1. JDBC 표준 인터페이스
- JAVA에서 데이터 베이스에 접속할 수 있도록 하는 Api이다
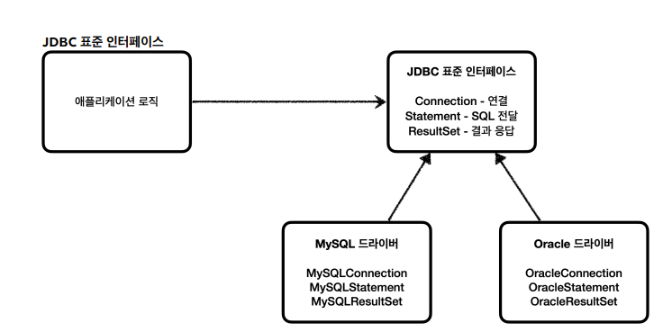
JDBC 드라이버: 각 DB마다 JDBC를 구현해서 라이브러리로 제공하는 것- DB에 접근하는 어플리케이션 로직은, JDBC 표준 인터페이스에만 의존한다
- 다른 종류의 데이터베이스로 변경하고 싶으면, JDBC 구현 라이브러이인 JDBC 드라이버만 변경하면, OCP원칙을 잘 지키면서 DB를 변경할 수 있다
JDBC 기능
java.sql.Connection: 연결java.sql.Statement: SQL을 담은 내용Statement: sql을 그대로 넣는 것preparedStatement: 파라미터를 바인딩해서 sql로 넣는 것, Statement를 상속받은 것
java.sql.ResultSet: SQL 요청 응답excuteUpdate: 등록, 수정, 삭제 (int 반환 -> 변경된 데이터 수, 여기선 pk이므로 1아니면 0임)excuteQuery: select -> 조회 (여기서 rs씀->반환값이 ResultSet임)
public Member findById(String memberId) throws SQLException {
String sql = "select * from member where member_id = ?";
Connection con = null;
PreparedStatement pstmt = null;
ResultSet rs = null;
try{
con=getConnection();
pstmt = con.prepareStatement(sql);
pstmt.setString(1,memberId);
rs = pstmt.executeQuery();
if (rs.next()){
Member member = new Member();
member.setMemberId(rs.getString("member_id"));
member.setMoney(rs.getInt("money"));
return member;
} else {
throw new NoSuchElementException("member not found memberId=" + memberId);
}
} catch (SQLException e) {
log.error("db error",e);
throw e;
} finally {
close(con,pstmt,rs);
}
}정리
물론, JDBC는 db의 연결측면에서 여러 db 기술들의 표준 인터페이스를 제공하는데 아주 큰 의의가 있다
- 하지만, JDBC는 코드가 매우 길고... 반복이 많다
- 또한, 예외를 계속 다음 계층으로 넘겨주는 문제도 있다...
- 또한, db 마다 문법이 조금씩 달라 완벽한 통합은 어렵다!
JDBC와 최신 데이터 접근 기술
- DBC는 1997년에 출시된 기술이라 복잡하다
- JDBC를 편리하게 사용하는 방법으로 대표적으로 SQL Mapper와 ORM기술로 나눌 수 있다
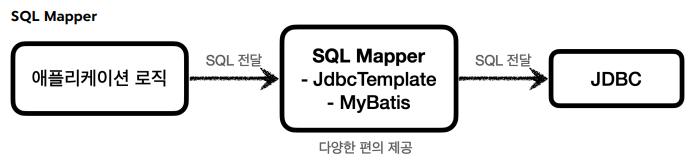
SQL Mapper
- 장점: JDBC를 편리하게 사용하도록 도와준다.
- SQL 응답 결과를 객체로 편리하게 변환해준다.
- JDBC의 반복 코드를 제거해준다.
- 단점: 개발자가 SQL을 직접 작성해야한다.
