1. 딥러닝이란?
딥러닝(Deep Learning)은 인공지능(AI)의 한 분야로, 인공 신경망을 사용하여 데이터를 학습하고 예측하는 기술이다.
딥러닝은 특히 대규모 데이터셋과 복잡한 패턴을 다룰 때 뛰어난 성능을 발휘한다.
주요 개념
1. 인공 신경망 (Artificial Neural Networks):
- 딥러닝의 기본 단위로, 인간 뇌의 뉴런을 모방한 구조
- 입력층(Input Layer), 은닉층(Hidden Layer), 출력층(Output Layer)으로 구성
2. 레이어 (Layer):
- 신경망의 각 층은 여러 뉴런으로 이루어져 있으며, 층 사이의 연결을 통해 데이터가 전달되고 변환
3. 피드포워드 신경망 (Feedforward Neural Networks):
- 데이터가 입력층에서 시작하여 출력층으로 한 방향으로만 흐르는 신경망
4. 컨볼루션 신경망 (Convolutional Neural Networks, CNNs):
- 주로 이미지 인식에 사용되는 신경망으로, 컨볼루션 연산을 통해 특징을 추출
5. 순환 신경망 (Recurrent Neural Networks, RNNs):
- 시퀀스 데이터를 다룰 때 유용한 신경망으로, 이전 단계의 출력을 다음 단계의 입력으로 사용
- LSTM(Long Short-Term Memory)과 GRU(Gated Recurrent Units) 같은 변형도 있음
학습 과정
1. 데이터 준비:
- 신경망을 학습시키기 위해 대규모의 데이터셋이 필요.
- 데이터는 학습 데이터(training set)와 검증 데이터(validation set)로 나뉨.
2. 전처리 (Preprocessing):
- 데이터의 품질을 높이기 위해 정규화(normalization)나 표준화(standardization) 등의 작업을 함.
3. 모델 설계 (Model Architecture):
- 신경망의 구조를 설계.
- 몇 개의 층을 사용할지, 각 층에 몇 개의 뉴런을 둘지 등을 결정.
4. 손실 함수 (Loss Function):
- 모델의 예측이 실제 값과 얼마나 다른지 측정하는 함수.
- 대표적으로 교차 엔트로피 손실(cross-entropy loss)와 평균 제곱 오차(mean squared error)가 있음.
5. 역전파 (Backpropagation):
- 손실 함수를 최소화하기 위해 가중치를 업데이트하는 과정.
그래디언트 디센트(Gradient Descent) 알고리즘이 사용됨.6. 학습 (Training):
- 여러 번의 반복(epoch)을 통해 모델을 학습.
7. 평가 (Evaluation):
- 학습된 모델의 성능을 검증 데이터로 평가.
2. 수치 예측
2-1) 선형 회귀 (Linear Regression)
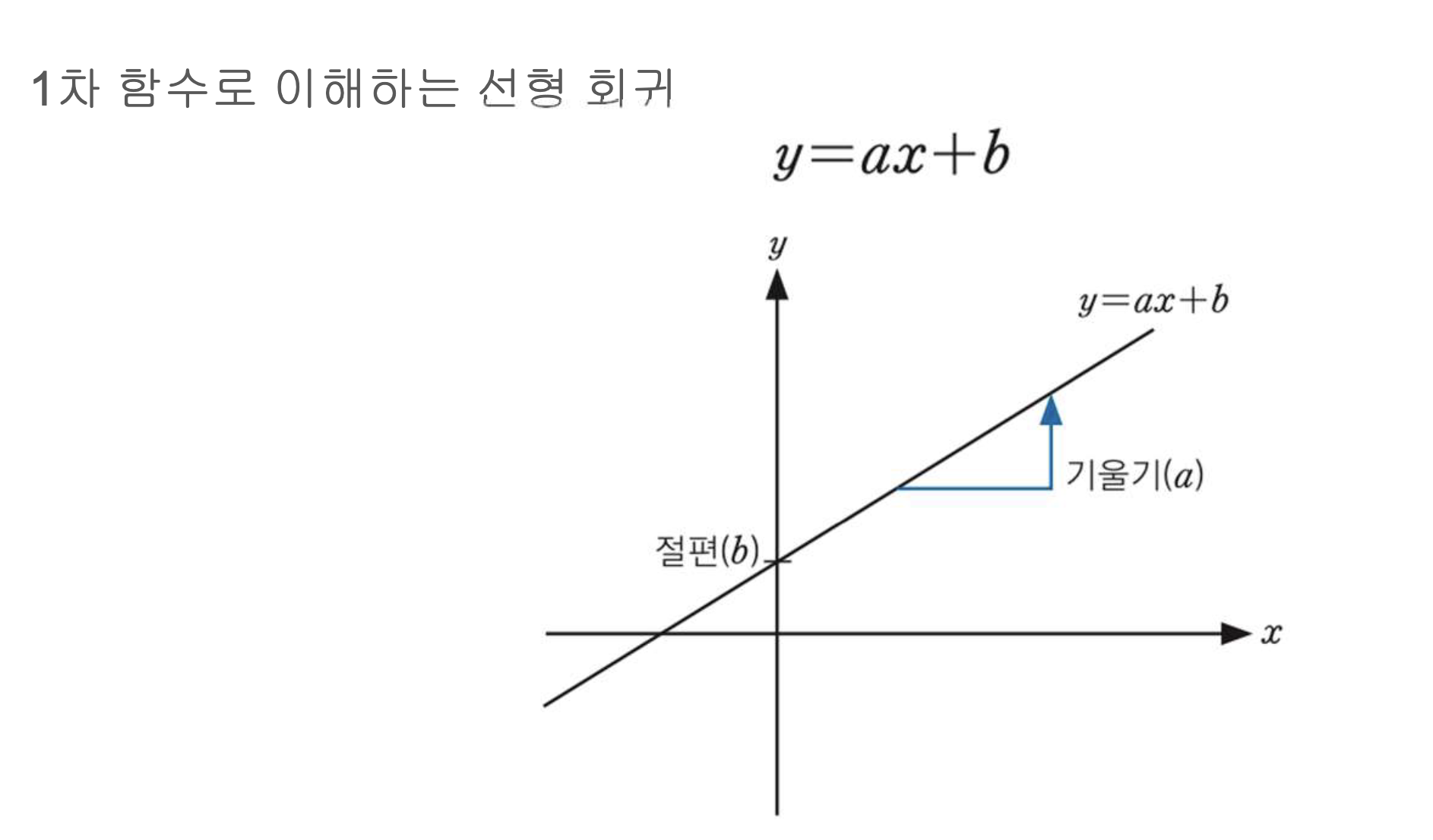
기존에 머신러닝에서 다뤘던 선형 회귀 이다.
