개는 제곱비례를 하는 것을 확인할 수가 있어요.
우선 Depth는 늘리는 만큼 연산이 증가하니 1:1 비율이 맞고,
resolution은 2배로 키운다면 가로, 세로가 다 늘어나므로 제곱 비례하는 것은 자명하죠?
width는 아래 그림을 보면 쉽게 이해가 갈 거라 생각합니다.

4. EfficientNet Architecture
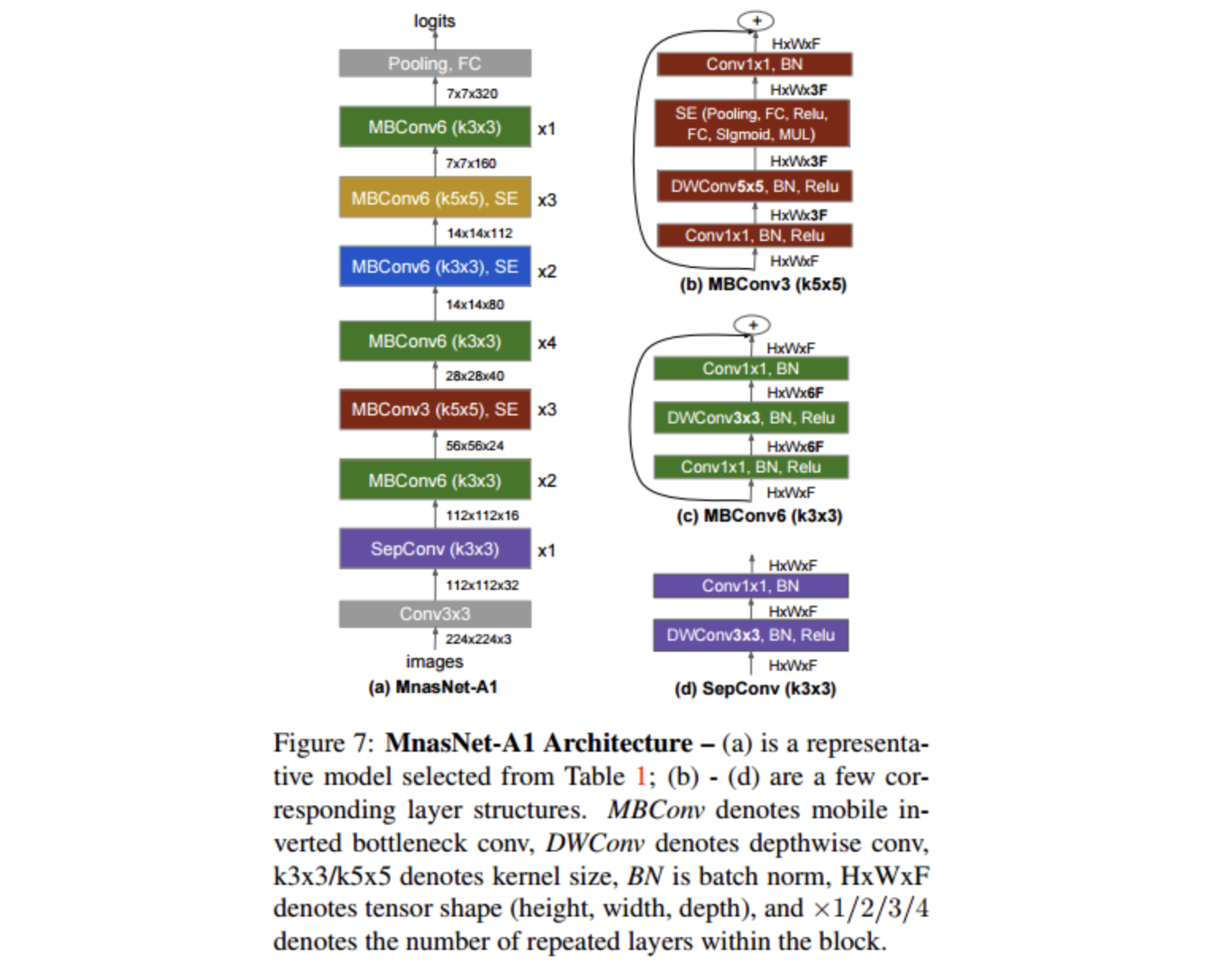
해당 모델은 MNasNet과 유사한 구조를 가지는데 MNasNet의 구조는 아래와 같아요.
