📌Pandas
- Python에서R 만큼 강력한 데이터 핸들링 성능을 제공하는 모듈
- 단일 프로세스에서는 최대 효율
- 코딩 가능하고 응용 가능한 엑셀로 받아들여도 됨
- 누군가는 스테로이드를 맞은 엑셀로 표현함
사용방법: import pandas as pd
📍Series
- index와 value로 이루어져 있다.
- 한 가지 데이터 타입만 가질 수 있다.
import pandas as pd
import numpy as nps = pd.Series([1, 3, 5, np.nan, 6, 8])
s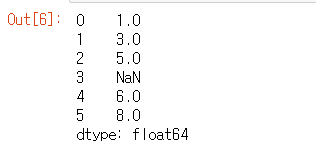
pd.Series([1, 2, 3, 4], dtype=np.float64)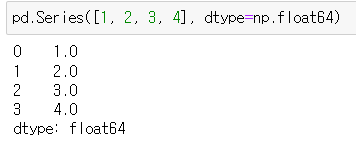
pd.Series([1, 2, 3, 4], dtype=str)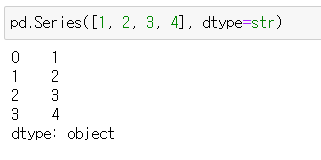
pd.Series([1, 2, 3, 4], dtype=str)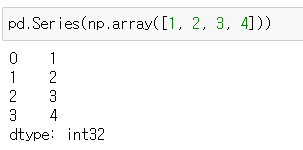
pd.Series({"Key":"Value"})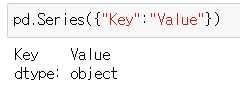
📍date_range()
- 시간, 날짜를 다루는 함수
- 출력은 버전에 따라 조금씩 다르다.
- periods: 원하는 기간
dates = pd.date_range("20230101", periods=6)
dates
