핵심 주제
수치형 데이터는 이산형과 연속형으로 구분되며, 히스토그램을 사용하여 이러한 데이터의 분포를 시각적으로 표현할 수 있다.
주요 내용
수치형 데이터의 구분: 수치형 데이터는 이산형 데이터와 연속형 데이터로 나뉜다. 이산형 데이터는 특정한 값으로 구분되며, 연속형 데이터는 값 사이에 무한한 세분화가 가능하다.
연속형 데이터 예시: 키와 몸무게는 연속형 데이터에 속하며, 이들은 특정 범위 내에서 다양한 값을 가질 수 있다.
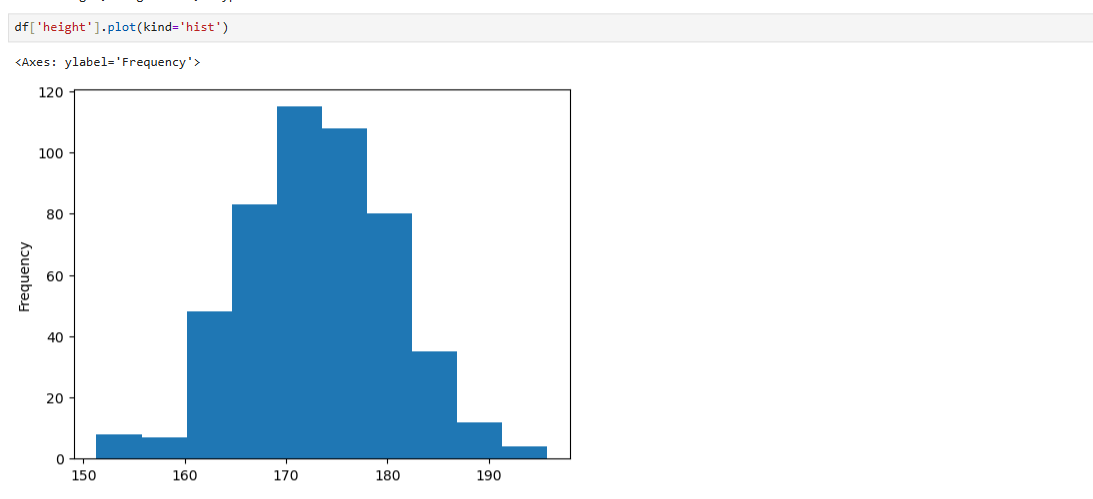
히스토그램의 활용: 히스토그램은 연속형 데이터를 구간별로 묶어 시각화하는 방법으로, 데이터가 특정 범위에 어떻게 분포하는지를 쉽게 파악할 수 있다.
Jupyter Notebook을 통한 히스토그램 생성: pandas와 matplotlib 라이브러리를 이용하여 데이터셋의 특정 열에 대한 히스토그램을 그릴 수 있다.
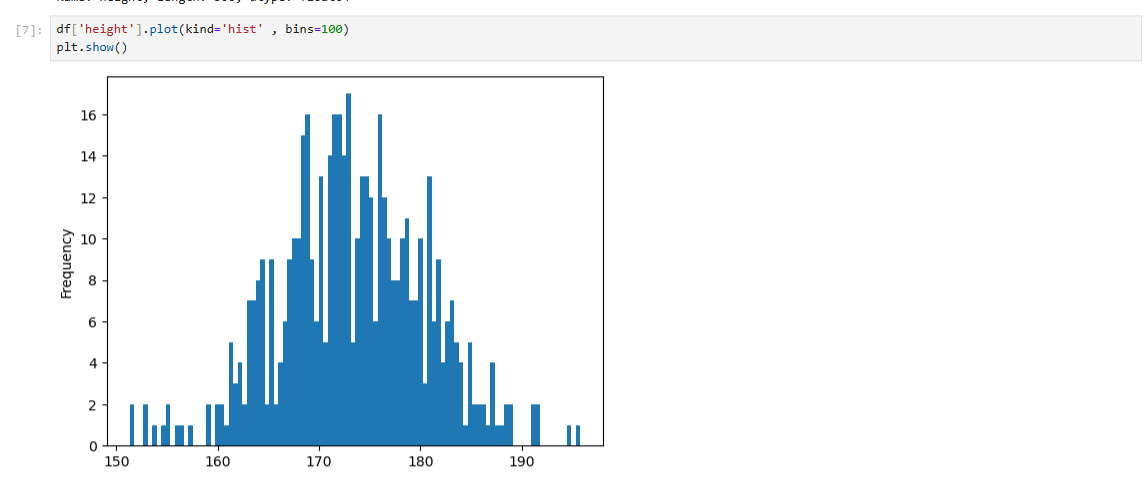
히스토그램의 bin 설정: 히스토그램의 빈(bin) 수는 데이터를 얼마나 세분화할지를 결정한다. 데이터의 특성과 분석 목적에 따라 적절한 빈 수를 설정하는 것이 중요하다.
import pandas as pd
import matplotlib.pyplot as plt
df = pd.read_csv('data/body.csv')
df
df['height'].plot(kind='hist')
df['height'].plot(kind='hist' , bins=100)
plt.show()
import pandas as pd
import matplotlib.pyplot as plt
car_df = pd.read_csv('data/car.csv')1. 현대자동차만 고르기
hyundai_df = car_df[car_df['manufacturer'] == 'HYUNDAI']2. 가격 컬럼으로 히스토그램 그리기
hyundai_df['price'].plot(kind='hist')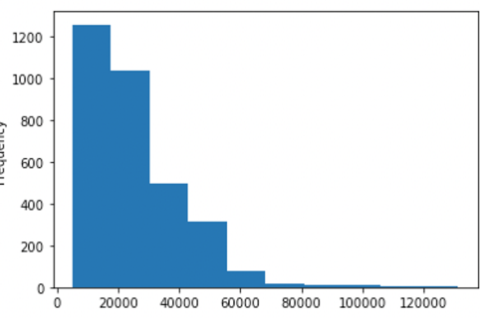

개발자