기본적으로 기울기를 구할 때 ''로 구한다.
from sklearn.datasets import load_diabetes
diabetes = load_diabetes()
print(diabetes.data.shape, diabetes.target.shape)
### 출력 결과
(442, 10) (442,)해당 코드로만은 데이터가 어떤 특성을 가졌는지 확인이 어려우니, 데이터 프레임화 시켜서 자세히 봐보자.
import pandas as pd
pd.DataFrame(diabetes.data, columns=diabetes.feature_names)
### 출력 결과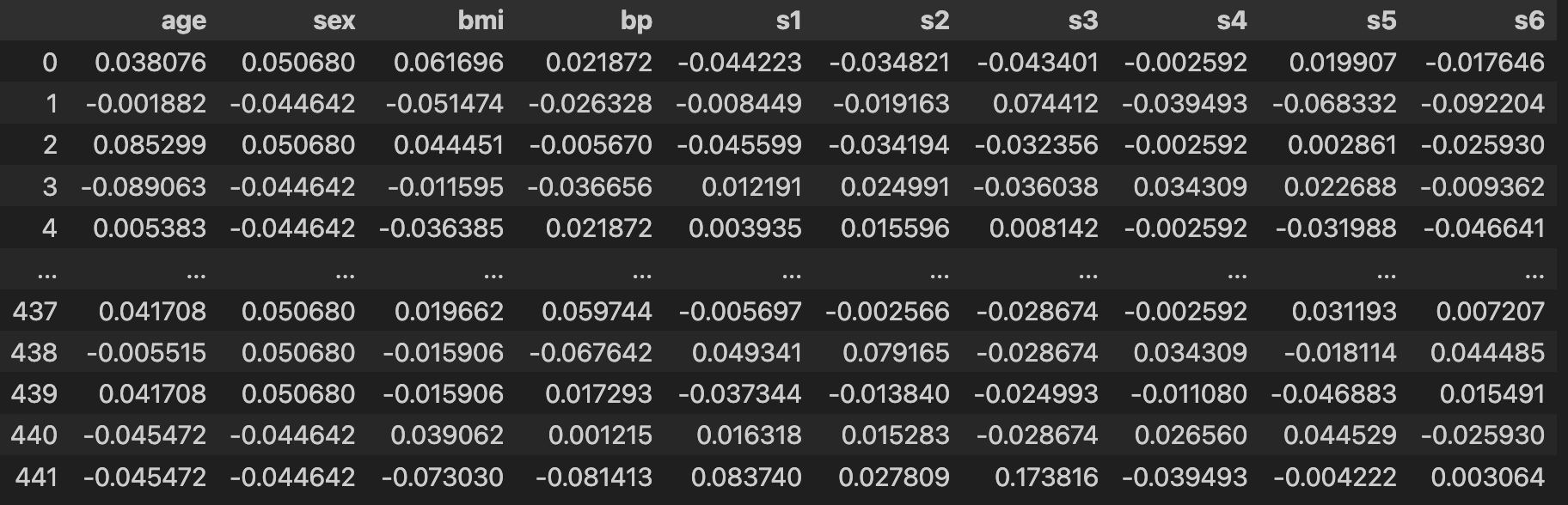
diabetes.data[0:3]
### 출력 결과
array([[ 0.03807591, 0.05068012, 0.06169621, 0.02187239, -0.0442235 ,
-0.03482076, -0.04340085, -0.00259226, 0.01990749, -0.01764613],
[-0.00188202, -0.04464164, -0.05147406, -0.02632753, -0.00844872,
-0.01916334, 0.07441156, -0.03949338, -0.06833155, -0.09220405],
[ 0.08529891, 0.05068012, 0.04445121, -0.00567042, -0.04559945,
-0.03419447, -0.03235593, -0.00259226, 0.00286131, -0.02593034]])
diabetes.target[:3]
### 출력 결과
array([151., 75., 141.])import matplotlib.pyplot as plt
plt.rcParams['axes.unicode_minus'] = FalseMatplotlib은 기본적으로 '-'(빼기, 음수 부호) 표시가 제대로 표기되지 않는다.