📍DataFrame()
- Pandas에서 가장 많이 사용되는 데이터형
- index와 columns를 지정하면 된다.
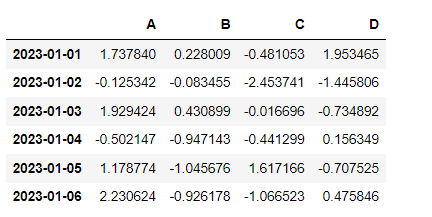
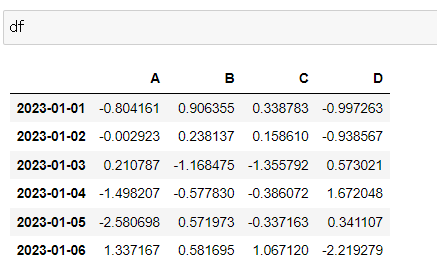
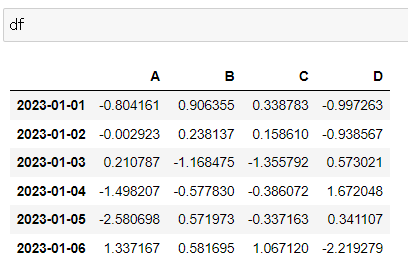
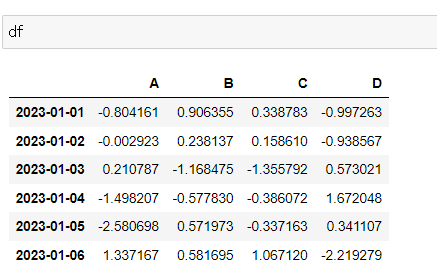
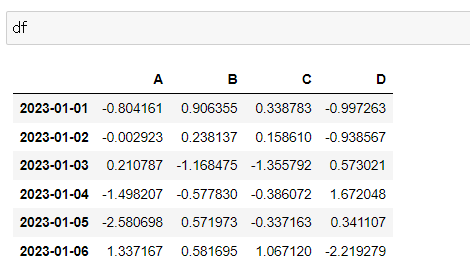
df = pd.DataFrame(np.random.randn(6, 4), index=dates, columns=["A", "B", "C", "D"])
dfnp.random.randn(6, 4): 6행 4열, 표준 정규 분포에서 샘플링한 난수 생성
index: 앞서 생성한 dates 변수
columns: 컬럼명
- 표준 정규 분포에서 샘플링한 난수 생성
# 표준 정규 분포에서 샘플링한 난수 생성
np.random.randn(6, 4)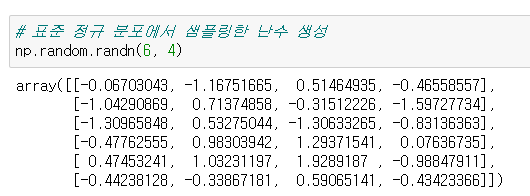
- 데이터 프레임 정보 탐색(head, index, values, columns)
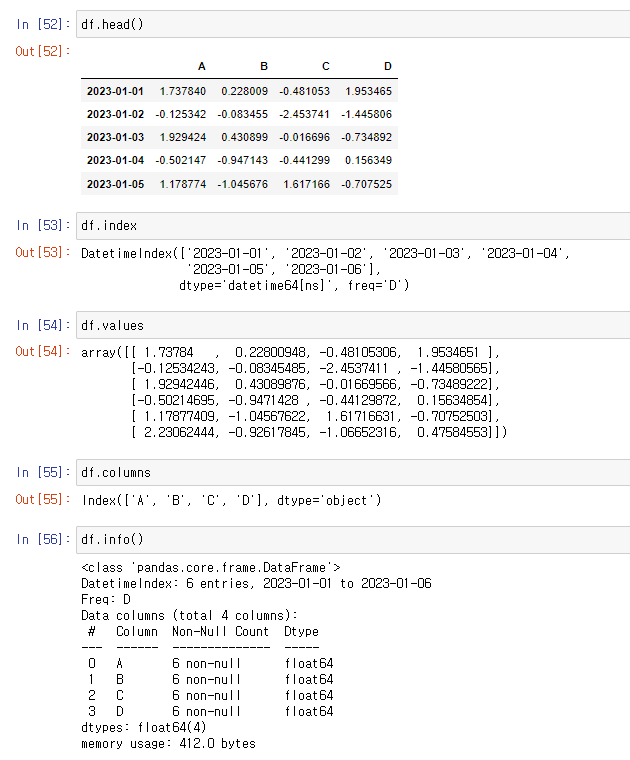
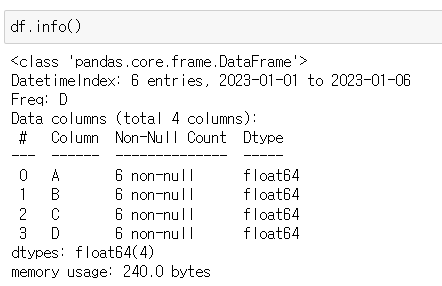
📍info()
- DataFrame의 기본 정보 확인
- 각 컬럼의 크기와 데이터 형태를 확인하는 경우가 많다.
