data
1.[data science] jupyter notebook

셀에서 print문 없이도 값이 나오지만 마지막 셀의 값만 찍힌다.셀의 마지막줄에 값이 없는 경우 아무것도 안나옴.
2.[data science] Numpy
*jupyter notebook에서 작성 예제
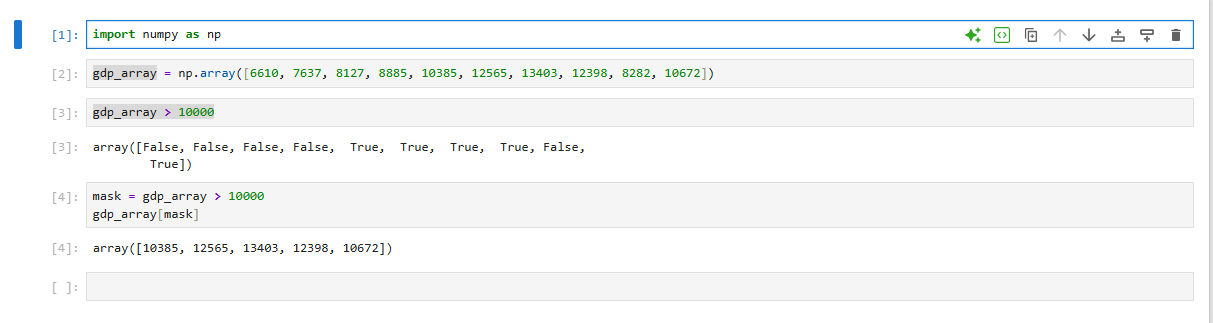
3.[data science] numpy boolean indexing
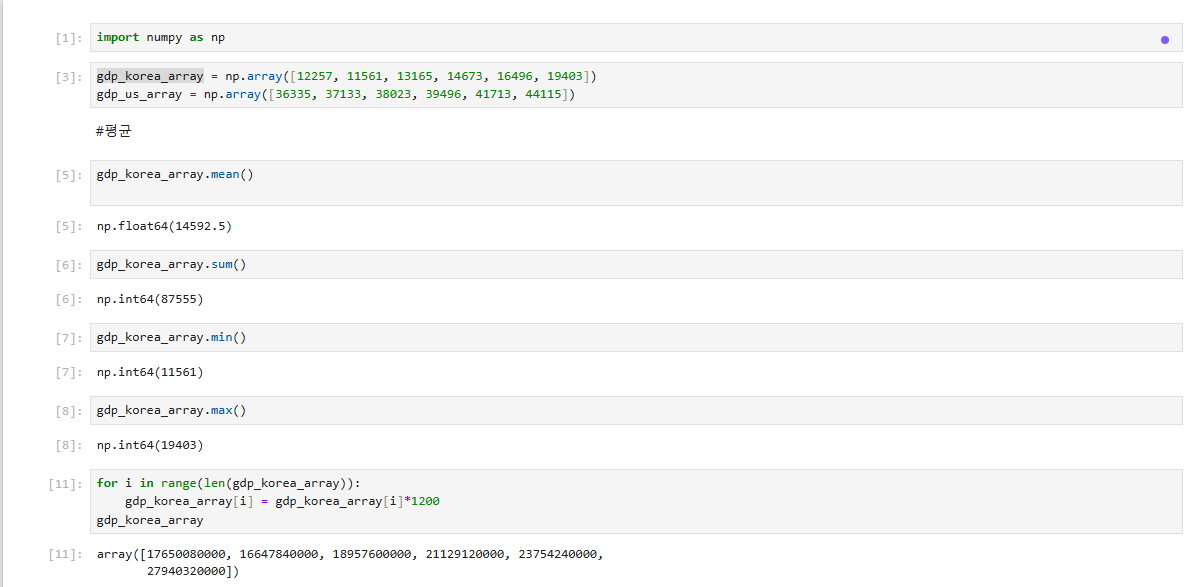
4.[data science]numpy 연산
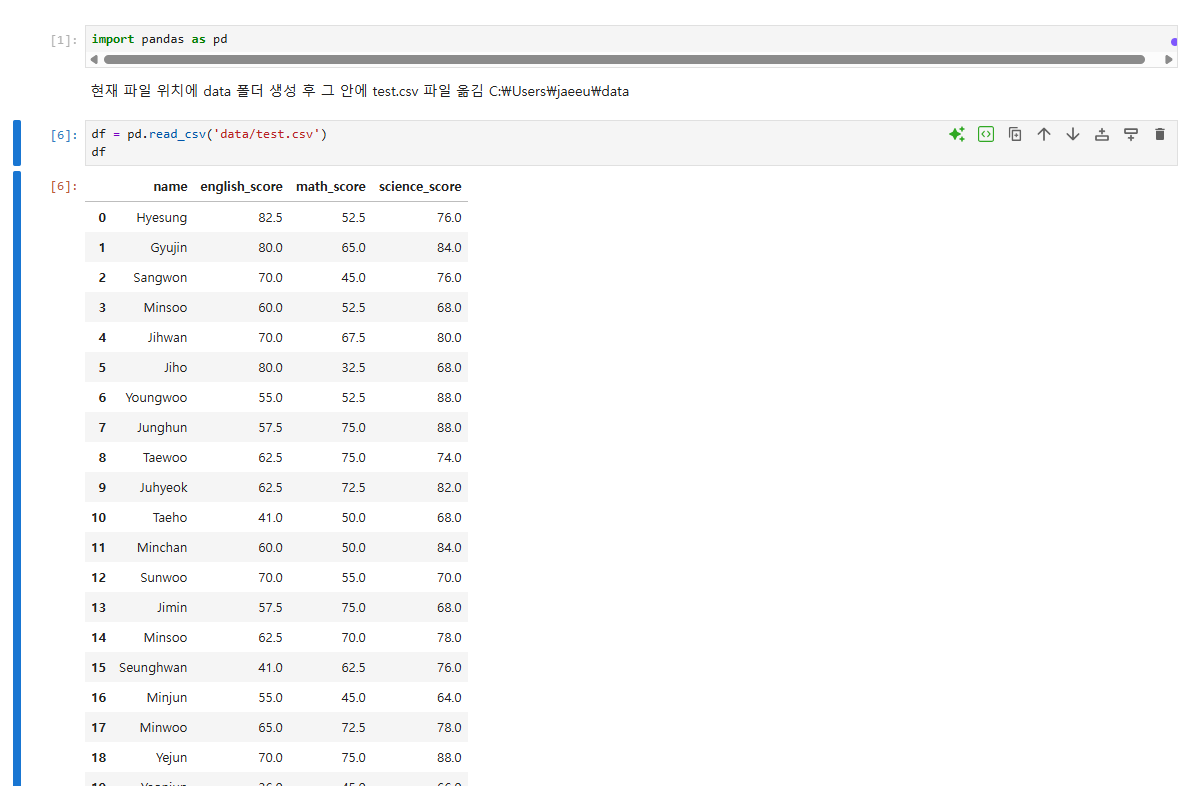
5.[data science] pandas
6.[data science] 박스플롯과 이상점
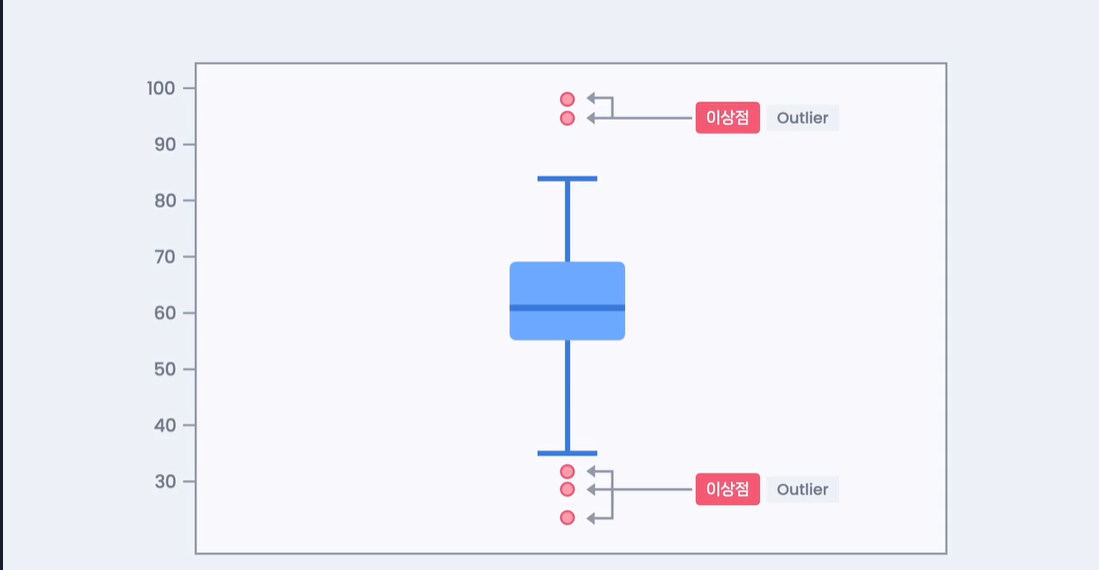
df'english_score'.plot(kind='box')plt.show()q1 = df'english_score'.quantile(0.25)q3 = df'english_score'.quantile(0.75)iqr = q3 - q1q1 -1.5 \*iqrnp.flo
7.[data science] 히스토그램
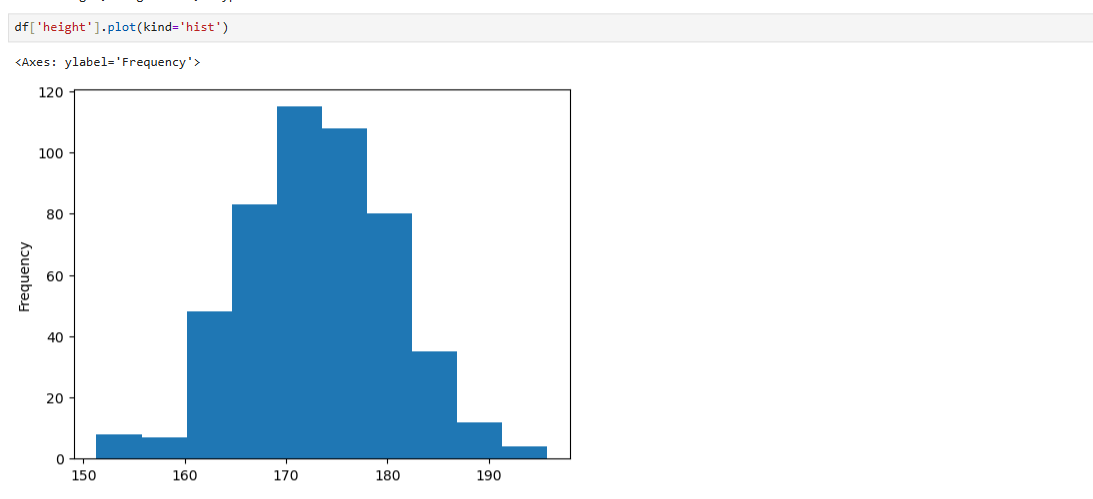
핵심 주제수치형 데이터는 이산형과 연속형으로 구분되며, 히스토그램을 사용하여 이러한 데이터의 분포를 시각적으로 표현할 수 있다.주요 내용수치형 데이터의 구분: 수치형 데이터는 이산형 데이터와 연속형 데이터로 나뉜다. 이산형 데이터는 특정한 값으로 구분되며, 연속형 데이
8.[data science] Statistics(통계)
1.기술통계 2.추론통계
9.[data science]pandas DataFrame
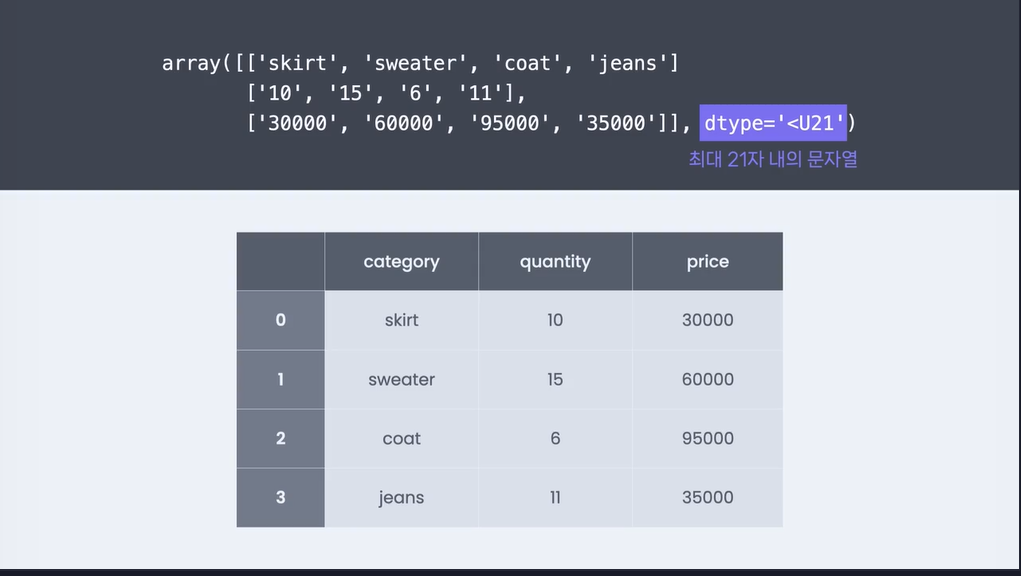