그와 동시에 아래와 같은 경고메시지를 출력한다.
UserWarning: Glyph 8722 (\N{MINUS SIGN}) missing from current font.func(*args, **kwargs)
위에는 해당 오류를 수정하는 코드이다.
plt.scatter(diabetes.data[:, 2], diabetes.target)
plt.xlabel('x')
plt.ylabel('y')
plt.show()
### 출력 결과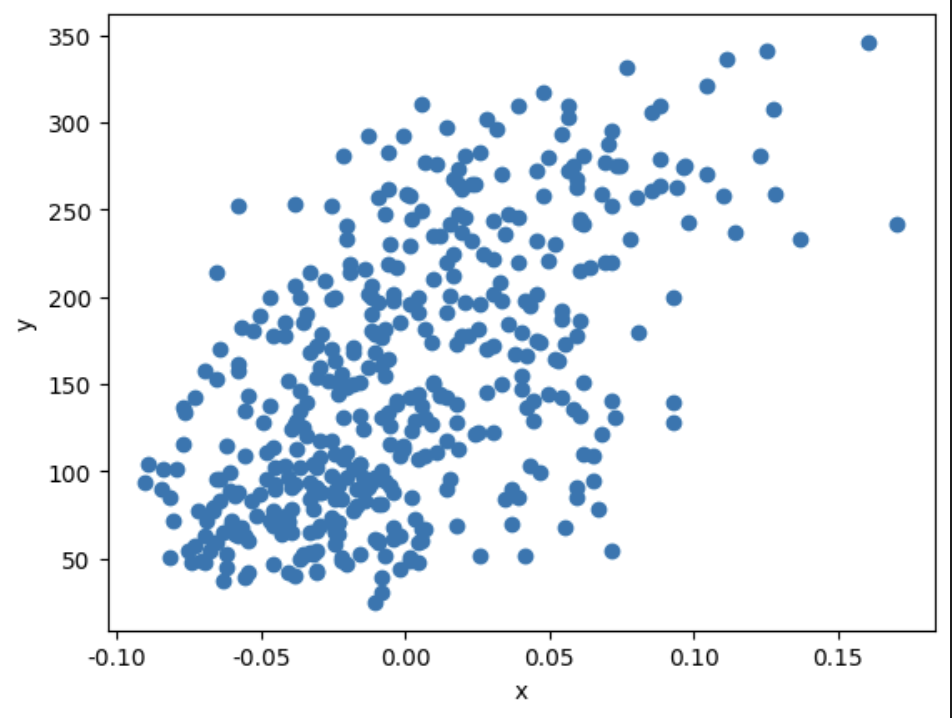
x = diabetes.data[:, 2]
y = diabetes.targetdata는 2번째 column.
즉, bmi 열을 사용하겠다는 뜻이다.
data에는 현재 평균 중심화(mean-centered) 및 표준 편차에 샘플 수의 제곱근을 곱한 값으로 스케일 조정되었다
(즉, 각 열의 제곱합은 1이 됨).
2-2) 경사 하강법
w = 1.0
b = 1.0
y_hat = x[0] * w + b
print(y_hat)
### 출력 결과
1.0616962065186832의 공식이다.
여기서 는 가 되었다.
와 는 각각 가중치, y 절편이다.
print(y[0])
### 출력 결과
151.0
w_inc = w + 0.1
y_hat_inc = w_inc * x[0] + b
print(y_hat_inc)
### 출력 결과
1.0678658271705517
print(y_hat_inc - y_hat)
print(w_inc - w)
### 출력 결과
0.006169620651868435
0.10000000000000009
w_rate = (y_hat_inc - y_hat) / (w_inc - w)
print(w_rate)
### 출력 결과
0.06169620651868429
w_new = w + w_rate
print(w_new)
### 출력 결과
1.0616962065186843
b_inc = b + 0.1
y_hat_inc = x[0] * w + b_inc
print(y_hat_inc)
### 출력 결과
1.1616962065186833
print(y_hat_inc - y_hat)
print(b_inc - b)
### 출력 결과
0.10000000000000009
0.10000000000000009
b_rate = (y_hat_inc - y_hat) / (b_inc - b)
print(b_rate)
### 출력 결과
1.0
b_new = b + 1
print(b_new)
### 출력 결과
2.0w와 b를 임의의 값으로 초기화를 시킨후 증감 시켜가며 적절한 값을 찾는 경사 하강법의 방법이다.
하지만 여기서 큰 단점이 있다.
임의의 값으로 증감 시킬 경우 실제 값까지의 도달하는데 너무 오래 걸릴수 있다는 것이다.
따라서, 실제값과 예측값과의 차이를 계산하여 오차율을 계산한 뒤 기존 값에 곱하여 다시 계산을 해주면 빠르게 실제값에 도달 할 수 있다는 것이다.