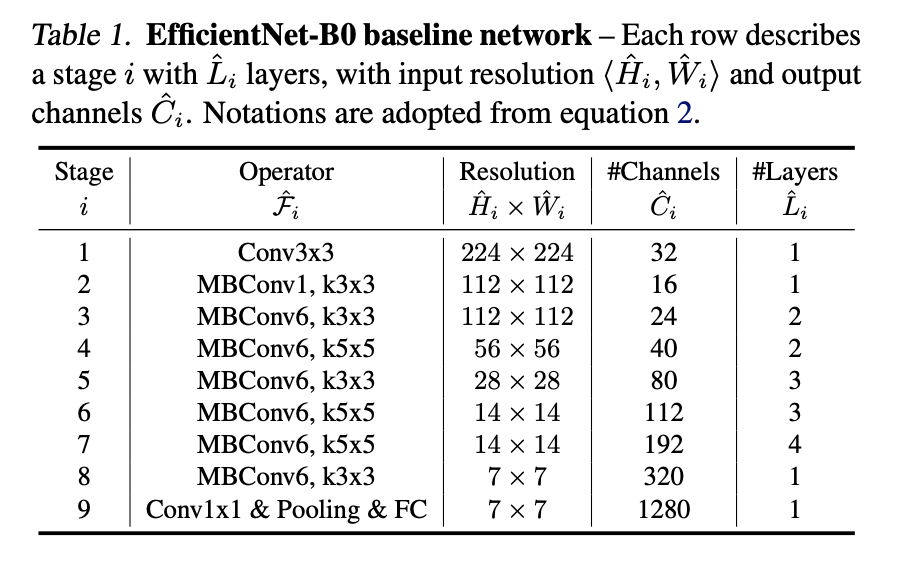
그리고 EfficientNet의 Baseline 구조는 아래와 같아요.
여기서 MBConv1, MBConv6의 구조는 아래와 같아요. MobileNetV2에서 사용하는 inverted bottleneck MBConv에서 가져온 내용이라고 해요.
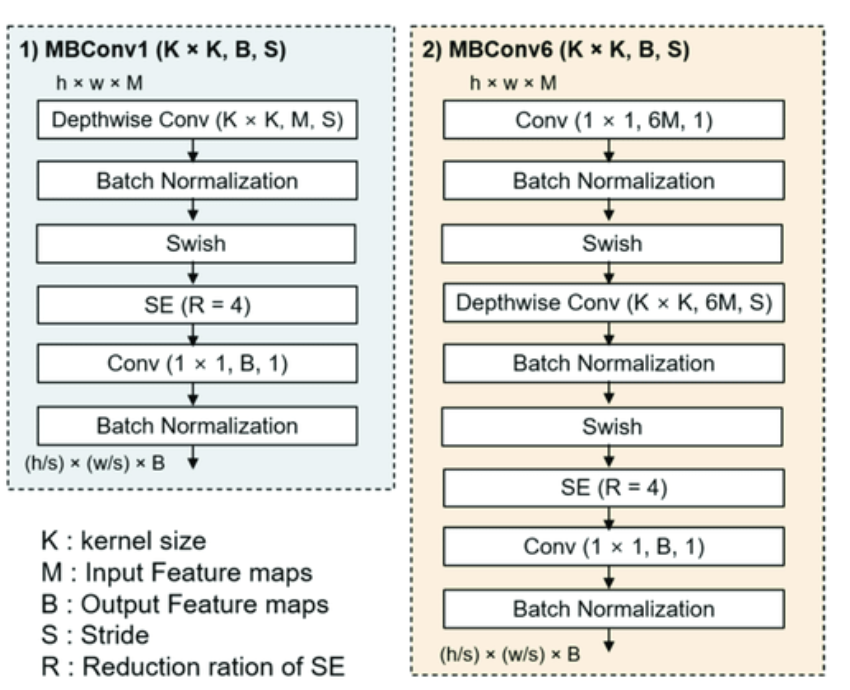
다음으로 해당 Baseline부터 보면 두 가지 step을 통해 Scale을 높이는 방법을 소개해요.
