목적
- 이 글은 업무적으로 캐싱의 흐름을 개선한 내용을 정리한 내용입니다.
- 업무적으로 개선한 사항을 정리한 내용으로 전반적인 개선 흐름만 문서화 하였습니다.
- 서비스의 역할, 구조상 해당 개선사항을 모든 서비스에 적용할 수 없고 개선하고자 하는 서비스를 정확히 이해한 이후에 그에 적합한 성능 개선을 하는것이 바람직하다고 생각합니다.
기존
작업 흐름
- 기존
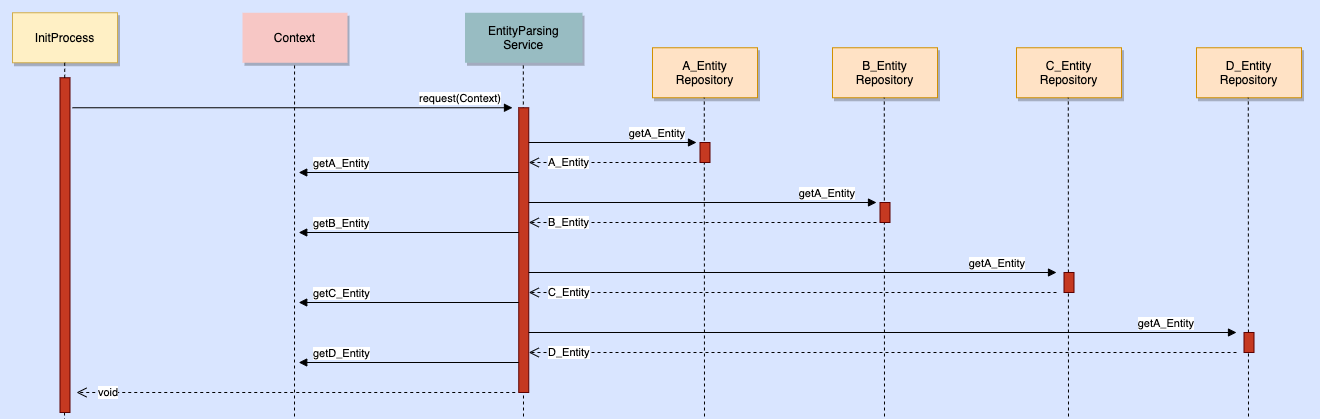
- 코드: Entity 리포지토리 별로 @Cacheable 이 설정되어 있다.
public interface EntityA_Repository extends JpaRepository<EntityA, Long> {
@Cacheable(cacheNames = CachingConfig.CACHE_NAME_1, key = "{...}")
@Query("...")
Optional<EntityA> findByUniqueKeys(...);
...
}public interface EntityB_Repository extends JpaRepository<EntityB, Long> {
@Cacheable(cacheNames = CachingConfig.CACHE_NAME_2, key = "{...}")
@Query("...")
Optional<EntityB> findByUniqueKeys(...);
...
}public interface EntityC_Repository extends JpaRepository<EntityC, Long> {
@Cacheable(cacheNames = CachingConfig.CACHE_NAME_3, key = "{...}")
@Query("...")
Optional<EntityC> findByUniqueKeys(...);
...
}문제점
- EntityA, EntityB, EntityC 로 연관관계가 되어 있기 때문에 한 객체의 인스턴스에 캐싱이 큰 의미를 가지기 힘들다.
- 위와 같은 이유로 AOP 에 의한 Spring-Cache 특성상 Entity 계층에 2차 캐시를 적용할 경우 잦은 Dispatch 가 필요하다.
- 해당 서버 특성상 객체가 가지는 도메인적인 역할 수행이 필요하다기 보다는 단순히 데이터의 상태가 필요하다.
- In-memory 캐시의 메모리 효율성이 떨어진다.
- 각 엔티티의 역할에 대한 책임을 제외하더라도, 서비스 내에서 실제로 사용하는 값은 엔티티가 가진 값의 지극히 일부다.
