📌오토인코더(AutoEncoder)
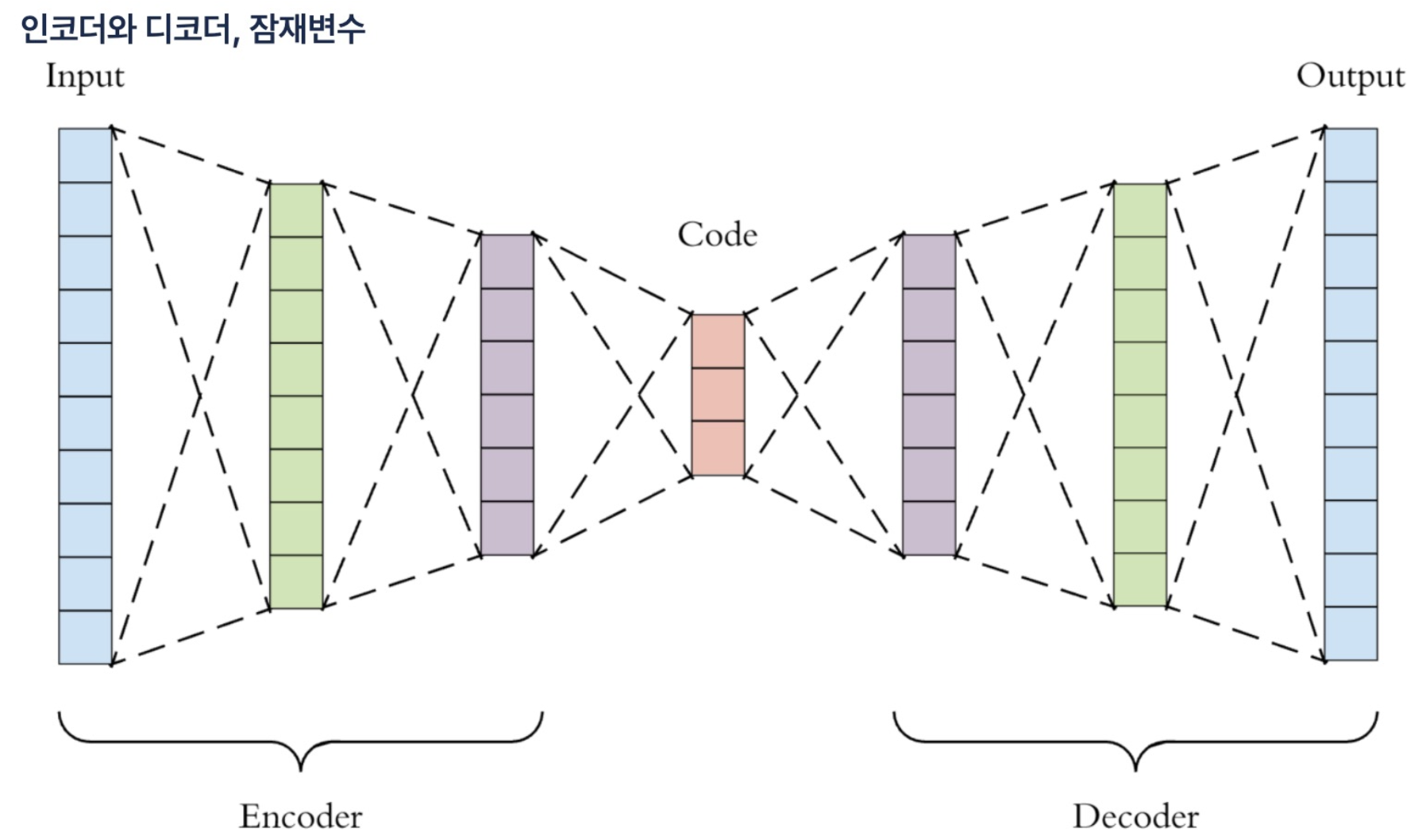
- 오토인코더는 입력과 출력이 동일하다.