numpy 기반 데이터 분석 라이브러리numpy -복잡한 수학연산pandas - 표 형태의 데이터를 간편하게 다루고 싶을 때DataFrame을 만들 때 columns라는 옵션을 사용해서 컬럼명을 설정하는 것도 가능합니다.two_dimensional_list = \[
10.[data science]pandas
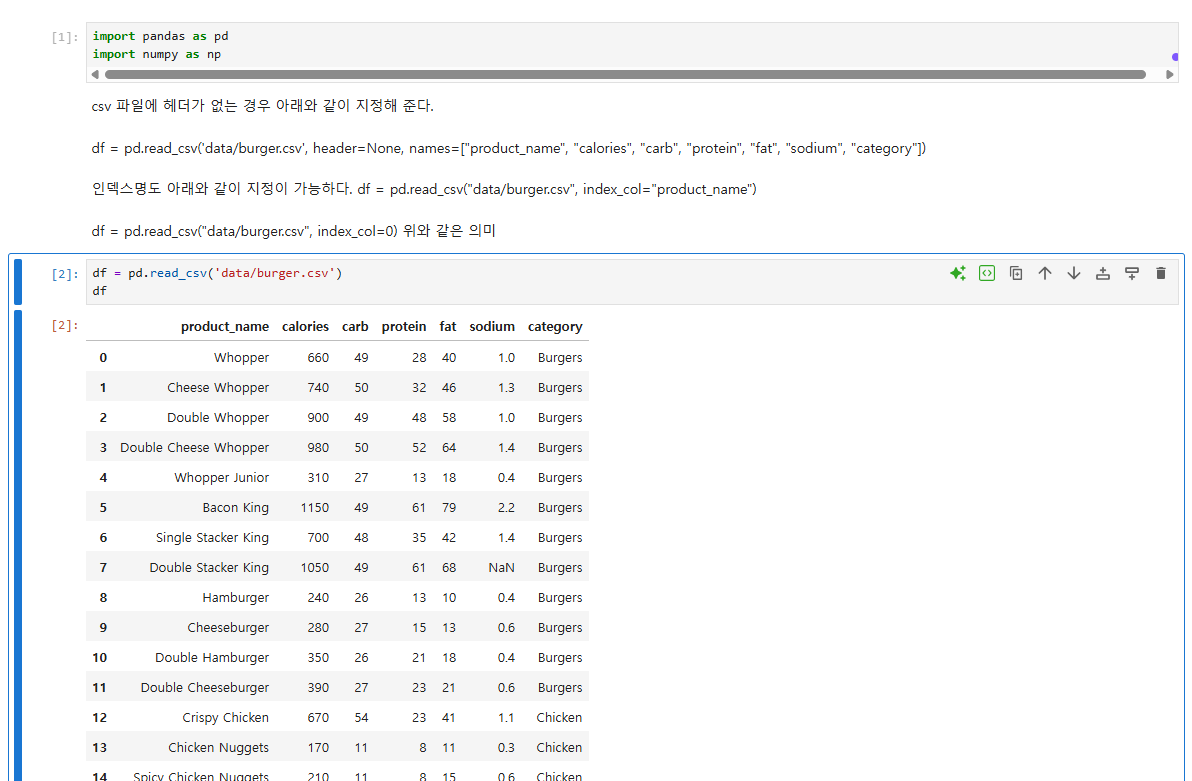
csv 파일에 헤더가 없는 경우 아래와 같이 지정해 준다.df = pd.read_csv('data/burger.csv', header=None, names="product_name", "calories", "carb", "protein", "fat", "sodium",
11.[data science] pandas Dataframe
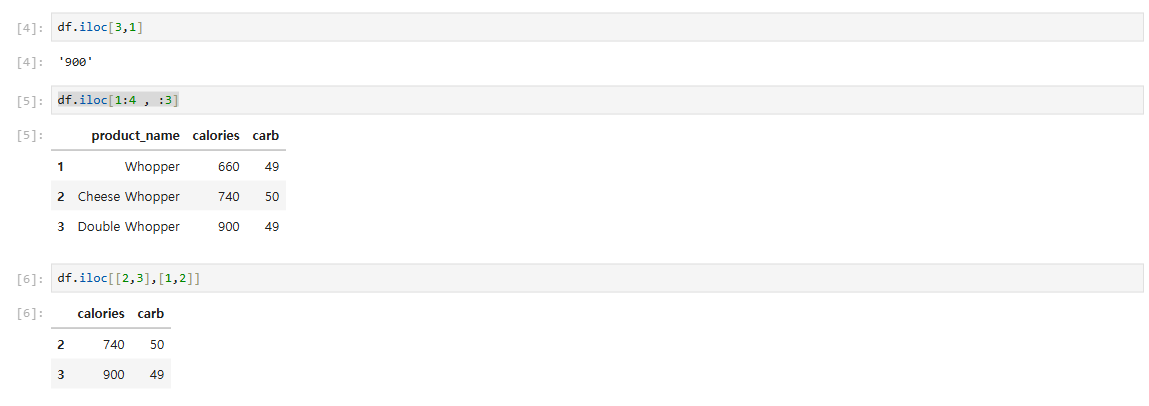
iloc - 정수값에 인덱스loc - 컬럼명 인덱스Dataframe에서 위 함수로 일부 데이터만 가져올 수 있다.DataFrame에서 손흥민 선수의 골 득점 수import pandas as pdplayers_df = pd.read_csv('data/tottenham_2
12.[data science] dataframe boolean index
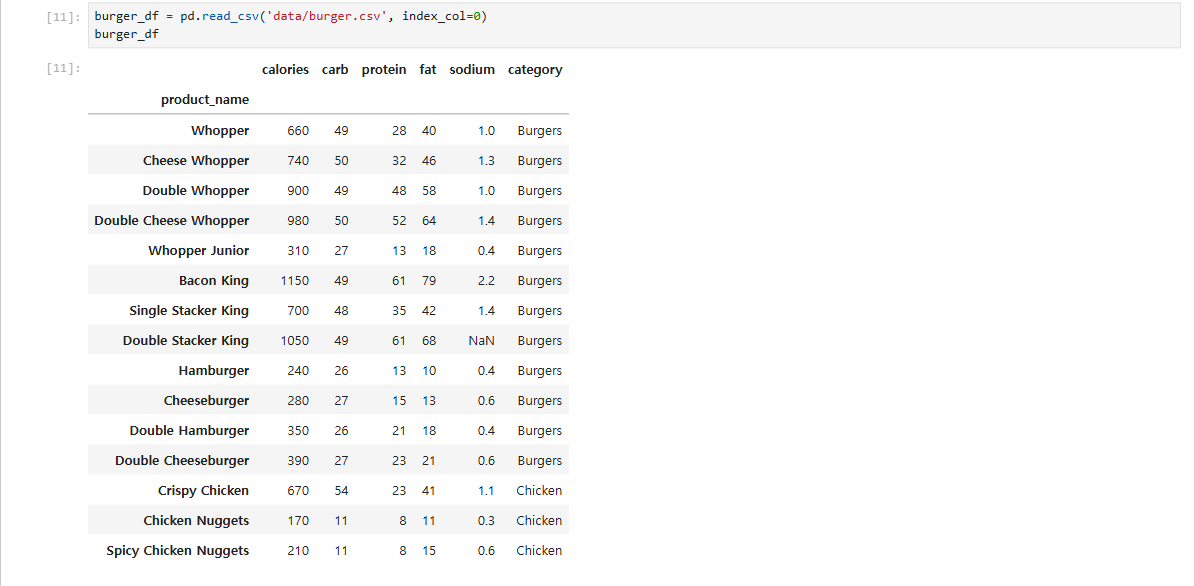
burger_df.loc\[burger_df'calories' < 500]burger_df.loc\[burger_df'calories' < 500 , 'carb','protein']burger_df.loc\[burger_df'calories' < 500
13.[data science] dataframe 수정 및 추가
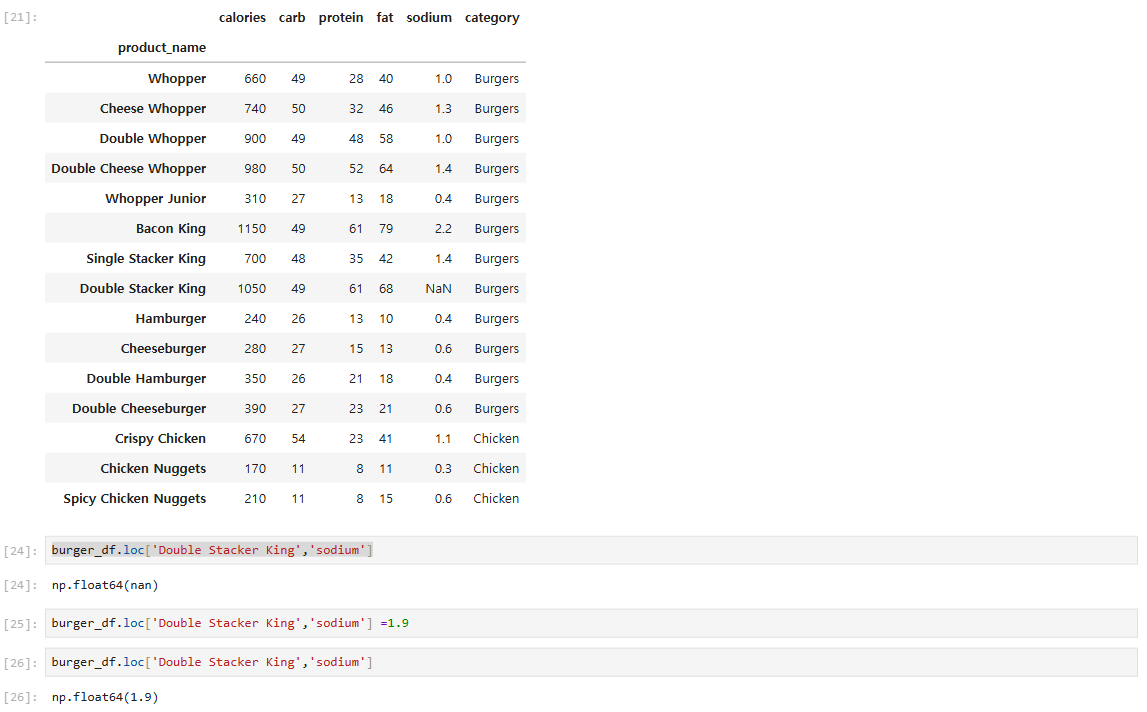