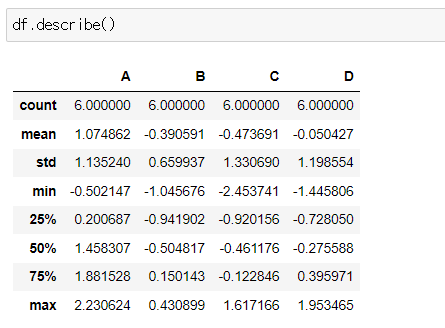
📍describe()
- DataFrame의 기술통계 정보 확인
📍sort_values()
- 데이터 정렬
- 특정 컬럼(열)을 기준으로 데이터를 정렬
- Default: 오름차순
B 컬럼을 기준으로 ascending=False로 정렬
df.sort_values(by="B", ascending=False)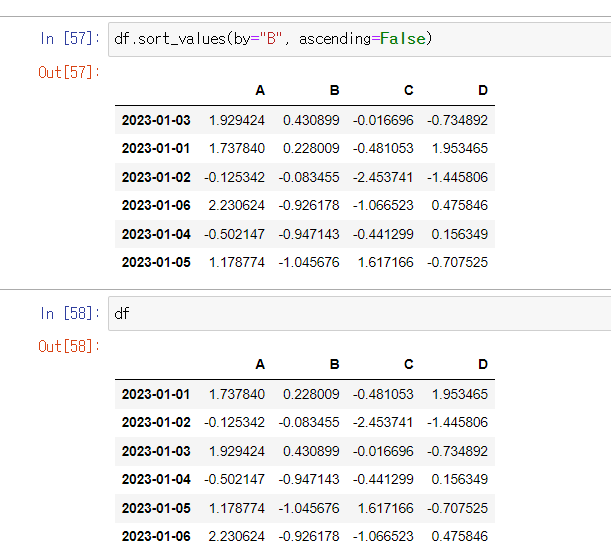
💡df 원본 데이터를 바뀌지 않는다. 따라서 inplace="True" 적용을 해야 원본 데이터가 바뀐다.
df.sort_values(by="B", ascending=False, inplace=True)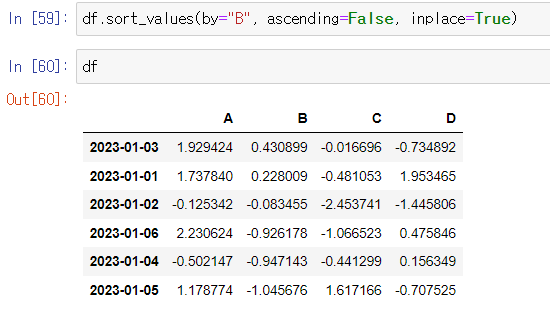
📍데이터 선택
📍한 개 컬럼 선택
✔️방법 1
df["A"]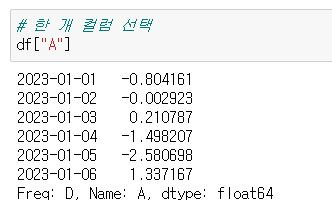
💡 데이터 타입
pandas의 Series 데이터 타입
✔️방법 2 - 문자열인 경우에만 가능하다.
df.A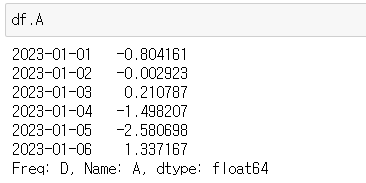
- ⚠️ 숫자, 숫자 문자열인 경우에는 불가능하다.
📍두 개 이상 컬럼 선택
# 두 개 이상 컬럼 선택
df[["A", "B"]]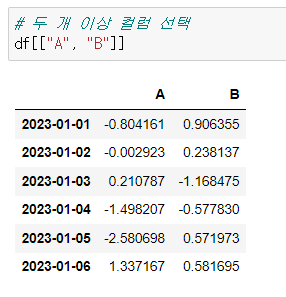
📍offset index
- [N:M]: N부터 M-1까지
- 인덱스나 컬럼의 이름으로 Slice 하는 경우는 끝을 포함함
df[:4]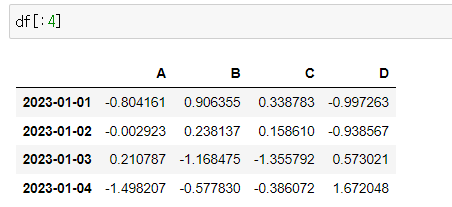
df["20230102":"20230104"]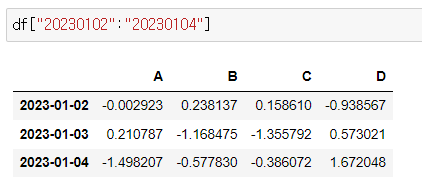
📍LOC
- loc : location
- index 이름으로 특정 행, 열을 선택합니다.