- 자기 자신을 재생성하는 네트워크 - Latent Vector: 잠재변수, Encoder: 입력쪽, Decoder: 출력쪽
- 인코더: 일종의 특징 추출기과 같은 역할
- 디코더: 압축된 데이터를 다시 복원하는 역할
import tensorflow as tf
import numpy as np- mnist
(train_X, train_Y), (test_X, test_Y) = tf.keras.datasets.mnist.load_data()
print(train_X.shape, train_Y.shape)
train_X = train_X / 255.0
test_X = test_X / 255.0
train_X = train_X.reshape(-1, 28 * 28)
test_X = test_X.reshape(-1, 28 * 28)
print(train_X.shape, train_Y.shape)
model = tf.keras.Sequential([
tf.keras.layers.Dense(784, activation='relu', input_shape=(784,)),
tf.keras.layers.Dense(64, activation='relu'),
tf.keras.layers.Dense(784, activation='sigmoid')
])
model.compile(optimizer=tf.optimizers.Adam(), loss='mse')
model.summary()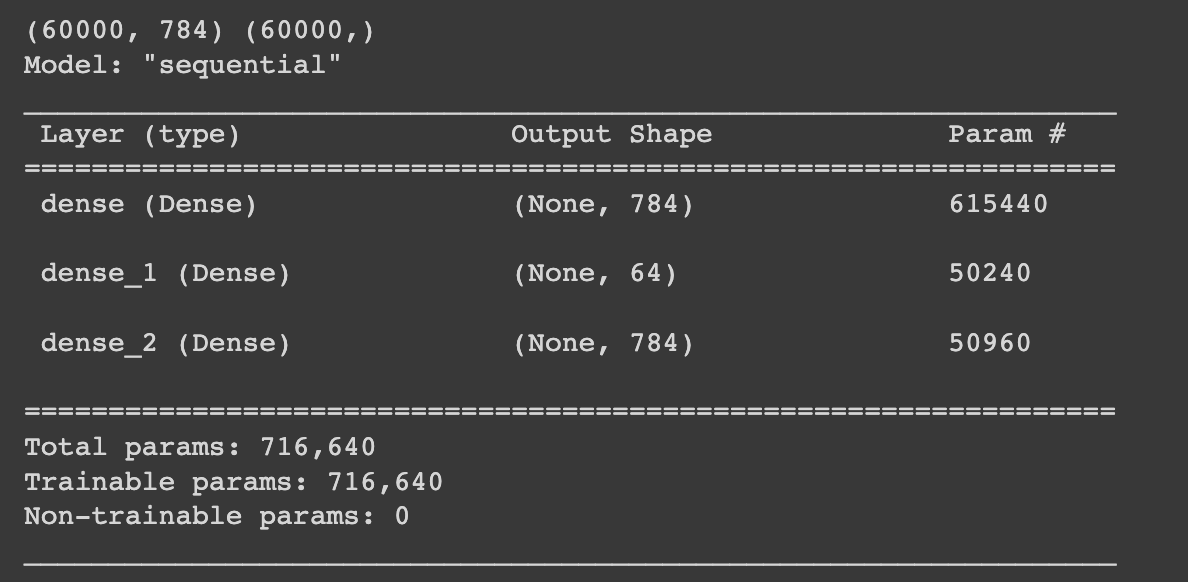
오토 인코더는 자신을 출력으로 가짐.
즉, 자기 자신을 비교한다.