burger_df.loc'Double Stacker King','sodium'np.float64(nan)burger_df.loc'Double Stacker King','sodium' =1.9burger_df.loc'Double Stacker King','sodium'n
14.[data science] pandas에서 그래프 그리기
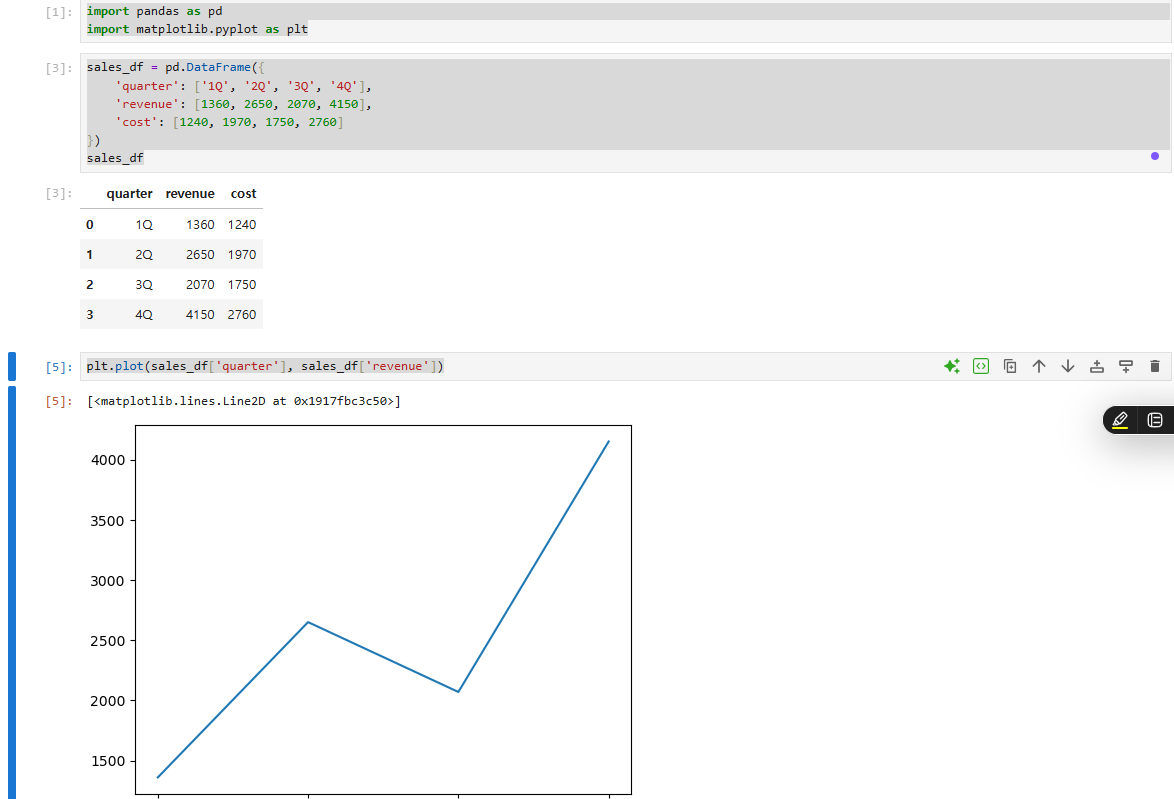
import pandas as pdimport matplotlib.pyplot as pltsales_df = pd.DataFrame({ 'quarter': '1Q', '2Q', '3Q', '4Q', 'revenue': 1360, 2650, 2070, 4150
15.[data science] 확률밀도함수&KDE plot
히스토그램은 데이터를 간편하게 시각화할 수 있어 많이 사용되지만, 연속형 데이터를 단순화하여 분석하는 제한이 있다.확률 밀도 함수(PDF)는 각 구간이 전체에서 차지하는 비중을 통해 연속형 데이터의 분포를 살펴볼 수 있다.연속형 데이터에서 특정 값의 확률은 0이지만,
16.[data science] 데이터 분포
핵심 주제데이터 분포의 다양한 형태와 그것을 이해하는 데 도움이 되는 통계적 개념들이 무엇인지 살펴본다.주요 내용정규 분포(Normal Distribution): 데이터가 중간에 몰려 있고 양 끝으로 갈수록 줄어드는 형태로, 다양한 상황에서 나타난다. 종 모양을 닮아
17.[data science] 분산과 표준편차
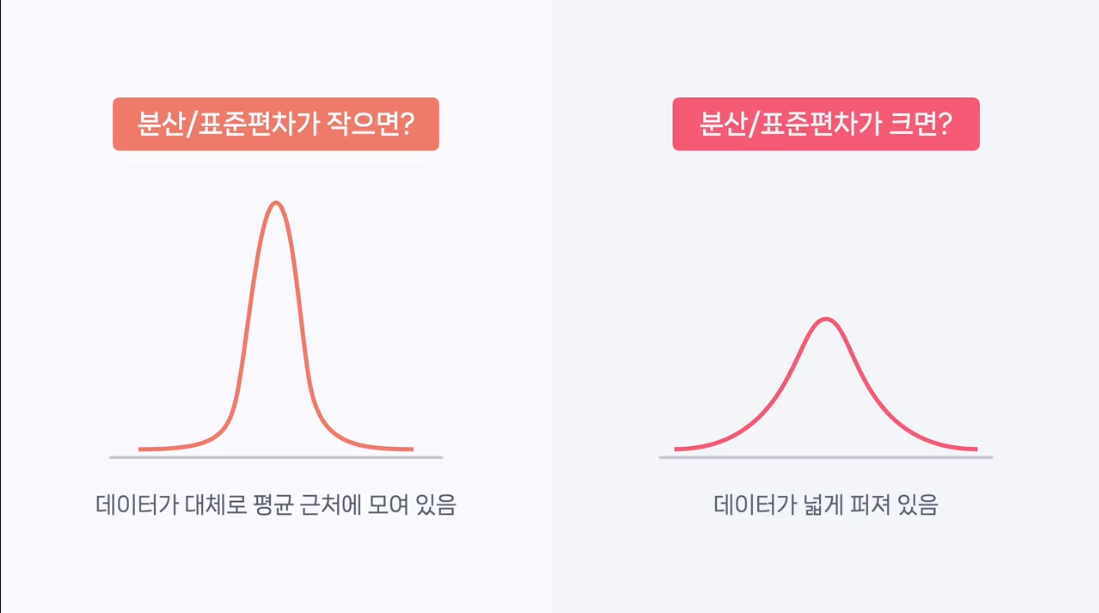
핵심 주제KDE Plot을 통해 데이터의 분포를 비교하고, 분산과 표준 편차를 계산하여 데이터가 얼마나 넓게 퍼져 있는지를 파악하는 방법을 배웁니다.주요 내용KDE Plot을 통한 데이터 분포 비교두 개의 KDE Plot을 통해 고등학생 남학생들과 다양한 나이대의 남학
18.[data science] 누적값 계산