- 모든 행의 "A","B" 컬럼
df.loc[:, ["A","B"]]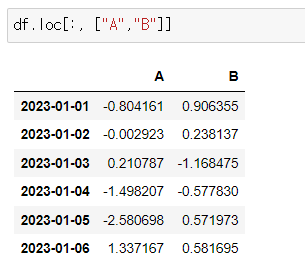
- "20230102":"20230104"행의 "A","B" 컬럼
df.loc["20230102":"20230104", ["A","B"]]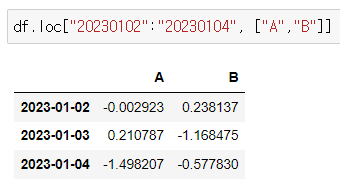
- "20230103"행의 "A","B" 컬럼
df.loc["20230103", ["A","B"]]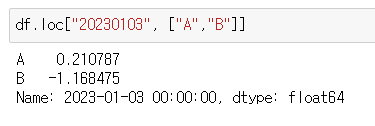
📍iLOC
- iloc : integer location
- 컴퓨터가 인식하는 인덱스 값으로 선택
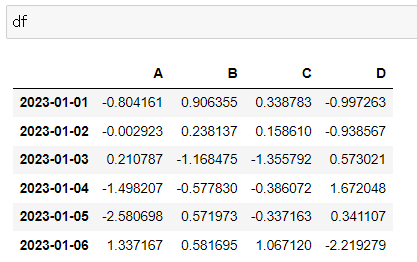
df.iloc[3]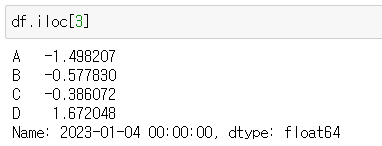
df.iloc[3, 2]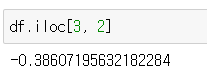
- iloc[3:5, 0:2] - 3, 4번 행 0, 1번 컬럼
df.iloc[3:5, 0:2]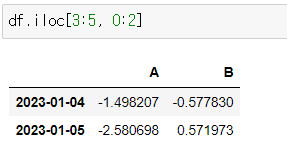
- iloc[[1, 2, 4], [0, 2]] - 1, 2, 4번 행 0, 2번 컬럼
df.iloc[[1, 2, 4], [0, 2]]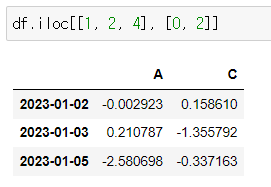
- iloc[:, 1:3] - 모든 행 1, 2번 컬럼
df.iloc[:, 1:3]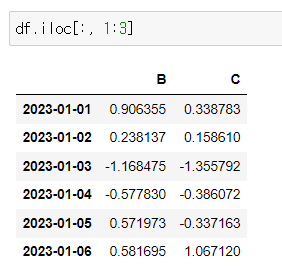
📍condition(조건)
- df의 A 컬럼에서 0보다 큰 숫자(양수)만 선택
df[df["A"] > 0]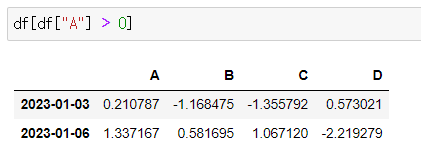
