1) 학습한 내용
라쏘 알고리즘
선형 회귀(linear regression) 그리고 라쏘(Lasso)
데이터 정규화란?
ex)입력 변수 X를 최소값은 0, 최댓값은 1이 되게 1차 함수를 통해서 변환한다.
- Regularization: predict function에 복잡도를 조정하는 작업
ex)Regularization은 모델이 너무 복잡해지지 않도록 임의로 제약을 가하는 것
Blob알고리즘
Tree 계열 분류 알고리즘
Random Forest는 feature space를 랜덤하게 쪼갠다음, 쪼개진 sub feature space를 다시 디시전 트리를 이용해 격자 형태의 decision boundary를 갖도록 분류한다. 이렇게 학습한 N개의 디시전 트리를 앙상블하여 최종 inference에 사용한다. 즉 추론할 때에는 데이터를 모든 디시전 트리에 집어넣고 클래시피케이션한 각각의 분류 결과를 majority voting(다수결) 하는 방식으로 최종 결정을 한다.
이처럼 랜덤포리스트는 앙상블기반의 분류기이므로 이론적으로, 그리고 실질적으로 오버피팅 문제를 적게 격는다.(물론 decision tree의 개수가 너무 적거나, 개별적인 decision tree의 depth가 지나치게 복잡할 경우 오버피팅이 심해질 수 있다.)
Gradient Boosting Tree
Gradient Boosting은 컴퓨터공학의 알고리즘에서 자주 등장하는 greedy 전략을 decision tree에 적용한 것이라고 볼 수 있다. (이와 반대로 divide&conquer전략을 적용한 예시가 random forest이다.)
간단히 요약하자면, Boosting은 기존 모델이 잘 맞추지 못한 데이터에 대해 additional model을 이용해서 모델의 표현력을 계속해서 높이는 방법이다. 기존 모델이 잘 못맞춘 데이터에 대한 정보를 전달하는 방법이 weight에 기반하면 Adaboost가 되고, error를 미분한 gradient에 기반하면 gradient boost가 된다.
Gradient Boosting 알고리즘의 경우 MLP를 예로 들면 그 학습 원리를 바로 이해할 수 있다. 만약 GB_MLP을 만든다면, 경우 먼저 1개의 히든 뉴런만 있는 3층짜리 MLP로 데이터를 학습한다. 그다음 error가 더이상 줄어들지 않으면, 새로운 히든 노드를 하나 추가하고 그 새로 추가된 노드의 weight를 같은 데이터로 다시 학습한다. 이를 error가 충분히 줄어들 때까지 계속 반복한다. 이 과정은 결국 하나의 히든 뉴런을 additional model로써 계속 추가하면서 표현력을 점진적으로 증가시키는 과정에 해당한다.
그런데 만약에 이걸 MLP가아니라, Decision tree를 사용하게 되면 Gradient Boosting Tree(GBTree)가 되는 것이다.
XGBoost tree의 경우, 이러한 과정을 GPU등을 이용해 가속화시켜 5배정도 더 빨리 학습하는 알고리즘이다.
Boosted Decision Tree의 경우 Loss가 미분이 불가능한 형태에서 Boosting을 하는 것으로, gradient descent가 아닌 다른 방법을 이용해서 학습을 시킨다.
Feature Importance
Decision Tree 알고리즘에서는 각각의 attribute가 얼마나 분류 성능에 영향을 미치는지, 즉 feature의 유용성을 판단할 수 있는 Feature Importance를 계산할 수 있다. 이를 계산하는 과정은 다음과 같다.
우선 하나의 decision tree에서 각각의 attribute로 이루어진 split point들 마다 얼마나 트리의 성능이 올라가는지를 계산한다. 그리고 이때 얼마나 많은 데이터 instance가 그 split point(node)에 의해서 영향을 받는지 그 숫자만큼 가중치를 두어 성능 향상치를 계산하게 된다. (이때 성능 증가의 측정 방법에는 다양한 metric이 사용될 수 있다.)
만약 앙상블 모델이라면(RandomForest 등) 이렇게 1개의 decision tree에서 계산된 feature importance를 모든 decision tree에 대해서 구하고, 그 평균을 내어 최종적으로 계산을 하게 된다.