df1 = pd.read_csv('data/revenue.csv')df1df.sum()df1'revenue'.cumsum()df1'revenue_cumsum' = df1'revenue'.cumsum()df1df1.plot(x='month', y='revenue_cums
19.[date science] seaborn과 matplotlib
Matplotlib과 Seaborn의 가장 큰 차이점은 제어 수준과 사용 편의성입니다. Matplotlib은 모든 요소를 세밀하게 조정할 수 있는 기초 도구인 반면, Seaborn은 Matplotlib을 기반으로 더 쉽고 예쁘게 그래프를 그릴 수 있게 만든 고급 라이브
20.[date science] seaborn
\*설치jupyter notebook에서!conda install --yes seaborn\*csv파일 읽기import seaborn as sbnimport pandas as pdimport matplotlib as pltdf = pd.read_csv('data/bik
21.[data science]seaborn.set_theme()
import seaborn as sbnimport pandas as pdimport matplotlib as plt..df = pd.read_csv('data/\*\*\*.csv')\*스타일 설정sbn.set_theme(style='white') --> 배경색style
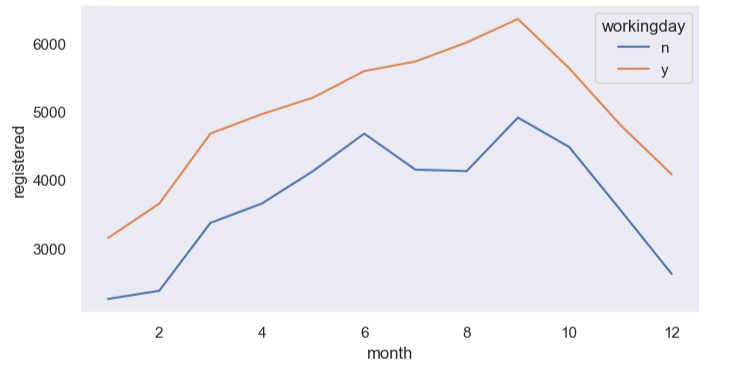
22.[data science]seaborn-데이터 분포 시각화
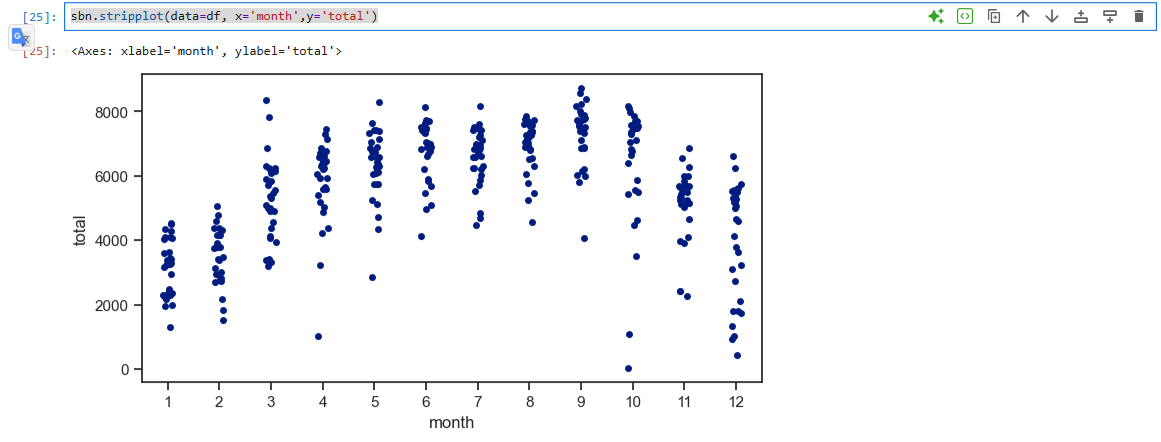
\*stripplotsbn.stripplot(data=df, x='month',y='total')sbn.stripplot(data=df, x='month',y='total', hue='workingday')\*swarmplot - 작은 데이터셋을 분석할 떄 추천sbn.
