데이터를 요약하고 분석할 때, Groupby와 피벗 테이블은 상호 보완적으로 사용되며, 상황에 따라 각기 다른 장점과 단점을 가지고 있다.
피벗 테이블과 Groupby의 차이점: Groupby와 피벗 테이블 모두 데이터를 요약하여 분석할 수 있지만, 피벗 테이블은 인덱스와 컬럼을 사용해 데이터를 더 깔끔하게 시각화한다.
피벗 테이블 기본 사용법: pd.pivot_table() 함수를 사용하여 데이터를 요약하며, values, index, columns 등의 파라미터를 설정하여 원하는 데이터를 출력할 수 있다. 기본적으로 평균값을 계산한다.
함수 설정: aggfunc 파라미터를 사용하여 평균 외의 통계값, 예를 들어 최댓값 등을 계산할 수 있다.
여러 개의 설정값 사용: values, index, columns, aggfunc에 리스트 형태로 여러 개의 값을 설정할 수 있으며, 이를 통해 다양한 데이터를 한번에 분석할 수 있다.
피벗 테이블과 Groupby의 비교: 피벗 테이블은 시각적으로 깔끔하지만 큰 데이터셋에서는 가독성이 떨어질 수 있고 느리다. Groupby는 속도가 빠르며, 큰 데이터셋에는 더 적합하다. 상황에 맞게 선택하여 사용하면 된다.
#평균
pd.pivot_table(netflix_df, values='score' , index='year' ,columns='genre')
#최대값
pd.pivot_table(netflix_df, values='score' , index='year' ,columns='genre', aggfunc='max')
#여러값 처리
pd.pivot_table(netflix_df, values='score' , index='year' ,columns='genre', aggfunc=['max','min'])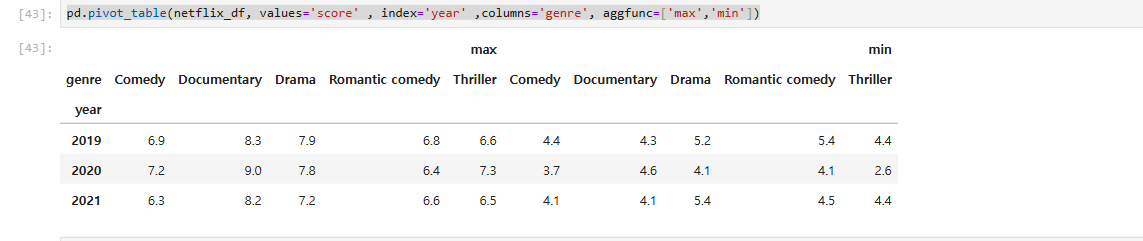
- 예제
피벗 테이블로 몬트리올 올림픽의 국가별 금메달, 은메달, 동메달의 개수를 계산해 봅시다. 이때 결측값은 0으로 채우고, 금메달, 은메달, 동메달 개수, 나라 이름 순서대로 내림차순 정렬해 주세요. 메달 정보는 medal 컬럼에 저장되어 있고, 1st는 금메달, 2nd는 은메달, 3rd는 동메달을 의미합니다. 정렬 방식에 대한 자세한 정보는 아래를 확인해 주세요!
금메달 개수를 기준으로 먼저 내림차순 정렬합니다.
금메달 개수가 같은 경우에는 은메달 개수를 기준으로 내림차순 정렬합니다.
금메달과 은메달 개수도 같은 경우에는 동메달 개수를 기준으로 내림차순 정렬합니다.
금메달, 은메달, 동메달 개수도 모두 같은 경우에는 나라 이름을 기준으로 내림차순 정렬합니다.
import pandas as pd
olympic_df = pd.read_csv('data/olympic.csv')
result = pd.pivot_table(
olympic_df,
index='team',
columns='medal',
aggfunc='size'
).fillna(0).sort_values(
by=['1st', '2nd', '3rd', 'team'],
ascending=False
)