- df의 전체 컬럼에서 0보다 큰 것들만 출력
NaN : Not a Number
df[df > 0]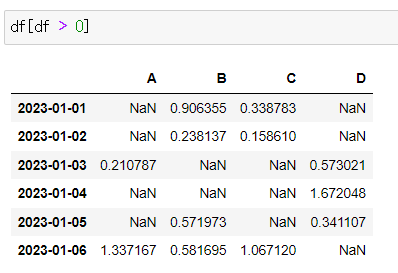
📍컬럼 추가
- 기존 컬럼이 없으면 추가
- 기존 컬럼이 있으면 수정
- 컬럼 E 추가
⚠️index의 개수를 맞추지 않으면 ERROR 발생
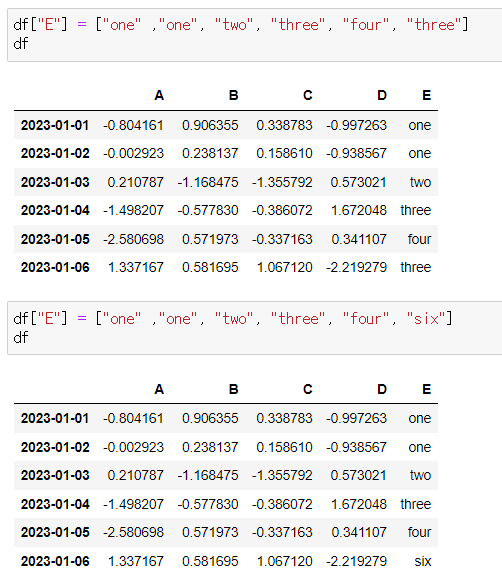
df["E"] = ["one" ,"one", "two", "three", "four", "three"]
df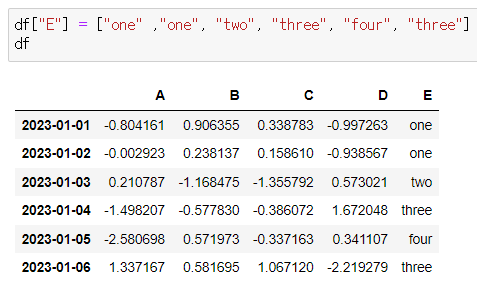
- 컬럼 E 수정
📍isin()
특정 요소가 있는지 확인
- E 컬럼에 "two", "four"가 있는가 (O - True, X - False)
df["E"].isin(["two", "four"])
- E 컬럼에 "two", "four"가 있는 행만 선택
df[df["E"].isin(["two", "four"])]
📍특정 컬럼 제거
방법 1: del
방법 2: drop
✔️방법 1 - del
- E 컬럼 제거
del df["E"]
df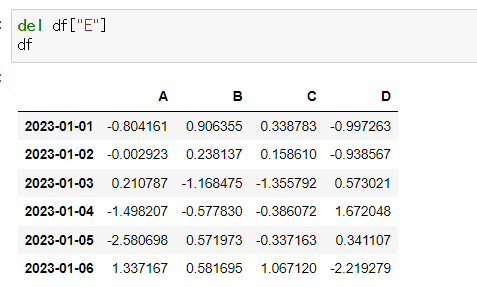
✔️방법 2 - drop
⭕ df.drop(["D"], axis=1)
axis=0 가로, axis=1 세로
df.drop(["D"], axis=1) # axis=0 가로, axis=1 세로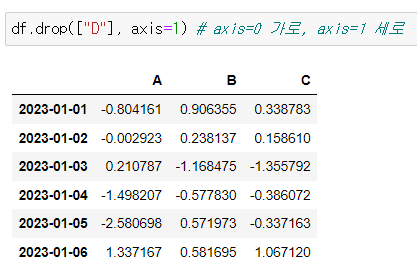
❌ df.drop(["D"])
df.drop(["D"])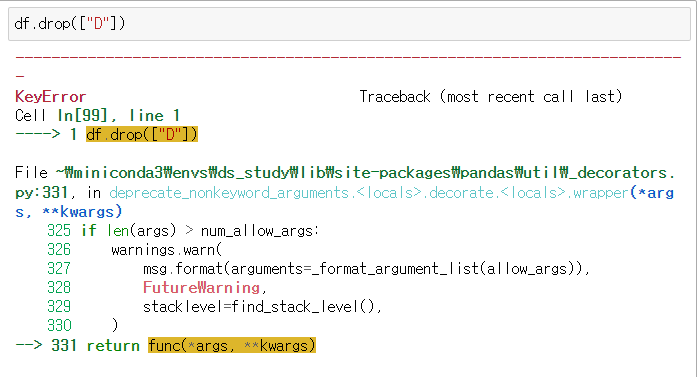
axis = 축
💡axis=0
axis=0인 경우는 인덱스를 작성해줘야한다.