23.[data science]seaborn-데이터 분포 시각화 예제
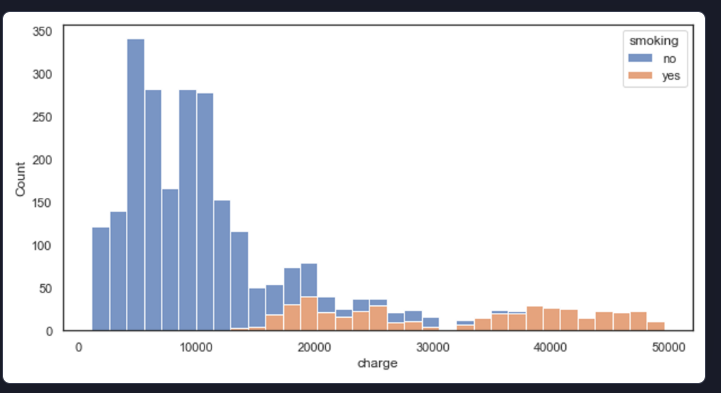
import pandas as pdimport seaborn as snsimport matplotlib.pyplot as pltinsurance_df = pd.read_csv('data/insurance_charge.csv')sns.set_theme(rc={'figur
24.[data science]seaborn-상관관계 시각화
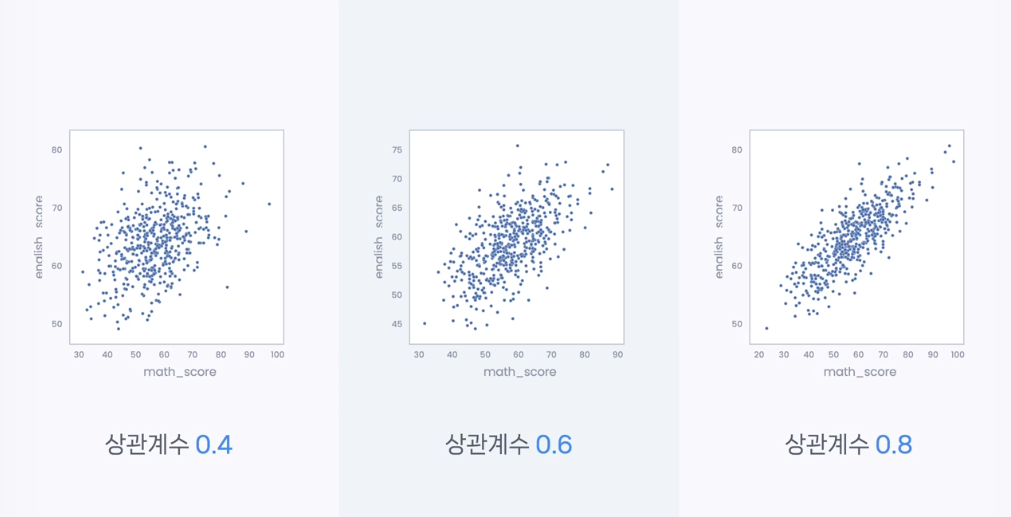
\*\*- 어떤겂이 변함에따라 다른값도 변함이 있어 두 값이 상관 관계가 있는 경우상관관계를 구체적인 수치로 표현 -> 상관계수 , -1에서 1사이 , 상관관계 0이면 두 값은 상관관계가 없다0 < 상관계수. 어떤값이 커질 때 같이 커짐. 양의 상관관계 0 > 상
25.data science]seaborn-피어슨 상관계수와 공분산
1.피어슨 상관계수의 범위: 피어슨 상관계수는 -1에서 1 사이의 값을 가지며, 이 값은 두 변수 간의 양적 상관관계의 강도를 나타냅니다.2.피어슨 상관계수 계산 방법: 공분산을 각 변수의 표준 편차의 곱으로 나눔으로써 피어슨 상관계수를 계산합니다.3.공분산의 정의와
26.[data science] pandas
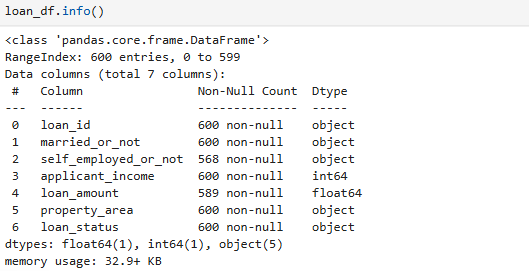
데이터 분석 도구의 중요성: 데이터를 다양한 방법으로 분석하기 위해 적절한 도구 사용이 필수적이다.pandas의 중요성: pandas는 표 형태의 데이터를 DataFrame 형식으로 불러와 자유롭게 분석하고 가공할 수 있는 강력한 도구이다.loan_df라는 DataFr
27.[data science] pandas - index , columnName , dataType 설정
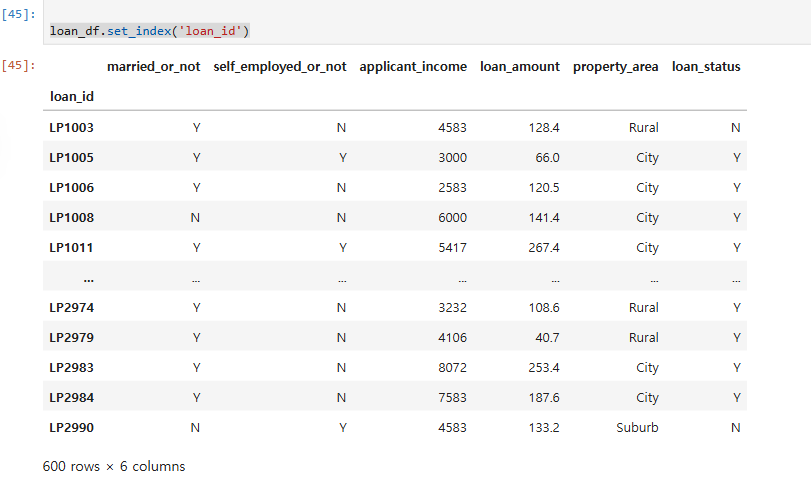
\*Indexloan_df.set_index('loan_id')loan_df = loan_df.set_index('loan_id') // 이와 같이 해야 변경사항이 저장됨.loan_id 컬럼을 인덱스로 셋팅loan_df = loan_df.reset_index() //
28.[data science] pandas - series
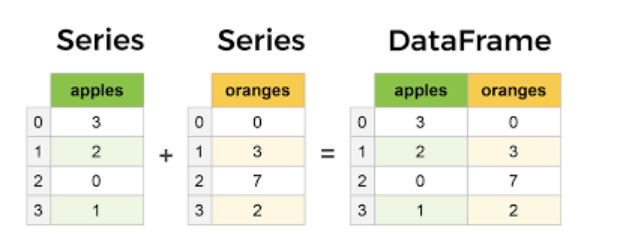
시리즈(Series): 1차원 데이터 구조로, 인덱스를 가지는 단일 열입니다. 한 종류의 데이터(예: 숫자, 문자열 등) 목록을 저장하고자 할 때 사용됩니다.데이터프레임(DataFrame): 2차원 데이터 구조로, 여러 개의 시리즈(열)로 구성됩니다. 데이터프레임의 특
29.[data science] pandas - 여러개의 조건으로 boolean 인덱싱
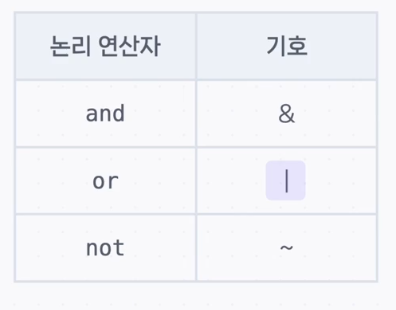
iloc\[] : 위치를 기준으로 인덱싱loc\[] : 이름을 기준으로 인덱싱boolean indexing : 조건을 만족하는 데이터 추출\*논리 연산자 .median()(중앙값)\*multi boolean indexingcondition1 = loan_df'marr
30.[data science] pandas - query()