-> 잠재벡터가 입력을 대표하는 특성벡터가 된다.(특징추출)
model.fit(train_X, train_X, epochs=10, batch_size=256)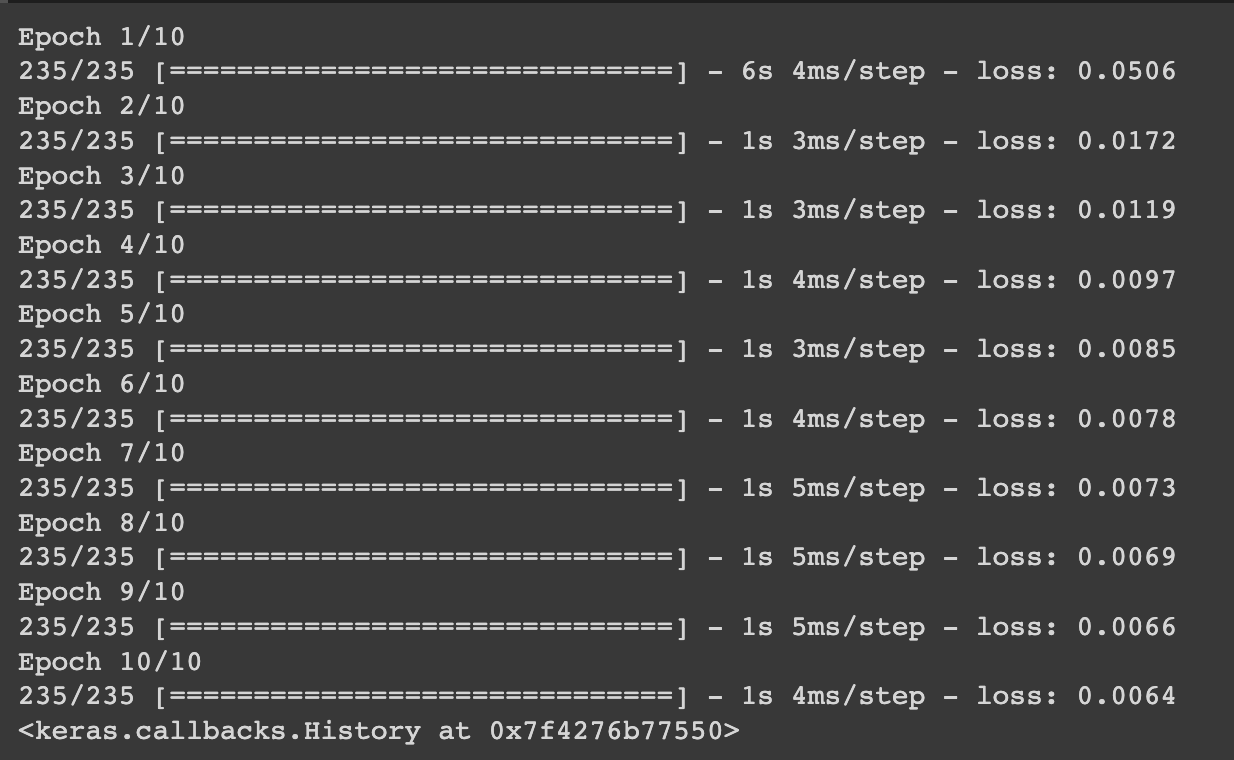
- 랜덤한 값을 뽑아 test data의 이미지를 뽑아주고, 해당 테스트 데이터를 예측시켜 그 결과의 이미지를 보여준다.
import random
import matplotlib.pyplot as plt
plt.figure(figsize=(4, 8))
for c in range(4):
plt.subplot(4, 2, c*2+1)
rand_index = random.randint(0, test_X.shape[0])
plt.imshow(test_X[rand_index].reshape(28, 28), cmap='gray')
plt.axis('off')
plt.subplot(4, 2, c*2+2)
img = model.predict(np.expand_dims(test_X[rand_index], axis=0))
plt.imshow(img.reshape(28, 28), cmap='gray')
plt.axis('off')
plt.show()
model.evaluate(test_X, test_X)
화질이 조금 떨어지는데 자기 자신을 잘 표현한 것 처럼 보임
- CNN
train_X = train_X.reshape(-1, 28, 28, 1)
test_X = test_X.reshape(-1, 28, 28, 1)
model = tf.keras.Sequential([
tf.keras.layers.Conv2D(filters=32, kernel_size=2, strides=(2,2), activation='relu', input_shape=(28, 28, 1)),