- 캐시의 관리 포인트가 많아지며, 각 엔티티의 캐싱 주기도 따로 관리되기 때문에 원자성 보장이 힘들다.
- 예를 들어 EntityA, EntityB 까지는 캐싱되어 있는데 EntityC 만 만료되어 있는 경우 결국 해당 요청이 발생할 경우 또 DB 를 조회해야 한다.
서비스의 특성
-
EntityA, EntityB, EntityC 중에 DB 에서는 EntityC 만 알면, 다른 Entity는 조인으로 알 수 있다.
-
요청상 EntityC 에 대하여 모든 요청이 골고루 들어오는것이 아니라 특정 id 의 EntityC 에대한 요청이 자주 들어온다.
- 즉, 요청이 편중되어 있다.
- 수집한 지표상 50,000 개의 EntityD 중에서, 상위 5퍼센트에 대한 요청이 80퍼센트 이상이었다.
-
엔티티의 도메인적 역할보다는 있는 데이터를 그대로 보여주는것이 메인인서비스이다.
-
속도가 매우매우 중요한 서비스이다.
개선
작업 흐름
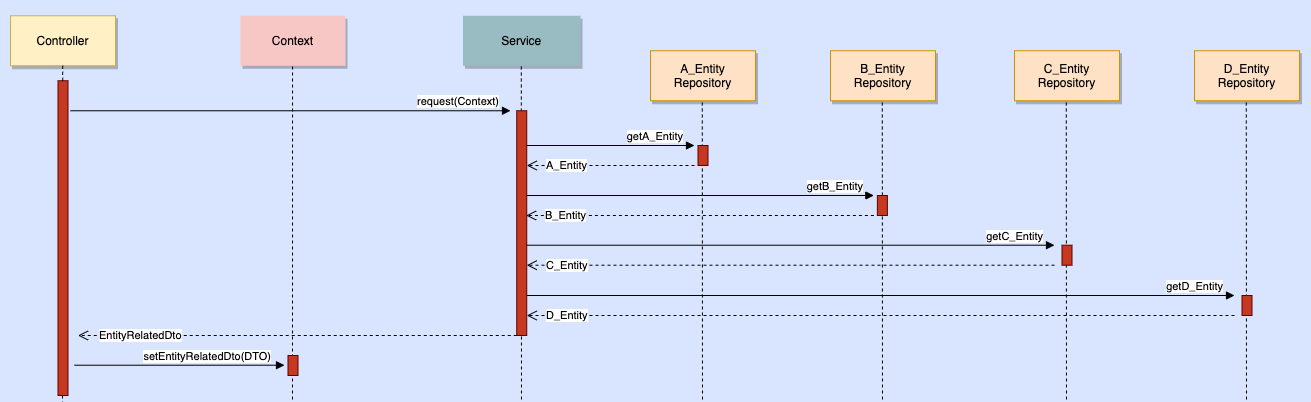
개선사항
- Join 이 되어 있지 않은 쿼리에 대하여 Fetch 조인 또는 LEFT 조인을 하여 자주 DB 를 조회하지 않도록 하였다.
- 각 리포지토리에 적용되어 있던 캐싱을 서비스 계층으로 옮기고, 엔티티 역할간에 key 역할을 하는 entityC 의 id 를 key 로 설정하였다.
- 캐싱 포인트가 서비스 계층으로 옮겨짐에 따라, 실제 서비스에서 사용되는 값만을 따로 모아서 캐싱할 수 있도록 별도의 종합 EntityDto 를 만들고 이를 저장하도록 하였다.