loan_df\[loan_df'income' >= 5000]위의 코드를 query()를 사용해소 변경할 수 있다.loan_df.query('income >= 5000')DataFrame에 query() 함수를 사용하면 좀 더 간단한 코드로 동일한 결과물을 얻을 수 있어
31.[data science] pandas - data 삭제
loan_df = loan_df.drop('LP1006') //dataframe.drop(index). 데이터 삭제loan_df = loan_df.drop(columns='married') // columl 삭제리스트로 값을 넘기면 동시에 여러개 삭제도 가능drop()
32.[data science] pandas - 데이터 내보내기
1.CSV 파일로 내보내기to_csv() 함수를 사용하여 DataFrame을 CSV 파일로 저장할 수 있습니다.기본적으로 인덱스 값은 컬럼으로 저장됩니다.index라는 파라미터 값의 기본값이 True로 되어 있기 때문.index 파라미터를 False로 설정하면 인덱스를
33.[data science] 결측값(NaN) 찾기
Garbage in Garbage out데이터 전처리의 중요성: 데이터의 품질이 분석 결과에 직접적인 영향을 미치므로, 깨끗하지 않은 데이터를 그대로 사용하면 예상 밖의 결과나 오류가 발생할 수 있다.결측값 탐색: 원본 데이터를 분석하기 전에 결측값을 확인하는 것이 중
34.[data science] 결측값(NaN) 처리
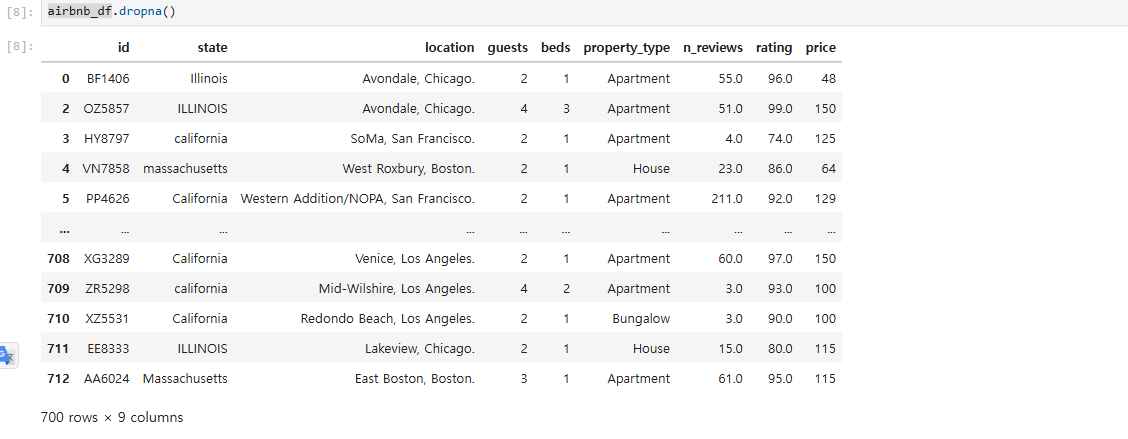
결측값을 처리하는 방법에는 삭제와 대체 두 가지가 있으며, 각각의 방법에 따라 데이터의 분석 가능성과 정확도가 영향을 받을 수 있다.결측값 삭제 결측값이 많지 않거나 특정 컬럼이나 row의 값들이 대부분 결측값일 때 사용. 간단하지만, 데이터 양이 줄어드는 단점이
35.[data science] pandas - 중복

duplicated()는 중복되는 값들 중 첫번째 값은 중복이 아니라고 판단하고 그 다음 값 부터 중복이라고 판단함.airbnb_df.duplicated() // 모든 데이터가 중복일때 중복되는 데이터에 True.중복되는 값들 중 첫번째는 Falseairbnb_df.d
36.[data science] pandas - 이상점(Outlier) 찾기
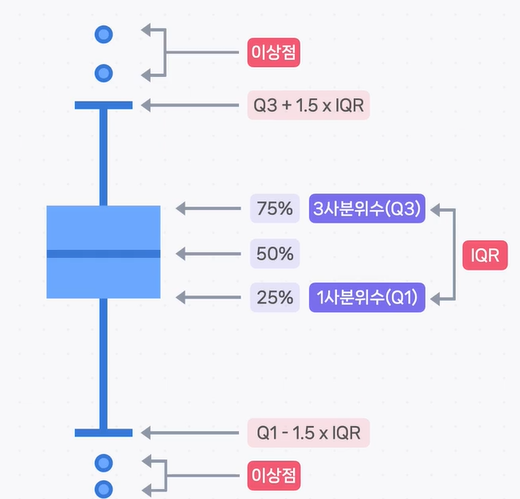
airbnb_df['price'].quantile(0.25)
37.[data science] 문자 데이터 가공

.str.lower() - 모두 소문자로 반환.str.upper() - 모두 대문자로 반환.str.capitalize() - 첫글자는 대문자, 나머지는 소문자로 반환문자열 분리(.str.split())불필요한 문자 제거(.str.replace()) 데이터가 안나와 확
38.[data science] 숫자 데이터 가공
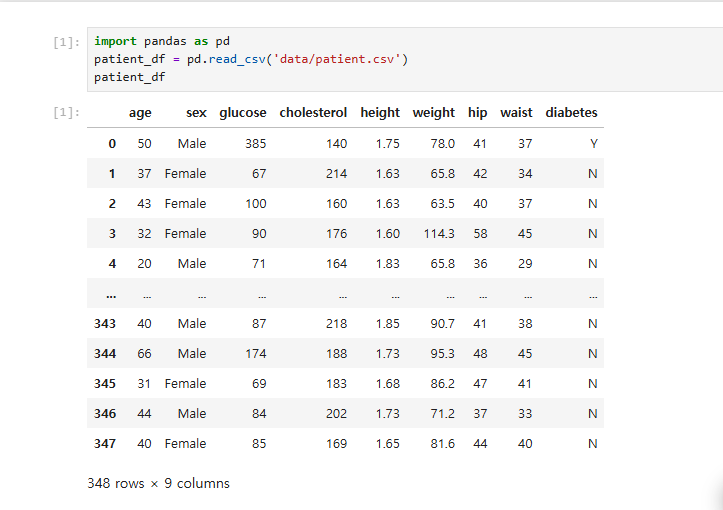
round()patient_df'waist_hip_ratio' = round(patient_df'waist' / patient_df'hip' , 2)import pandas as pdpatient_df = pd.read_csv('data/patient.csv')pati
39.과학적 표기법과 고정 소수점 표기법
pandas에서 숫자 표기법 설정하기pandas는 기본적으로 고정 소수점 표기법을 사용해서 숫자를 표현하지만, 숫자가 엄청 크거나 작을 때 혹은 소수점 아래 숫자가 많을 때에는 자동으로 과학적 표기법을 사용. pandas의 set_option()이라는 함수를 사용하면