tf.keras.layers.Conv2D(filters=64, kernel_size=2, strides=(2,2), activation='relu'),
tf.keras.layers.Flatten(),
tf.keras.layers.Dense(64, activation='relu'),
tf.keras.layers.Dense(7*7*64, activation='relu'),
tf.keras.layers.Reshape(target_shape=(7, 7, 64)),
tf.keras.layers.Conv2DTranspose(filters=32, kernel_size=2, strides=(2,2), padding='same',activation='relu'),
tf.keras.layers.Conv2DTranspose(filters=1, kernel_size=2, strides=(2,2), padding='same',activation='sigmoid'),
])
model.compile(optimizer=tf.optimizers.Adam(), loss='mse')
model.summary()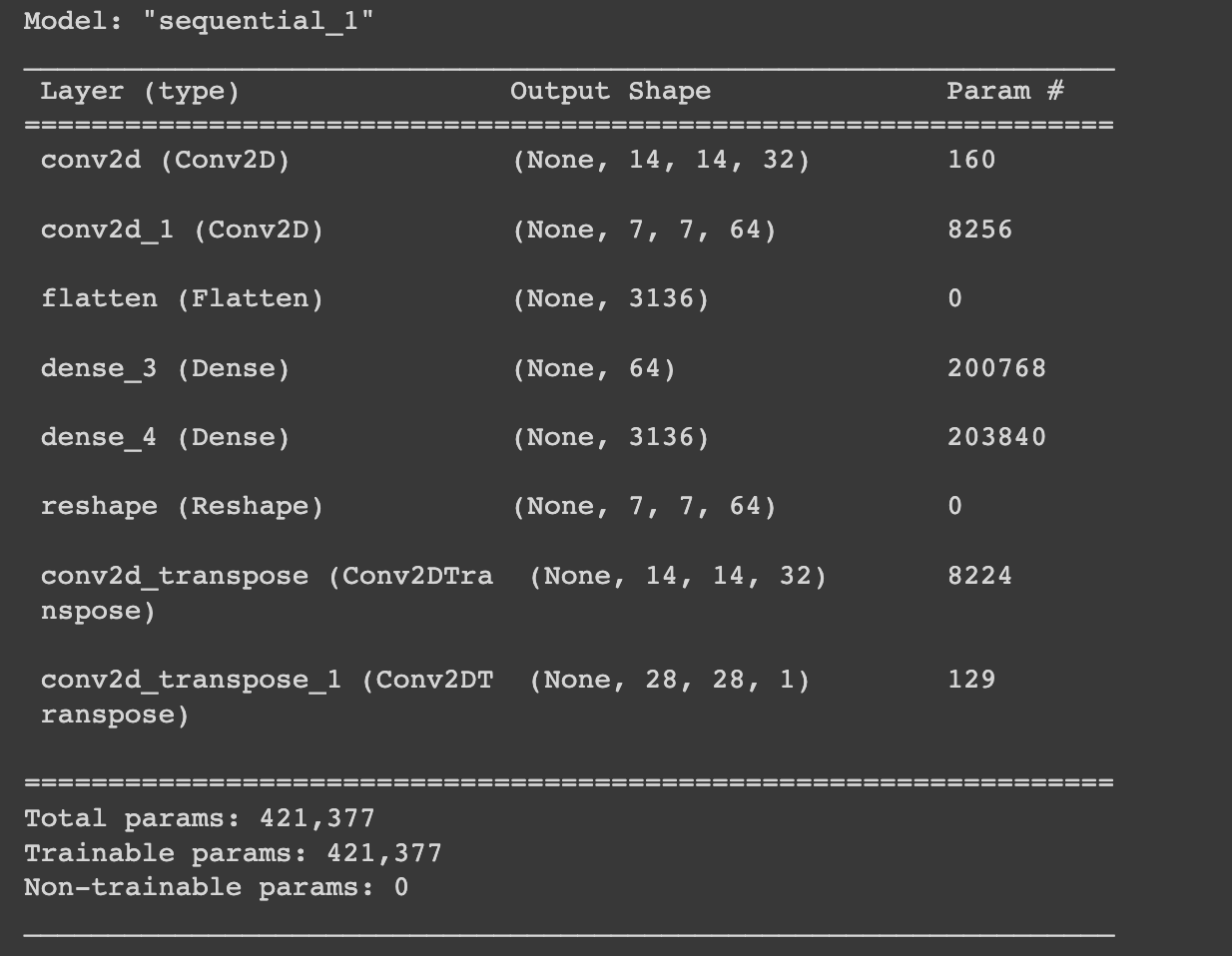
model.fit(train_X, train_X, epochs=20, batch_size=256)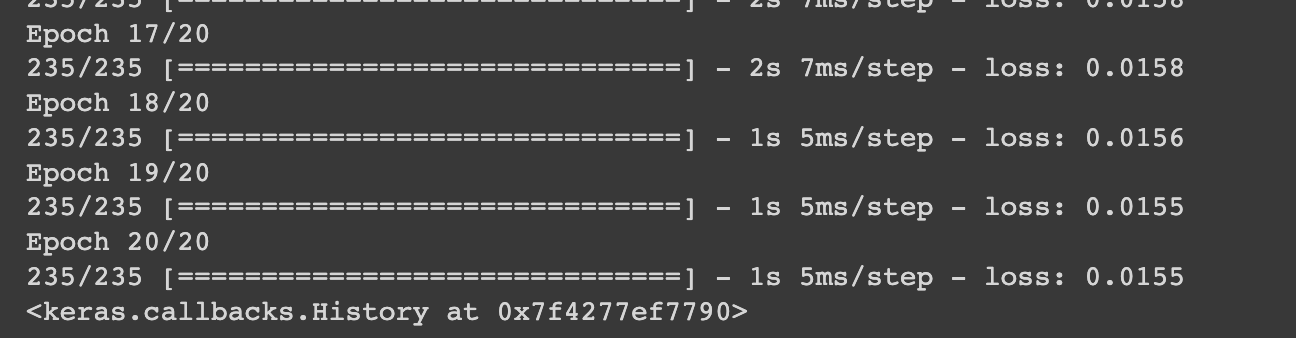
plt.figure(figsize=(4, 8))
for c in range(4):
plt.subplot(4, 2, c*2+1)
rand_index = random.randint(0, test_X.shape[0])