그리고 보통의 경우 이 성능 측정으로는 Gini impurity(=Gini index) or Information Gain 둘중 한가지를 사용한다.
http://machinelearningmastery.com/feature-importance-and-feature-selection-with-xgboost-in-python/
Gini Impurity
수식적으로는 거의 Entropy와 유사하다. 다만 정보량의 평균을 이용해서 불확실성을 구한 것이 아니라, log를 씌우지 않은 확률값(p와 1-p를 이용)을 이용하여 불확실헝을 구했다고 보면 된다. 그래서 마찬가지로 가장 불확실성이 클 때 0.5가 되고, 가장 예측력이 높을 때 값이 0이 된다.
http://funnypr.tistory.com/entry/Random-forestGini-impurity
# Tree 계열 분류 알고리즘
mglearn.plots.plot_tree_progressive()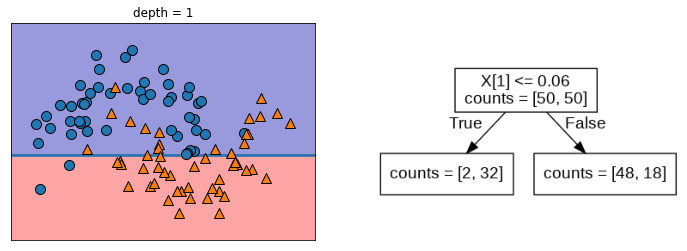
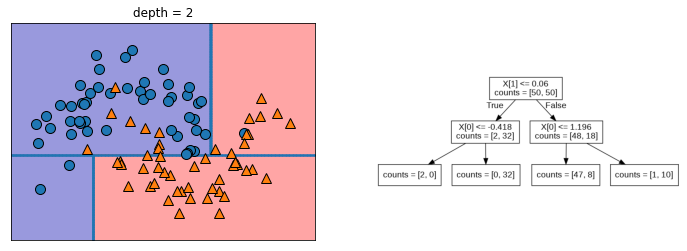
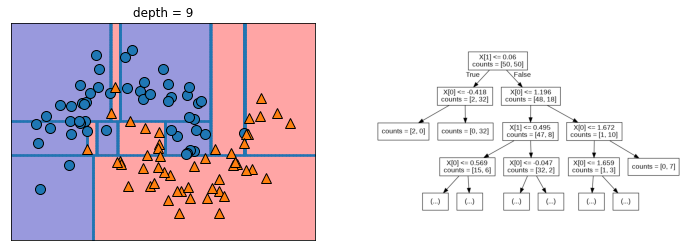
랜덤 포레스트 분류(RandomForestClassifier)
배깅(Bagging)
학습 데이터 세트에 총 1000개의 행이 있다고 해보자. 그러면 임의로 100개씩 행을 선택해서 의사결정 트리를 만드는 게 배깅(bagging)이다. 물론 이런 식으로 트리를 만들면 모두 다르겠지만 그래도 어쨌거나 학습 데이터의 일부를 기반으로 생성했다는 게 중요하다.
그리고 이 때 중복을 허용해야 한다는 걸 기억하자.
랜덤 포레스트는 파이썬 라이브러리 scikit-learn을 사용하면 쉽게 구현할 수 있다.
sklearn.ensemble 모듈에서 RandomForestClassifier를 불러오면 된다. 단, 숲을 만들 때 나무의 개수를 n_estimators라는 파라미터로 지정해주어야 한다.
from sklearn.ensemble import RandomForestClassifier
classifier = RandomForestClassifier(n_estimators = 100)-오버피팅을 피하기 위해 임의(random)의 숲을 구성하는 거다. 다수의 나무들로부터 분류를 집계하기 때문에 오버피팅이 나타나는 나무의 영향력을 줄일 수 있다.
-모든 의사결정 트리는 학습 데이터 세트에서 임의로 하위 데이터 세트를 추출하여 생성된다. 중복을 허용하기 때문에 단일 데이터가 여러번 선택될 수도 있다. 이 과정을 배깅(bagging)이라고 한다.
-나무를 만들 때는 모든 속성(feature)들에서 임의로 일부를 선택하고 그 중 정보 획득량이 가장 높은 것을 기준으로 데이터를 분할한다. 만약 데이터 세트에 n개의 속성이 있는 경우 n제곱근 개수만큼 무작위로 선택하는 것이 일반적이다.
2) 학습내용 중 어려웠던 점
3) 해결방법
4) 학습소감
ps. 수업에 많이 적응되었는지 도중에 잠이 오는 상황은 줄었다. 다만, 오늘은 복부 가운데에 갑자기 통증이 와서 수업에 집중하기가 어려웠었다.