- 먼저 φ를 1로 고정시키고 grid search를 통해 α=1.2 β=1.1 γ=1.15 값을 구해줍니다.
- α β γ를 고정시키고 φ값을 바꿔주면서 EfficientNet-B1부터 -B7까지 구해요.
5. Experiments
-
5.1 Scaling Up MobileNet and ResNets
여기까지 소개한 내용들이 기존 모델에 적용되었을 때 얼마나 효과가 있는지 알아보기 위해 MobileNet과 ResNet에 적용시켜 볼까요?
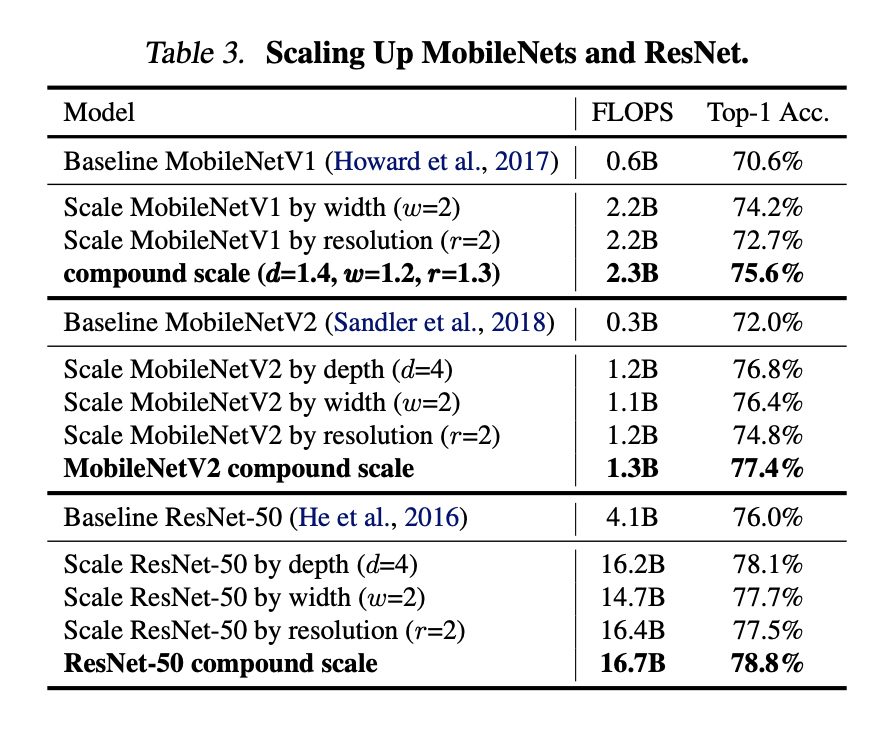
하나의 scale을 올렸을 때보다 compound 방식이 물론 연산량은 좀 많아졌지만 정확도를 확실히 더 높일 수 있다는 것을 확인할 수 있어요.
아래 표는 다른 Network와 비교를 한 표입니다.