plt.imshow(test_X[rand_index].reshape(28, 28), cmap='gray')
plt.axis('off')
plt.subplot(4, 2, c*2+2)
img = model.predict(np.expand_dims(test_X[rand_index], axis=0))
plt.imshow(img.reshape(28, 28), cmap='gray')
plt.axis('off')
plt.show()
model.evaluate(test_X, test_X)
import math
x = np.arange(-5, 5, 0.01)
relu = [0 if z<0 else z for z in x]
elu = [1.0 * (np.exp(z)-1) if z <0 else z for z in x]
plt.axvline(0, color='gray')
plt.plot(x, relu, 'r--', label='relu')
plt.plot(x, elu, 'g-', label='elu')
plt.legend()
plt.show()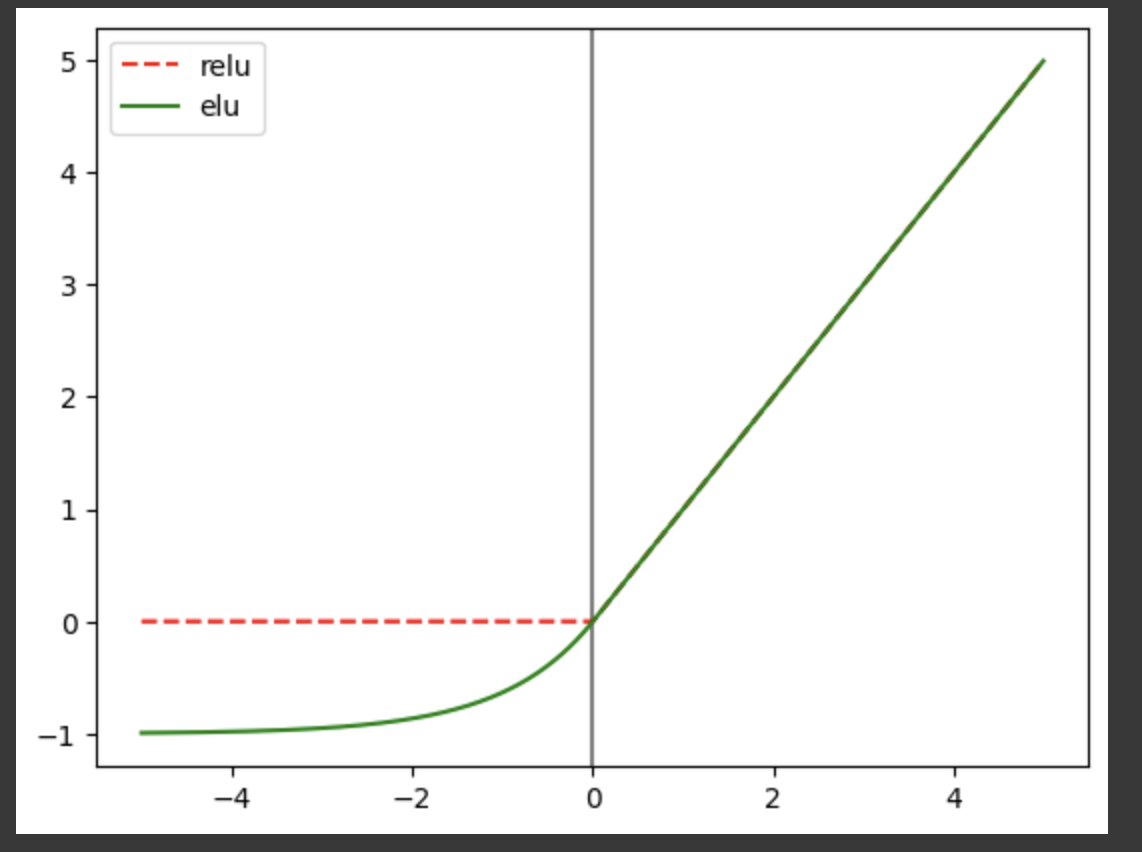
- elu로 변경
0보다 x가 작을때 무조건 0의 값을 가지는 relu가 아무리 연산량이 simple하다 하지만 안좋을 수 있으니 음의 값을 조금이라고 가지게 해보자.
train_X = train_X.reshape(-1, 28, 28, 1)
test_X = test_X.reshape(-1, 28, 28, 1)
model = tf.keras.Sequential([
tf.keras.layers.Conv2D(filters=32, kernel_size=2, strides=(2,2), activation='elu', input_shape=(28, 28, 1)),