그리고 또 하나로는 기존에는 예측값이 실제값을 넘어갈 경우 다시 줄일 수 있는 방법이 없었지만, 해당 방법으로 계산시 오차율이 음수로 나오니 다시 줄일수 있다.
err = y[0] - y_hat
print(err)
w_new = w + w_rate * err
b_new = b + 1 * err
print(w_new, b_new)
### 출력 결과
149.9383037934813
10.250624555903848 150.9383037934813
y_hat = x[1] * w_new + b_new
err = y[1] - y_hat
w_rate = x[1]
w_new = w_new + w_rate * err
b_new = b_new + 1 * err
print(w_new, b_new)
### 출력 결과
14.132317616380695 75.52764127612656
y_hat = x[2] * w_new + b_new
err = y[2] - y_hat
w_rate = x[2]
w_new = w_new + w_rate * err
b_new = b_new + 1 * err
print(w_new, b_new)
### 출력 결과
17.014719208776086 140.3718013346938
for x_i, y_i in zip(x, y):
y_hat = x_i * w + b
err = y_i - y_hat
w_rate = x_i
w = w + w_rate * err
b = b + 1 * err
print(w, b)
### 출력 결과
587.8654539985616 99.4093556453094
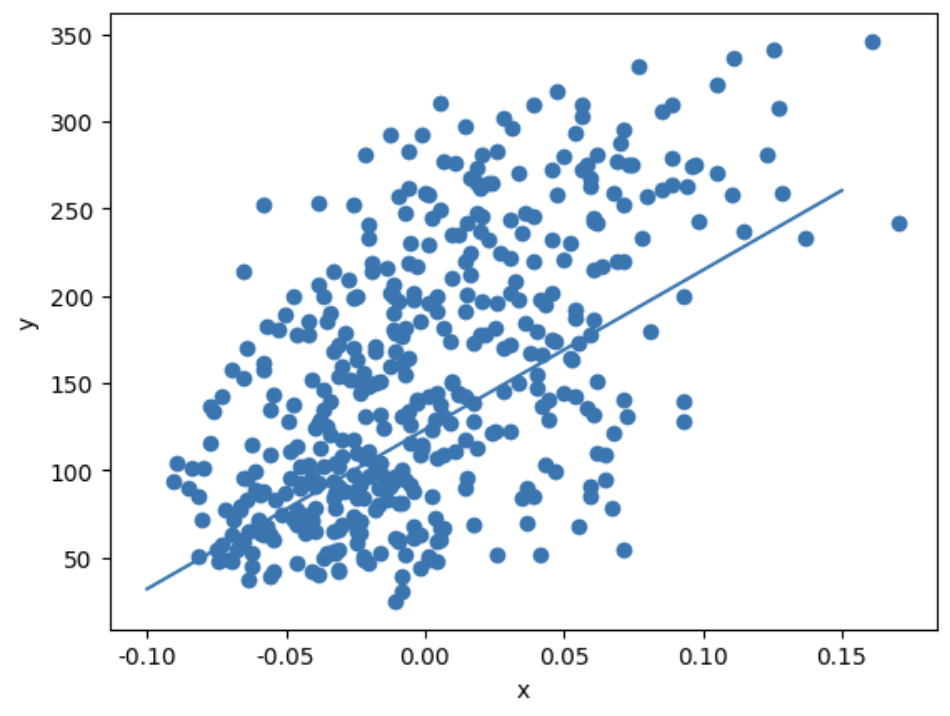
plt.scatter(x, y)
pt1 = (-0.1, -0.1 * w + b)
pt2 = (0.15, 0.15 * w + b)
plt.plot([pt1[0], pt2[0]], [pt1[1], pt2[1]])
plt.xlabel('x')
plt.ylabel('y')
plt.show()
### 출력 결과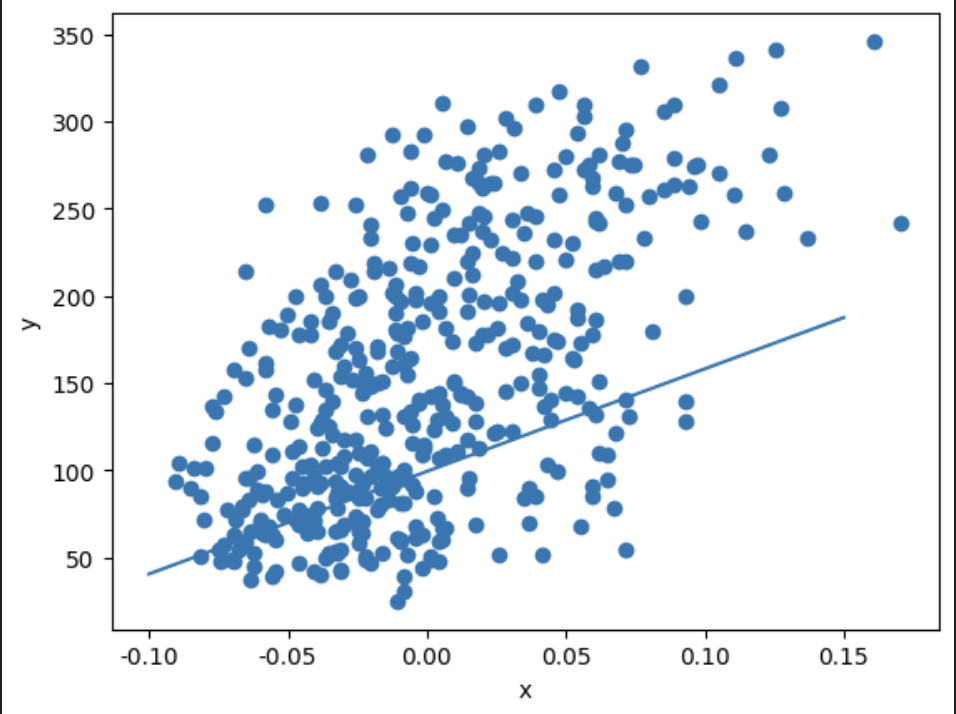
기본적인 경사 하강법을 통해 정답에 근접하게 다가갔다.