40.[data science] 표준화

표준화는 데이터를 평균 0, 분산 1로 변환하여 각 데이터가 평균으로부터 얼마나 떨어져 있는지를 나타내며, 데이터 분석 및 모델링에 있어 중요한 전처리 기법이다.주요 내용1\. 표준화 정의: 표준화는 각 데이터가 평균에 비해 얼마나 크거나 작은지를 나타내기 위해 평균을
41.[data science] pandas - cut()
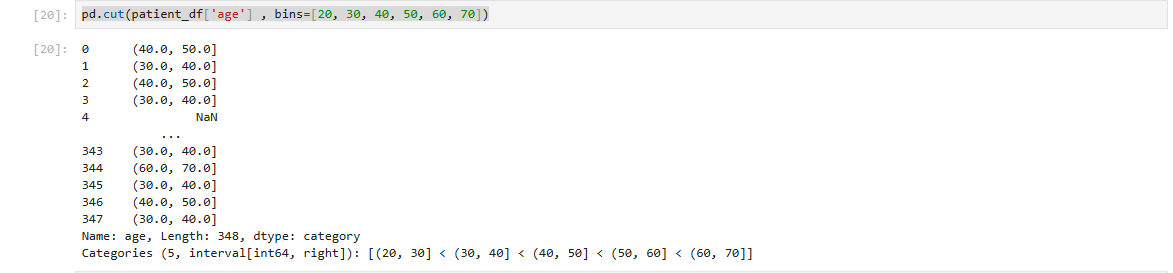
cut() 함수 사용으로 데이터 구간화(binning)데이터 구간화는 연속적인 숫자 데이터를 특정 기준에 따라 여러 개의 구간으로 분류하는 작업이다..1\. 데이터 구간화(Binning)의 정의와 활용: 연속적인 숫자 데이터를 기준에 따라 그룹으로 분류.2\. pand
42.[data science] pandas - apply()

cut()이 데이터 구간화를 위해 만들어진 함수라면, apply()는 원하는 기능을 마음대로 구현할 수 있는 만능 함수apply()는 다른 함수를 아규먼트로 사용합니다. apply가 '적용하다'라는 뜻을 가지고 있는 것처럼 DataFrame이나 Series에 있는 값
43.[data science] pandas - 날짜와 시간 data type
1. 날짜와 시간 데이터의 중요성: 데이터 분석에서는 날짜와 시간 정보를 포함한 데이터를 자주 다루며, 이를 효과적으로 처리하기 위해 적절한 데이터 타입이 필요. datetime 타입으로 변환: Pandas의 to_datetime 함수를 사용하여 문자열로 저장된 날짜와
44.[data science] pandas - 날짜와 시간 index
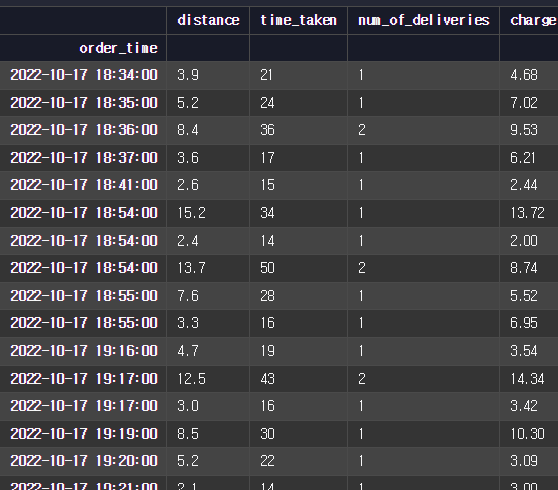
Datetime 인덱싱 설정: 데이터프레임에서 특정 컬럼을 인덱스로 설정하기 위해 set_index 함수를 사용하고, 이렇게 설정한 datetime 인덱스를 통해 부분 문자열 인덱싱이 가능하다는 점을 소개합니다. Datetime을 통한 데이터 정렬: datetime
45.[data science] pandas - 날짜와 시간 변경
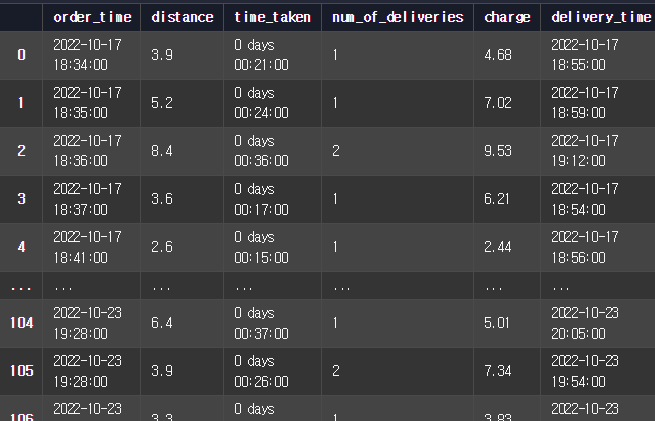
날짜사이에 몇일인지 확인\*데이터 타입이 같아야 비교가능.\*데이터 타입을 timedelta로 변경
46.[data science] pandas - concat()
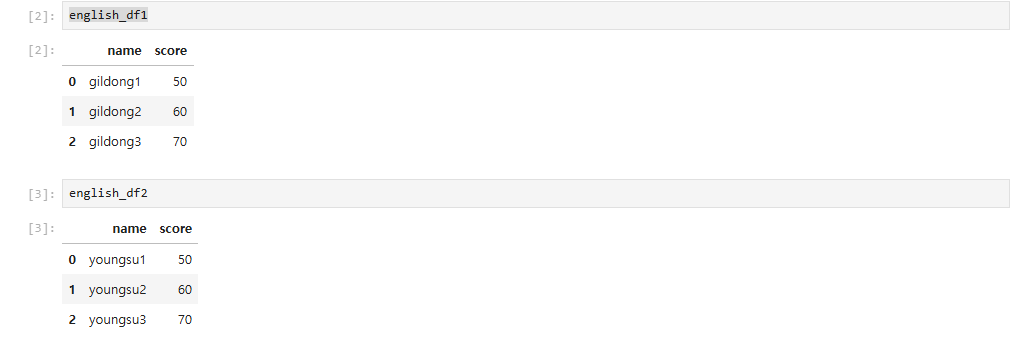
DataFrame 결합데이터를 결합하기 위해 pandas의 concat 함수를 사용하여 DataFrame을 위아래 또는 옆으로 합침기본 concat 방식pd.concat()을 사용하여 여러 DataFrame들을 리스트 형태로 전달하여 위아래로 합칠 수 있다.인덱스 조정
47.[data science] pandas : join 연산 - column 기준 합치기 [merge()]
1.merge 함수 사용법: pandas의 merge 함수를 사용해 employee_df와 survey_df를 id 컬럼을 기준으로 Inner Join으로 병합한다.2.Inner Join, Left Outer Join, Right Outer Join, Full Oute
48.[data science] pandas - join 연산
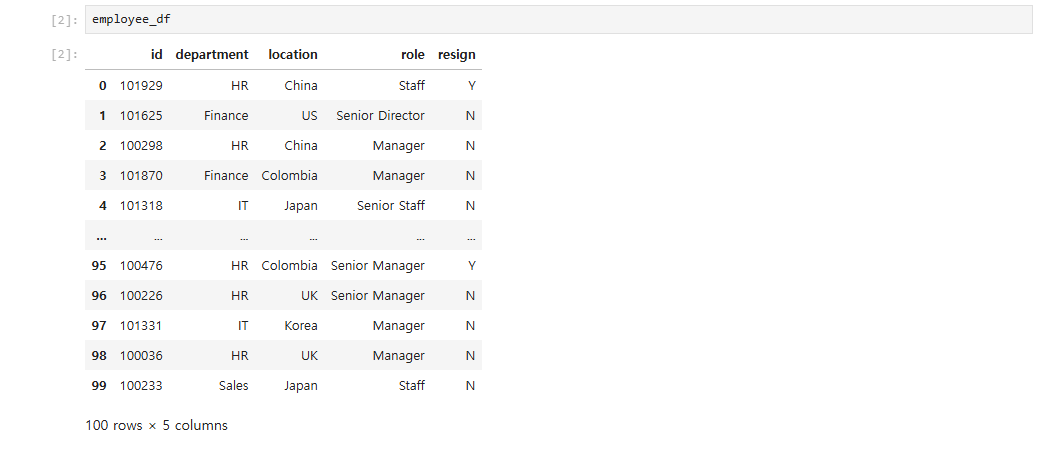