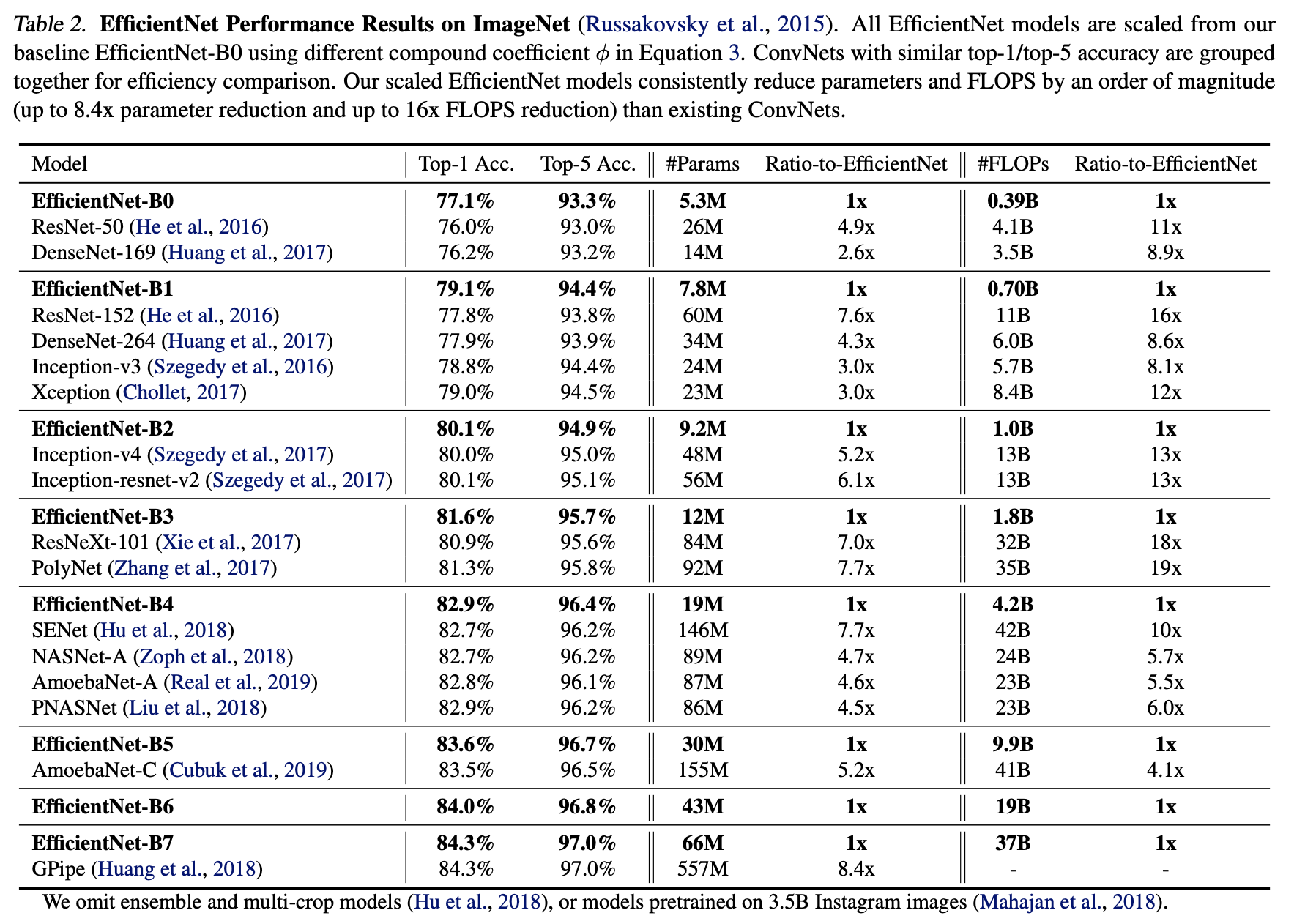
-
5.2 ImageNet Results for EfficientNet
Settings :
- RMSprop optimizer - decay:0.9, momentum:0.9
- batch norm momentum - 0.99
- weight decay - 1e-5
- learning rate - 0.256, decay by 0.97 per 2.4 epochs
- SiLU - Swish activation
- AutoAugment - 강화학습과 유사한 방식으로 data augmentation을 자동으로 해주는 기법