따라서, 경사 하강법을 여러번 돌리다 보면 정답에 더욱 더 근접하게 다가갈 수 있다.
x = diabetes.data[:, 2]
y = diabetes.target
for i in range(1, 10):
for x_i, y_i in zip(x, y):
y_hat = x_i * w + b
err = y_i - y_hat
w_rate = x_i
w = w + w_rate * err
b = b + 1 * err
print(w, b)
### 출력 결과
913.5656499924592 123.39181064719266
plt.scatter(x, y)
pt1 = (-0.1, -0.1 * w + b)
pt2 = (0.15, 0.15 * w + b)
plt.plot([pt1[0], pt2[0]], [pt1[1], pt2[1]])
plt.xlabel('x')
plt.ylabel('y')
plt.show()
### 출력 결과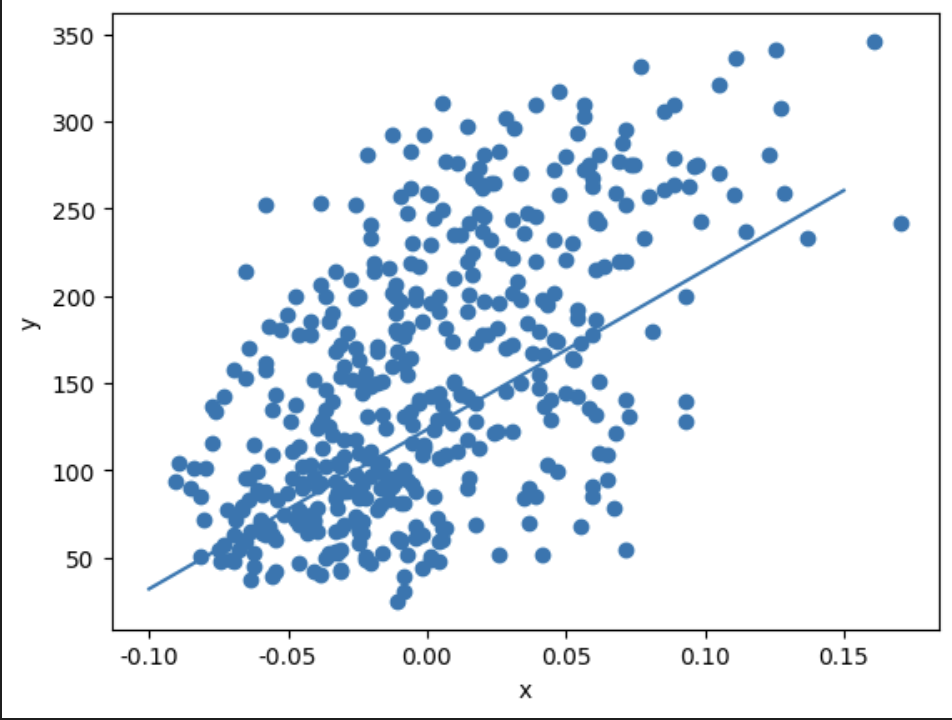
x = diabetes.data[:, 2]
y = diabetes.target
for i in range(1, 100):
for x_i, y_i in zip(x, y):
y_hat = x_i * w + b
err = y_i - y_hat
w_rate = x_i
w = w + w_rate * err
b = b + 1 * err
print(w, b)
### 출력 결과
913.5973364346786 123.39414383177173
plt.scatter(x, y)
pt1 = (-0.1, -0.1 * w + b)
pt2 = (0.15, 0.15 * w + b)
plt.plot([pt1[0], pt2[0]], [pt1[1], pt2[1]])
plt.xlabel('x')
plt.ylabel('y')
plt.show()
### 출력 결과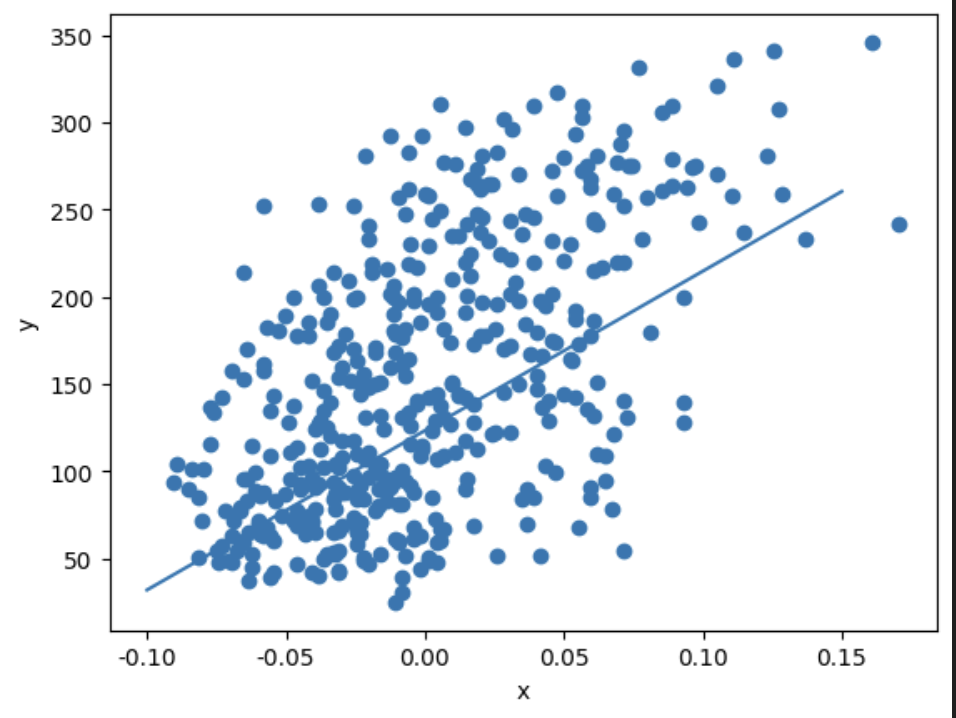
10번만 돌려봐도 정답에 매우 근접하게 다가간 걸 볼 수 있다.