코드
- 종합 EntityDto
public class EntityRelatedDto implements Serializable {
//EntityA
private Long a_property_1;
private String a_property_2;
//EntityB
private Long b_property_1;
private Long b_property_2;
private String b_property_3;
//EntityC
private Long c_property_1;
private Long c_property_2;
private Long c_property_3;
}- Service 계층 코드
@Slf4j
@Service
@RequiredArgsConstructor
public class EntityParsingService {
private final EntityA_Repository EntityA_REPOSITORY; // EntityA + EntityA_2 FETCH JOIN
private final EntityB_Repository EntityB_REPOSITORY; // EntityB + EntityB_2 FETCH JOIN
private final EntityC_Repository EntityC_REPOSITORY; // EntityC + EntityC_2 + EntityC_3 LEFT OUTER JOIN
@Cacheable(
value = "EntityParseDtoCache",
key = "#requestDto.request.info.entityD")
public SspEntityParseDto requestParsing(RequestParseDto requestDto) {
RequestInfo info = requestDto.getSspRequest().getSspInfo();
EntityA entityA = EntityA_REPOSITORY.findById(info.getPublisherId())
.orElseThrow(() -> new Exception());
EntityB entityB = EntityB_REPOSITORY.findBySspIdAndAdClassId(info.getId(), info.getClassId())
.orElseThrow(() -> new Exception());
EntityC entityC = EntityC_REPOSITORY.findById(info.getPid())
.orElseThrow(() -> new Exception());
return EntityParseDto.builder()
.aEntityProperty_1(entityA.getProperty1())
.aEntityProperty_2(entityA.getProperty2())
.bEntityProperty_1(entityB.getProperty1())
.bEntityProperty_2(entityB.getProperty2())
.bEntityProperty_3(entityB.getProperty3())
.cEntityProperty_1(entityC.getProperty1())
.cEntityProperty_2(entityC.getProperty2())
.cEntityProperty_3(entityC.getProperty3())
.build();
}
}시스템 지표 결과
1) 쿼리 성능 결과
- 기존: 약 231ms
- 개선: 약 206ms
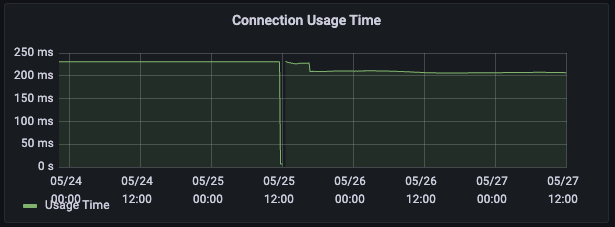
2) 캐싱 메커니즘 관련 캐시 HIT 결과
-
기존
- connection_size: 84
- 평균 Active: 30
-
개선
- connection_size: 65
- 평균 Active: 3

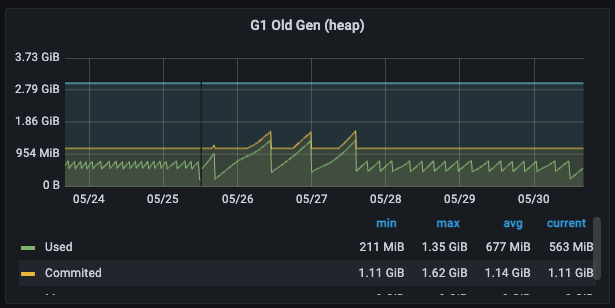
3) 메모리 관련 결과
- 5/24 ~ 5/25 기간(하루) OLD 영역 메모리가 정리된 횟수: 11회
- 5/29 ~ 5/30 기간(하루) OLD 영역 메모리가 정리된 횟수: 5회
- GC 가 발생하는 획수 6회 약(50%) 감소
- 평균 STW (Stop-The-World) 시간은 733µs → 655µs 로 줄긴 했으나, 배포후 중간에 JVM 이 메모리 최적화 하는 시간이 함께 포함되어 있어서, 이는 배포후 좀더 봐야 알 수 있을듯.