- 대표 기술:
스프링 JdbcTemplate,MyBatis
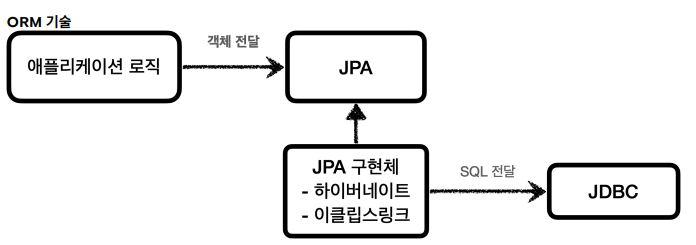
ORM 기술
- ORM은 객체를 관계형 데이터베이스 테이블과 매핑해주는 기술이다.
- 이 기술 덕분에 개발자는 반복적인SQL을 직접 작성하지 않고, ORM 기술이 개발자 대신에 SQL을 동적으로 만들어 실행해준다.
- 추가로 각각의 데이터베이스마다 다른 SQL을 사용하는 문제도 중간에서 해결해준다.
- 대표 기술:
JPA,하이버네이트,이클립스링크 - JPA는 자바 진영의 ORM 표준 인터페이스이고, 이것을 구현한 것으로 하이버네이트와 이클립스 링크 등의 구현 기술이 있다.
중요
이런 기술들도 내부에서는 모두 JDBC를 사용한다. 따라서 JDBC를 직접 사용하지는 않더라도, JDBC가 어떻게 동작하는지 기본 원리를 알아두어야 한다. 그래야 해당 기술들을 더 깊이있게 이해할 수 있고, 무엇보다 문제가 발생했을 때 근본적인 문제를 찾아서 해결할 수 있다 JDBC는 자바 개발자라면 꼭 알아두어야 하는 필수 기본 기술이다
2. ORM - JPA
ORM: 객체와 데이터베이스의 관계를 매핑하는 방법JPA: JAVA ORM 기술에 대한 인터페이스Hibernate: JAP 인터페이스를 구현한 라이브러리- EclipseLink, DataNucleus, TopLink, OpenJPA등등의 구현체가 있다
- 자바 ,관계 패러다임에서의 불일치를 해소해준다!
- 🤔JPA에 대한부분은 따로 공부하고, 작성하겠다!
3. Spring Data Jpa
- 하지말 결국, JPA를 써도 반복되는 작업이 발생한다
- Spring Data Jpa는 이런부분을 대신해준다
- 또한 Transaction 관리도 Spring에서 대신 해준다!
- 우리는 단지 Spring Data Jpa만 상속받아서 사용하면 된다!
@Transactional
public User save(User user) {
return userRepository.save(user);
}
@Transactional
@Override
public <S extends T> S save(S entity) {
Assert.notNull(entity, "Entity must not be null.");
if (entityInformation.isNew(entity)) {
em.persist(entity);
return entity;
} else {
return em.merge(entity);
}
}

- 결국 raw한 JDBC코드와
- JPA, Hibernate로 ORM을 구현하였고
- 이를 🤔 추상화해서 편리하게 시용하는 것이 Spring Data JPA 다
핵심은 결국 JPA이다!
- JPA를 잘 알아야지, 다음 기술들을 잘 사용할 수 있는 것이다
4. Memory DB -> Sql, Spring Data JPA 변환
application.yml
spring:
jpa:
show-sql: true
properties:
format_sql: true
dialect: org.hibernate.dialect.MySQLDialect
hibernate:
ddl-auto: validate
datasource:
url: jdbc:mysql://localhost:3307/book_store?useSSL=false&useUnicode=true&allowPublicKeyRetrieval=true
driver-class-name: com.mysql.cj.jdbc.Driver
username: root
password: ~~~~~- local host 3307에 book_store이라는 스키마와 연결하였다
UserEntity
@Data
@AllArgsConstructor
@NoArgsConstructor
@Builder
@Entity(name = "user")
public class UserEntity {
@Id @GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
private String name;
private int score;
}UserRepository
public interface UserRepository extends JpaRepository<UserEntity,Long> {}- service와 컨트롤러는 변경하지 않아도 된다
- 이것이, SRP를 잘 지킨 프레임워크를 이용한 개발의 힘이다!
- 그런데... 🤔 특정 점수를 넘는 User을 뽑는 메서드에 문제가 생겼다...