df.drop(["20230102"], axis=0) # axis=0 가로, axis=1 세로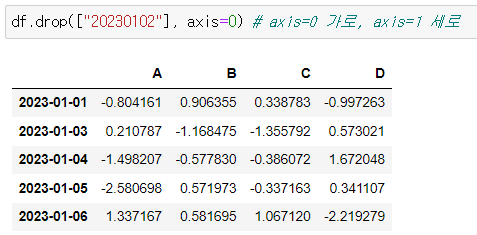
📍apply()
함수를 적용
📍sum - 합
df["A"].apply("sum")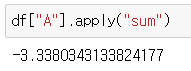
df[["A", "D"]].apply("sum")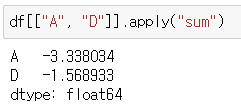
- numpy의 sum
df["A"].apply(np.sum)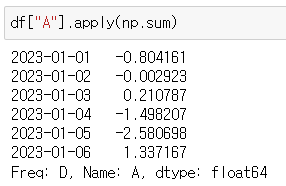
df.apply(np.sum)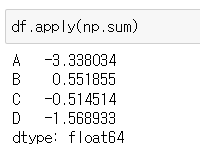
📍mean - 평균
df["A"].apply("mean")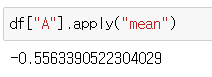
📍min - 최솟값, max - 최댓값
df["A"].apply("min"), df["A"].apply("max")
📍cumsum(누적합)
numpy의 cumsum(누적합) 함수를 이용하면 적용된다.
# 각 컬럼 누적합
df.apply(np.cumsum)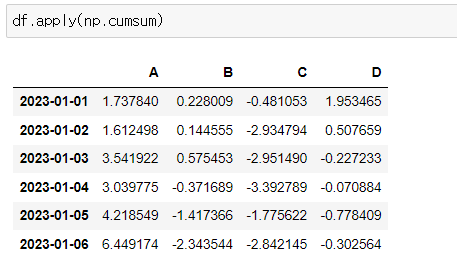
- 사용자 함수(양수는 plus 음수는 minus 반환)
def plusminus(num):
return "plus" if num > 0 else "minus"df["A"].apply(plusminus)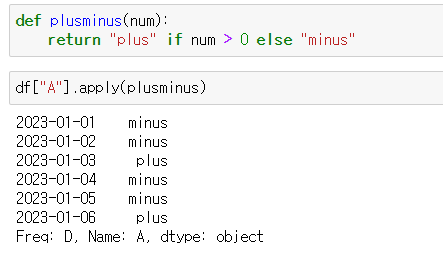
- lambda 함수
df["A"].apply(lambda num: "plus" if num > 0 else "minus")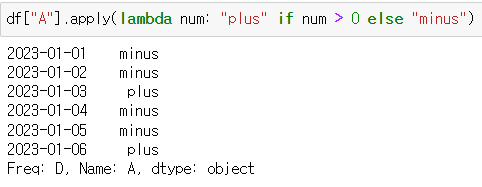
📌데이터프레임 생성
✔️방법 1 - 딕셔너리 안의 리스트 형태
열 값 기준으로 데이터가 들어감
# 딕셔너리 안의 리스트 형태
left = pd.DataFrame({
"key": ["K0", "K4", "K2", "K3"],
"A": ["A0", "A1", "A2", "A3"],
"B": ["B0", "B1", "B2", "B3"]
})
left
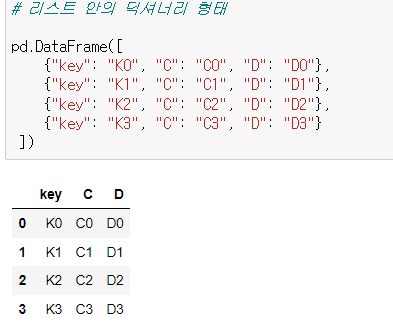
✔️방법 2 - 리스트 안의 딕셔너리 형태
행 기준으로 데이터가 들어감
# 리스트 안의 딕셔너리 형태
pd.DataFrame([