x_new = 0.18
y_pred = x_new * w + b
print(y_pred)
### 출력 결과
287.8416643900139
plt.scatter(x, y)
plt.scatter(x_new, y_pred)
plt.xlabel('x')
plt.ylabel('y')
# plt.show()
### 출력 결과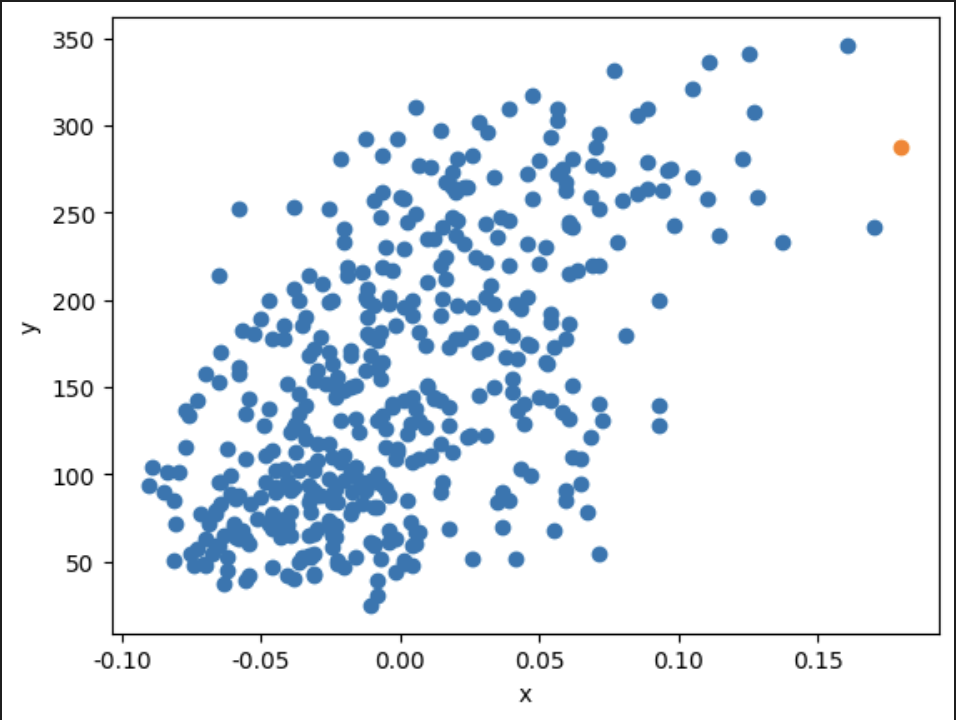
이렇게 새로운 데이터를 넣어봐도 기존 값들과 유사한 위치에 예측하는걸 볼 수 있다.
2-3) 손실 함수와 경사 하강법의 관계
손실 함수란?
손실 함수(Loss Function)는 머신러닝과 딥러닝 모델의 예측 값이 실제 값과 얼마나 다른지를 측정하는 함수이다.
손실 함수는 모델의 성능을 평가하고, 학습 과정에서 모델의 파라미터를 조정하는 데 사용된다.
손실 함수가 작을수록 모델의 예측이 실제 값과 가까워지며, 이를 통해 모델을 최적화할 수 있다.
주요 손실 함수 종류
1. 회귀 문제에서의 손실 함수
1-1) 평균 제곱 오차 (Mean Squared Error, MSE):
- 예측 값과 실제 값의 차이를 제곱하여 평균을 구하는 방식
- 여기서 ( y_i )는 실제 값, ( \hat{y_i} )는 예측 값, ( n )은 데이터 포인트의 수
1-2) 평균 절대 오차 (Mean Absolute Error, MAE):
- 예측 값과 실제 값의 차이의 절대값을 평균한 것
1-3) 평균 제곱 로그 오차 (Mean Squared Logarithmic Error, MSLE):
- 예측 값과 실제 값의 로그 차이의 제곱을 평균한 것
2. 분류 문제에서의 손실 함수
2-1) 교차 엔트로피 손실 (Cross-Entropy Loss):
- 예측 확률 분포와 실제 분포 간의 차이를 측정
- 이진 분류와 다중 클래스 분류에서 사용
2-2) 이진 교차 엔트로피 (Binary Cross-Entropy)
2-3) 다중 클래스 교차 엔트로피 (Categorical Cross-Entropy)
- 여기서 는 클래스의 수, 는 실제 값 (원-핫 인코딩), 는 예측 확률이다.