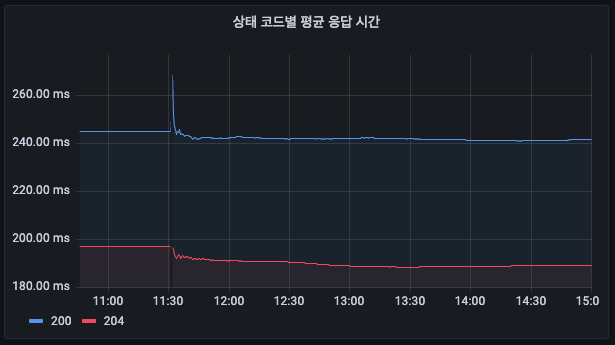
4) 상태 코드결 평균 응답시간 결과
-
기존
- 200: 245ms, 204: 197ms
-
개선
- 200: 241ms, 204: 190ms
DB 모니터링 결과
1) NetworkTransmitThroughput
-
배포 시점(5/30) 이후로 DB 의 network transmit 에서 Bytes/Second 지표가 전반적으로 낮아진 것 확인
-
기존 - 고점 기준: 330k
-
개선 - 고점 기준: 261K

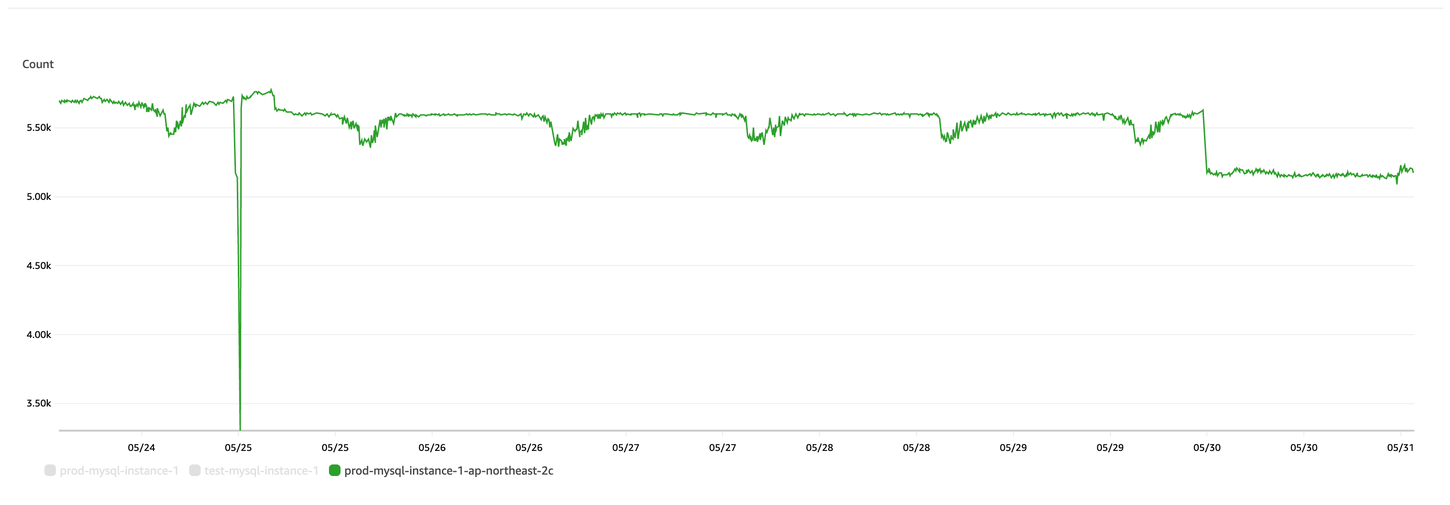
2) DatabaseConnections: Sum
DB 를 연결하고 있는 커넥션 수 감소