- Stochastic Depth - Random Dropout
- Dropout - 0.2 for B0, 0.5 for B7
- 5.3 Transfer Learning Results for EffiecientNet
이번엔 ImageNet으로 pretrain시키고 다른 데이터셋을 학습한 결과는 아래와 같아요.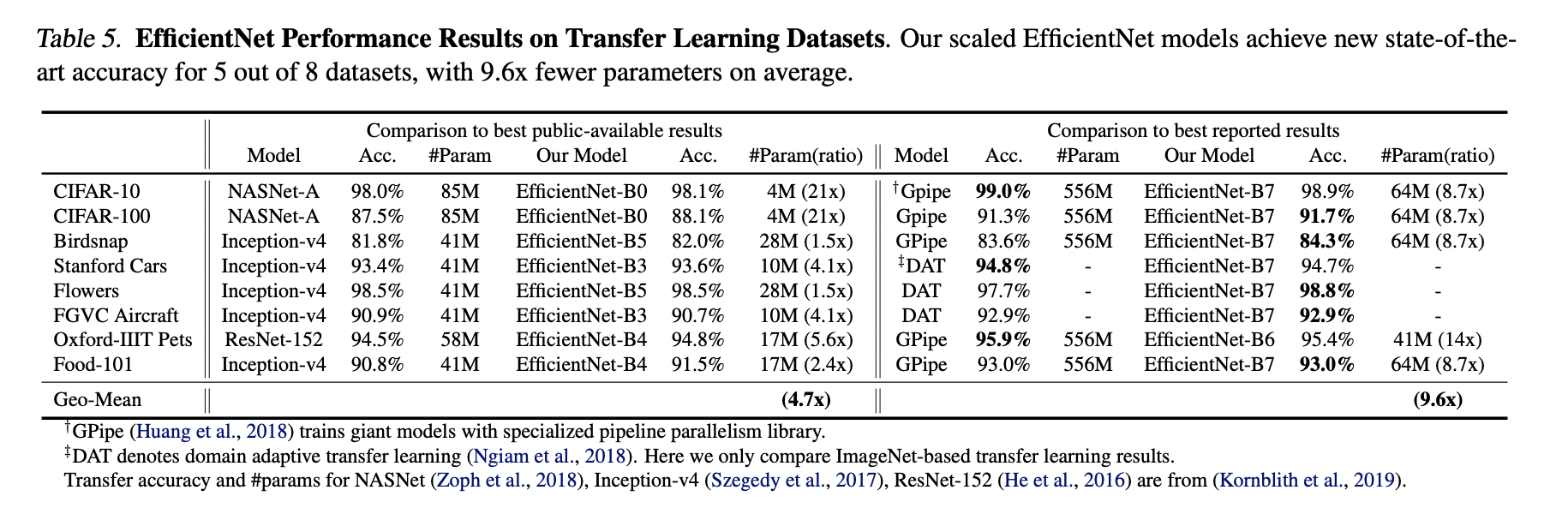
6. Discussion
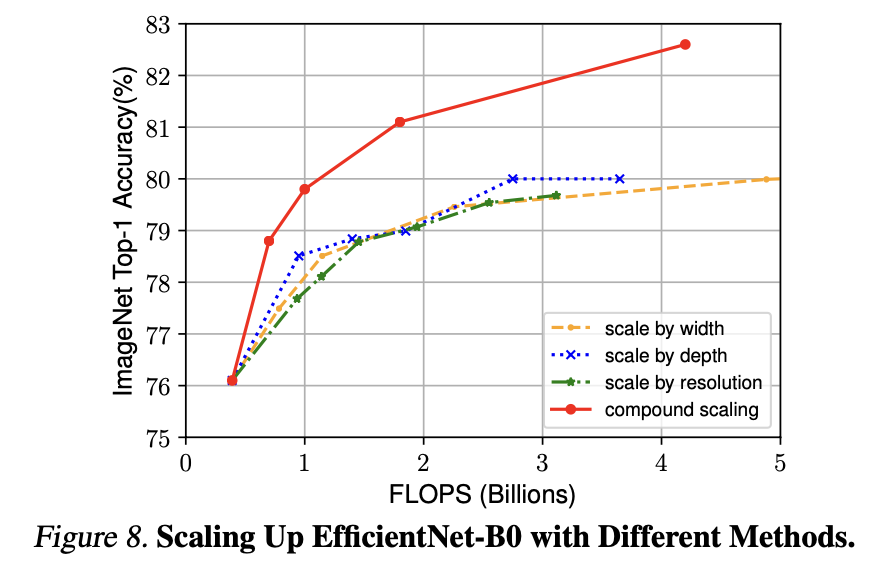 위의 그래프에서 볼 수 있듯이 하나의 scale만 조정하는 것보다 compound scaling 방식의 정확도가 훨씬 좋은 것을 볼 수 있어요.