2-4) 스파스 교차 엔트로피 (Sparse Categorical Cross-Entropy):
- 다중 클래스 교차 엔트로피와 유사하지만, 실제 레이블이 원-핫 인코딩되지 않은 정수로 표현
3. 기타 손실 함수
3-1) 허브 손실 (Huber Loss):
- MSE와 MAE의 장점을 결합한 손실 함수로, 이상치에 덜 민감
2-4) 뉴런
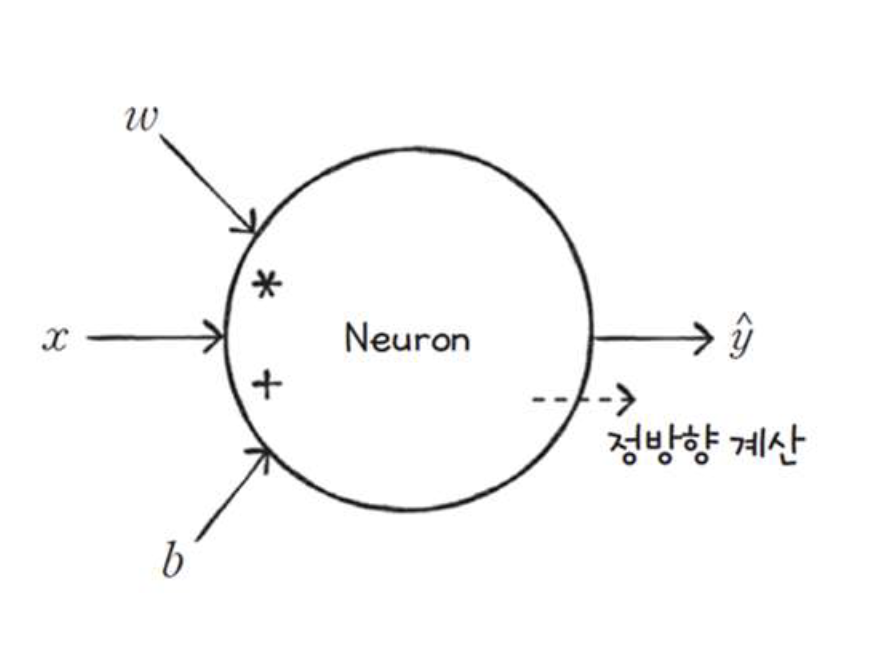
뉴런이란?
뉴런(Neuron)은 딥러닝과 인공신경망에서 정보 처리를 담당하는 기본 단위이다.
생물학적 뉴런에서 영감을 받아 만들어진 인공 뉴런은 입력을 받아 가중치를 적용하고, 활성화 함수를 통해 출력을 생성한다.
이러한 뉴런들이 모여 신경망을 구성하고, 복잡한 패턴을 학습하게 된다.
뉴런의 구조와 작동 원리
1. 입력 (Input):
- 뉴런은 여러 입력값을 받는다.
- 이 입력값들은 각기 다른 가중치(weight)와 곱해진다.
- 입력값과 가중치는 뉴런이 학습을 통해 조정하는 주요 요소이다.
2. 가중합 (Weighted Sum):
- 각 입력값과 해당 가중치의 곱을 모두 더하여 가중합을 계산
- 여기서 ( x_i )는 입력값, ( w_i )는 가중치, ( b )는 바이어스(bias)이다.
3. 활성화 함수 (Activation Function):
가중합을 비선형 변환하여 출력으로 변환하는 함수.
활성화 함수는 신경망이 복잡한 패턴과 비선형성을 학습할 수 있게 한다.
시그모이드 함수 (Sigmoid Function): 출력값을 0과 1 사이로 변환한다.
ReLU (Rectified Linear Unit): 입력값이 0보다 크면 그대로 출력하고, 0 이하이면 0을 출력한다.
탄젠트 하이퍼볼릭 함수 (Tanh): 출력값을 -1과 1 사이로 변환한다.
4. 출력 (Output):
- 활성화 함수를 통해 변환된 값을 출력으로 내보낸다.
- 이 출력값은 다음 층의 뉴런으로 전달되거나, 최종 예측 결과로 사용된다.
인공 신경망의 구성
입력층 (Input Layer):
- 외부 데이터가 입력되는 층
은닉층 (Hidden Layer):
- 입력층과 출력층 사이에 위치한 층으로, 각 층은 여러 뉴런으로 구성.