tf.keras.layers.Conv2D(filters=64, kernel_size=2, strides=(2,2), activation='elu'),
tf.keras.layers.Flatten(),
tf.keras.layers.Dense(64, activation='elu'),
tf.keras.layers.Dense(7*7*64, activation='elu'),
tf.keras.layers.Reshape(target_shape=(7, 7, 64)),
tf.keras.layers.Conv2DTranspose(filters=32, kernel_size=2, strides=(2,2), padding='same',activation='elu'),
tf.keras.layers.Conv2DTranspose(filters=1, kernel_size=2, strides=(2,2), padding='same',activation='sigmoid'),
])
model.compile(optimizer=tf.optimizers.Adam(), loss='mse')
model.summary()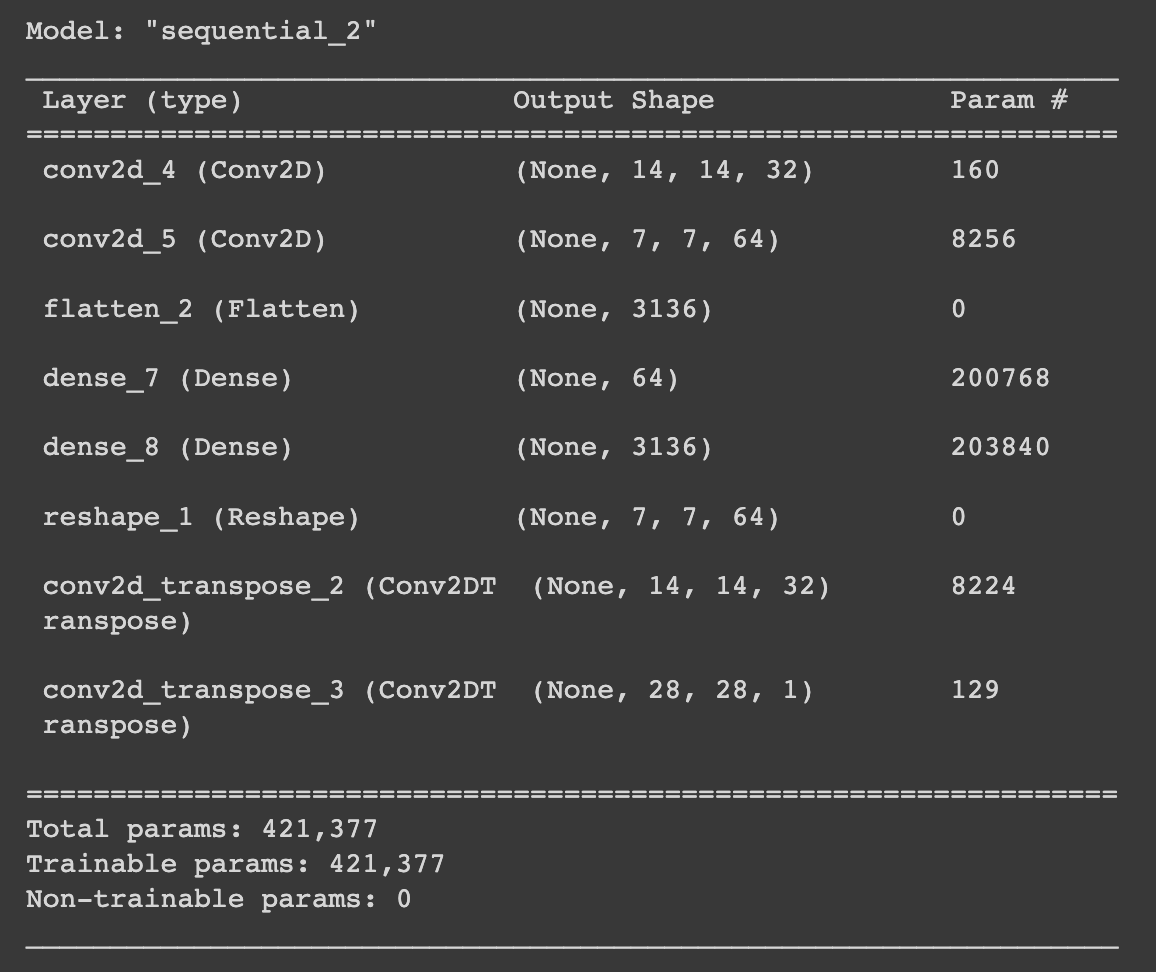
model.fit(train_X, train_X, epochs=20, batch_size=256)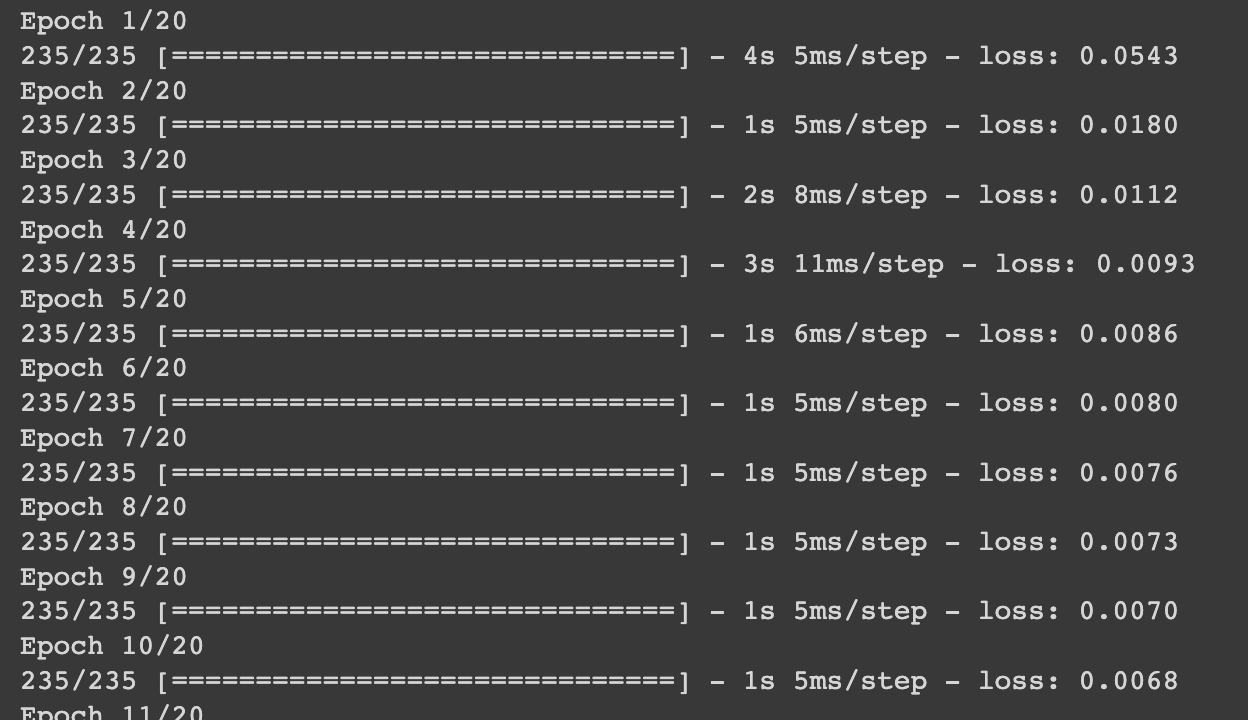
plt.figure(figsize=(4, 8))
for c in range(4):
plt.subplot(4, 2, c*2+1)
rand_index = random.randint(0, test_X.shape[0])