데이터를 효과적으로 결합하기 위한 방법인 조인(Join) 연산에는 Inner Join, Left Outer Join, Right Outer Join, Full Outer Join이 있으며, 각 방법은 서로 다른 기준으로 데이터를 병합Inner Join: 두 데이터에 모
49.[data science] pandas : join 연산 - index 기준 합치기 [join()]
인덱스를 이용한 조인: join 함수는 인덱스를 Key값으로 사용하여 데이터를 합치는 기능을 제공. index가 없다면 설정. 기본적으로 left outer join을 함컬럼 중복 해결: 겹치는 컬럼이 있을 경우, lsuffix와 rsuffix를 설정하여 수동으로 접미
50.[data science] pandas : Groupby
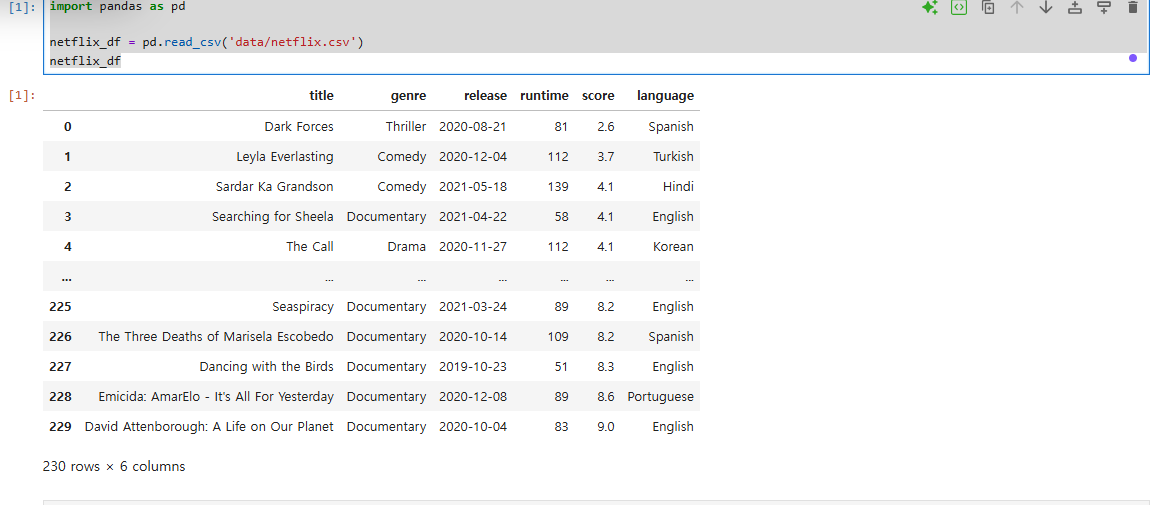
데이터 기본 정보 확인: DataFrame의 기본적인 정보를 확인하고, 결측값이 없는지 info 함수를 통해 점검.통계 정보 요약: describe 함수를 사용하여 상영 시간과 평점 등 숫자 데이터의 기본 통계 정보를 확인.그룹별 통계 분석: groupby 함수를 이용
51.[data science] pandas : category type
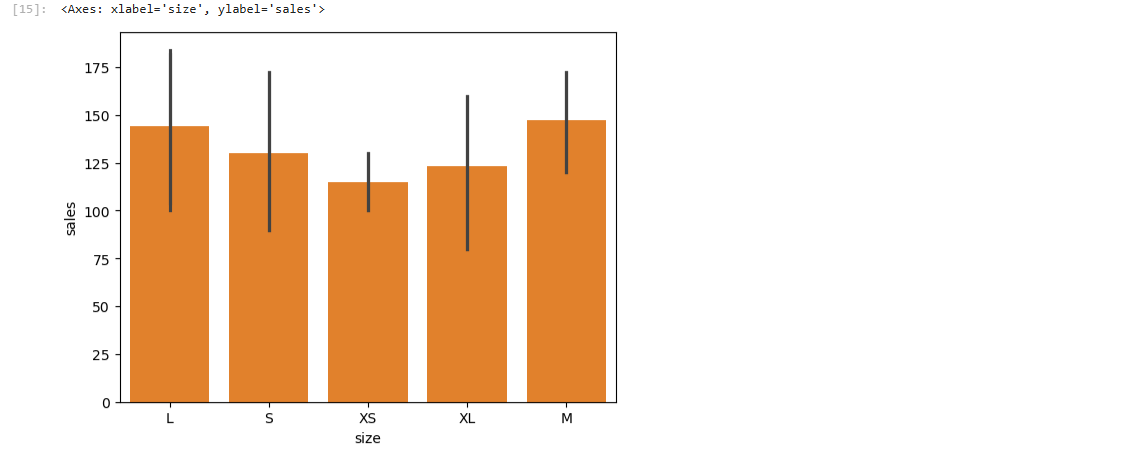
pandas의 category 타입은 범주형 데이터를 더 효율적으로 관리하며, 특히 각 범주에 순서를 지정할 수 있는 기능을 통해 데이터 정렬 및 시각화에서 유용하게 활용할 수 있다.category 타입 개요: 범주형 데이터를 나타내는 pandas 데이터 타입으로, 메
52.[data science] pandas : groupby 와 multi index
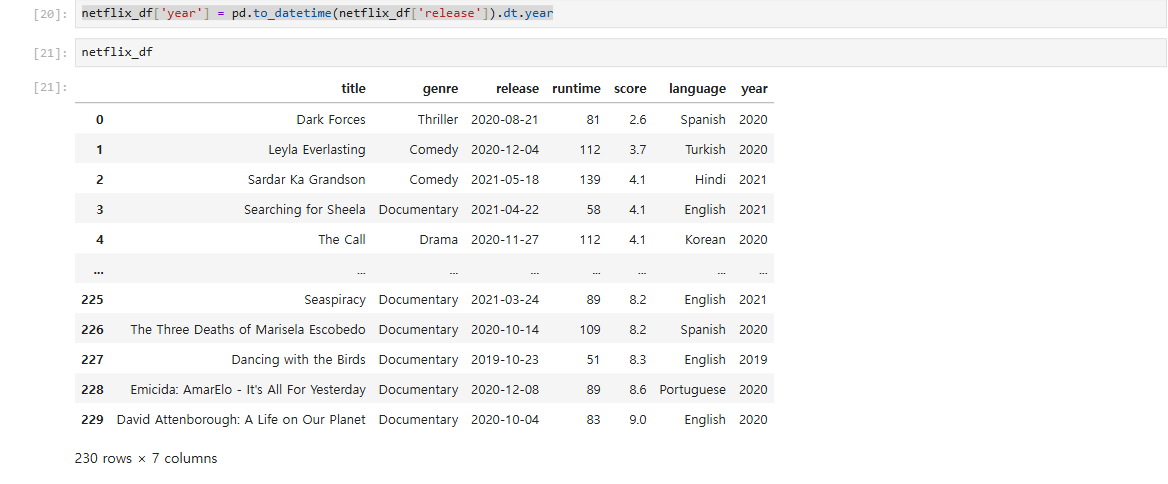
Python의 Pandas 라이브러리를 사용하여 데이터 프레임을 그룹화(grouby)하고 멀티 인덱스를 활용하여 데이터를 확인하고 인덱싱하는 방법Groupby 함수 소개 및 활용: Pandas의 groupby 함수를 사용하는 방법을 배우고, 장르 및 연도 정보를 기준
53.[data science] pandas : groupby를 이용한 통
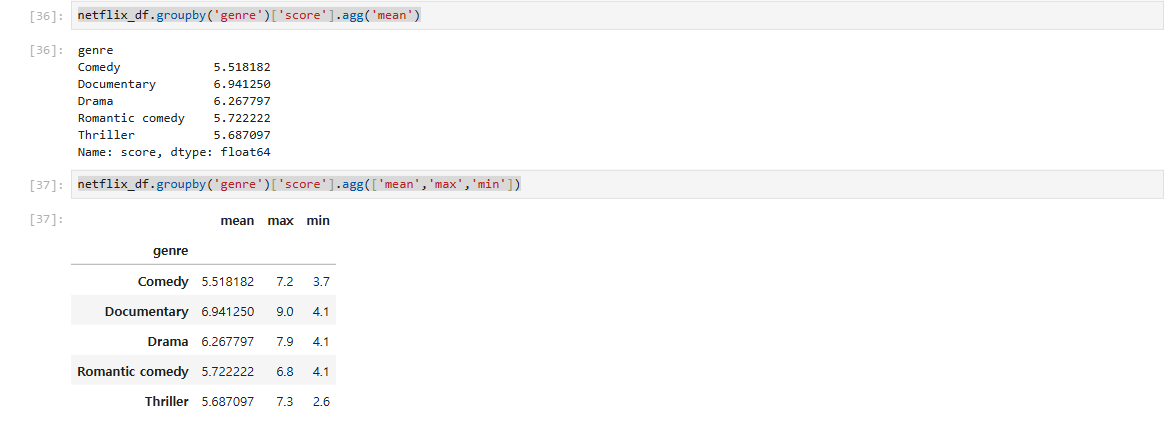
Groupby를 사용하여 여러 통계값을 한 번에 계산할 수 있는 agg() 함수Groupby로 특정 컬럼을 기준으로 데이터를 그룹화 할 수 있다.agg() 함수는 여러 통계값을 한 번에 계산할 수 있게 해준다.agg() 함수 안에 리스트로 여러 통계 연산을 전달하면,
54.[data science] pandas : 피벗테이블

데이터를 요약하고 분석할 때, Groupby와 피벗 테이블은 상호 보완적으로 사용되며, 상황에 따라 각기 다른 장점과 단점을 가지고 있다.피벗 테이블과 Groupby의 차이점: Groupby와 피벗 테이블 모두 데이터를 요약하여 분석할 수 있지만, 피벗 테이블은 인덱스
55.[data science] pandas : resample
핵심 주제pandas의 resample 함수를 사용하면 datetime이 index로 설정된 DataFrame에서 원하는 시간 간격으로 데이터를 묶어 다양한 집계를 수행할 수 있다.주요 내용1\. datetime을 index로 설정하기resample 함수를 사용하기 위