- 기존: 약 5,600
- 개선: 약 5,100
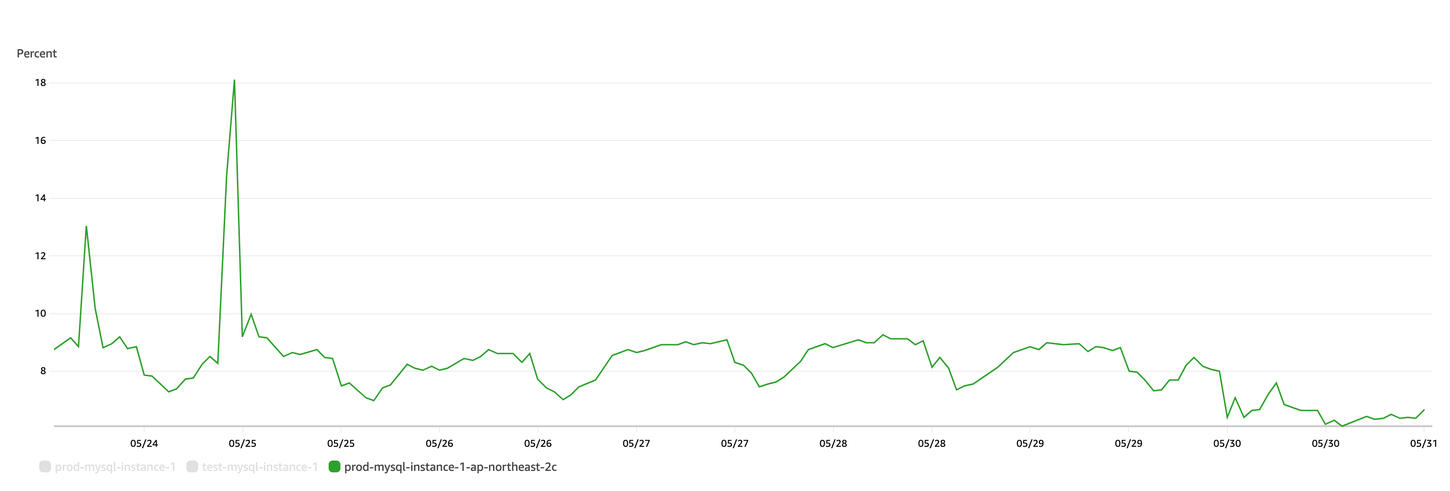
3) CPU Utilization: Average
CPU 평균 사용율 감소
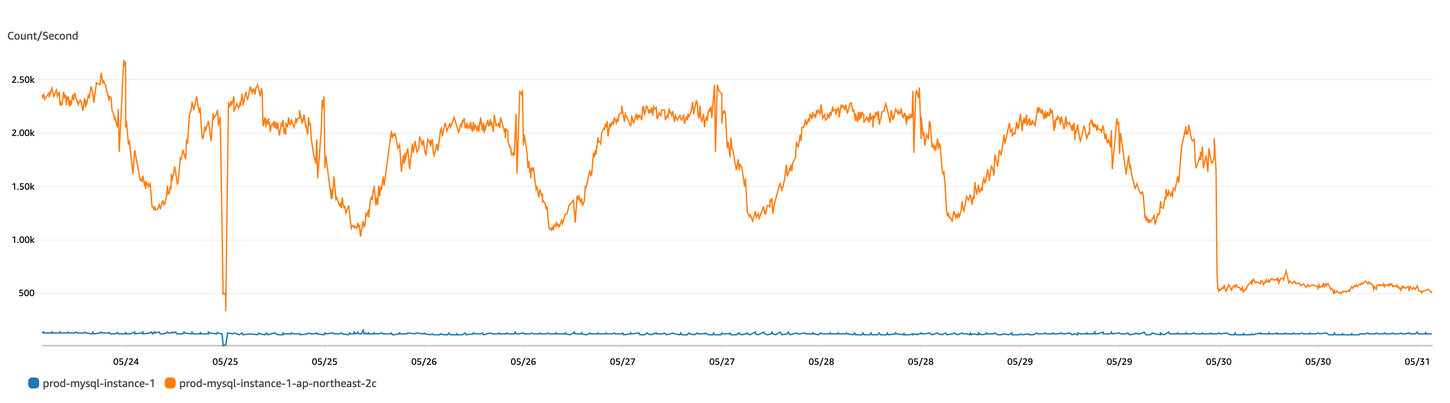
4) Queries
쿼리량 감소
- 대상: prod-mysql-instance-1-ap-northeast-2c
- 기존: 1,600(중간지점 기준)
- 개선: 600
고려해야할 사항
- 서비스상 EntityA, EntityB, EntityC 는 모두 같은 변경주기를 가지는 엔티티입니다.
- 위와 같이 엔티티간 묶음 캐싱을 적용할 경우 각 엔티티가 같은 변경주기가 아닐 경우 이를 따로 관리하는것이 좋습니다.