plt.imshow(test_X[rand_index].reshape(28, 28), cmap='gray')
plt.axis('off')
plt.subplot(4, 2, c*2+2)
img = model.predict(np.expand_dims(test_X[rand_index], axis=0))
plt.imshow(img.reshape(28, 28), cmap='gray')
plt.axis('off')
plt.show()
model.evaluate(test_X, test_X)
- 잠재변수 벡터 확보
latent_vector_model = tf.keras.Model(inputs=model.input, outputs=model.layers[3].output)
latent_vector = latent_vector_model.predict(train_X)
print(latent_vector.shape)
print(latent_vector[0])
1개의 숫자를 64의 숫자(특성)로 바꿈
- 군집
%%time
from sklearn.cluster import KMeans
kmeans = KMeans(n_clusters=10, n_init=10, random_state=42)
kmeans.fit(latent_vector)
- 시각화
plt.figure(figsize=(12, 12))
for i in range(10):
images = train_X[kmeans.labels_ == i]
for c in range(10):
plt.subplot(10, 10, i*10+c+1)
plt.imshow(images[c].reshape(28, 28), cmap='gray')
plt.axis('off')
plt.show()
- t-SNE
- t Stochastic Nearest Neghbor
- 고차원의 벡터를 저차원으로 옮겨서 시각화에 도움을 주는 방법
- k-Means가 각 클러스터를 계산하기 위한 단위로 중심과 각 데이터의 거리를 측정한다면 t-SNE는 각 데이터의 유사도를 정의하고 원래의 공간에서의 유사도와 저차원 공간에서의 유사도가 비슷해지도록 학습 시킴
- 여기서 유사도가 수학적으로 확률로 표현됨
%%time
from sklearn.manifold import TSNE
tsne = TSNE(n_components=2, learning_rate=100, perplexity=15, random_state=0)
tsne_vector = tsne.fit_transform(latent_vector[:5000])
cmap = plt.get_cmap('rainbow', 10)
fig = plt.scatter(tsne_vector[:, 0], tsne_vector[:, 1], marker='.', c=train_Y[:5000], cmap=cmap)
cb = plt.colorbar(fig, ticks=range(10))
n_clusters=10
tick_locs = (np.arange(n_clusters)+ 0.5)*(n_clusters-1)/n_clusters
cb.set_ticks(tick_locs)
cb.set_ticklabels(range(10))
plt.show()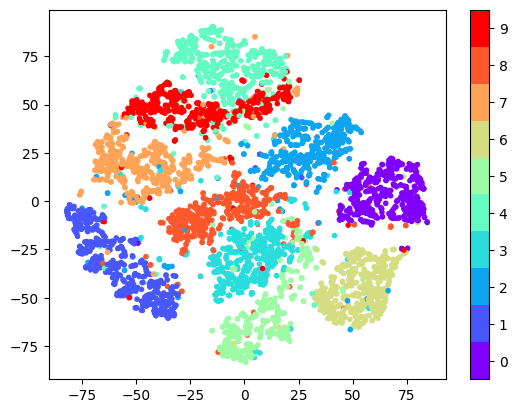
"이 글은 제로베이스 데이터 취업 스쿨 강의를 듣고 작성한 내용으로 제로베이스 데이터 취업 스쿨 강의 자료 일부를 발췌한 내용이 포함되어 있습니다."