{"key": "K0", "C": "C0", "D": "D0"},
{"key": "K1", "C": "C1", "D": "D1"},
{"key": "K2", "C": "C2", "D": "D2"},
{"key": "K3", "C": "C3", "D": "D3"}
])
📌데이터프레임 병합하는 방법
- pd.concat()
- pd.merge()
- pd.join()
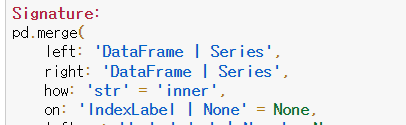
📍pd.merge()
- 두 데이터 프레임에서 컬럼이나 인덱스를 기준으로 잡고 병합하는 방법
- 기준이 되는 컬럼이나 인덱스를 키값이라고 한다.
- 기준이 되는 키값은 두 데이터 프레임에 모두 포함되어 있어야한다.
📍how="inner" - 교집합
양 쪽 데이터 프레임 중에서 "key"라는 컬럼을 기준 키 값으로 잡고 병합하라.
💡how="inner" 생략 가능 - 디폴트값
pd.merge(left, right, on="key")pd.merge(left, right, how="inner", on="key")
📍 how="outer" - 합집합
left, right 데이터프레임을 "key"라는 컬럼 이름으로 병합하는데 합집합을 기준으로 데이터를 병합하라.
pd.merge(left, right, how="outer", on="key")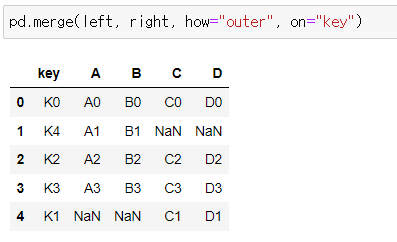
📍how="left"
left, right 데이터프레임을 "key"라는 컬럼 이름으로 병합하는데 left 데이터 키 값을 기준으로 데이터를 병합하라.
pd.merge(left, right, how="left", on="key")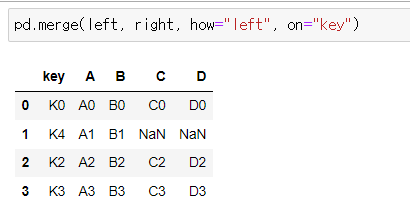
📍how="right"
left, right 데이터프레임을 "key"라는 컬럼 이름으로 병합하는데 right 데이터 키 값을 기준으로 데이터를 병합하라.
pd.merge(left, right, how="right", on="key")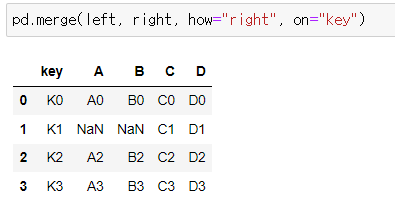
느낀 점😊
판다스 올해 초 책 구매해서 조금 사용해보고 오랜만이다.
확실히 그냥 책만 가지고 공부할 때랑 강의를 들으면서 적용해보는 거랑 이해도가 다르지만 진도가 너무 빨라서 머리에 다 들어올지가 의문,,,ㅎㅎ
외우기보단 우선 이해를 목적으로 학습 중
"이 글은 제로베이스 데이터 취업 스쿨 강의 자료 일부를 발췌한 내용이 포함되어 있습니다."