- 은닉층의 뉴런은 입력값을 처리하고, 다음 층으로 전달
출력층 (Output Layer):
- 최종 예측값을 출력하는 층
학습 과정
1. 순전파 (Forward Propagation):
- 입력 데이터를 뉴런을 통해 순차적으로 처리하여 최종 출력을 생성
2. 손실 계산 (Loss Calculation):
- 출력값과 실제 값 간의 오차(손실)를 계산
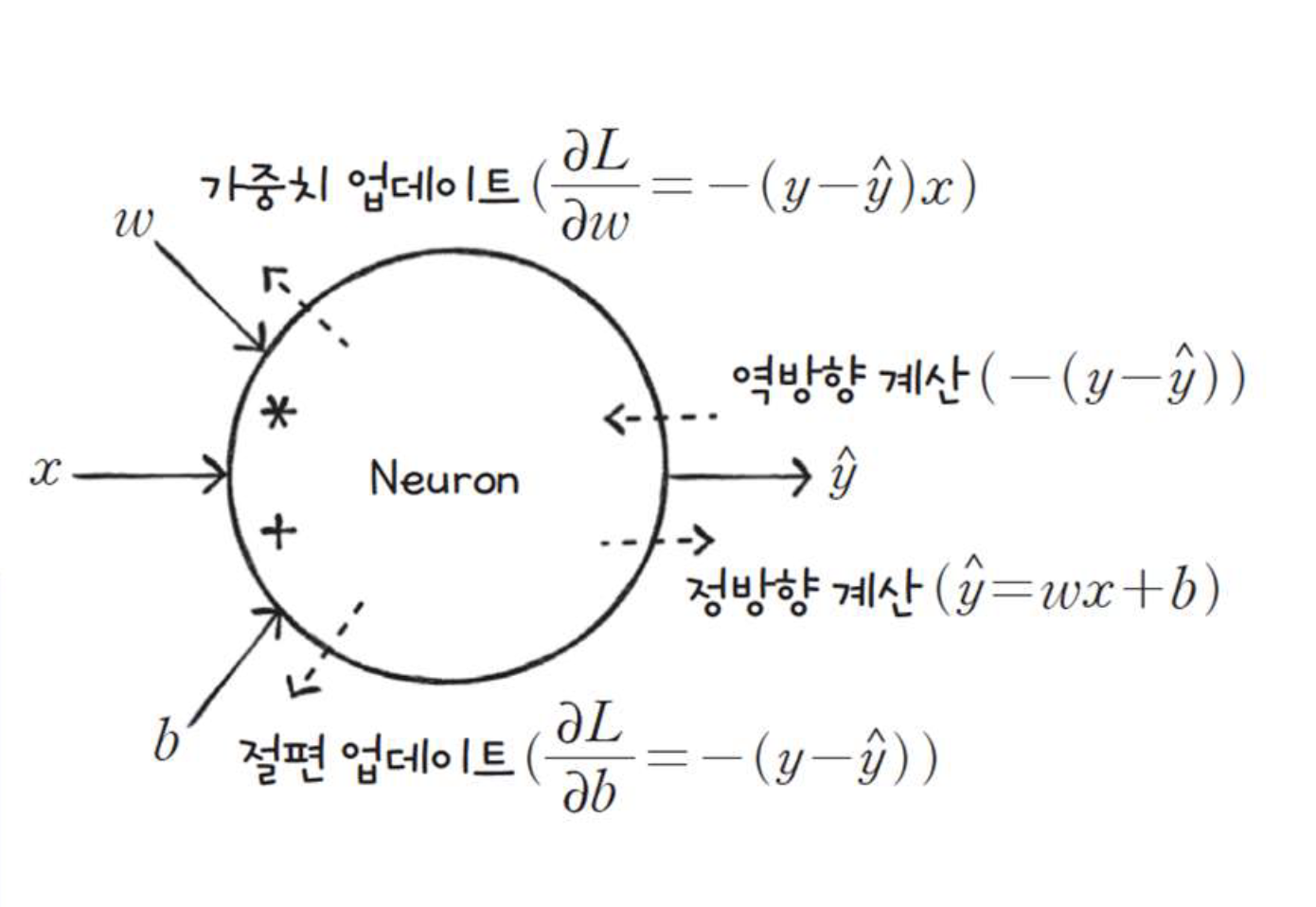
3. 역전파 (Backpropagation):
- 손실을 최소화하기 위해 가중치와 바이어스를 조정
- 그래디언트 디센트(Gradient Descent) 알고리즘을 사용하여 가중치의 그래디언트를 계산하고, 이를 이용해 가중치를 업데이트
class Neuron:
def __init__(self):
self.w = 1.0 # 가중치를 초기화합니다
self.b = 1.0 # 절편을 초기화합니다
def forpass(self, x):
y_hat = x * self.w + self.b # 직선 방정식을 계산합니다
return y_hat
def backprop(self, x, err):
w_grad = x * err # 가중치에 대한 그래디언트를 계산합니다
b_grad = 1 * err # 절편에 대한 그래디언트를 계산합니다
return w_grad, b_grad
def fit(self, x, y, epochs=100):
for i in range(epochs): # 에포크만큼 반복합니다
for x_i, y_i in zip(x, y): # 모든 샘플에 대해 반복합니다
y_hat = self.forpass(x_i) # 정방향 계산
err = -(y_i - y_hat) # 오차 계산
w_grad, b_grad = self.backprop(x_i, err) # 역방향 계산
self.w -= w_grad # 가중치 업데이트
self.b -= b_grad # 절편 업데이트
neuron = Neuron()
neuron.fit(x, y)
print("w :", neuron.w)
print("b :", neuron.b)
### 출력 결과
w : 913.5973364346786
b : 123.39414383177173
plt.scatter(x, y)
pt1 = (-0.1, -0.1 * neuron.w + neuron.b)
pt2 = (0.15, 0.15 * neuron.w + neuron.b)
plt.plot([pt1[0], pt2[0]], [pt1[1], pt2[1]])
plt.xlabel('x')
plt.ylabel('y')
plt.show()
### 출력 결과