위의 그래프에서 볼 수 있듯이 하나의 scale만 조정하는 것보다 compound scaling 방식의 정확도가 훨씬 좋은 것을 볼 수 있어요.
왜 성능이 더 좋은 건지 CAM(Class Activation Map)과 표를 통해 확인할 수 있어요.
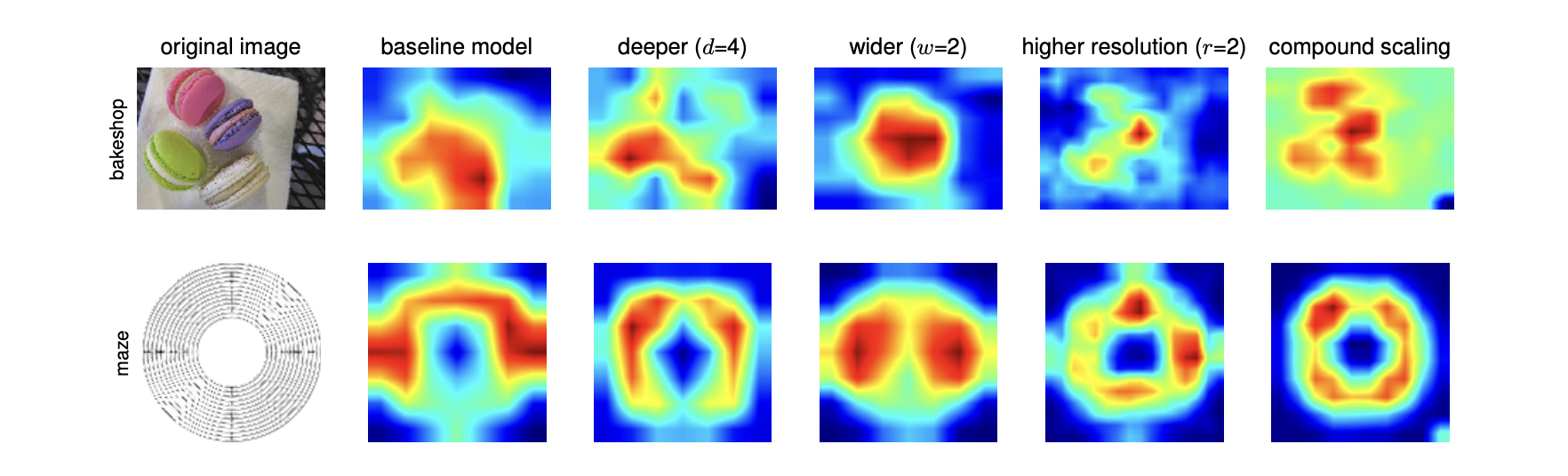
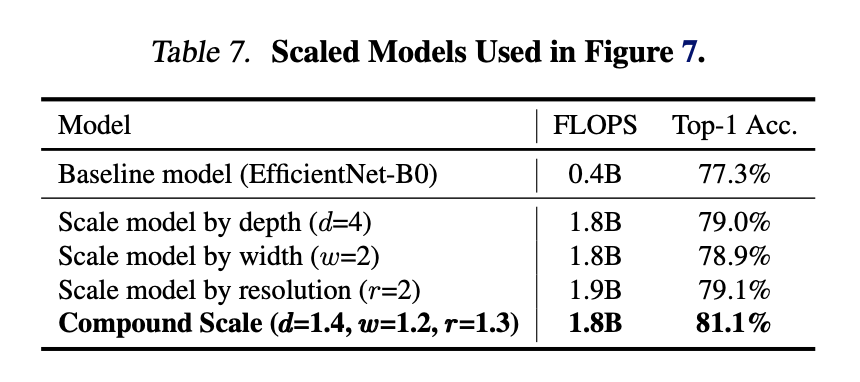
7. Conclusion
Width, Depth, Resolution를 scale하는 방법에 대해 얘기를 하며 효율적으로 성능을 올릴 수 있는 EfficientNet에 소개하는 논문이었습니다.
