
SPSS를 이용한 통계분석 <기초>
- 분산분석 (ANOVA)
통계분석에서 가장 대표적으로 사용되는 분석을 살펴보겠습니다. 통계분석을 하는 의미가 어떠한 차이와 효과가 존재할때 그 '차이'가 과연 의미가 있는 수치인지 아닌지를 객관적으로 증명하는 것이 목적이라고 생각합니다.
-
분산분석은 여러 집단 간의 평균을 비교하는 분석방법입니다. 앞에서 소개해 드렸던 독립표본 t-test의 확장판이라고 생각 할 수 있습니다.
-
귀무가설 : 세집단의 평균은 모두 같다. vs 대립가설 : 모두 같지는 않다. 적어도 한개의 집단의 평균은 다르다. (not H0)
-
Yij : i 번째 집단에서 j번째 관찰.

SST = 전체 평균과의 편차 제곱합
SSE = 그 자료가 속한 집단의 평균과의 편차 제곱합
SSE = 그 자료가 속한 집단의 평균과의 편차 제곱합표에서 집단차이로 인해 생긴 제곱합의 평균(집단 간 분산, MSB)이 동일 집단 내 제곱합의 평균(집단 내 분산, MSE)에 비해 충분히 크다면 집단 간 평균 차이는 의미가 있다고 결론을 내릴 수 있다.(F=MSB/MSE)
SPSS 실습
-
분석 -> 평균비교 -> 일원배치분산분석
-
집단차이로 인해 생긴 제곱합의 평균이 동일 집단 내 제곱합의 평균에 비해 충분히 크다면 집단 간 평균 차이는 의미가 있다.(요인 에는 3개이상 집단으로 나눠진 데이터를 삽입)

-
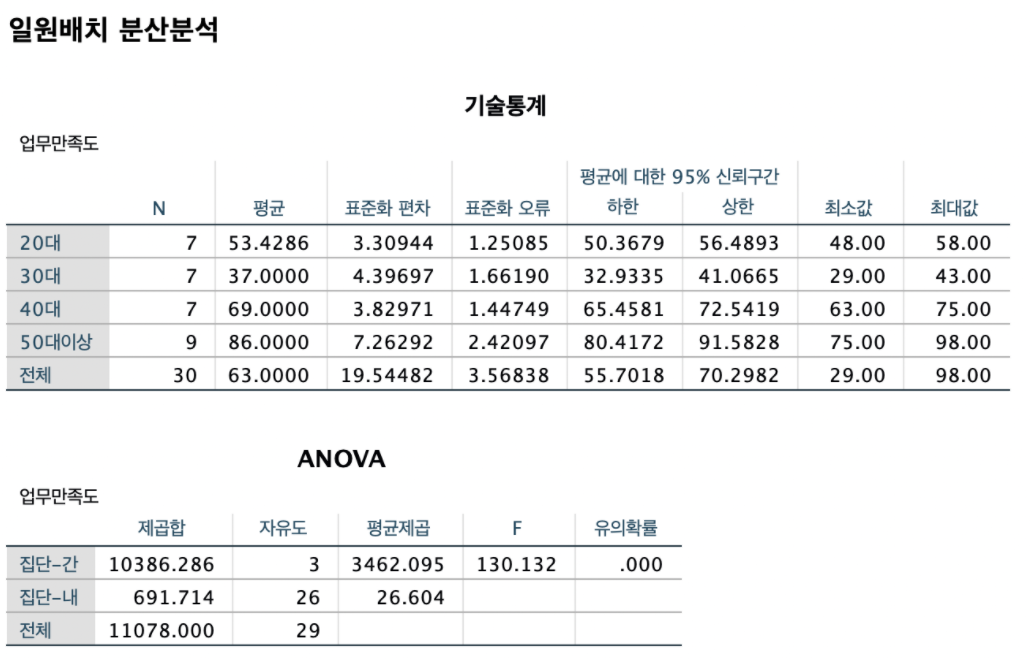
결과를 살펴보면 - F가 130.132이고 유의확률이 0.000이다. 유의확률은 귀무가설이 참일때 집단 간 분산이 집단 내 분산의 130.132배 보다 큰 값이 나올 가능성으로 0%이다.
→ 즉 귀무가설이 참 이라면 연령집단(20,30,40,50대)의 평균이 차이가 위의 수치처럼 날 가능성이 0%로 매우 희박하다는 결과이며 이는 귀무가설을 기각 할 수 있다.
→ 유의확률을 살펴보면 0.05보다 작기에 귀무가설을 기각! → 적어도 하나의 평균은 다르다, 즉 모두 같다고 할 수 없다 , 차이가 존재한다!
사후검정
-
보통 2가지 중에서 1가지만 선택하여 진행한다.
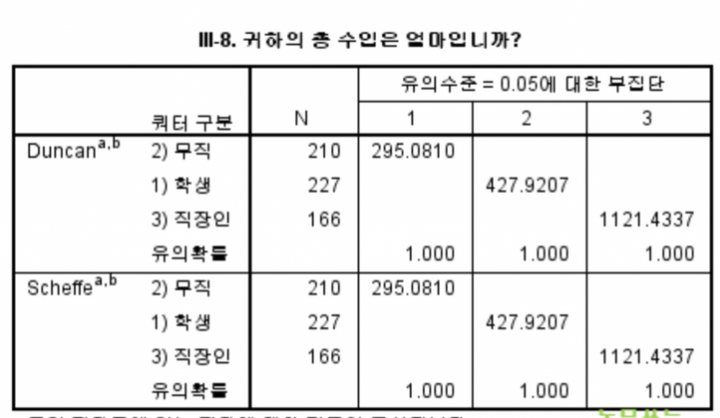
-
사후검정은 앞서 집단 간의 평균차이가 유의미하다는 결과가 나왔고 그 때의 집단의 평균 순위를 확인 하고 싶을때 검정하여 판단하는 방법이다.