Spring Data JPA 공식문서
https://docs.spring.io/spring-data/jpa/docs/current-SNAPSHOT/reference/html/#reference
3.1.3 Query Method가 부분이 있는데, 여기 나오는 규칙을 이용해 우리가 db에서 특정 쿼리를 메서드의 이름을 가지고 생성할 수 있다
public interface UserRepository extends JpaRepository<UserEntity,Long> {
// select * from user where score >= [??];
public List<UserEntity> findAllByScoreGreaterThanEqual(int score);
// select * from user where score >= ?? and score <= ??
public List<UserEntity> findAllByScoreGreaterThanEqualAndScoreLessThanEqual(int min, int max);
// 네이티브 쿼리 활용법
@Query(
// value = "select u from user u where u.score >= ?1 AND u.score <= ?2",
value = "select * from user as u where u.score >= :min AND u.score <= :max",
nativeQuery = true
)
List<UserEntity> score(
@Param(value= "min") int min,
@Param(value = "max") int max);- findAllByScoreGreaterThanEqual, findAllByScoreGreaterThanEqualAndScoreLessThanEqual 같이 이름을 통해 해당 쿼리를 날릴 수 있다
@Query
@Query: 어노테이션을 이용해 네이티브 쿼리를 날릴 수 있다!nativeQuery = true: default = false
public List<UserEntity> filterScore(int min,int max){
userRepository.findAllByScoreGreaterThanEqualAndScoreLessThanEqual(min, max);
return userRepository.score(min, max);
}@GetMapping("/score")
public List<UserEntity> filterScore(
@RequestParam("score") int score
){
return userService.filterScore(score);
}
@GetMapping("/min_max")
public List<UserEntity> filterScore(
@RequestParam("min") int min,
@RequestParam("max") int max
){
return userService.filterScore(min,max);
}-
다음 코드를 통해, 쿼리 파라미터인 score을 이용해 요청을 한 결과를 보면
-
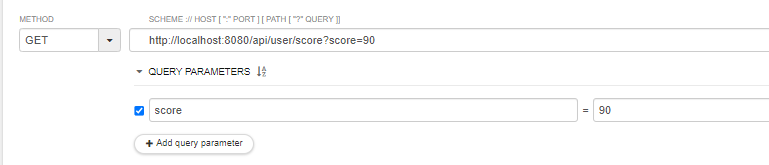
-
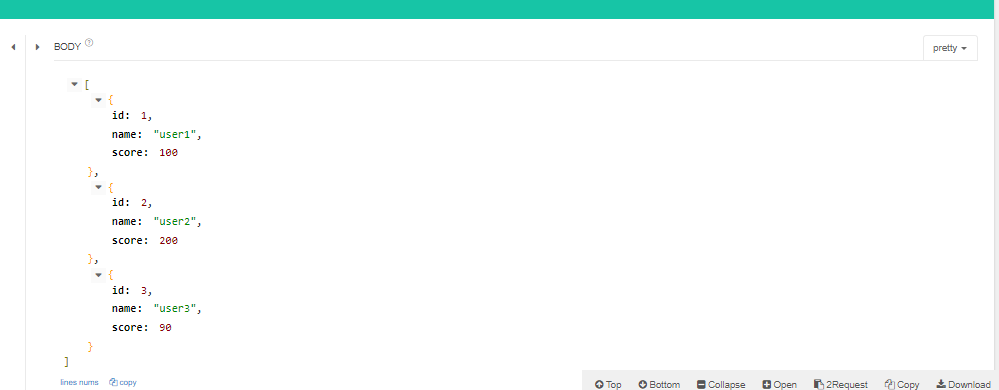
-
모두 90점이 넘는 user만 반환된 것을 알 수 있다!
5. 정리
- 이번 시간엔 간략하게 JDBC부터 Spring data jpa를 이용해
- JAVA에서 데이터 베이스에 접근하는 방법을 알아봤다
- 또한 memory db를 이용해서 연습한 코드를, sql과 spring data JPA를 통해 변경해 주었다
- 이번 학기가 거의 끝나가는데.. 방학 때 공부해둔 JPA도 많이 까먹은 것 같다
- 다음 주제론 JPA에 대해서 다시 한번 복습하는 시간을 가져야 겠다
- 🤔 Spring data jpa도 JPA에 대해서 복습하고 보면, 더욱 편리하고 강력한 도구로 사용할 수 있을 것 같다!

개발 공부,정리